SSR-Merge: Subspace Signal Routing for Training-Free LoRA Merging in Diffusion Models
Pith reviewed 2026-06-27 13:34 UTC · model grok-4.3
The pith
SSR merges LoRAs by routing decorrelated signals through a unified subspace instead of combining parameters directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
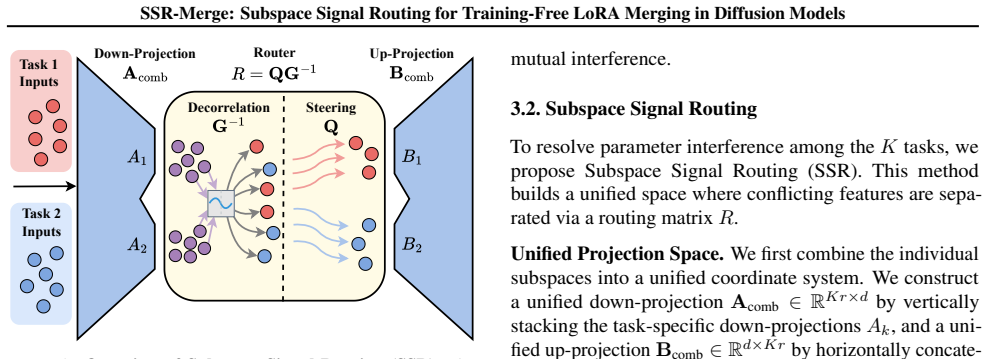
SSR first constructs a unified subspace by concatenating candidate LoRAs along the rank dimension. Next, SSR employs an inverse correlation matrix to decorrelate mixed signals within this space. Finally, a directional guide matrix steers these purified signals into their respective task-specific subspaces. The approach aligns with the Ordinary Least Squares solution, ensuring mathematical optimality, and supports a streaming algorithm via the additivity of sufficient statistics.
What carries the argument
Subspace Signal Routing via rank-wise subspace concatenation, followed by an inverse correlation matrix for decorrelation and a directional guide matrix for task-specific routing.
If this is right
- Merging works without task-specific data or additional training for any collection of LoRAs.
- Parameter interference is removed through explicit decorrelation rather than heuristic weighting.
- On-the-fly updates become possible with reduced memory via the streaming algorithm.
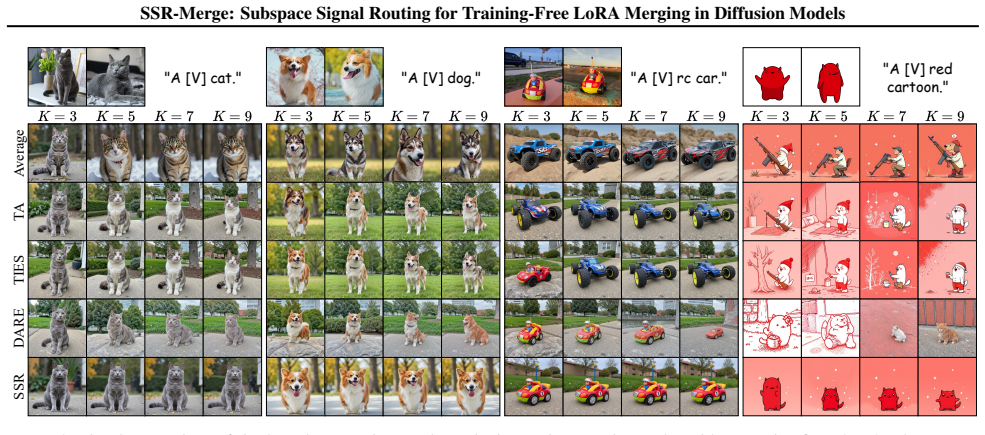
- Generation quality exceeds that of earlier parameter-space merging methods at similar speed.
Where Pith is reading between the lines
- The same subspace construction could be tested on LoRA-style adapters outside diffusion models.
- The OLS equivalence may suggest analogous routing methods for other forms of model composition.
- Dynamic selection among many LoRAs at inference time could reuse the same decorrelation step.
- Hardware accelerators might exploit the streaming property for real-time multi-task generation.
Load-bearing premise
The rank-wise concatenation into one unified subspace together with the inverse correlation matrix and directional guide matrix fully resolves parameter interference for arbitrary LoRAs without any task data or retraining.
What would settle it
Merge several LoRAs trained on mutually incompatible tasks and check whether the merged model produces outputs whose quality equals or exceeds that of the best individual LoRA under the same prompts.
Figures





read the original abstract
Low-Rank Adaptation (LoRA) merging can efficiently combine diverse generative capabilities from multiple trained LoRAs for a diffusion model. However, existing LoRA merging techniques often suffer from severe parameter interference, causing destructive collisions in the shared parameter space. To address this, we propose Subspace Signal Routing (SSR), which resolves interference by routing internal signals instead of performing parameter-space merge. Specifically, SSR first constructs a unified subspace by concatenating candidate LoRAs along the rank dimension. Next, SSR employs an inverse correlation matrix to decorrelate mixed signals within this space. Finally, a directional guide matrix steers these purified signals into their respective task-specific subspaces. We provide a rigorous theoretical analysis proving that SSR aligns with the Ordinary Least Squares (OLS) solution, thereby ensuring mathematical optimality. We utilize the additivity of sufficient statistics to design a streaming algorithm. This enables on-the-fly updates that significantly reduce memory overhead and computation time. Extensive experiments validate that SSR significantly outperforms state-of-the-art methods while maintaining comparable efficiency. Code is available at https://github.com/nagara214/SSR-Merge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Subspace Signal Routing (SSR) for training-free merging of LoRAs in diffusion models to mitigate parameter interference. SSR constructs a unified subspace via rank-wise concatenation of candidate LoRAs, applies an inverse correlation matrix for decorrelation, and uses a directional guide matrix to route signals to task-specific subspaces. It claims a rigorous proof that this procedure aligns with the OLS estimator for mathematical optimality, introduces a streaming algorithm exploiting additivity of sufficient statistics for efficiency, and reports superior empirical performance over prior merging methods.
Significance. If the claimed OLS equivalence is rigorously established without circularity or hidden assumptions, the work would supply a parameter-free optimality guarantee for data-free LoRA merging, a practical streaming implementation, and reproducible code. This could meaningfully advance multi-task adaptation of diffusion models by replacing heuristic merging with a provably optimal routing mechanism.
major comments (2)
- [Abstract, §3] Abstract and §3 (theoretical analysis): the central claim that SSR 'aligns with the Ordinary Least Squares (OLS) solution' is load-bearing for the optimality guarantee, yet the provided text supplies no derivation showing that the composite operation (rank-wise concatenation + inverse correlation matrix + directional guide matrix) reproduces the normal equations of any stated merging objective. Without the explicit mapping from the subspace construction to the OLS estimator (including the precise definition of the correlation matrix and the interference model), the equivalence cannot be verified and may reduce to a tautology or hold only under unstated orthogonality assumptions.
- [§4] §4 (streaming algorithm) and experiments: the additivity of sufficient statistics is invoked to justify on-the-fly updates, but no explicit statement is given of the underlying statistical model or the precise sufficient statistics being accumulated; this leaves open whether the streaming procedure preserves the claimed OLS optimality when LoRAs are added incrementally.
minor comments (2)
- [§3] Notation for the correlation matrix and guide matrix should be introduced with explicit dimensions and a small worked example to clarify how they act on the concatenated subspace.
- [§5] The experimental section should report the exact number of LoRAs merged per task, the rank values used, and any data-exclusion criteria applied when computing the correlation matrix.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on the theoretical claims and streaming implementation. We address each major comment below and will incorporate the requested clarifications and derivations into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (theoretical analysis): the central claim that SSR 'aligns with the Ordinary Least Squares (OLS) solution' is load-bearing for the optimality guarantee, yet the provided text supplies no derivation showing that the composite operation (rank-wise concatenation + inverse correlation matrix + directional guide matrix) reproduces the normal equations of any stated merging objective. Without the explicit mapping from the subspace construction to the OLS estimator (including the precise definition of the correlation matrix and the interference model), the equivalence cannot be verified and may reduce to a tautology or hold only under unstated orthogonality assumptions.
Authors: We agree that an explicit derivation is necessary for verifiability. In the revised manuscript we will expand §3 with a complete proof that maps the SSR operations to the OLS normal equations: rank-wise concatenation constructs the design matrix X whose columns are the LoRA basis vectors; the inverse correlation matrix is defined as (X^T X)^{-1} where the correlation matrix is the Gram matrix of these vectors; and the directional guide matrix implements the projection that solves the multi-task least-squares objective under the additive interference model (parameter collisions as summed updates). This derivation will be presented without hidden orthogonality assumptions beyond those stated in the merging objective. revision: yes
-
Referee: [§4] §4 (streaming algorithm) and experiments: the additivity of sufficient statistics is invoked to justify on-the-fly updates, but no explicit statement is given of the underlying statistical model or the precise sufficient statistics being accumulated; this leaves open whether the streaming procedure preserves the claimed OLS optimality when LoRAs are added incrementally.
Authors: We will revise §4 to state the statistical model explicitly as multivariate linear regression with the merged weight as the response and the concatenated LoRA directions as predictors. The sufficient statistics are the accumulated Gram matrix X^T X and the cross-term X^T y. Because these statistics are additive, appending a new LoRA updates them by simple matrix addition, and the resulting OLS solution remains identical to the batch solution. A short proof of invariance under incremental addition will be added. revision: yes
Circularity Check
No circularity: OLS alignment presented as independent theoretical result
full rationale
The abstract describes SSR via explicit construction (rank-wise concatenation into unified subspace, inverse correlation matrix for decorrelation, directional guide matrix) and separately claims a rigorous theoretical analysis proving alignment with the OLS solution. No equations, self-citations, or reductions are shown that would make the alignment tautological or force the prediction by definition of the inputs. The method is not defined in terms of OLS; instead, the paper asserts an external equivalence via analysis. No load-bearing self-citation or fitted-input-as-prediction pattern appears. The derivation chain is therefore self-contained against the given text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ordinary Least Squares yields the optimal linear estimator for the signal routing task
invented entities (1)
-
Subspace Signal Routing (SSR) mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
K., Hayase, J., and Srinivasa, S
Ainsworth, S. K., Hayase, J., and Srinivasa, S. Git re-basin: Merging models modulo permutation symmetries. In ICLR, 2023
2023
-
[2]
J., Lu, Z., Wu, E., and Hu, J
Chen, D., Tan, V. J., Lu, Z., Wu, E., and Hu, J. Openfed: A comprehensive and versatile open-source federated learning framework. In CVPR Workshops, 2023
2023
-
[3]
Iteris: Iterative inference-solving alignment for lora merging
Chen, H., Li, R., Zhu, B., Wang, Z., and Chen, L. Iteris: Iterative inference-solving alignment for lora merging. In CVPR, 2025 a
2025
-
[4]
Se-merging: A self-enhanced approach for dynamic model merging
Chen, Z., Zhou, Z., Zhang, B., Zhang, W., Sun, X., and Yan, J. Se-merging: A self-enhanced approach for dynamic model merging. arXiv preprint arXiv:2506.18135, 2025 b
arXiv 2025
-
[5]
and Belilovsky, E
Davari, M. and Belilovsky, E. Model breadcrumbs: Scaling multi-task model merging with sparse masks. In ECCV, 2024
2024
-
[6]
Arcface: Additive angular margin loss for deep face recognition
Deng, J., Guo, J., Xue, N., and Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In CVPR, 2019
2019
-
[7]
Implicit style-content separation using b-lora
Frenkel, Y., Vinker, Y., Shamir, A., and Cohen-Or, D. Implicit style-content separation using b-lora. In ECCV, 2024
2024
-
[8]
A., Crisostomi, D., Bucarelli, M
Gargiulo, A. A., Crisostomi, D., Bucarelli, M. S., Scardapane, S., Silvestri, F., and Rodola, E. Task singular vectors: Reducing task interference in model merging. In CVPR, 2025
2025
-
[9]
Z., Shi, Y., Chen, Y., Fan, Z., Xiao, W., Zhao, R., Chang, S., Wu, W., et al
Gu, Y., Wang, X., Wu, J. Z., Shi, Y., Chen, Y., Fan, Z., Xiao, W., Zhao, R., Chang, S., Wu, W., et al. Mix-of-show: Decentralized low-rank adaptation for multi-concept customization of diffusion models. In NeurIPS, 2023
2023
-
[10]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. In NeurIPS, 2020
2020
-
[11]
Parameter-efficient transfer learning for nlp
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. Parameter-efficient transfer learning for nlp. In ICML, 2019
2019
-
[12]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. In ICLR, 2022
2022
-
[13]
Y., Pang, T., Du, C., and Lin, M
Huang, C., Liu, Q., Lin, B. Y., Pang, T., Du, C., and Lin, M. Lorahub: Efficient cross-task generalization via dynamic lora composition. In COLM, 2023
2023
-
[14]
Emr-merging: Tuning-free high-performance model merging
Huang, C., Ye, P., Chen, T., He, T., Yue, X., and Ouyang, W. Emr-merging: Tuning-free high-performance model merging. In NeurIPS, 2024
2024
-
[15]
T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A
Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing models with task arithmetic. In ICLR, 2023
2023
-
[16]
Dataless knowledge fusion by merging weights of language models
Jin, X., Ren, X., Preotiuc-Pietro, D., and Cheng, P. Dataless knowledge fusion by merging weights of language models. In ICLR, 2023
2023
-
[17]
A style-based generator architecture for generative adversarial networks
Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks. In CVPR, 2019
2019
-
[18]
Labs, B. F. Flux. https://github.com/black-forest-labs/flux, 2024
2024
-
[19]
The power of scale for parameter-efficient prompt tuning
Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. In EMNLP, 2021
2021
-
[20]
Li, X. L. and Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. In ACL, 2021
2021
-
[21]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In ECCV, 2024
2024
-
[22]
Twin-merging: Dynamic integration of modular expertise in model merging
Lu, Z., Fan, C., Wei, W., Qu, X., Chen, D., and Cheng, Y. Twin-merging: Dynamic integration of modular expertise in model merging. In NeurIPS, 2024
2024
-
[23]
Unipelt: A unified framework for parameter-efficient language model tuning
Mao, Y., Mathias, L., Hou, R., Almahairi, A., Ma, H., Han, J., Yih, S., and Khabsa, M. Unipelt: A unified framework for parameter-efficient language model tuning. In ACL, 2022
2022
-
[24]
D., and van de Weijer, J
Marczak, D., Magistri, S., Cygert, S., Twardowski, B., Bagdanov, A. D., and van de Weijer, J. No task left behind: Isotropic model merging with common and task-specific subspaces. In ICML, 2025
2025
-
[25]
Matena, M. S. and Raffel, C. A. Merging models with fisher-weighted averaging. In NeurIPS, 2022
2022
-
[26]
Dinov2: Learning robust visual features without supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[27]
K-lora: Unlocking training-free fusion of any subject and style loras
Ouyang, Z., Li, Z., and Hou, Q. K-lora: Unlocking training-free fusion of any subject and style loras. In CVPR, 2025
2025
-
[28]
D., Calderara, S., and van de Weijer, J
Panariello, A., Marczak, D., Magistri, S., Porrello, A., Twardowski, B., Bagdanov, A. D., Calderara, S., and van de Weijer, J. Accurate and efficient low-rank model merging in core space. In NeurIPS, 2025
2025
-
[29]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In ICML, 2021
2021
-
[30]
Hierarchical text-conditional image generation with clip latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022
Pith/arXiv arXiv 2022
-
[31]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In CVPR, 2022
2022
-
[32]
Duolora: Cycle-consistent and rank-disentangled content-style personalization
Roy, A., Borse, S., Kadambi, S., Das, D., Mahajan, S., Garrepalli, R., Park, H., Nayak, A., Chellappa, R., Hayat, M., et al. Duolora: Cycle-consistent and rank-disentangled content-style personalization. In ICCV, 2025
2025
-
[33]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., and Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, 2023
2023
-
[34]
L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E. L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al. Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022
2022
-
[35]
Ziplora: Any subject in any style by effectively merging loras
Shah, V., Ruiz, N., Cole, F., Lu, E., Lazebnik, S., Li, Y., and Jampani, V. Ziplora: Any subject in any style by effectively merging loras. In ECCV, 2024
2024
-
[36]
Shenaj, D., Bohdal, O., Ozay, M., Zanuttigh, P., and Michieli, U. Lora. rar: Learning to merge loras via hypernetworks for subject-style conditioned image generation. In ICCV, 2025
2025
-
[37]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In ICLR, 2021
2021
-
[38]
Zipit! merging models from different tasks without training
Stoica, G., Bolya, D., Bjorner, J., Ramesh, P., Hearn, T., and Hoffman, J. Zipit! merging models from different tasks without training. In ICLR, 2024
2024
-
[39]
Model merging with svd to tie the knots
Stoica, G., Ramesh, P., Ecsedi, B., Choshen, L., and Hoffman, J. Model merging with svd to tie the knots. In ICLR, 2025
2025
-
[40]
Concrete subspace learning based interference elimination for multi-task model fusion
Tang, A., Shen, L., Luo, Y., Ding, L., Hu, H., Du, B., and Tao, D. Concrete subspace learning based interference elimination for multi-task model fusion. arXiv preprint arXiv:2312.06173, 2023
arXiv 2023
-
[41]
Diffusers: State-of-the-art diffusion models
von Platen, P., Patil, S., Lozhkov, A., Cuenca, P., Lambert, N., Rasul, K., Davaadorj, M., Nair, D., Paul, S., Berman, W., Xu, Y., Liu, S., and Wolf, T. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/diffusers, 2022
2022
-
[42]
Lora-flow: Dynamic lora fusion for large language models in generative tasks
Wang, H., Ping, B., Wang, S., Han, X., Chen, Y., Liu, Z., and Sun, M. Lora-flow: Dynamic lora fusion for large language models in generative tasks. In ACL, 2024 a
2024
-
[43]
Localizing task information for improved model merging and compression
Wang, K., Dimitriadis, N., Ortiz-Jimenez, G., Fleuret, F., and Frossard, P. Localizing task information for improved model merging and compression. In ICML, 2024 b
2024
-
[44]
Modeling multi-task model merging as adaptive projective gradient descent
Wei, Y., Tang, A., Shen, L., Hu, Z., Yuan, C., and Cao, X. Modeling multi-task model merging as adaptive projective gradient descent. In ICML, 2025
2025
-
[45]
Wiggins, W. F. and Tejani, A. S. On the opportunities and risks of foundation models for natural language processing in radiology. Radiology: Artificial Intelligence, 2022
2022
-
[46]
L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Transformers: State-of-the-art natural language processing. In EMNLP, 2020
2020
-
[47]
Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A
Wortsman, M., Ilharco, G., Gadre, S. Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A. S., Namkoong, H., Farhadi, A., Carmon, Y., Kornblith, S., et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In ICML, 2022
2022
-
[48]
Qwen-image technical report, 2025
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., a...
Pith/arXiv arXiv 2025
-
[49]
Wu, X., Huang, S., and Wei, F. Mixture of lora experts. arXiv preprint arXiv:2404.13628, 2024
arXiv 2024
-
[50]
A., and Bansal, M
Yadav, P., Tam, D., Choshen, L., Raffel, C. A., and Bansal, M. Ties-merging: Resolving interference when merging models. In NeurIPS, 2023
2023
-
[51]
Representation surgery for multi-task model merging
Yang, E., Shen, L., Wang, Z., Guo, G., Chen, X., Wang, X., and Tao, D. Representation surgery for multi-task model merging. In ICML, 2024 a
2024
-
[52]
Adamerging: Adaptive model merging for multi-task learning
Yang, E., Wang, Z., Shen, L., Liu, S., Guo, G., Wang, X., and Tao, D. Adamerging: Adaptive model merging for multi-task learning. In ICLR, 2024 b
2024
-
[53]
Lora-composer: Leveraging low-rank adaptation for multi-concept customization in training-free diffusion models
Yang, Y., Wang, W., Peng, L., Song, C., Chen, Y., Li, H., Yang, X., Lu, Q., Cai, D., He, X., et al. Lora-composer: Leveraging low-rank adaptation for multi-concept customization in training-free diffusion models. IEEE Transactions on Image Processing, 2025
2025
-
[54]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y. Language models are super mario: Absorbing abilities from homologous models as a free lunch. In ICML, 2024
2024
-
[55]
Robustmerge: Parameter-efficient model merging for mllms with direction robustness
Zeng, F., Guo, H., Zhu, F., Shen, L., and Tang, H. Robustmerge: Parameter-efficient model merging for mllms with direction robustness. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[56]
Adding conditional control to text-to-image diffusion models
Zhang, L., Rao, A., and Agrawala, M. Adding conditional control to text-to-image diffusion models. In ICCV, 2023
2023
-
[57]
Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild
Zhao, Z., Gan, L., Wang, G., Zhou, W., Yang, H., Kuang, K., and Wu, F. Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild. arXiv preprint arXiv:2402.09997, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.