OmniCD: A Foundational Framework for Remote Sensing Image Change Detection Guided by Multimodal Semantics
Pith reviewed 2026-06-29 08:00 UTC · model grok-4.3
The pith
OmniCD unifies remote sensing change detection by guiding it with multimodal image and text prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniCD is a foundational framework that unifies remote sensing change detection through multimodal semantic guidance, incorporating prompts such as text descriptions and semantic maps into an architecture with hierarchical scene retrieval and style disentanglement, backed by the RSITCD dataset of over 300K pairs, to achieve strong performance across tasks from binary to zero-shot.
What carries the argument
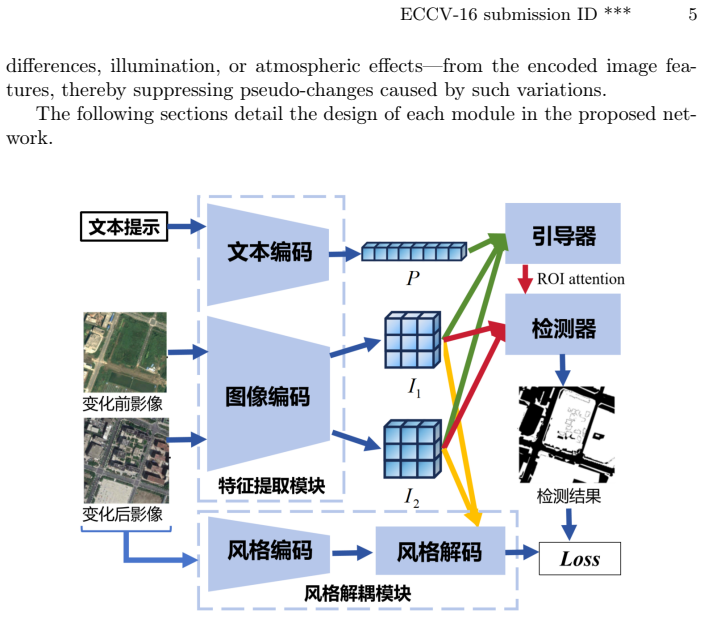
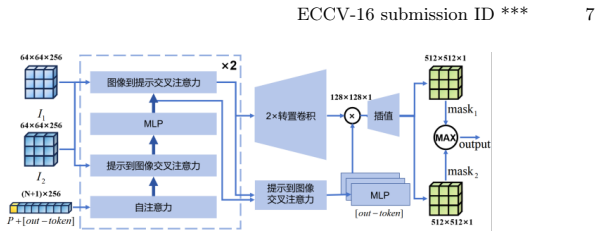
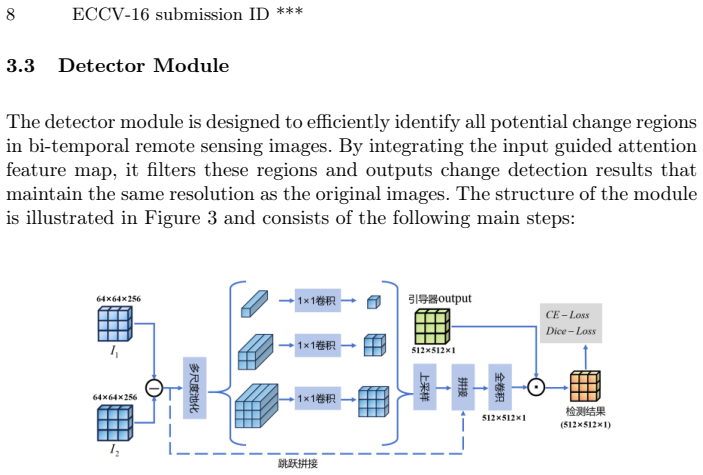
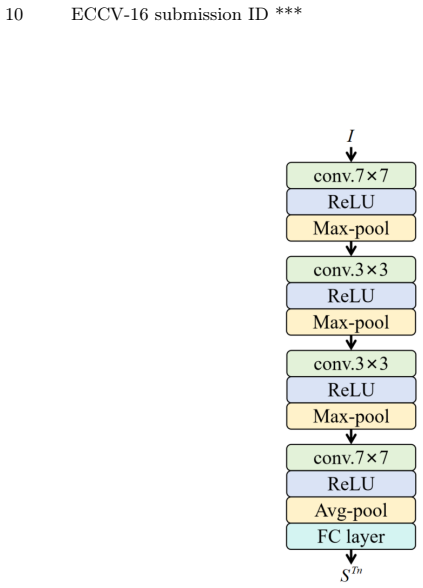
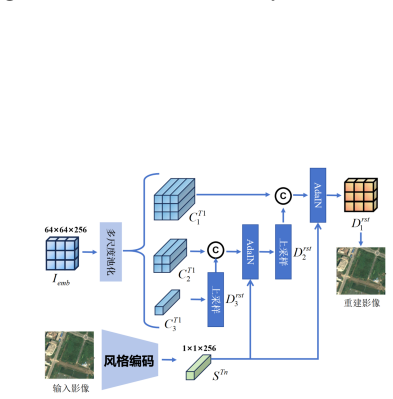
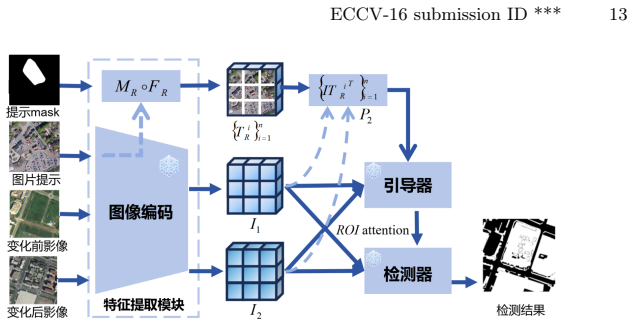
The OmniCD architecture, which integrates multimodal prompts with a hierarchical scene retrieval module and a style disentanglement mechanism to enhance cross-domain robustness.
If this is right
- OmniCD supports a spectrum of change detection tasks from binary to zero-shot semantic change understanding.
- The style disentanglement mechanism aims to improve performance when applied to new domains.
- The framework sets a foundation for building general-purpose change detection systems in remote sensing.
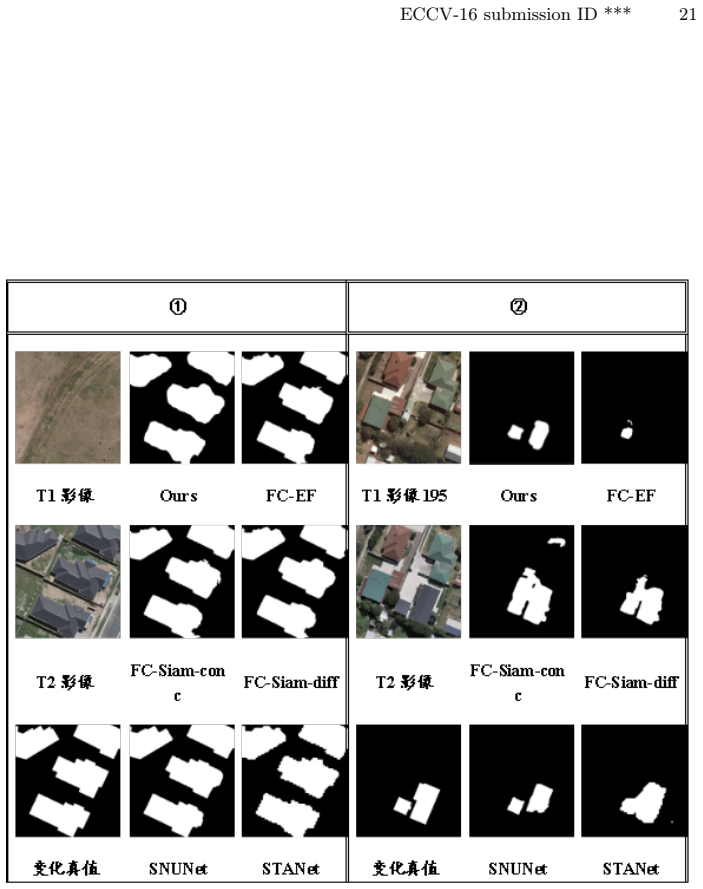
- Extensive experiments position it as state-of-the-art on existing benchmarks.
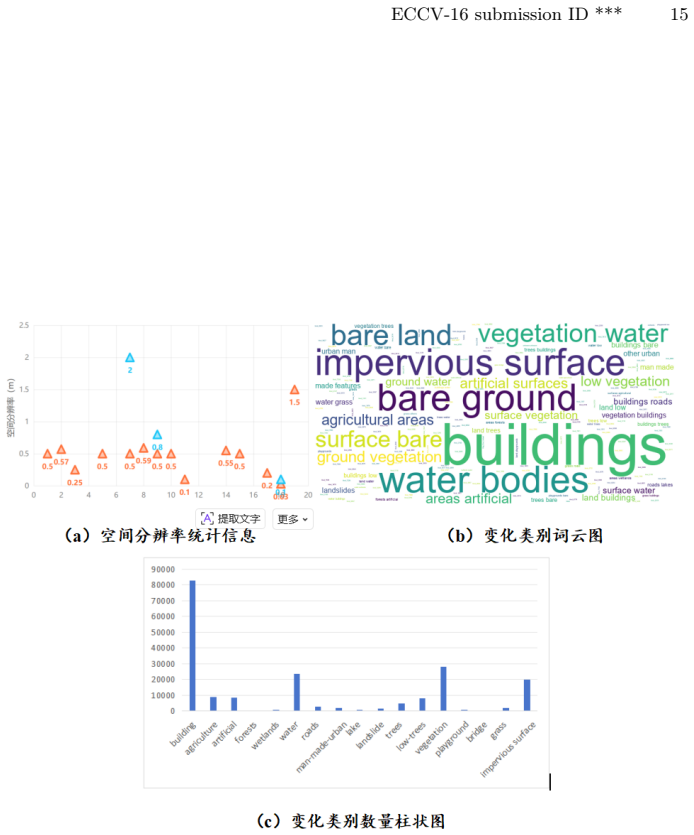
- RSITCD provides a large-scale resource with multimodal annotations for future work.
Where Pith is reading between the lines
- The approach could allow users to query changes using natural language descriptions in addition to images.
- It may extend to real-time applications in urban planning by incorporating live geospatial metadata.
- Similar multimodal integration might apply to other image analysis tasks beyond change detection.
- Further testing on diverse disaster scenarios could validate its adaptability claims.
Load-bearing premise
That adding multimodal prompts, hierarchical retrieval, and style disentanglement will produce better generalization and robustness than prior methods in varied remote sensing conditions.
What would settle it
A controlled test on a held-out remote sensing dataset from a completely different geographic region or sensor type where OmniCD does not outperform current leading methods.
Figures







read the original abstract
Change detection (CD) in remote sensing is vital for applications such as urban monitoring and disaster assessment, yet traditional methods struggle with generalization across diverse scenarios. We present OmniCD, a foundational framework that unifies and enhances remote sensing CD through multimodal semantic guidance. OmniCD incorporates image and text prompts -- such as textual descriptions, semantic maps, and geospatial metadata -- into a unified architecture, supporting tasks from binary CD to zero-shot semantic change understanding. The framework integrates a hierarchical scene retrieval module and a change detection module, reinforced by a style disentanglement mechanism for improved cross-domain robustness. We further introduce RSITCD, a large-scale multimodal dataset with 300K+ annotated image-text pairs. Extensive experiments show that OmniCD achieves state-of-the-art performance across benchmarks, demonstrating strong adaptability and setting a solid foundation for general-purpose CD systems in remote sensing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OmniCD as a foundational framework for remote sensing image change detection that incorporates multimodal semantic guidance through image and text prompts. It features a hierarchical scene retrieval module, a change detection module, and a style disentanglement mechanism to enhance cross-domain robustness. The authors introduce the RSITCD dataset containing over 300,000 annotated image-text pairs and report that OmniCD achieves state-of-the-art performance across multiple benchmarks, supporting tasks ranging from binary change detection to zero-shot semantic change understanding.
Significance. Should the claims be validated with rigorous experiments and ablations, this work has the potential to establish a new paradigm for general-purpose change detection systems in remote sensing by leveraging multimodal inputs for better generalization. The release of a large-scale multimodal dataset could also facilitate future research in the field.
major comments (2)
- Abstract: the central claim that the hierarchical scene retrieval module combined with style disentanglement and multimodal prompts delivers improved cross-domain robustness and SOTA performance is presented without ablation results, cross-domain train/test splits, or quantitative comparisons isolating these components' contributions. This prevents attribution of any gains to the proposed modules rather than dataset scale or standard training.
- Abstract: no methods, implementation details for the style disentanglement or retrieval modules, performance metrics, error bars, or experimental setup are provided, rendering the soundness of the SOTA and adaptability claims unevaluable.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to address these points. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim that the hierarchical scene retrieval module combined with style disentanglement and multimodal prompts delivers improved cross-domain robustness and SOTA performance is presented without ablation results, cross-domain train/test splits, or quantitative comparisons isolating these components' contributions. This prevents attribution of any gains to the proposed modules rather than dataset scale or standard training.
Authors: We agree that the abstract, as a concise summary, does not itself contain the ablation results, cross-domain splits, or isolating comparisons. The full manuscript presents these analyses in the Experiments section to attribute gains to the proposed modules. We will revise the abstract to note that supporting quantitative evidence and ablations appear in the main text. revision: yes
-
Referee: Abstract: no methods, implementation details for the style disentanglement or retrieval modules, performance metrics, error bars, or experimental setup are provided, rendering the soundness of the SOTA and adaptability claims unevaluable.
Authors: We agree that the abstract omits these specifics, which is conventional for the format. The manuscript details the methods, implementation, metrics with error bars, and setup in the Methods and Experiments sections. We will revise the abstract to reference the experimental validation supporting the claims. revision: yes
Circularity Check
No circularity: framework claims rest on empirical results without self-referential derivations
full rationale
The paper introduces OmniCD as a multimodal framework for remote sensing change detection, describing components such as hierarchical scene retrieval, style disentanglement, and multimodal prompts, along with a new dataset RSITCD. No equations, parameter-fitting procedures, or derivation chains appear in the abstract or description. Performance claims are stated as outcomes of extensive experiments rather than predictions derived from fitted inputs or self-definitions. No self-citations are used to justify uniqueness theorems or ansatzes. The central assertions about cross-domain robustness are presented as design motivations supported by results, not as reductions equivalent to the inputs by construction. This satisfies the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Geoscience and Remote Sensing Letters14(5) (2017) 778–782
Kussul, N., Lavreniuk, M., Skakun, S., et al.: Deep learning classification of land cover and crop types using remote sensing data. IEEE Geoscience and Remote Sensing Letters14(5) (2017) 778–782
2017
-
[2]
Remote Sensing14(10) (2022) 2385
Li, Z., Wang, Y., Zhang, N., et al.: Deep learning based object detection techniques for remote sensing images: A survey. Remote Sensing14(10) (2022) 2385
2022
-
[3]
arXiv preprint arXiv:submit/4812508 [cs.CL] (2023)
OpenAI: Gpt-4 technical report. arXiv preprint arXiv:submit/4812508 [cs.CL] (2023)
-
[4]
Li, J., Li, D., Xiong, C., et al.: Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation. arXiv preprint arXiv:2201.12086v2 [cs.CV] (2022)
-
[5]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE (2023) 3992–4003
Alexander, K., Eric, M., Nikhila, R., et al.: Segment anything. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE (2023) 3992–4003
2023
-
[6]
International Journal of Remote Sensing29(16) (2008) 4823–4838
Deng, J., Wang, K., Deng, Y., et al.: Pca-based land-use change detection and analysis using multitemporal and multisensor satellite data. International Journal of Remote Sensing29(16) (2008) 4823–4838
2008
-
[7]
IEEE Geoscience and Remote Sensing Letters8(4) (2011) 799–803
Marpu, P., Gamba, P., Canty, M.: Improving change detection results of ir-mad by eliminating strong changes. IEEE Geoscience and Remote Sensing Letters8(4) (2011) 799–803
2011
-
[8]
Interna- tional Journal of Remote Sensing33(14) (2012) 4434–4457
Chen, G., Hay, G., Carvalho, L., et al.: Object-based change detection. Interna- tional Journal of Remote Sensing33(14) (2012) 4434–4457
2012
-
[9]
ISPRS Journal of Photogrammetry and Remote Sensing58(3-4) (2004) 225–238
Walter, V.: Object-based classification of remote sensing data for change detection. ISPRS Journal of Photogrammetry and Remote Sensing58(3-4) (2004) 225–238
2004
-
[10]
In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Springer (2015) 234–241
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Springer (2015) 234–241
2015
-
[11]
Remote Sensing12(10) (2020) 1662
Chen, H., Shi, Z.: A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sensing12(10) (2020) 1662
2020
-
[12]
IEEE Geoscience and Remote Sensing Letters 19(2021) 1–5
Fang, S., Li, K., Shao, J., et al.: Snunet-cd: A densely connected siamese network for change detection of vhr images. IEEE Geoscience and Remote Sensing Letters 19(2021) 1–5
2021
-
[13]
In: The Thirteenth Interna- tional Conference on Learning Representations (ICLR)
Kolesnikov, V., Dosovitskiy, A., Weissenborn, D., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: The Thirteenth Interna- tional Conference on Learning Representations (ICLR). (2021)
2021
-
[14]
IEEE Transactions on Geoscience and Remote Sensing60(2022) 1–14
Chen,H.,Qi,Z.,Shi,Z.: Remotesensingimagechangedetectionwithtransformers. IEEE Transactions on Geoscience and Remote Sensing60(2022) 1–14
2022
-
[15]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing15(2022) 4297–4306
Liu, M., Chai, Z., Deng, H., et al.: A cnn-transformer network with multiscale context aggregation for fine-grained cropland change detection. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing15(2022) 4297–4306
2022
-
[16]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2022) 15979–15988
He, K., Chen, X., Xie, S., et al.: Masked autoencoders are scalable vision learners. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2022) 15979–15988
2022
-
[17]
In: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), IEEE (2021) 9394–9403
Mañas, O., Lacoste, A., Giró-i Nieto, X., et al.: Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), IEEE (2021) 9394–9403
2021
-
[18]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2023) 5161–5270 ECCV-16 submission ID *** 29
Mall, U., Hariharan, B., Bala, K.: Change-aware sampling and contrastive learning for satellite images. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2023) 5161–5270 ECCV-16 submission ID *** 29
2023
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(8) (2024) 5227–5244
Hong, D., Zhang, B., Li, X., et al.: Spectralgpt: Spectral remote sensing foundation model. IEEE Transactions on Pattern Analysis and Machine Intelligence46(8) (2024) 5227–5244
2024
-
[20]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2024) 27662–27673
Guo, X., Lao, J., Dang, B., et al.: Skysense: A multi-modal remote sensing founda- tion model towards universal interpretation for earth observation imagery. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE (2024) 27662–27673
2024
-
[21]
arXiv preprint arXiv:2307.15266 [cs.CV] (2023)
Hu, Y., Yuan, J., Wen, C., et al.: Rsgpt: A remote sensing vision language model and benchmark. arXiv preprint arXiv:2307.15266 [cs.CV] (2023)
-
[22]
IEEE Transactions on Geoscience and Remote Sensing 62(2024) 1–16
Liu, F., Chen, D., Guan, Z., et al.: Remoteclip: A vision language foundation model for remote sensing. IEEE Transactions on Geoscience and Remote Sensing 62(2024) 1–16
2024
-
[23]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kuckreja, K., Danish, M., Naseer, M., et al.: Geochat: Grounded large vision- language model for remote sensing. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (2024) 27831–27840
2024
-
[24]
arXiv preprint arXiv:2312.06960 [cs.CV] (2023)
Mall, U., Phoo, C., Liu, M., et al.: Remote sensing vision-language founda- tion models without annotations via ground remote alignment. arXiv preprint arXiv:2312.06960 [cs.CV] (2023)
-
[25]
arXiv preprint arXiv:2309.16020 [cs.CV] (2023)
Cepeda, V., Nayak, G., Shah, M.: Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization. arXiv preprint arXiv:2309.16020 [cs.CV] (2023)
-
[26]
arXiv preprint arXiv:2311.17179 [cs.CV] (2023)
Klemmer, K., Rolf, E., Robinson, C., et al.: Satclip: Global, general-purpose loca- tion embeddings with satellite imagery. arXiv preprint arXiv:2311.17179 [cs.CV] (2023)
-
[27]
arXiv preprint arXiv:2312.03606 [cs.CV] (2024)
Khanna, S., Liu, P., Zhou, L., et al.: Diffusionsat: A generative foundation model for satellite imagery. arXiv preprint arXiv:2312.03606 [cs.CV] (2024)
-
[28]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M., Lee, K., et al.: Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12) (2024) 9677– 9696
Wang, X., Chen, H., Tang, S., et al.: Disentangled representation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12) (2024) 9677– 9696
2024
-
[30]
In: 2017 IEEE International Conference on Computer Vision (ICCV), IEEE (2017) 1510–1519
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive in- stance normalization. In: 2017 IEEE International Conference on Computer Vision (ICCV), IEEE (2017) 1510–1519
2017
-
[31]
Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Ma, X., Dong, H., Gao, P., and Li, H
Zhang, R., Jiang, Z., Guo, Z., et al.: Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048 [cs.CV] (2023)
-
[32]
In: 2018 25th IEEE International Conference on Image Process- ing (ICIP), IEEE (2018) 4063–4067
Daudt, R., Le Saux, B., Boulch, A.: Fully convolutional siamese networks for change detection. In: 2018 25th IEEE International Conference on Image Process- ing (ICIP), IEEE (2018) 4063–4067
2018
-
[33]
In: IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Sympo- sium, IEEE (2024) 8577–8580
Tan, X., Chen, G., Wang, T., et al.: Segment change model (scm) for unsuper- vised change detection in vhr remote sensing images: A case study of buildings. In: IGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Sympo- sium, IEEE (2024) 8577–8580
2024
-
[34]
In: 38th Conference on Neural Information Processing Systems (NeurIPS)
Zheng, Z., Zhong, Y., Zhang, L., et al.: Segment any change. In: 38th Conference on Neural Information Processing Systems (NeurIPS). (2024)
2024
-
[35]
Remote Sensing Letters5(8) (2014) 713–722
Huang, X., Zhu, T., Zhang, L., et al.: A novel building change index for automatic building change detection from high-resolution remote sensing imagery. Remote Sensing Letters5(8) (2014) 713–722
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.