Mitigating Provenance-Role Collapse in Long-Term Agents via Typed Memory Representation
Pith reviewed 2026-06-29 21:12 UTC · model grok-4.3
The pith
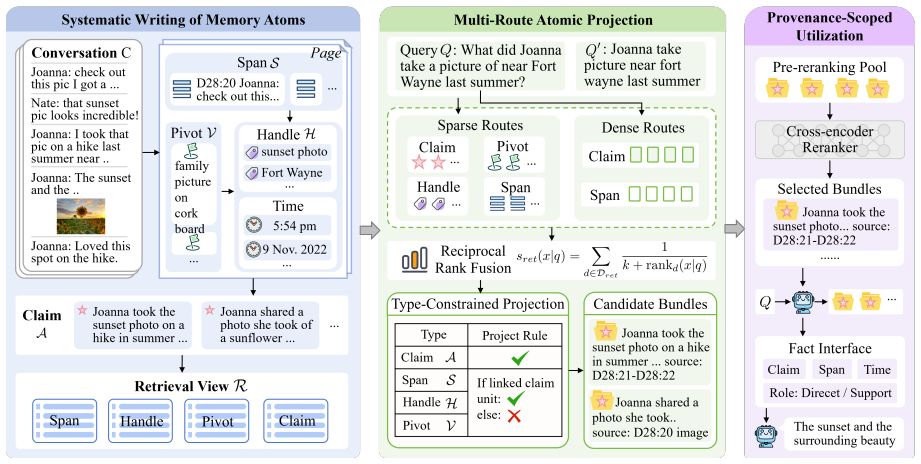
MemIR stores long-term agent memory as typed atoms separating evidence, cues, and claims to enforce source monitoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
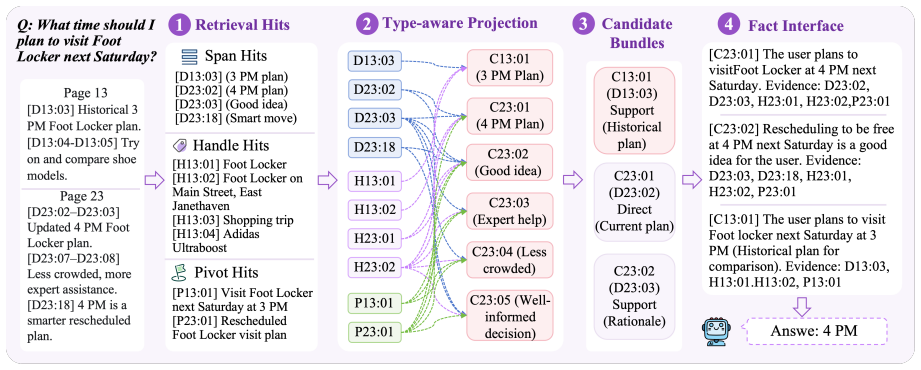
MemIR writes long-term memory into grounded atoms that separate raw evidence, retrieval cues, and truth-bearing claims, with factual authorization restricted to supported claim atoms. It applies multi-route atomic projection and provenance-scoped utilization to transform heterogeneous retrieval hits into claim-centered candidate bundles and a normalized fact interface for answer generation.
What carries the argument
MemIR, a typed Memory Intermediate Representation that operationalizes source monitoring as a structural constraint by writing memory into atoms separating raw evidence, retrieval cues, and truth-bearing claims.
If this is right
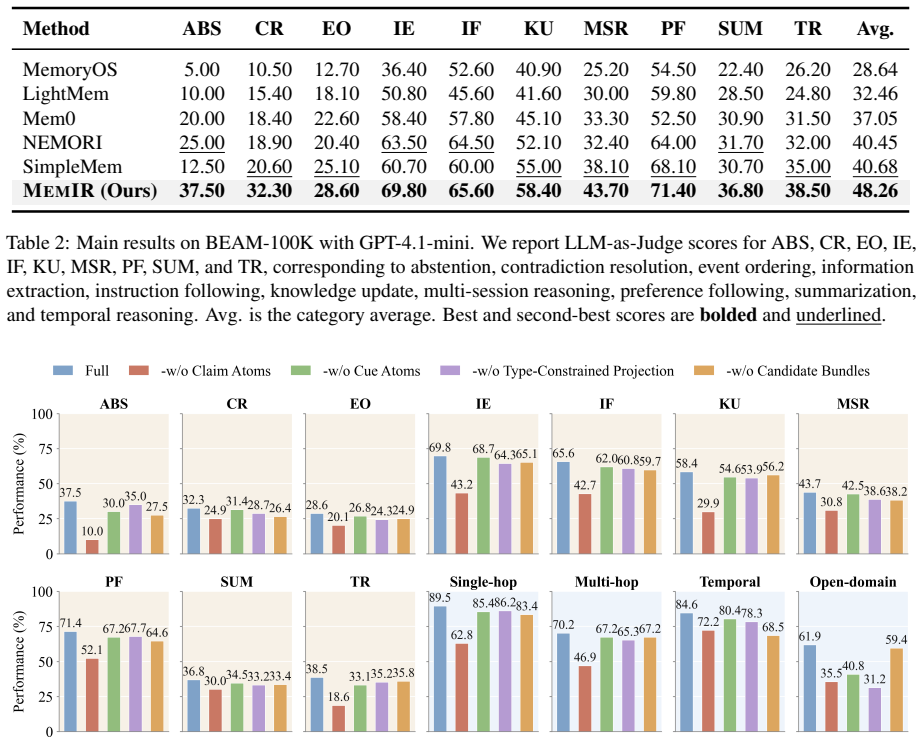
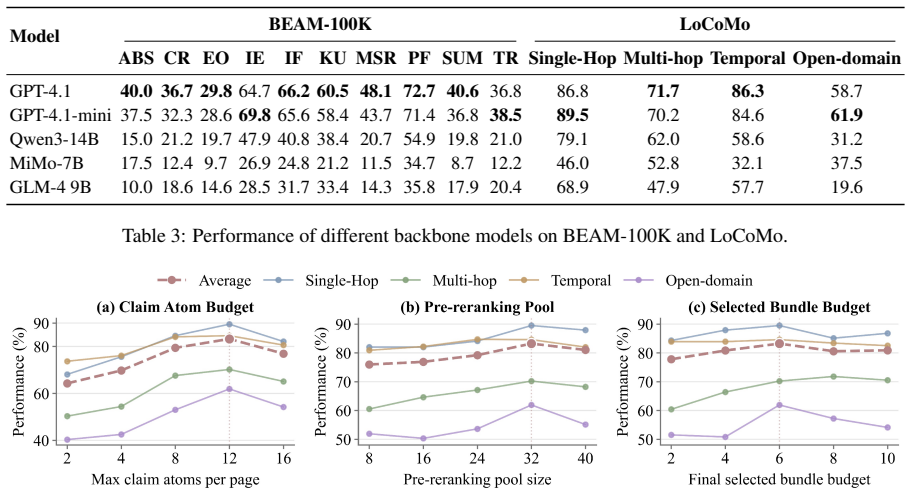
- Agents using MemIR outperform existing memory baselines on LoCoMo and BEAM-100K.
- Performance gains are largest on tasks requiring source tracking.
- The approach improves temporal grounding and aggregation of fragmented evidence.
- Retrieval hits are transformed into claim-centered bundles with a normalized fact interface.
Where Pith is reading between the lines
- Similar structural typing could address other agent failure modes beyond source errors.
- The method implies memory architecture changes may substitute for some post-training fixes.
- Extensions could test whether additional atom types handle dynamic or conflicting provenance.
Load-bearing premise
Provenance-role collapse is caused primarily by unstructured flat text storage and can be resolved by introducing typed atoms without new failure modes.
What would settle it
A controlled test on source-tracking tasks where MemIR agents exhibit source-monitoring error rates comparable to flat-text baselines despite the typed structure.
Figures

read the original abstract
Long-term memory is essential for persistent LLM agents, yet prevailing architectures store historical interactions as unstructured, flat text. This unconstrained storage induces provenance-role collapse, a critical failure mode where agents suffer from source-monitoring errors. To resolve this cognitive vulnerability at the architectural level, we propose MemIR, a typed Memory Intermediate Representation that operationalizes source monitoring as a structural constraint. MemIR writes long-term memory into grounded atoms that separate raw evidence, retrieval cues, and truth-bearing claims, with factual authorization restricted to supported claim atoms. It then applies multi-route atomic projection and provenance-scoped utilization to transform heterogeneous retrieval hits into claim-centered candidate bundles and a normalized fact interface for answer generation. Experiments on LoCoMo and BEAM-100K demonstrate that MemIR consistently outperforms existing memory baselines, especially on tasks requiring source tracking, temporal grounding, and aggregation of fragmented evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that unstructured flat-text storage in long-term LLM agent memory induces provenance-role collapse (source-monitoring errors). It proposes MemIR, a typed Memory Intermediate Representation that writes memory as grounded atoms separating raw evidence, retrieval cues, and truth-bearing claims (with factual authorization restricted to supported claim atoms), applies multi-route atomic projection and provenance-scoped utilization to produce claim-centered bundles, and reports consistent outperformance over memory baselines on source-tracking, temporal-grounding, and evidence-aggregation tasks in the LoCoMo and BEAM-100K benchmarks.
Significance. If the empirical gains are robust, the structural (rather than heuristic) treatment of source monitoring could provide a reusable architectural primitive for reliable long-term agents; the design is presented as parameter-free and directly falsifiable via the cited external benchmarks.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of consistent outperformance is stated without any numerical results, baselines, or error bars; the manuscript must supply the quantitative tables or figures that support the headline result before the claim can be evaluated.
- [§3] §3 (MemIR definition): the claim that factual authorization is 'restricted to supported claim atoms' is load-bearing for the provenance-role-collapse mitigation argument, yet the precise authorization predicate and its interaction with multi-route projection are not formalized; an explicit definition or pseudocode is required to confirm the constraint is architectural rather than post-hoc.
minor comments (2)
- Define all acronyms (MemIR, LoCoMo, BEAM-100K) on first use and ensure consistent notation for atom types across sections.
- Add a limitations paragraph discussing whether the typed-atom representation introduces new retrieval latency or memory-overhead costs not present in flat-text baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of consistent outperformance is stated without any numerical results, baselines, or error bars; the manuscript must supply the quantitative tables or figures that support the headline result before the claim can be evaluated.
Authors: We agree that the headline claim requires explicit quantitative backing. The current abstract summarizes results qualitatively for brevity, while §4 contains the supporting tables. We will revise the abstract to include key metrics (e.g., accuracy deltas on source-tracking tasks) and ensure all tables in §4 display baselines, mean performance, and error bars with clear captions. revision: yes
-
Referee: [§3] §3 (MemIR definition): the claim that factual authorization is 'restricted to supported claim atoms' is load-bearing for the provenance-role-collapse mitigation argument, yet the precise authorization predicate and its interaction with multi-route projection are not formalized; an explicit definition or pseudocode is required to confirm the constraint is architectural rather than post-hoc.
Authors: This observation is correct; the current description relies on prose. We will add an explicit formal definition of the authorization predicate (as a boolean function over atom types and provenance tags) together with pseudocode showing its enforcement during multi-route atomic projection and bundle construction in the revised §3. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces MemIR as a new typed memory architecture that separates evidence, cues, and claims via structural constraints, then evaluates the design empirically on external benchmarks LoCoMo and BEAM-100K. No load-bearing equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description; the central claim rests on the architectural proposal plus benchmark results rather than any reduction to its own inputs by construction. The derivation is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Source monitoring errors in agents are primarily due to unstructured memory storage.
invented entities (3)
-
MemIR
no independent evidence
-
claim atoms
no independent evidence
-
multi-route atomic projection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970
Memory OS of AI agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25961–25970. Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. 2024. A human-inspired reading agent with gist memory of very long contexts. InInternational Conference on Machine Learning, pages 26396–26415. Patrick ...
2025
-
[2]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Simplemem: Efficient lifelong memory for LLM agents.arXiv preprint arXiv:2601.02553. Wenquan Ma, Jiayan Nan, Wenlong Wu, and Yize Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
What deserves memory: Adaptive memory distillation for LLM agents.arXiv e-prints, pages arXiv–2508. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
-
[4]
WebGPT: Browser-assisted question-answering with human feedback
Evaluating very long-term conversational 9 memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Association for Computational Linguistics. Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Ja...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
InThe Four- teenth International Conference on Learning Repre- sentations
Beyond a million tokens: Benchmarking and enhancing long-term memory in LLMs. InThe Four- teenth International Conference on Learning Repre- sentations. Anxin Tian, Yiming Li, Xing Li, Hui-Ling Zhen, Lei Chen, Xianzhi Yu, Zhenhua Dong, and Mingx- uan Yuan. 2026. SwiftMem: Fast agentic mem- ory via query-aware indexing.arXiv preprint arXiv:2601.08160. Nikh...
-
[6]
Beyond static summarization: Proactive mem- ory extraction for LLM agents.arXiv preprint arXiv:2601.04463. Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Ji- aqi Feng, Yaliang Li, and Libing Wu. 2026. Agen- tic memory: Learning unified long-term and short- term memory management for large language model agents.arXiv preprint arXiv:2601.01885. Ningning Zhan...
-
[7]
Decide whether the exact mention is worth keeping
-
[8]
Confirm it points to a specific local item in this page, not only a broad topic, domain, category, identity group, support relation, or life area
-
[9]
Confirm it would still be a useful name if shown alone in search results
-
[10]
Confirm it is noun-like rather than a clause or action snippet
-
[11]
Choose the shortest exact substring that preserves that mention and distinguishes the thing
-
[12]
Omit it if the mention is mainly a theme, value, feeling, identity expression, support phrase, or weak pointer, even when it is an exact substring
-
[13]
Omit it if it is a clause-like snippet, verb phrase, subject-verb snippet, speaking fragment, sentence fragment, or depends on words like this, that, these, those, my, your, or a generic the-phrase to identify the item
-
[14]
Omit it if shortening would turn it into a broad category, pronoun-like phrase, or bare generic noun
-
[15]
Output fields: - surface_text - support_span_ids Field rules: -`surface_text`must be copied exactly from one cited support span
Do not add weak or generic handles just to reach the usual quantity. Output fields: - surface_text - support_span_ids Field rules: -`surface_text`must be copied exactly from one cited support span. -`support_span_ids`must contain the span ids that ground the handle. Output shape: Return only a JSON object: {"handles": [...]}. Quantity: - Empty output is a...
-
[16]
Read the page and candidate list
-
[17]
Judge each candidate span before thinking about its label
-
[18]
Decide the candidate span's main meaning: does it record the external page item itself, or does it mainly explain meaning , feeling, value, identity expression, support effect, or why it matters?
-
[19]
Check that the accepted item is stated in the candidate span itself, not inferred from a concrete noun inside an 12 interpretation sentence
-
[20]
Keep candidates whose main job is to record a concrete external event, plan, object use, visit, creation, change, application, attendance, completion, or arrangement
-
[21]
Skip candidates that mainly express interpretation, reaction, aspiration, value, support effect, or identity expression
-
[22]
Group candidates that point to the same page item
-
[23]
Pick one best candidate for each page item
-
[24]
units": [ {
Emit pivots only for the selected candidates. Do not rescue a weak candidate by writing a more concrete referent_label. If the candidate span is mainly interpretation, reaction, aspiration, or value, skip it even when it contains a concrete noun. Do not rescue a meaning-focused sentence by turning a concrete noun or action inside it into the referent_labe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.