Assign and Add: A Mechanistic Study of Compositional Arithmetic
Pith reviewed 2026-06-28 22:55 UTC · model grok-4.3
The pith
Transformers reuse the same modular addition module for both direct numbers and those reached through variable assignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the same modular addition MLP module is invoked whether the inputs are supplied directly as numbers or are obtained indirectly after a separate variable assignment step has occurred. This shared circuit is what permits the model to generalize to novel pairings of variables and numbers that were withheld from the training distribution.
What carries the argument
The modular addition MLP module, which computes the arithmetic result and is shared between the direct-input path and the variable-assignment path.
If this is right
- Compositional generalization follows when internal circuits are reused rather than duplicated for each new combination of skills.
- Training proceeds through separable phases that first install the arithmetic operation, then the routing for assignment, and finally refine the integrated behavior.
- Generalization to sequences withheld from training emerges only after the refinement phase has aligned the shared module with the assignment pathway.
- Compositionality is a natural outcome of the compositionality already present inside the model's learned mechanisms.
Where Pith is reading between the lines
- The same reuse pattern could be searched for in other tasks that combine lookup or binding with subsequent computation, such as function application or simple logical inference.
- If the three-phase dynamic is robust, curricula that deliberately separate skill acquisition from integration might accelerate compositional learning in larger models.
- The theoretical framework could be tested by ablating the refinement phase and checking whether generalization to hard sequences collapses while basic addition remains intact.
- Scaling the setting to deeper networks might reveal whether additional circuits are recruited or whether the same modular addition module continues to be reused.
Load-bearing premise
The controlled toy task of variable assignment followed by modular addition in small transformers captures the mechanisms that produce compositional generalization in large models trained on natural data.
What would settle it
Finding two functionally distinct MLP modules, one used only for direct addition and another used only after variable lookup, in a replication of the same architecture and data split would falsify the reuse claim.
Figures



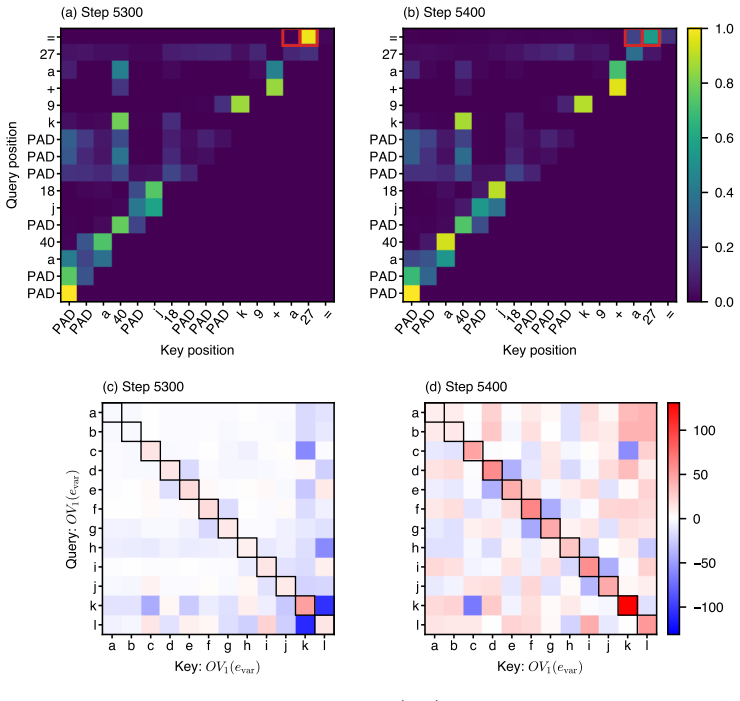
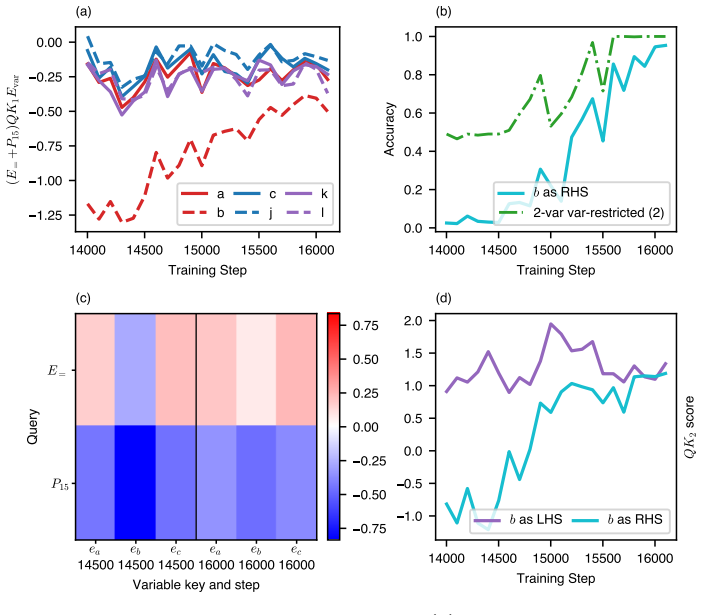


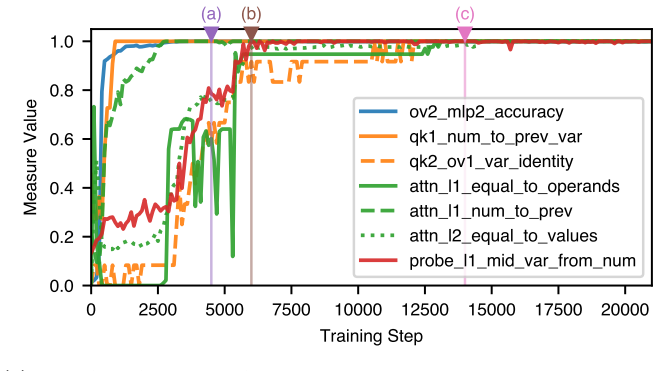
read the original abstract
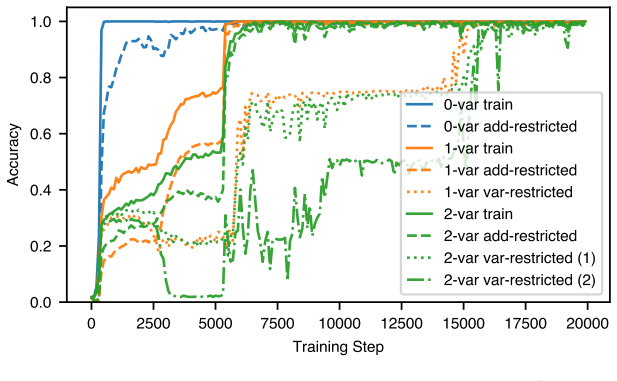
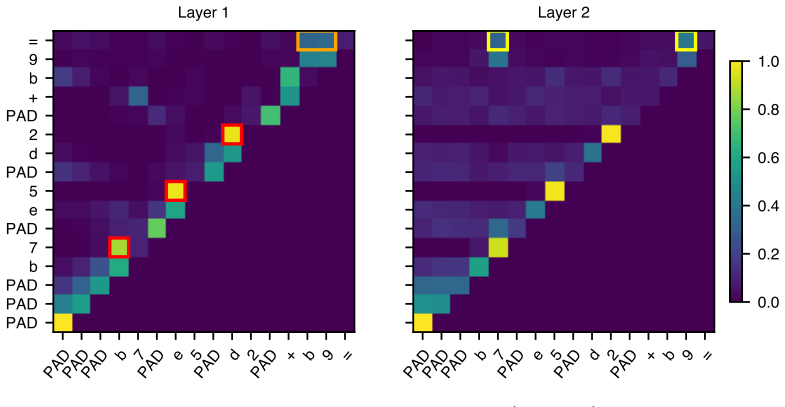
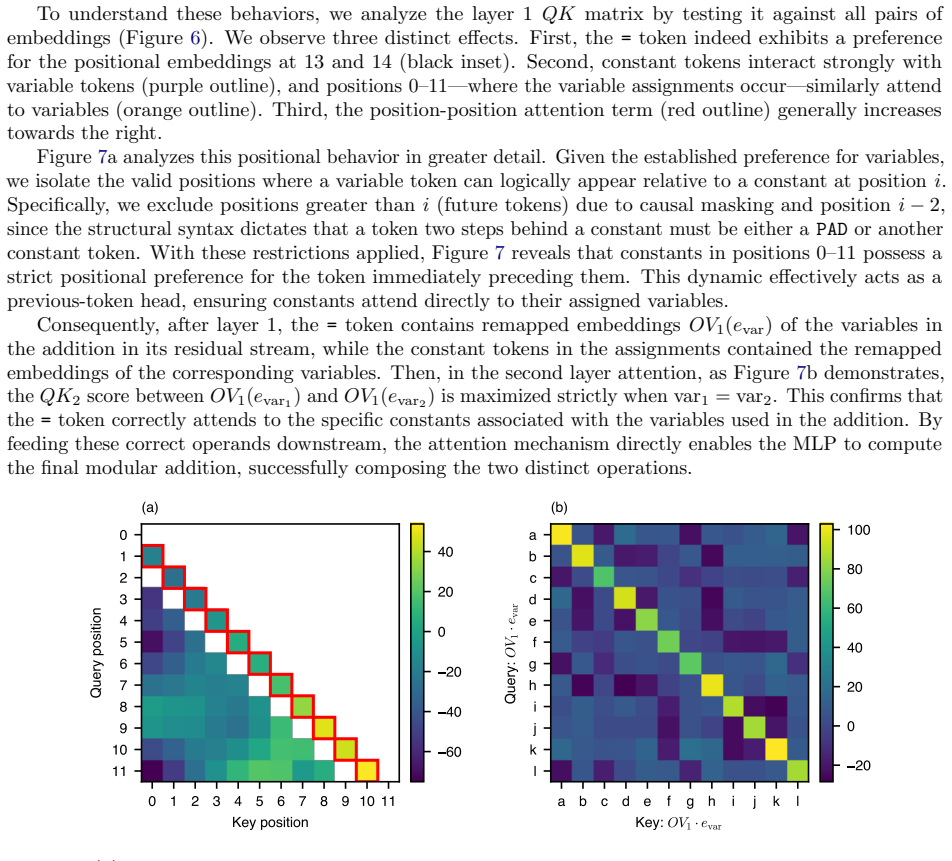
Large language models are able to compose skills in order to perform complex tasks, many of which might not have been seen during training. The details of how exactly this composition occurs remain elusive. In this paper, we study a mechanism for compositional generalization in transformers by considering a simple controlled setting involving variable assignment and modular addition. By partitioning our training data into disjoint sets, we observe that small transformers are able to generalize to previously unseen combinations of variables and numbers. Our mechanistic analysis shows that the same ``modular addition'' MLP module is used whether the inputs are given directly or indirectly through a separate variable assignment mechanism. We also analyze the training dynamics from an empirical lens, which reveals three phases of learning: first, modular addition is learned, then the structure required for variable assignment, and finally a refinement phase where the model generalizes to some hard sequences not seen in training. Finally, we provide a theoretical framework to explain how compositionality emerges from training dynamics. These results suggest that compositional generalization can be a natural consequence of the compositionality of internal mechanisms in~transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines compositional generalization in small transformers trained on a controlled task of variable assignment followed by modular addition. By partitioning the training data into disjoint sets, the models generalize to unseen combinations of variables and numbers. Mechanistic analysis indicates that the same modular addition MLP module is reused for both direct numeric inputs and inputs routed through a learned variable assignment circuit. Training dynamics reveal three phases—learning modular addition, acquiring variable assignment structure, and a refinement phase enabling generalization to hard sequences—with a theoretical framework proposed to explain how compositionality emerges from these dynamics.
Significance. If the central claims hold, the work offers a concrete mechanistic example of module reuse enabling compositional generalization in transformers within a simplified arithmetic setting. The empirical identification of three training phases and the accompanying theoretical framework provide useful insights into how compositionality can arise naturally from training dynamics. The controlled experimental design and focus on mechanistic inspection are strengths that allow clear observation of the reuse phenomenon.
major comments (1)
- [Mechanistic Analysis] The claim that the identical modular addition MLP is reused for direct and assigned inputs (abstract and mechanistic analysis section) requires explicit quantification of the evidence, such as activation similarity metrics, weight cosine similarities, or results from causal interventions like activation patching; without these details the reuse conclusion rests on qualitative inspection alone.
minor comments (2)
- Provide the precise definition of the data partitioning scheme and the criteria used to identify 'hard sequences' in the refinement phase.
- The theoretical framework would be strengthened by including explicit equations or a pseudocode description of the proposed dynamics.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation of minor revision. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Mechanistic Analysis] The claim that the identical modular addition MLP is reused for direct and assigned inputs (abstract and mechanistic analysis section) requires explicit quantification of the evidence, such as activation similarity metrics, weight cosine similarities, or results from causal interventions like activation patching; without these details the reuse conclusion rests on qualitative inspection alone.
Authors: We agree that the current mechanistic analysis relies primarily on qualitative inspection of circuit components and would benefit from quantitative support. In the revised manuscript we will add cosine similarity between the relevant MLP weight matrices, Pearson correlation of activations on matched inputs, and activation patching results showing that ablating the modular addition MLP produces comparable performance drops on both direct and variable-assigned test cases. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical mechanistic interpretability study on a controlled toy task involving variable assignment and modular addition in small transformers. Claims rest on observations from partitioned training data, direct inspection of MLP modules, and training dynamics across phases, with no mathematical derivations, first-principles predictions, or equations that reduce to fitted inputs by construction. The theoretical framework is presented as an explanation of observed dynamics rather than a self-referential definition or load-bearing self-citation chain. No steps match the enumerated circularity patterns, making the derivation chain self-contained within the experimental setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The simple controlled task of variable assignment plus modular addition reflects the essential mechanisms of compositional generalization in transformers.
Reference graph
Works this paper leans on
-
[1]
Lake and Marco Baroni
Brenden M. Lake and Marco Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[2]
COGS: A compositional generalization challenge based on semantic interpretation
Najoung Kim and Tal Linzen. COGS: A compositional generalization challenge based on semantic interpretation. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[3]
Smith, and Mike Lewis
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics (EMNLP), 2023
2023
-
[4]
Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Za¨ ıd Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Za¨ ıd Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compositionality. InAdvances in Neural Information Processing Systems (N...
2023
-
[5]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
2021
-
[6]
In-context learning and induction heads.Transformer Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield- Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, ...
2022
-
[7]
Birth of a transformer: A memory viewpoint
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herv´ e J´ egou, and L´ eon Bottou. Birth of a transformer: A memory viewpoint. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[8]
The mechanistic basis of data dependence and abrupt learning in an in-context classification task
Gautam Reddy. The mechanistic basis of data dependence and abrupt learning in an in-context classification task. InInternational Conference on Learning Representations (ICLR), 2024. 10
2024
-
[9]
Eshaan Nichani, Alex Damian, and Jason D. Lee. How transformers learn causal structure with gradient descent. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[10]
Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022
2022
-
[11]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[12]
Grokking modular arithmetic, 2023
Andrey Gromov. Grokking modular arithmetic, 2023
2023
-
[13]
On the mechanism and dynamics of modular addition: Fourier features, lottery ticket, and grokking, 2026
Jianliang He, Leda Wang, Siyu Chen, and Zhuoran Yang. On the mechanism and dynamics of modular addition: Fourier features, lottery ticket, and grokking, 2026
2026
-
[14]
Inter- pretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Inter- pretability in the wild: a circuit for indirect object identification in GPT-2 small. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[15]
How does GPT-2 compute greater-than?: Inter- preting mathematical abilities in a pre-trained language model
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does GPT-2 compute greater-than?: Inter- preting mathematical abilities in a pre-trained language model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[16]
Circuit tracing: Revealing computational graphs in language models.Transformer Circuits Thread, 6:16318–16352, 2025
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, et al. Circuit tracing: Revealing computational graphs in language models.Transformer Circuits Thread, 6:16318–16352, 2025
2025
-
[17]
Unveiling transformers with lego: A synthetic reasoning task.arXiv preprint arXiv:2206.04301,
Yi Zhang, Arturs Backurs, S´ ebastien Bubeck, Ronen Eldan, Suriya Gunasekar, and Tal Wagner. Unveiling transformers with lego: a synthetic reasoning task.arXiv preprint arXiv:2206.04301, 2022
-
[18]
Transformers learn shortcuts to automata
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[19]
Discovering variable binding circuitry with desiderata
Xander Davies, Max Nadeau, Nikhil Prakash, Tamar Rott Shaham, and David Bau. Discovering variable binding circuitry with desiderata. ICML 2023 Workshop on Deployable Generative AI, 2023
2023
-
[20]
Dick, and Hidenori Tanaka
Rahul Ramesh, Ekdeep Singh Lubana, Mikail Khona, Robert P. Dick, and Hidenori Tanaka. Compositional capabilities of autoregressive transformers: A study on synthetic, interpretable tasks. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[21]
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
Tianyu He, Darshil Doshi, Aritra Das, and Andrey Gromov. Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
arXiv preprint arXiv:2505.20896 , year=
Yiwei Wu, Atticus Geiger, and Rapha¨ el Milliere. How do transformers learn variable binding in symbolic programs?arXiv preprint arXiv:2505.20896, 2025
-
[23]
Shattered compositionality: Counter- intuitive learning dynamics of transformers for arithmetic, 2026
Xingyu Zhao, Darsh Sharma, Rheeya Uppaal, and Yiqiao Zhong. Shattered compositionality: Counter- intuitive learning dynamics of transformers for arithmetic, 2026
2026
-
[24]
Transformers learn in-context by gradient descent
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo˜ ao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, (ICML), 2023
2023
-
[25]
Iteration head: A mechanistic study of chain-of-thought
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Yang, Fran¸ cois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[26]
Composing global solutions to reasoning tasks via algebraic objects in neural nets, 2025
Yuandong Tian. Composing global solutions to reasoning tasks via algebraic objects in neural nets, 2025. 11
2025
-
[27]
Alternating gradient flows: A theory of feature learning in two-layer neural networks
Daniel Kunin, Giovanni Luca Marchetti, Feng Chen, Dhruva Karkada, James B Simon, Michael R DeWeese, Surya Ganguli, and Nina Miolane. Alternating gradient flows: A theory of feature learning in two-layer neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2026
2026
-
[28]
Lee, and Denny Wu
Zixuan Wang, Eshaan Nichani, Alberto Bietti, Alex Damian, Daniel Hsu, Jason D. Lee, and Denny Wu. Learning compositional functions with transformers from easy-to-hard data. InAnnual Conference on Learning Theory (COLT), 2025
2025
-
[29]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[30]
Analyzing transformers in embedding space
Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant. Analyzing transformers in embedding space. InFindings of the Association for Computational Linguistics (ACL), 2023
2023
-
[31]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019
2019
-
[32]
Transformerlens
Neel Nanda and Joseph Bloom. Transformerlens. https://github.com/TransformerLensOrg/ TransformerLens, 2022
2022
-
[33]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[34]
Edelman, Costin-Andrei Oncescu, Rosie Zhao, and Sham M
Depen Morwani, Benjamin L. Edelman, Costin-Andrei Oncescu, Rosie Zhao, and Sham M. Kakade. Feature emergence via margin maximization: case studies in algebraic tasks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[35]
cleaning up
Dan Friedman, Alexander Wettig, and Danqi Chen. Learning transformer programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. A Additional Experimental Results Figure 10 shows the accuracies by evaluation set for another training run with the same parameters. The same “spikes” in non-var-restricted and var-restricted accuracies seen ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.