MIRAI: Prediction and Generation of High-Impact Academic Research
Pith reviewed 2026-06-28 02:25 UTC · model grok-4.3
The pith
A deep learning model predicts a paper's future PageRank and citations using only its title, abstract, and date.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
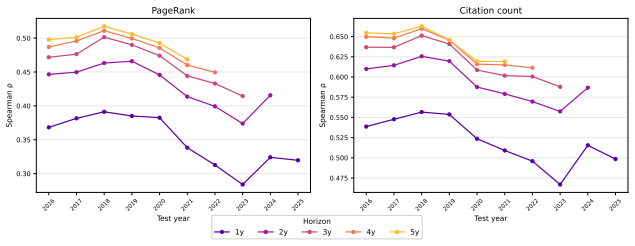
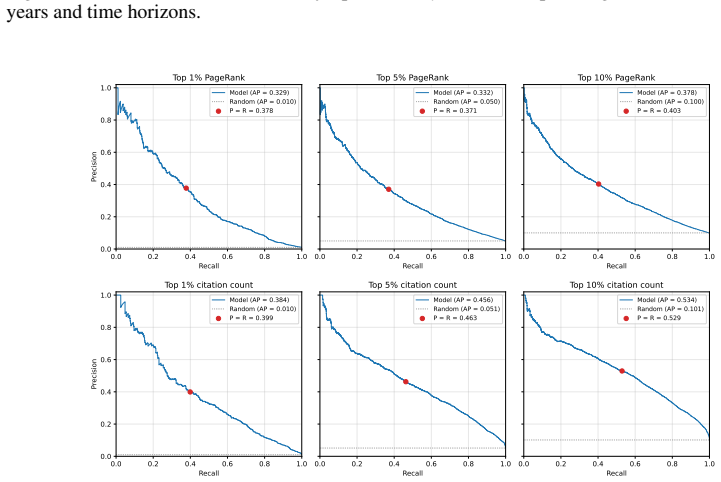
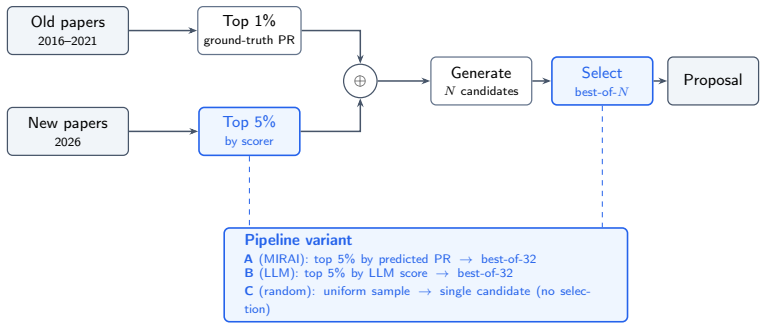
MIRAI predicts 5-year PageRank and citation counts for papers using only title, abstract, and publication date, with Spearman's ρ of 0.4686 and 0.6192 on 2021 publications. Its research ideation pipeline generates ideas rated higher impact than baseline by an LLM judge at a 4:3 ratio.
What carries the argument
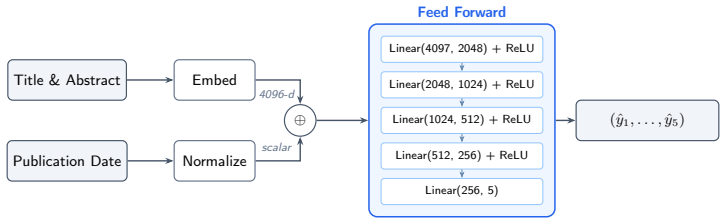
The MIRAI deep learning model that maps title, abstract, and date to predicted PageRank and citation impact, enabling both forecasting and guided idea generation.
If this is right
- Models can estimate long-term influence before a paper is written or published.
- The public citation prediction model allows anyone to assess potential impact.
- Research ideation can be steered toward topics likely to have higher future citations and influence.
- Prediction accuracy may improve with more data or refined architectures.
Where Pith is reading between the lines
- If widely adopted, such models might influence what research gets funded or pursued.
- Actual 5-year outcomes for recent papers could validate or refute the correlations.
- Human expert validation of the LLM judge would strengthen or weaken the ideation results.
- Similar approaches could apply to other domains like patents or technical reports.
Load-bearing premise
Title, abstract, and date contain enough information to predict long-term impact, and an LLM judge can fairly assess research idea impact without further validation.
What would settle it
Track the actual 5-year PageRank and citation counts for papers published in 2021 or later and compare them directly to MIRAI's predictions; if correlations drop substantially below reported values, the claim fails.
Figures

read the original abstract
The rapid pace of scientific publishing has made the identification and synthesis of high-impact work an increasingly urgent challenge. We introduce MIRAI (Multi-year Inference of Research trends and Academic Impact), a deep learning framework that predicts paper impact using only it's title, abstract, and publication date. We train MIRAI on the arXiv academic graph to predict 5-year PageRank and citation counts, achieving Spearman's $\rho$ of 0.4686 on PageRank prediction and 0.6192 on citation prediction for papers published in 2021. We propose a research ideation pipeline built on top of MIRAI that produces research ideas oriented towards high impact. These ideas were judged as more impactful than a baseline without MIRAI by an unbiased LLM judge at a 4:3 ratio. We make the 5-year citation prediction model publicly available at https://predict-paper-impact.vercel.app.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIRAI, a deep learning framework that predicts 5-year PageRank and citation counts of papers using only title, abstract, and publication date. Trained on the arXiv academic graph, it reports Spearman's ρ of 0.4686 for PageRank prediction and 0.6192 for citation prediction on 2021 papers. It further describes a research ideation pipeline that generates ideas oriented toward high impact, which an LLM judge rates as superior to a baseline at a 4:3 ratio. The 5-year citation prediction model is released publicly.
Significance. If the reported correlations hold under proper validation and the ideation pipeline demonstrably produces ideas with realized impact, the work could offer practical tools for literature navigation and research direction. The public release of the model is a clear strength supporting reproducibility. The significance is limited by the absence of grounding for the LLM-based evaluation of generated ideas.
major comments (3)
- [Abstract] Abstract: The central claim for the ideation pipeline rests on ideas being judged more impactful at a 4:3 ratio by an 'unbiased LLM judge,' yet no details are supplied on the judge model, prompting strategy, blinding procedure, or any correlation with human experts or realized citations. This substitutes for empirical validation and is load-bearing for the generation component.
- [Abstract] Abstract / Results: The reported Spearman's ρ values (0.4686 PageRank, 0.6192 citations) are presented without model architecture, training details, baselines, data splits, error bars, or statistical tests. These omissions prevent assessment of whether the metrics reflect genuine predictive power from title+abstract+date alone.
- [Ideation pipeline] Ideation pipeline: The pipeline generates ideas using the impact predictor and then evaluates them with an LLM judge, creating a risk that 'high impact' labels are self-reinforcing if the judge shares training biases or impact definitions with the predictor; no controls for this circularity are described.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, committing to revisions that strengthen the manuscript without overstating current results. Where details were omitted, we will expand the text; where validation is absent, we acknowledge the limitation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim for the ideation pipeline rests on ideas being judged more impactful at a 4:3 ratio by an 'unbiased LLM judge,' yet no details are supplied on the judge model, prompting strategy, blinding procedure, or any correlation with human experts or realized citations. This substitutes for empirical validation and is load-bearing for the generation component.
Authors: We agree that the abstract and methods lack sufficient detail on the LLM judge. In revision we will add the exact model (GPT-4), full prompting templates, blinding protocol, and temperature settings. We did not run a human-expert correlation study or track realized citations for the generated ideas; we will add an explicit limitations paragraph noting that the 4:3 ratio is an LLM proxy only and that future work should include human validation. revision: yes
-
Referee: [Abstract] Abstract / Results: The reported Spearman's ρ values (0.4686 PageRank, 0.6192 citations) are presented without model architecture, training details, baselines, data splits, error bars, or statistical tests. These omissions prevent assessment of whether the metrics reflect genuine predictive power from title+abstract+date alone.
Authors: The full manuscript contains the transformer architecture, training procedure on the arXiv graph, temporal split (pre-2021 train, 2021 test), and a length-based baseline. However, error bars across random seeds and formal significance tests were not reported. We will revise the Results section to include these, plus p-values for the reported Spearman correlations, to allow proper assessment of predictive power. revision: yes
-
Referee: [Ideation pipeline] Ideation pipeline: The pipeline generates ideas using the impact predictor and then evaluates them with an LLM judge, creating a risk that 'high impact' labels are self-reinforcing if the judge shares training biases or impact definitions with the predictor; no controls for this circularity are described.
Authors: We acknowledge the circularity concern. The revised manuscript will include a new subsection describing the mitigation steps taken (use of a distinct judge model family and an impact definition prompt written independently of the predictor) and will discuss remaining risks. If additional controls prove infeasible, we will state this limitation clearly. revision: yes
- Empirical correlation of the LLM judge outputs with human expert ratings or with realized future citations of the generated ideas, which was not performed and cannot be supplied from existing data.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains a model on arXiv data to predict held-out 5-year PageRank and citation counts from title/abstract/date, then reports test-set Spearman's ρ values; the ideation pipeline applies the trained predictor to generate ideas and evaluates them via a separate LLM judge whose outputs are not shown to be algebraically or definitionally identical to the predictor's inputs. No equation, definition, or self-citation reduces the reported metrics or the 4:3 ratio to the training data by construction. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and hyperparameters
axioms (2)
- domain assumption Historical arXiv citation graph and text provide reliable training signal for future impact
- ad hoc to paper LLM can act as unbiased proxy for real-world research impact
Reference graph
Works this paper leans on
-
[1]
Hanson, Pablo Gómez Barreiro, Paolo Crosetto, and Dan Brockington
Mark A. Hanson, Pablo Gómez Barreiro, Paolo Crosetto, and Dan Brockington. The strain on scientific publishing.Quantitative Science Studies, 5(4):823–843, 11 2024. ISSN 2641-3337. doi: 10.1162/qss_a_ 00327. URLhttps://doi.org/10.1162/qss_a_00327. 12
-
[2]
Why did the Nature Index grow by 16% in 2024? https://www.nature.com/nature-index/news/ why-did-the-nature-index-grow-by-sixteen-percent-in-twenty-twenty-four , July
Simon Baker. Why did the Nature Index grow by 16% in 2024? https://www.nature.com/nature-index/news/ why-did-the-nature-index-grow-by-sixteen-percent-in-twenty-twenty-four , July
2024
-
[3]
Accessed: April 2026
Nature Index. Accessed: April 2026
2026
-
[4]
arXiv monthly submission statistics
arXiv. arXiv monthly submission statistics. https://arxiv.org/stats/monthly_submissions,
-
[5]
Accessed: April 2026
2026
-
[6]
Cathleen O’Grady. Low-quality papers are surging by exploiting public data sets and AI.Science, 388 (6749):807–808, 2025. doi: 10.1126/science.adz1715
-
[7]
A bio-inspired bistable recurrent cell allows for long-lasting memory.PLOS ONE, 16(6):e0252676, 2021
Tulsi Suchak, Anietie E. Aliu, Charlie Harrison, Reyer Zwiggelaar, Nophar Geifman, and Matt Spick. Explosion of formulaic research articles, including inappropriate study designs and false discoveries, based on the NHANES US national health database.PLOS Biology, 23(5):e3003152, 2025. doi: 10.1371/journal. pbio.3003152
-
[8]
US science after a year of Trump: what has been lost and what remains.Nature, January 2026
Max Kozlov, Jeff Tollefson, and Dan Garisto. US science after a year of Trump: what has been lost and what remains.Nature, January 2026. doi: 10.1038/d41586-026-00088-9. URL https://www.nature. com/immersive/d41586-026-00088-9/index.html
-
[9]
Sandra Bendiscioli. The troubles with peer review for allocating research funding: Funders need to experiment with versions of peer review and decision-making.EMBO Reports, 20(12):e49472, 2019. doi: 10.15252/embr.201949472
-
[10]
Weixin Liang, Yuhui Zhang, et al. Can large language models provide useful feedback on research papers? A large-scale empirical analysis.NEJM AI, 1(8):AIoa2400196, 2024. doi: 10.1056/AIoa2400196
-
[11]
MARG: Multi-agent review generation for scientific papers, 2024
Mike D’Arcy, Tom Hope, Larry Birnbaum, and Doug Downey. MARG: Multi-agent review generation for scientific papers, 2024
2024
-
[12]
Silva, Osvaldo N
Adilson Vital Jr., Filipi N. Silva, Osvaldo N. Oliveira Jr., and Diego R. Amancio. Predicting citation impact of research papers using gpt and other text embeddings, 2024. URL https://arxiv.org/abs/2407. 19942
2024
-
[13]
From words to worth: Newborn article impact prediction with llm, 2024
Penghai Zhao, Qinghua Xing, Kairan Dou, Jinyu Tian, Ying Tai, Jian Yang, Ming-Ming Cheng, and Xiang Li. From words to worth: Newborn article impact prediction with llm, 2024. URL https: //arxiv.org/abs/2408.03934
-
[14]
Can LLMs generate novel research ideas? A large-scale human study with 100+ NLP researchers, 2024
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can LLMs generate novel research ideas? A large-scale human study with 100+ NLP researchers, 2024
2024
-
[15]
Valeria Aman. The potential of preprints to accelerate scholarly communication - a bibliometric analysis based on selected journals, 2013. URLhttps://arxiv.org/abs/1306.4856
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
Is preprint the future of science? a thirty year journey of online preprint services, 2021
Boya Xie, Zhihong Shen, and Kuansan Wang. Is preprint the future of science? a thirty year journey of online preprint services, 2021. URLhttps://arxiv.org/abs/2102.09066
-
[17]
Rodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David W. Graham, F.Q. Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, Ba...
-
[18]
Not-so-deep impact.Nature, 435:1003–1004, 2005
Nature Editorial. Not-so-deep impact.Nature, 435:1003–1004, 2005. doi: 10.1038/4351003b
-
[19]
Wilhite and Eric A
Allen W. Wilhite and Eric A. Fong. Coercive citation in academic publishing.Science, 335(6068):542–543,
-
[20]
URL https://www.science.org/doi/abs/10.1126/science
doi: 10.1126/science.1212540. URL https://www.science.org/doi/abs/10.1126/science. 1212540
-
[21]
The measure of research merit.Science, 346(6214):1155–1155, 2014
Marcia McNutt. The measure of research merit.Science, 346(6214):1155–1155, 2014. doi: 10.1126/ science.aaa3796. URLhttps://www.science.org/doi/abs/10.1126/science.aaa3796. 13
-
[22]
The PageRank citation ranking: Bringing order to the web
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The PageRank citation ranking: Bringing order to the web. Technical report, Stanford Digital Library Technologies Project, January 1998. URLhttp://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
1998
-
[23]
Identification of milestone papers through time-balanced network centrality.Journal of Informetrics, 10(4):1207–1223, November 2016
Manuel Sebastian Mariani, Matúš Medo, and Yi-Cheng Zhang. Identification of milestone papers through time-balanced network centrality.Journal of Informetrics, 10(4):1207–1223, November 2016. ISSN 1751-
2016
-
[24]
Journal of Informetrics , author =
doi: 10.1016/j.joi.2016.10.005. URLhttp://dx.doi.org/10.1016/j.joi.2016.10.005
-
[25]
Shuqi Xu, Manuel Sebastian Mariani, Linyuan Lü, and Matúš Medo. Unbiased evaluation of ranking metrics reveals consistent performance in science and technology citation data.Journal of Informetrics, 14 (1):101005, February 2020. ISSN 1751-1577. doi: 10.1016/j.joi.2019.101005. URL http://dx.doi. org/10.1016/j.joi.2019.101005
-
[26]
Fu and Constantin Aliferis
Lawrence D. Fu and Constantin Aliferis. Models for predicting and explaining citation count of biomedical articles. InAMIA Annual Symposium Proceedings, pages 222–226, 2008
2008
-
[27]
Citation count prediction: learning to estimate future citations for literature
Rui Yan, Jie Tang, Xiaobing Liu, Dongdong Shan, and Xiaoming Li. Citation count prediction: learning to estimate future citations for literature. InProceedings of the 20th ACM International Conference on Information and Knowledge Management, CIKM ’11, page 1247–1252, New York, NY , USA, 2011. Association for Computing Machinery. ISBN 9781450307178. doi: 1...
-
[28]
Xin Li, Xuli Tang, and Qikai Cheng. Predicting the clinical citation count of biomedical papers using multilayer perceptron neural network, 2022. URLhttps://arxiv.org/abs/2210.06346
-
[29]
Nature Biotechnology , author =
James W. Weis and Joseph M. Jacobson. Learning on knowledge graph dynamics provides an early warning of impactful research.Nature Biotechnology, 39:1300–1307, 2021. doi: 10.1038/s41587-021-00907-6
-
[30]
Cimate: Citation count prediction effectively leveraging the main text, 2024
Jun Hirako, Ryohei Sasano, and Koichi Takeda. Cimate: Citation count prediction effectively leveraging the main text, 2024. URLhttps://arxiv.org/abs/2410.04404
-
[31]
Zhanshuo Ye, Yiming Hou, Rui Pan, Tianchen Gao, and Hansheng Wang. Are large language models able to predict highly cited papers? evidence from statistical publications, 2026. URL https://arxiv.org/ abs/2601.13627
-
[32]
From automation to autonomy: A survey on large language models in scientific discovery, 2025
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. From automation to autonomy: A survey on large language models in scientific discovery, 2025. URL https://arxiv.org/abs/2505.13259
-
[33]
The ai scientist: Towards fully automated open-ended scientific discovery, 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URLhttps://arxiv.org/abs/2408. 06292
2024
-
[34]
Chain of ideas: Revolutionizing research via novel idea development with llm agents, 2024
Long Li, Weiwen Xu, Jiayan Guo, Ruochen Zhao, Xingxuan Li, Yuqian Yuan, Boqiang Zhang, Yuming Jiang, Yifei Xin, Ronghao Dang, Deli Zhao, Yu Rong, Tian Feng, and Lidong Bing. Chain of ideas: Revolutionizing research via novel idea development with llm agents, 2024. URL https://arxiv.org/ abs/2410.13185
-
[35]
Keyu Zhao, Weiquan Lin, Qirui Zheng, Fengli Xu, and Yong Li. Deep ideation: Designing llm agents to generate novel research ideas on scientific concept network, 2025. URL https://arxiv.org/abs/ 2511.02238
-
[36]
arXiv.org submitters. arxiv dataset, 2024. URLhttps://www.kaggle.com/dsv/7548853
-
[37]
SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python,
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric W. M...
-
[38]
Quantifying long-term scientific impact
Dashun Wang, Chaoming Song, and Albert-László Barabási. Quantifying long-term scientific impact. Science, 342(6154):127–132, October 2013. ISSN 1095-9203. doi: 10.1126/science.1237825. URL http://dx.doi.org/10.1126/science.1237825. 14
-
[39]
Towards a new crown indicator: Some theoretical considerations
Ludo Waltman, Nees Jan van Eck, Thed N. van Leeuwen, Martijn S. Visser, and Anthony F. J. van Raan. Towards a new crown indicator: Some theoretical considerations, 2010. URL https://arxiv.org/abs/ 1003.2167
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[40]
John P. A. Ioannidis, Kevin Boyack, and Paul F. Wouters. Citation metrics: A primer on how (not) to normalize.PLOS Biology, 14(9):1–7, 09 2016. doi: 10.1371/journal.pbio.1002542. URL https: //doi.org/10.1371/journal.pbio.1002542
-
[41]
Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks, 2025. URLhttps://arxiv.org/abs/2511.07025
-
[42]
Enevoldsen et al.,Mmteb: Massive multilingual text embedding benchmark, 2025
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi´nski, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Gabriel Sequeira, Diganta Misra, Shreeya Dhakal, Jonathan Rystrøm, Roman Solomatin, Ömer Ça˘gatan, Akash Kundu, Martin Bernstorff, Shit...
-
[44]
URLhttp://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
OpenAI Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mkadry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alexander Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alexandre Passos, Alexander Kirillov, Alexi Christakis, Alexi...
-
[46]
URLhttps://api.semanticscholar.org/CorpusID:273662196
-
[47]
Hermes 3 technical report.ArXiv, abs/2408.11857,
Ryan Teknium, Jeffrey Quesnelle, and Chen Guang. Hermes 3 technical report.ArXiv, abs/2408.11857,
-
[48]
URLhttps://api.semanticscholar.org/CorpusID:271923775
- [49]
-
[50]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Haotong Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena.ArXiv, abs/2306.05685, 2023. URL https://api. semanticscholar.org/CorpusID:259129398
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
LLM Evaluators Recognize and Favor Their Own Generations
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations, 2024. URLhttps://arxiv.org/abs/2404.13076. 16 A Per-Field Performance Results 2016201720182019202020212022202320242025 T est year 0.2 0.3 0.4 0.5 0.6 0.7Spearman 1-year horizon 2016201720182019202020212022202320242025 T est year 2-year horizon 2016...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
likely research field
-
[53]
methodological importance
-
[54]
practical usefulness
-
[55]
scores": {{
whether this sounds incremental or field-shaping Then output your best estimate as one non-negative integer. Do not output a default value. Do not choose a number merely because it is common. Do not explain. Do not output JSON. Output only one integer. Title: {title} Abstract: {abstract} B.2 LLM scoring to select top 5% research as generation seeds You ar...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.