HOLMES: Evaluating Higher-Order Logical Reasoning in LLMs
Pith reviewed 2026-06-26 08:25 UTC · model grok-4.3
The pith
LLMs reach at most 59.54% accuracy on a benchmark for higher-order symbolic reasoning over rules and predicates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current LLMs still struggle on HOLMES, with an average accuracy of only 50.64% and the best model reaching 59.54%. These findings identify higher-order symbolic reasoning as a key bottleneck for building reliable and verifiable LLMs.
What carries the argument
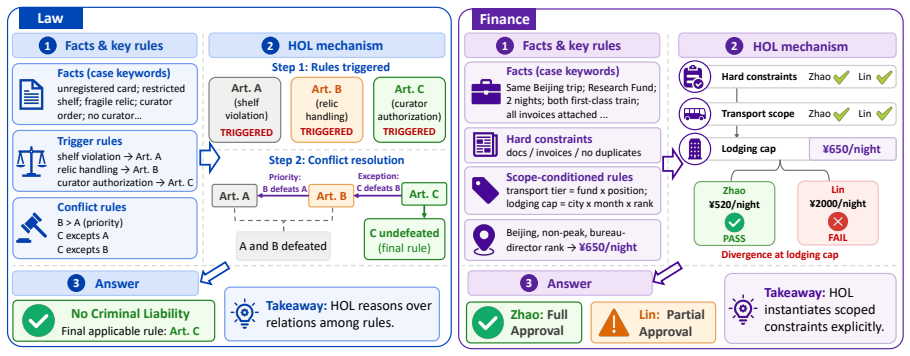
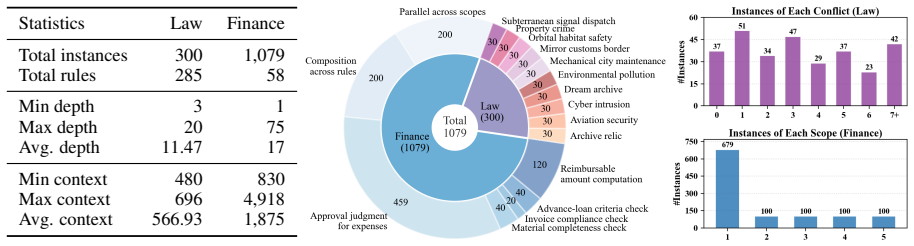
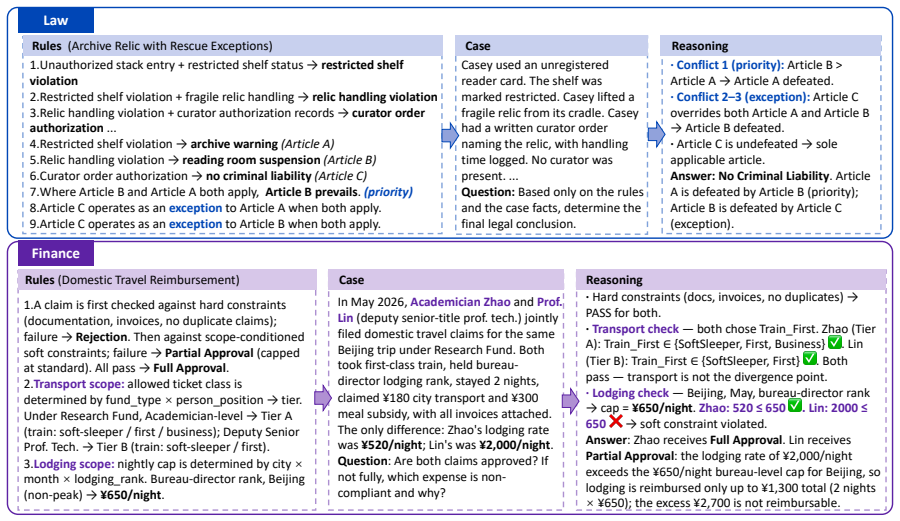
The HOLMES benchmark, consisting of 1379 natural-language problems each paired with higher-order logic formalizations, ground-truth answers, verifiable reasoning traces, and controllable reasoning factors across law and finance.
If this is right
- High final-answer accuracy can mask shortcut reasoning in conflict-resolution settings.
- Performance drops sharply under scope-conditioned and compositional reasoning.
- Higher-order symbolic reasoning is a key bottleneck for reliable and verifiable LLMs.
- First-order-logic benchmarks miss important realistic scenarios involving meta-level rules and predicates.
Where Pith is reading between the lines
- Training procedures that incorporate explicit higher-order formalisms may be needed beyond scale alone.
- The observed gaps suggest hybrid neuro-symbolic architectures could address limitations that pure language modeling has not closed.
- Extending the same evaluation protocol to new domains would test whether the bottleneck is domain-general.
Load-bearing premise
The 1379 instances and their HOL formalizations accurately isolate higher-order reasoning ability without introducing artifacts, shortcut opportunities, or domain-specific biases.
What would settle it
A language model that reaches above 80% accuracy on the full HOLMES set while producing only verifiable, non-shortcut reasoning traces across scope-conditioned and compositional subsets would falsify the bottleneck claim.
Figures




read the original abstract
Logical reasoning is essential for reliable AI, yet existing benchmarks are largely first-order-logic-centric, focusing on object-level deduction over fixed predicates. This misses many realistic scenarios where models must reason over rules, predicates, functions, constraints, and decision procedures themselves. We introduce HOLMES (Higher-Order Logic Meets real-world Explainable Symbolic reasoning), the first real-world benchmark for higher-order symbolic reasoning in LLMs, containing 1379 instances. Built on higher-order logic, HOLMES pairs natural-language problems with HOL formalizations, ground-truth answers, verifiable reasoning traces, and fine-grained controllable reasoning factors across law and finance. Experiments show that current LLMs still struggle on HOLMES, with an average accuracy of only 50.64% and the best model reaching 59.54%. Our analyses further reveal that high final-answer accuracy can mask shortcut reasoning in conflict-resolution settings, while performance drops sharply under scope-conditioned and compositional reasoning. These findings identify higher-order symbolic reasoning as a key bottleneck for building reliable and verifiable LLMs. The project code and dataset are publicly available at https://github.com/wuyucheng2002/HOLMES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HOLMES, the first real-world benchmark for higher-order symbolic reasoning in LLMs, consisting of 1379 natural-language problems paired with HOL formalizations, ground-truth answers, and verifiable traces across law and finance domains. Experiments evaluate multiple LLMs, reporting an average accuracy of 50.64% (best model 59.54%), with further analyses showing that high answer accuracy can mask shortcut reasoning in conflict-resolution cases and sharp performance drops on scope-conditioned and compositional reasoning tasks. The dataset and code are released publicly.
Significance. If the benchmark instances validly isolate higher-order features (e.g., quantification over predicates/functions and scope-conditioned rules) without first-order shortcuts or domain artifacts, the work would usefully extend existing first-order-centric benchmarks and provide a reproducible resource for studying verifiable reasoning. The public release of code and data is a clear strength supporting further evaluation and extension.
major comments (2)
- [Benchmark construction and dataset description] The central claim that current LLMs struggle specifically due to higher-order reasoning bottlenecks (and that HOLMES isolates this) depends on the construction and validation of the 1379 instances. The manuscript should detail the instance sourcing process, formalization procedure, and any validation steps (e.g., expert review or agreement metrics) confirming that problems require higher-order steps rather than permitting first-order shortcuts or introducing domain biases.
- [Experiments and analyses sections] The analyses of shortcut reasoning and performance drops (e.g., under scope-conditioned and compositional factors) are load-bearing for the bottleneck conclusion. The paper should include explicit controls, such as adversarial variants that succeed only via higher-order steps or ablation tests removing higher-order elements, to rule out confounds.
minor comments (2)
- [Dataset description] Clarify how the 'fine-grained controllable reasoning factors' are operationalized and varied across instances to enable the reported analyses.
- [Experimental setup] Ensure all model names, versions, and prompting setups are listed explicitly in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of HOLMES. We address each major comment below and commit to revisions that strengthen the description of benchmark construction and the supporting analyses without misrepresenting the current results.
read point-by-point responses
-
Referee: [Benchmark construction and dataset description] The central claim that current LLMs struggle specifically due to higher-order reasoning bottlenecks (and that HOLMES isolates this) depends on the construction and validation of the 1379 instances. The manuscript should detail the instance sourcing process, formalization procedure, and any validation steps (e.g., expert review or agreement metrics) confirming that problems require higher-order steps rather than permitting first-order shortcuts or introducing domain biases.
Authors: We agree that expanded details on construction are needed to support the isolation claim. Section 3 of the manuscript already describes the law and finance domains and the pairing with HOL formalizations, but we will add a dedicated subsection in the revision that specifies: (1) the sourcing process for the 1379 natural-language problems, (2) the step-by-step formalization procedure into higher-order logic (including explicit handling of predicate/function quantification and scope), and (3) the internal validation steps performed, such as consistency checks via the HOL prover and author review for higher-order necessity. We will include examples demonstrating why first-order shortcuts are insufficient. We did not conduct formal external expert review or inter-annotator agreement metrics; we will acknowledge this limitation explicitly rather than claim stronger validation than exists. revision: yes
-
Referee: [Experiments and analyses sections] The analyses of shortcut reasoning and performance drops (e.g., under scope-conditioned and compositional factors) are load-bearing for the bottleneck conclusion. The paper should include explicit controls, such as adversarial variants that succeed only via higher-order steps or ablation tests removing higher-order elements, to rule out confounds.
Authors: We appreciate the suggestion to add explicit controls. The current Section 5 already reports performance drops on scope-conditioned and compositional tasks plus evidence of shortcut reasoning in conflict cases. To further rule out confounds, we will incorporate ablation experiments in the revision: variants in which higher-order elements are removed or reduced to first-order form, with corresponding accuracy changes reported. We will also add discussion of how adversarial variants requiring higher-order steps could be constructed. These will be presented as new results supporting the bottleneck interpretation. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
The paper introduces a new benchmark (HOLMES) with 1379 instances and reports LLM accuracies (50.64% average, 59.54% best) as direct empirical results. No derivation chain, parameter fitting, predictions from fitted inputs, or self-citation load-bearing steps exist. The central claims rest on dataset construction and evaluation, which are self-contained against external benchmarks and do not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Higher-order logic formalizations can faithfully represent the target reasoning tasks in law and finance without loss of the intended higher-order structure.
Reference graph
Works this paper leans on
-
[1]
P roof W riter: Generating Implications, Proofs, and Abductive Statements over Natural Language
Tafjord, Oyvind and Dalvi, Bhavana and Clark, Peter. P roof W riter: Generating Implications, Proofs, and Abductive Statements over Natural Language. Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2021. doi:10.18653/v1/2021.findings-acl.317
-
[2]
Multi- L ogi E val: Towards Evaluating Multi-Step Logical Reasoning Ability of Large Language Models
Patel, Nisarg and Kulkarni, Mohith and Parmar, Mihir and Budhiraja, Aashna and Nakamura, Mutsumi and Varshney, Neeraj and Baral, Chitta. Multi- L ogi E val: Towards Evaluating Multi-Step Logical Reasoning Ability of Large Language Models. Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2024. doi:10.18653/v1/2024.emnlp-main.1160
-
[3]
Parmar, Mihir and Patel, Nisarg and Varshney, Neeraj and Nakamura, Mutsumi and Luo, Man and Mashetty, Santosh and Mitra, Arindam and Baral, Chitta. L ogic B ench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models. Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2024. doi:10.18653/v1/202...
-
[4]
CoRR , volume =
Ruiwen Zhou and Wenyue Hua and Liangming Pan and Sitao Cheng and Xiaobao Wu and En Yu and William Yang Wang , title =. CoRR , volume =
-
[5]
Simeng Han and Hailey Schoelkopf and Yilun Zhao and Zhenting Qi and Martin Riddell and Luke Benson and Lucy Sun and Ekaterina Zubova and Yujie Qiao and Matthew Burtell and David Peng and Jonathan Fan and Yixin Liu and Brian Wong and Malcolm Sailor and Ansong Ni and Linyong Nan and Jungo Kasai and Tao Yu and Rui Zhang and Shafiq R. Joty and Alexander R. Fa...
-
[6]
Proceedings of the International Conference on Learning Representations , year =
Abulhair Saparov and He He , title =. Proceedings of the International Conference on Learning Representations , year =
-
[7]
Proceedings of the International Conference on Learning Representations , year =
Chengwen Qi and Ren Ma and Bowen Li and He Du and Binyuan Hui and Jinwang Wu and Yuanjun Laili and Conghui He , title =. Proceedings of the International Conference on Learning Representations , year =
-
[8]
Diagnosing the First-Order Logical Reasoning Ability Through
Tian, Jidong and Li, Yitian and Chen, Wenqing and Xiao, Liqiang and He, Hao and Jin, Yaohui. Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.303
-
[9]
arXiv preprint arXiv:2007.08124 , year=
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning , author=. arXiv preprint arXiv:2007.08124 , year=
arXiv 2007
-
[10]
CLUTRR : A Diagnostic Benchmark for Inductive Reasoning from Text
Sinha, Koustuv and Sodhani, Shagun and Dong, Jin and Pineau, Joelle and Hamilton, William L. CLUTRR : A Diagnostic Benchmark for Inductive Reasoning from Text. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019. doi:10.18653/v1/D19-1458
-
[11]
LogiConBench: Benchmarking Logical Consistencies of
Zheng CHEN and Chuan Zhou and Fengxiang Cheng and Yip Tin Po and Fenrong Liu and Yisen Wang and Jiajun Chai and Xiaohan Wang and Guojun Yin and Wei Lin and Bo Li and Haoxuan Li and Zhouchen Lin , booktitle=. LogiConBench: Benchmarking Logical Consistencies of. 2026 , url=
2026
-
[12]
Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence , pages =
Transformers as Soft Reasoners over Language , author =. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence , pages =. 2020 , doi =
2020
-
[13]
Brown and Adam Santoro and Aditya Gupta and Adri
Aarohi Srivastava and Abhinav Rastogi and Abhishek Rao and Abu Awal Md Shoeb and Abubakar Abid and Adam Fisch and Adam R. Brown and Adam Santoro and Aditya Gupta and Adri. Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , journal=. 2023 , url=
2023
-
[14]
Logic- LM : Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning
Pan, Liangming and Albalak, Alon and Wang, Xinyi and Wang, William. Logic- LM : Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023
2023
-
[15]
Proceedings of the International Conference on Learning Representations , year =
LogicReward: Incentivizing LLM Reasoning via Step-Wise Logical Supervision , author =. Proceedings of the International Conference on Learning Representations , year =
-
[16]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =. 2024 , url=
2024
-
[17]
Proceedings of the International Conference on Learning Representations , year =
Mialon, Gr. Proceedings of the International Conference on Learning Representations , year =
-
[18]
Zeng, Aohan and others , year =. 2602.15763 , archivePrefix =
- [19]
-
[20]
Yang, An and others , year =. 2505.09388 , archivePrefix =
-
[21]
2026 , howpublished =
2026
-
[22]
2026 , howpublished =
Introducing. 2026 , howpublished =
2026
-
[23]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew , booktitle =. ROUGE : A Package for Automatic Evaluation of Summaries. 2004 , address =
2004
-
[24]
International Conference on Learning Representations , year =
BERTScore: Evaluating Text Generation with BERT , author =. International Conference on Learning Representations , year =
-
[25]
2023 , url=
Olga Golovneva and Moya Peng Chen and Spencer Poff and Martin Corredor and Luke Zettlemoyer and Maryam Fazel-Zarandi and Asli Celikyilmaz , booktitle=. 2023 , url=
2023
-
[26]
Logical reasoning in large language models: A survey , author=. 2502.09100 , archivePrefix=
-
[27]
Cheng, Fengxiang and Li, Haoxuan and Liu, Fenrong and Van Rooij, Robert and Zhang, Kun and Lin, Zhouchen , title =. 2025 , isbn =. doi:10.24963/ijcai.2025/1155 , booktitle =
-
[28]
2002 , publisher=
Isabelle/HOL: a proof assistant for higher-order logic , author=. 2002 , publisher=
2002
-
[29]
Journal of Symbolic Logic , volume =
A Formulation of the Simple Theory of Types , author =. Journal of Symbolic Logic , volume =. 1940 , publisher =
1940
-
[30]
2002 , publisher =
An Introduction to Mathematical Logic and Type Theory: To Truth Through Proof , author =. 2002 , publisher =
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.