Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning
Pith reviewed 2026-06-27 06:42 UTC · model grok-4.3
The pith
Everyday causal reasoning in humans and LLMs relies on pattern matching rather than abstract world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
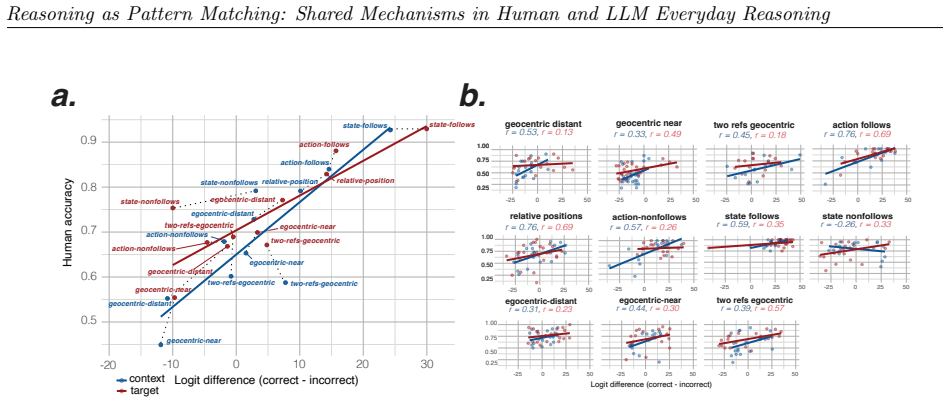
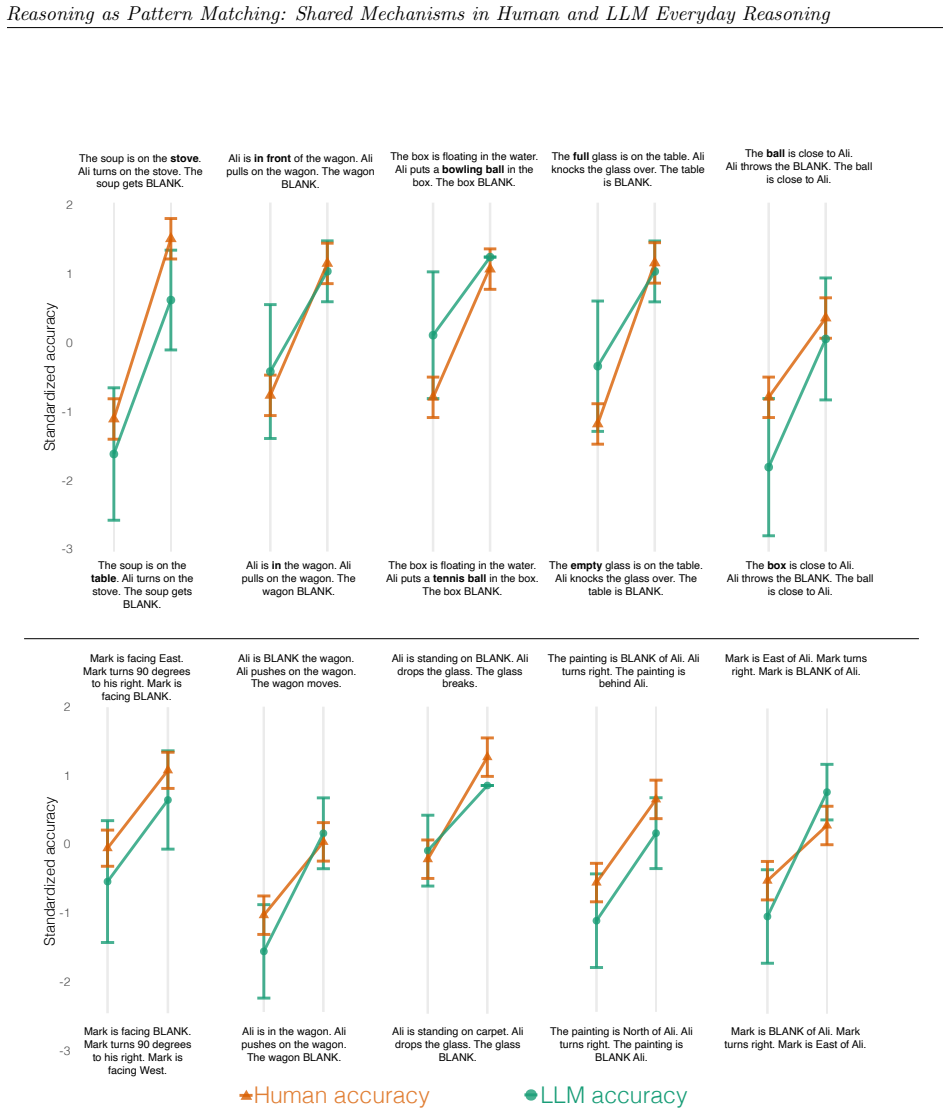
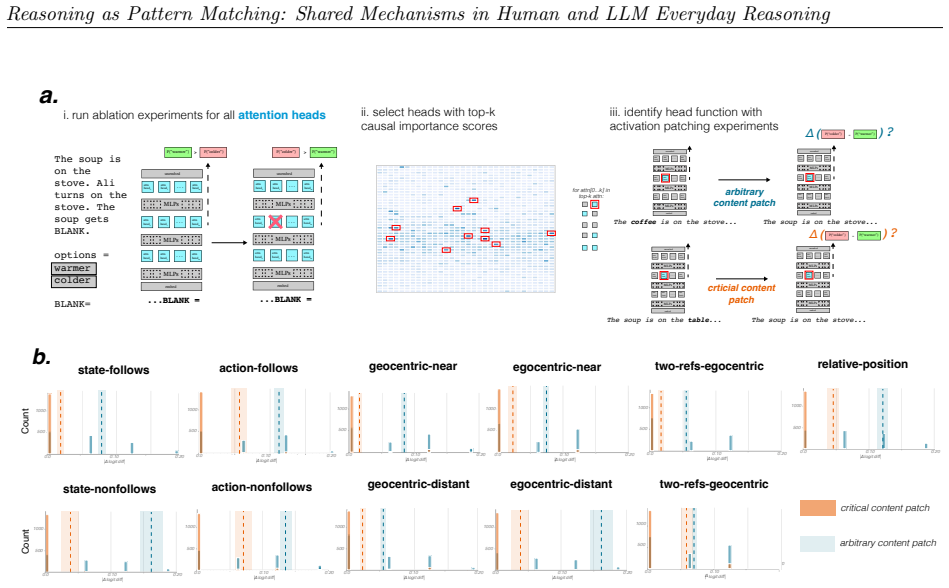
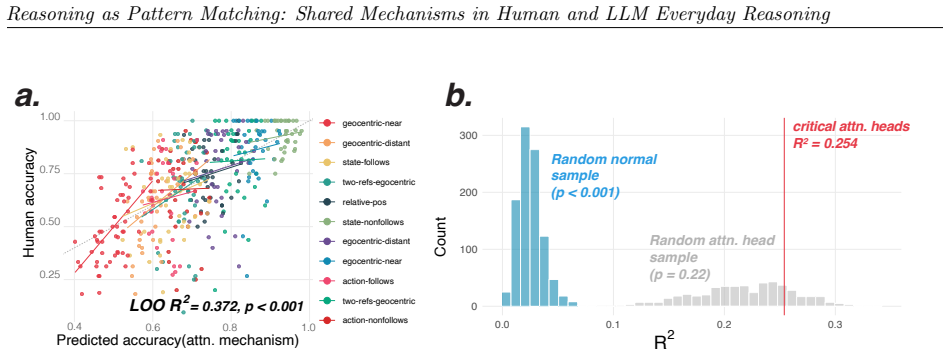
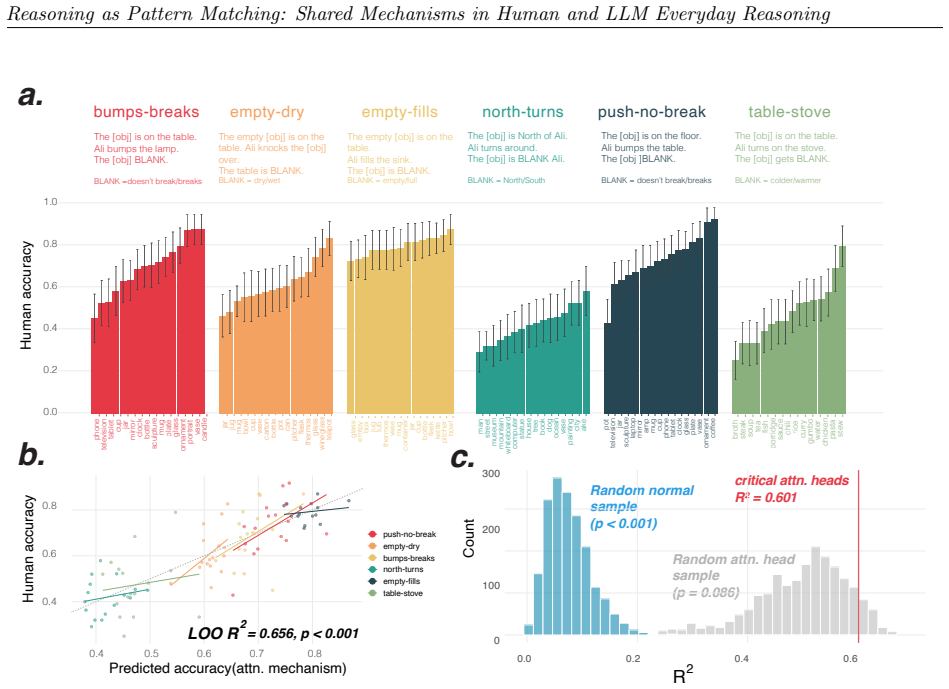
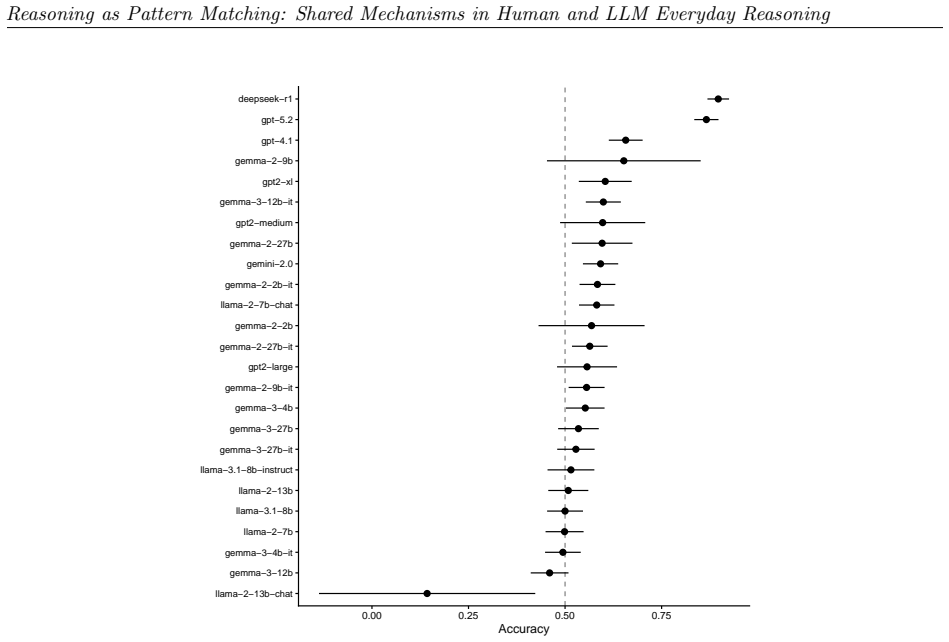
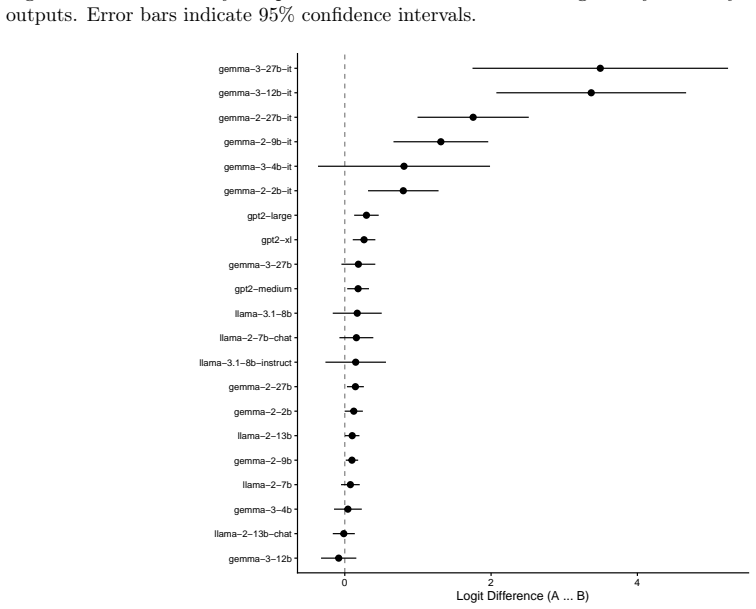
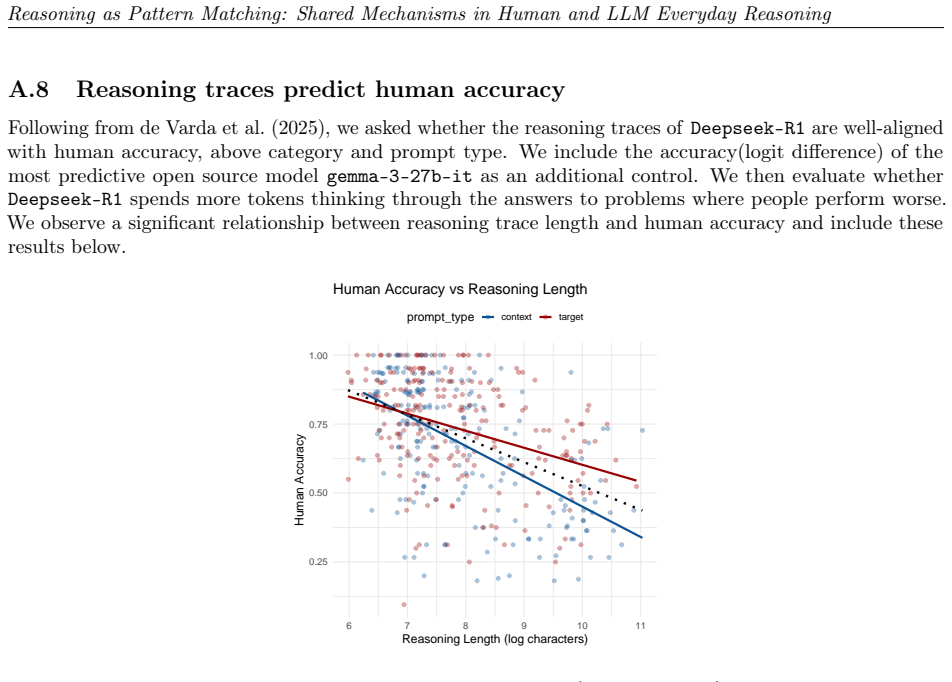
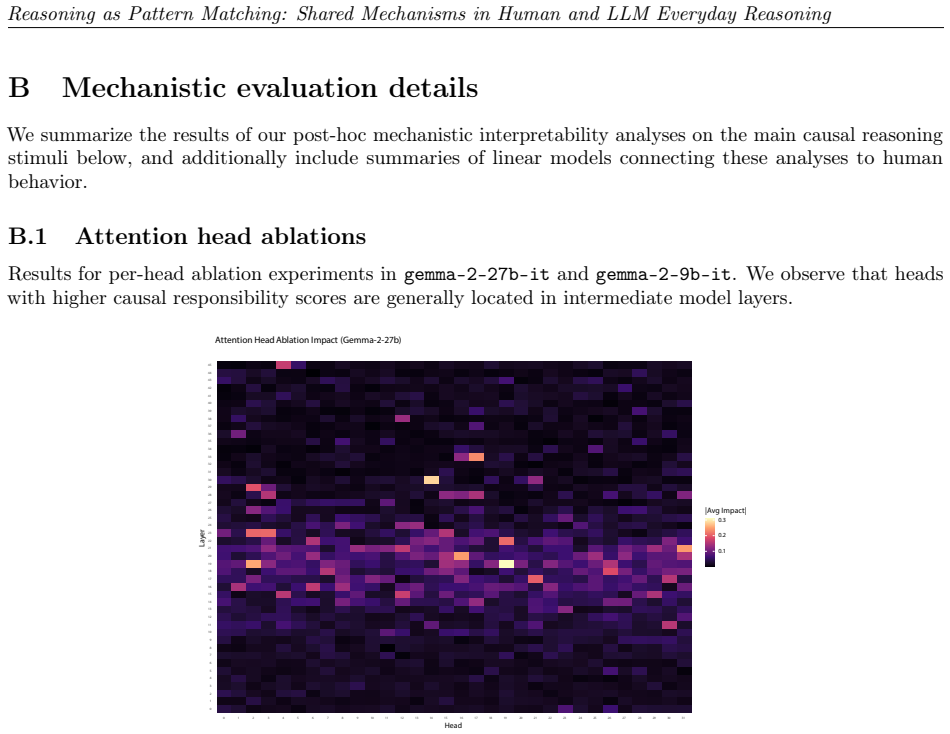
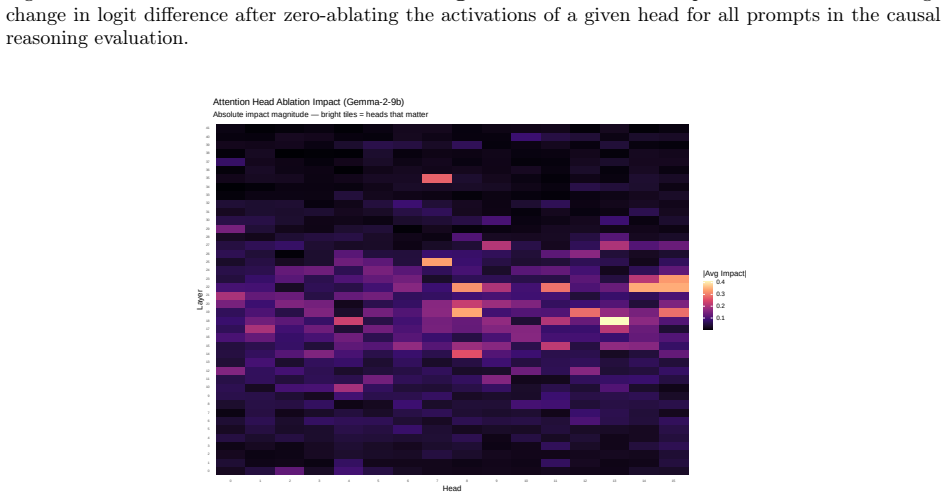
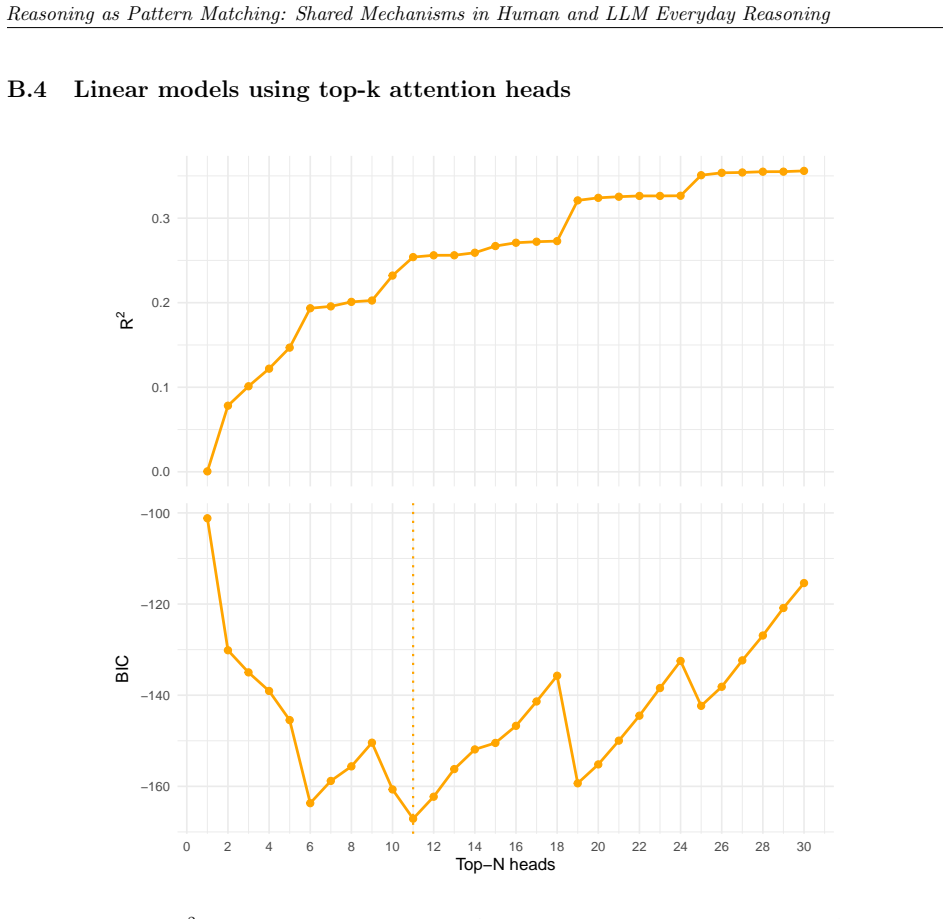
We observe similar patterns of errors in both people and models. We identify the set of attention heads driving LLM responses and find that these heads implement a form of pattern-matching. These attention heads allow us to predict seemingly inexplicable reasoning errors in people caused by ostensibly irrelevant prompt details. Taken together, our results suggest that everyday causal reasoning in people and LLMs is more consistent with a form of pattern-matching than with abstract world models.
What carries the argument
Attention heads in LLMs that implement pattern-matching and predict human errors from irrelevant prompt details.
If this is right
- Both humans and LLMs rely on pattern matching for everyday causal reasoning instead of abstract world models.
- Attention heads identified in LLMs can forecast human errors on prompts with irrelevant details.
- Error patterns observed in LLMs reflect mechanisms also present in human reasoning.
Where Pith is reading between the lines
- The same pattern-matching approach might apply to other reasoning domains beyond causal everyday tasks.
- Efforts to instill abstract world models in LLMs may not reduce errors if the underlying process remains pattern-based.
- Altering the relevant attention heads could produce targeted changes in both model and predicted human behavior on new prompts.
Load-bearing premise
The assumption that the identified attention heads implement the same pattern-matching process that produces the parallel error patterns in human participants, shown by their success at predicting those errors.
What would settle it
A new set of everyday reasoning tasks where the identified LLM attention heads fail to predict the specific errors made by human participants.
Figures


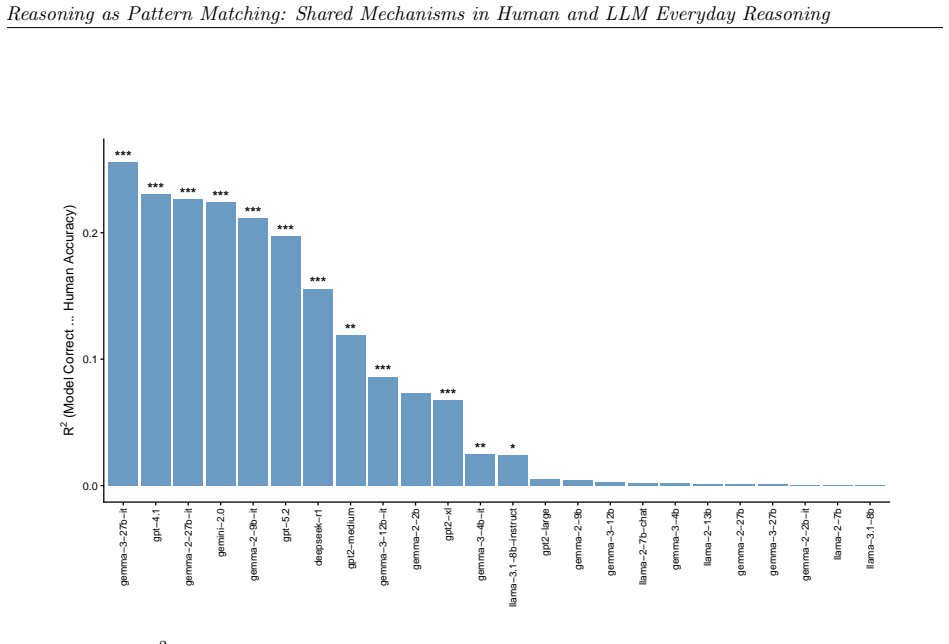
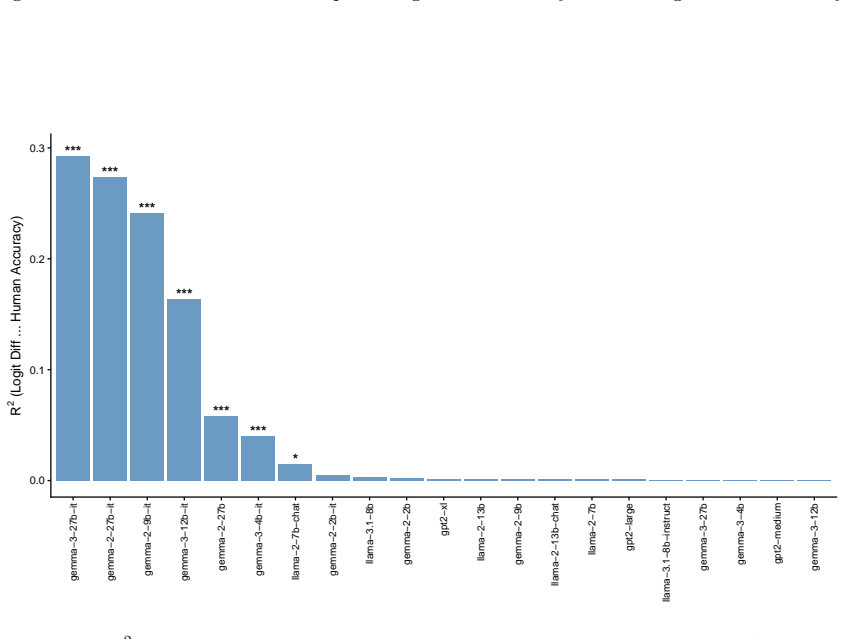
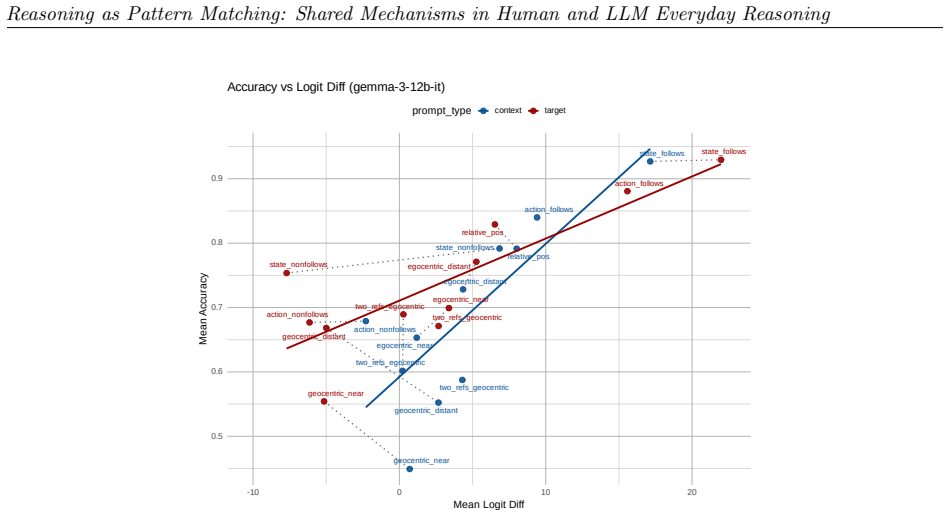
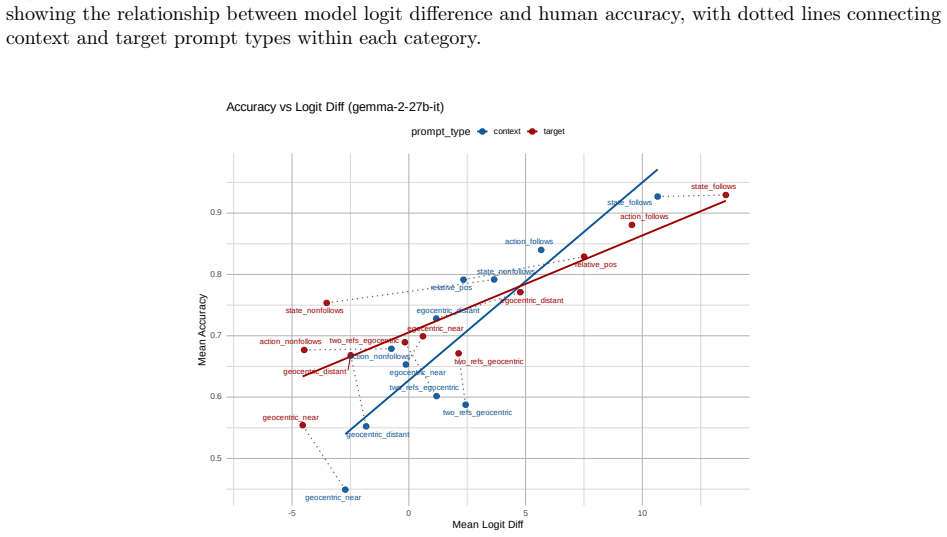
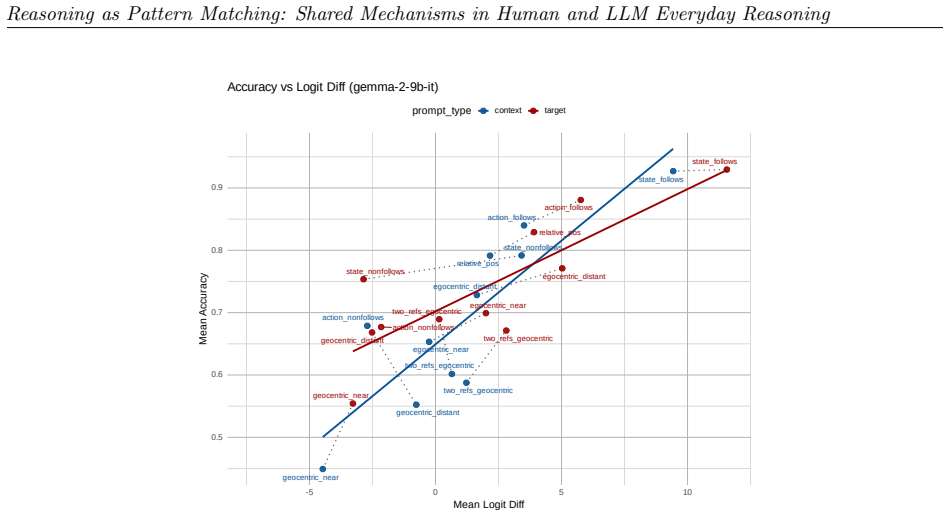
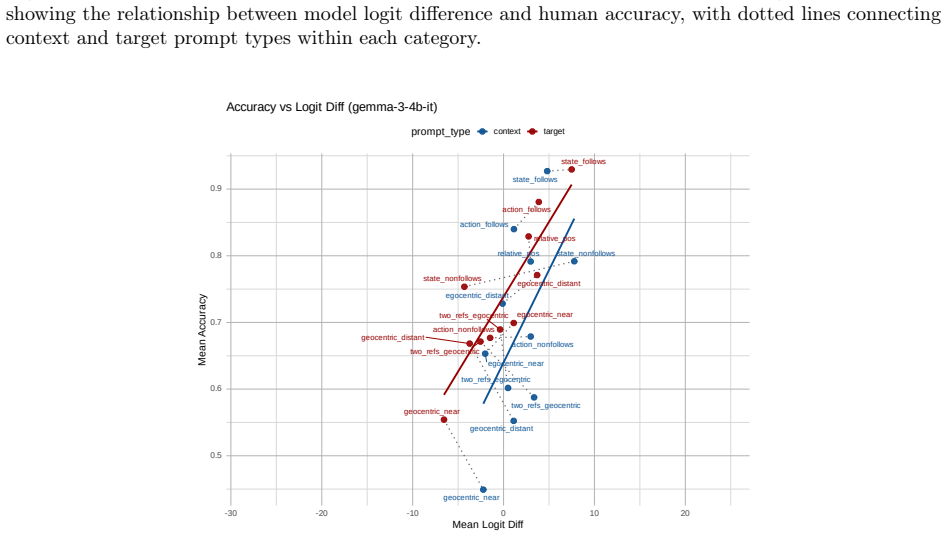
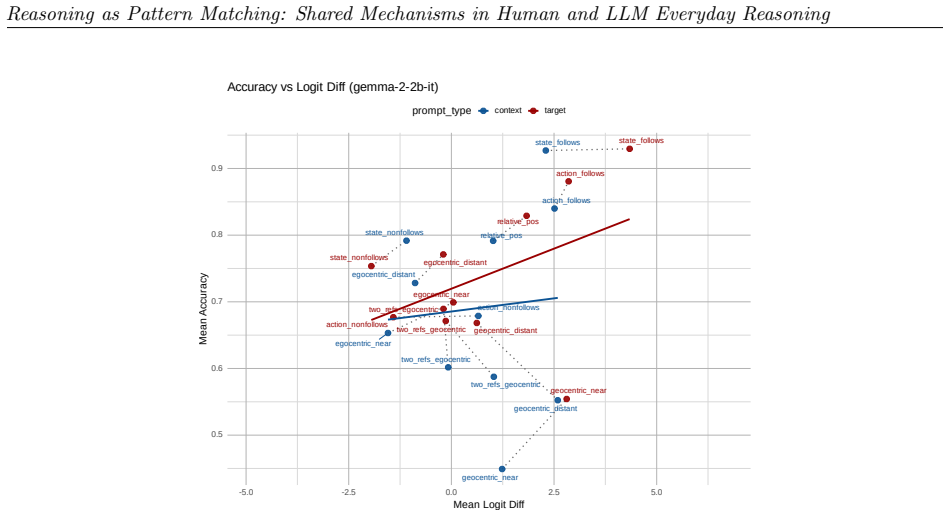
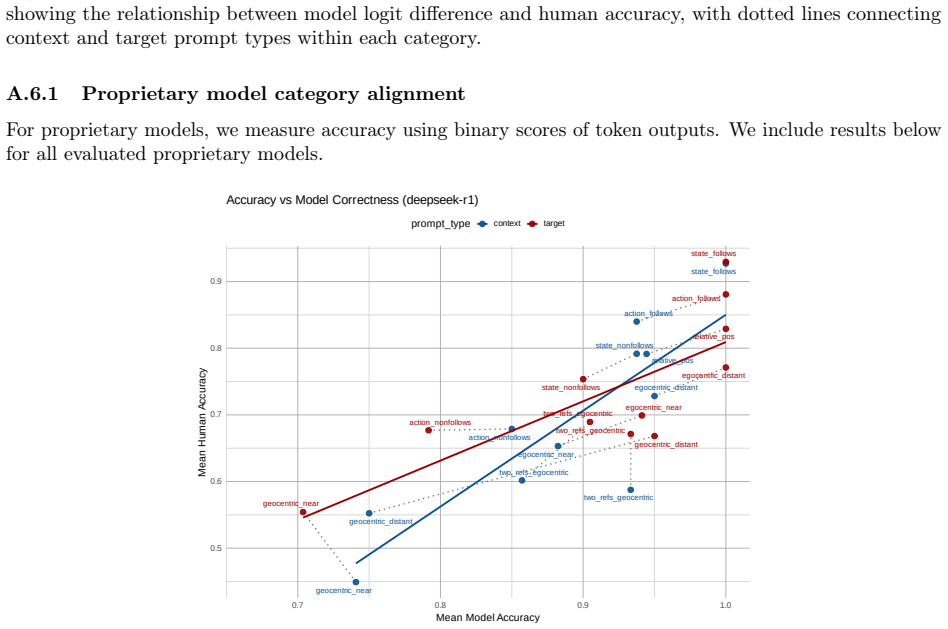
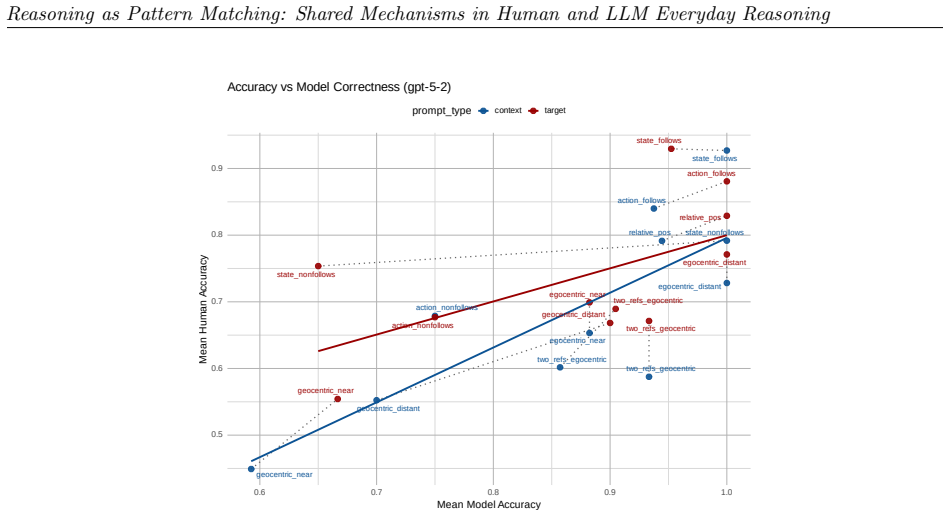
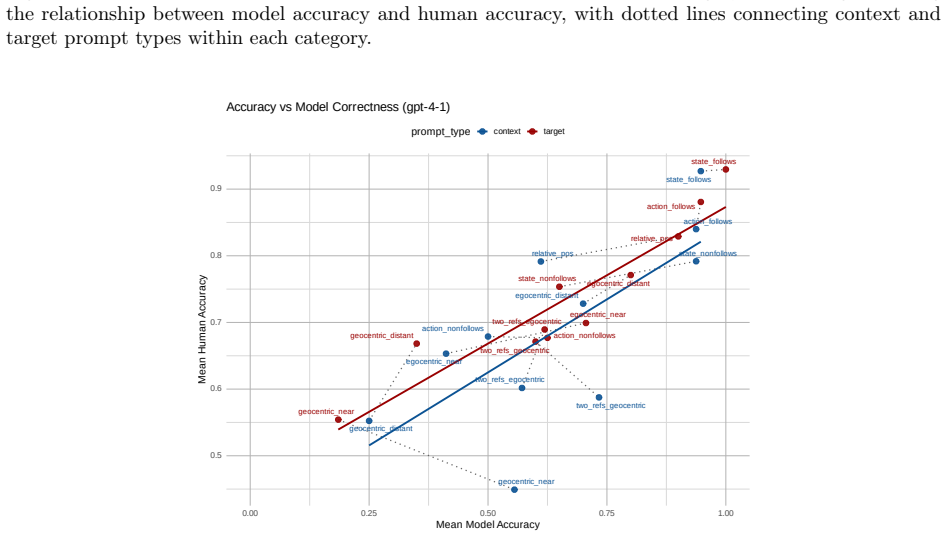
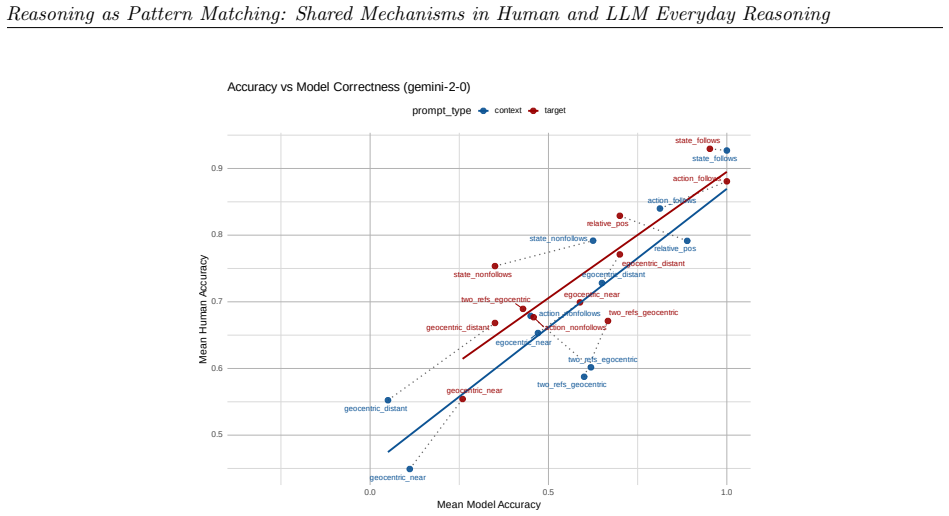
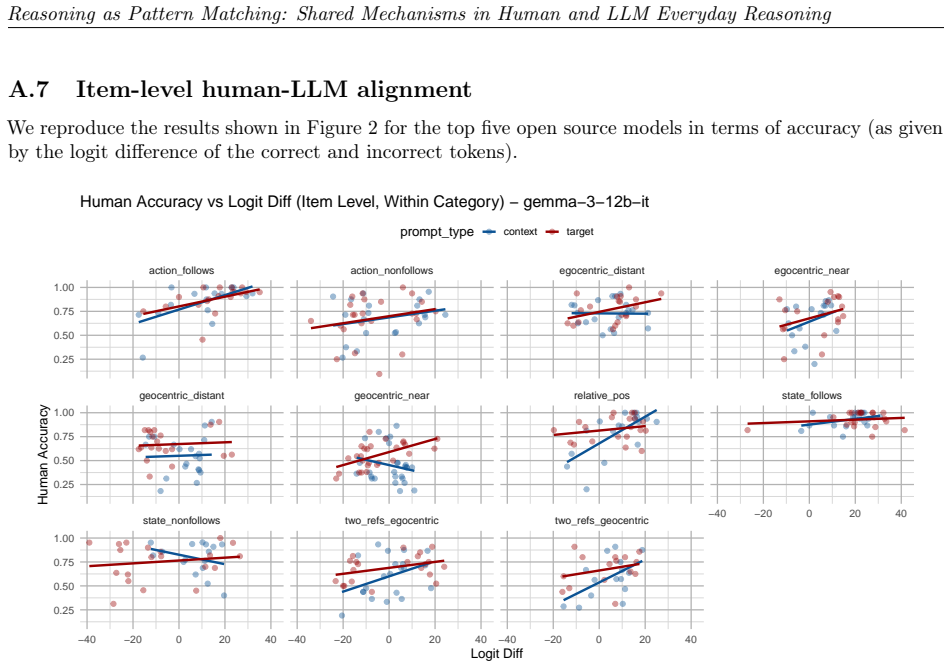
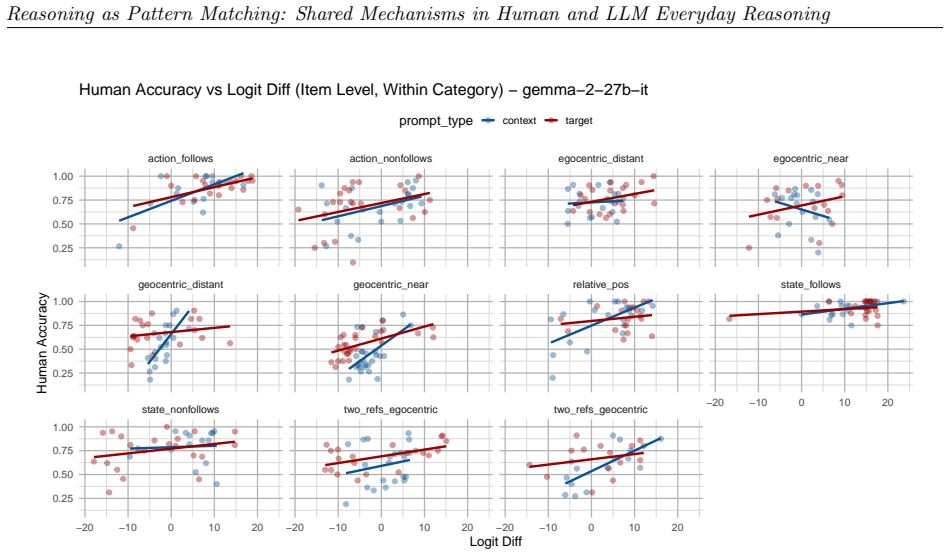
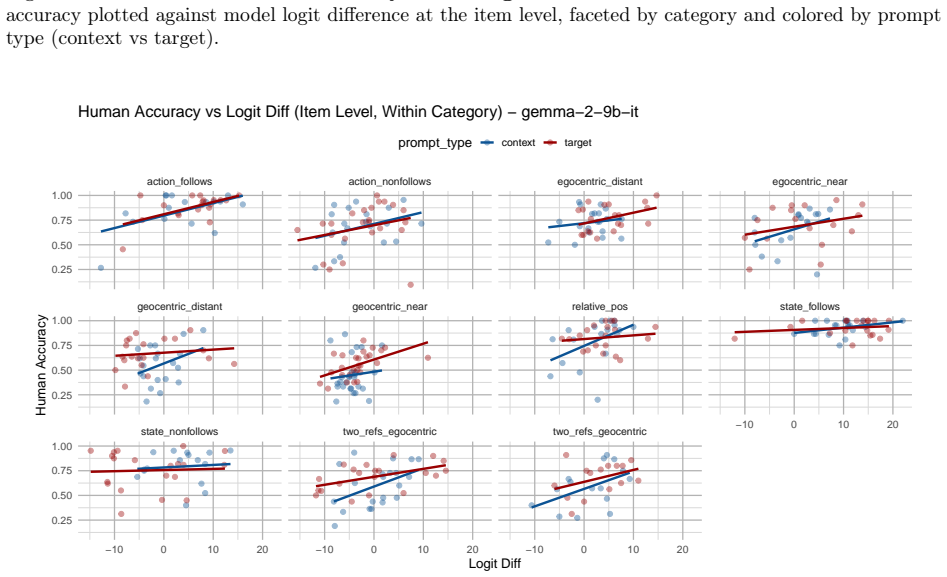
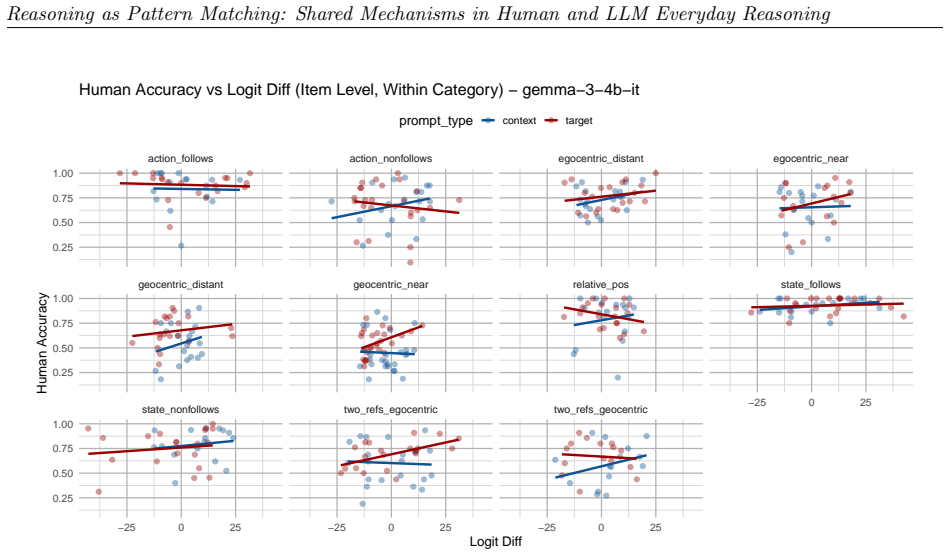
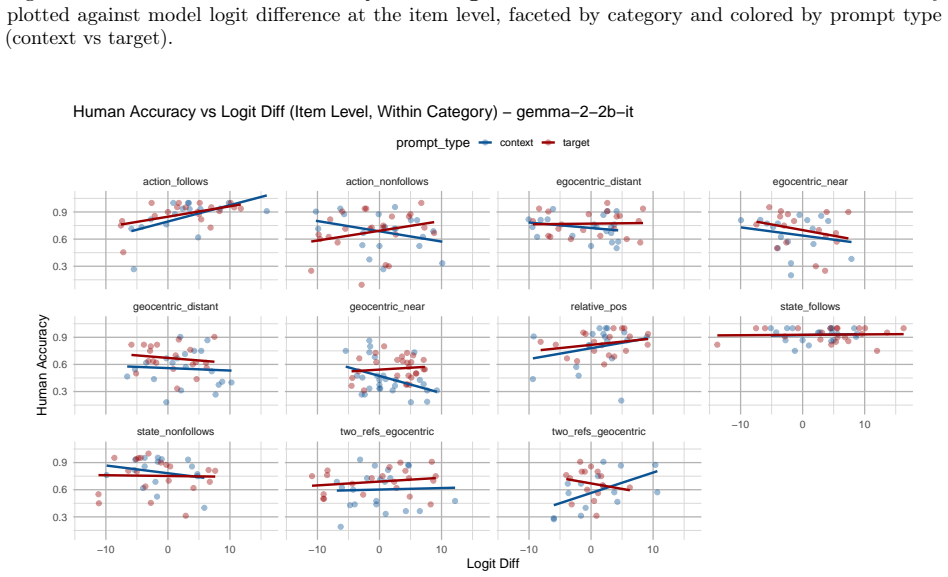
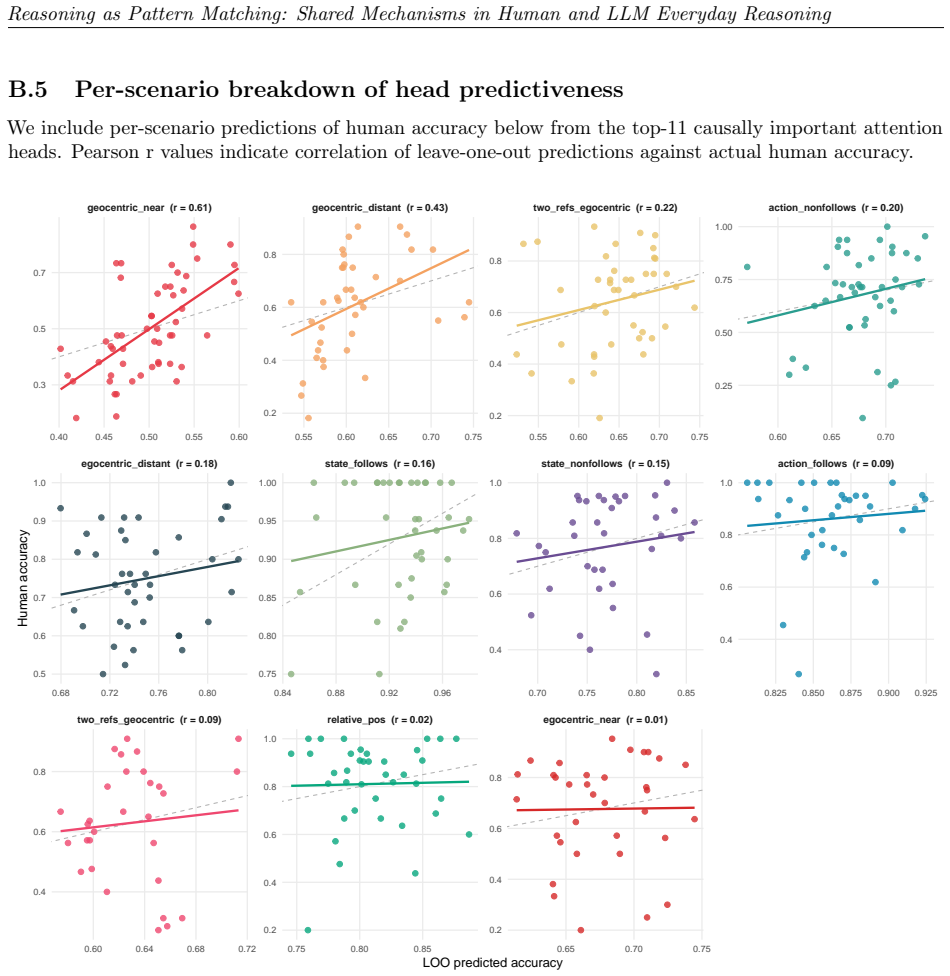
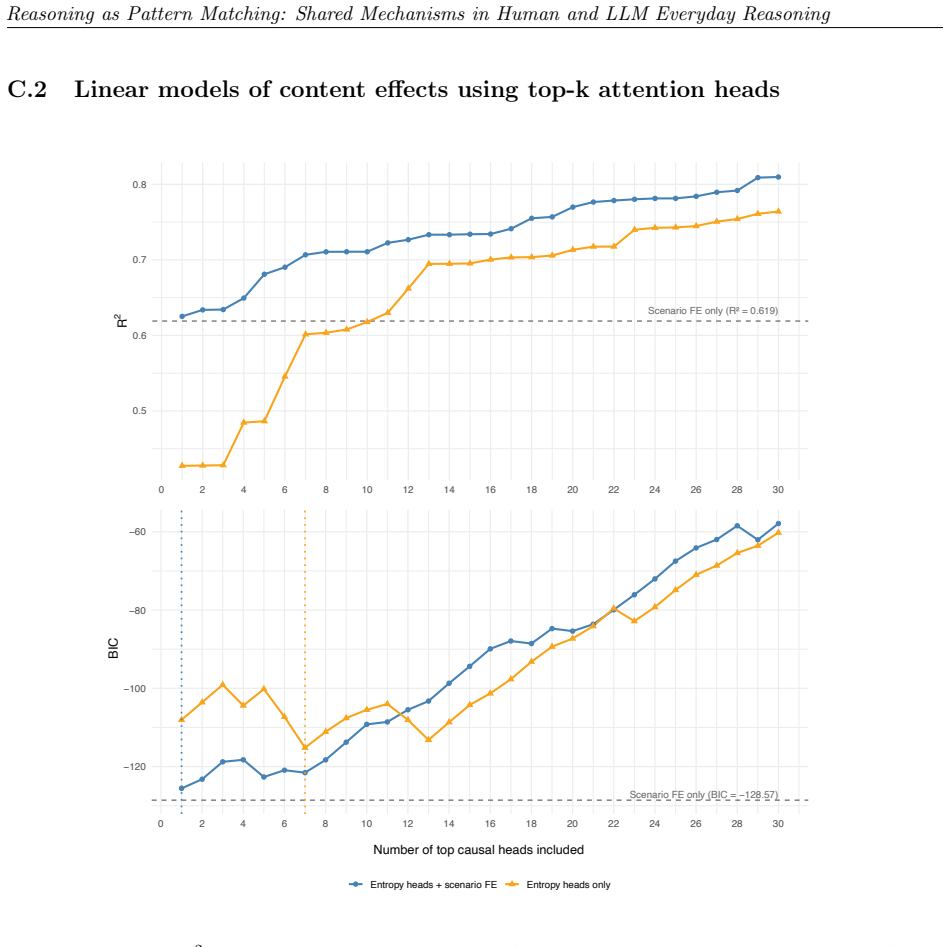
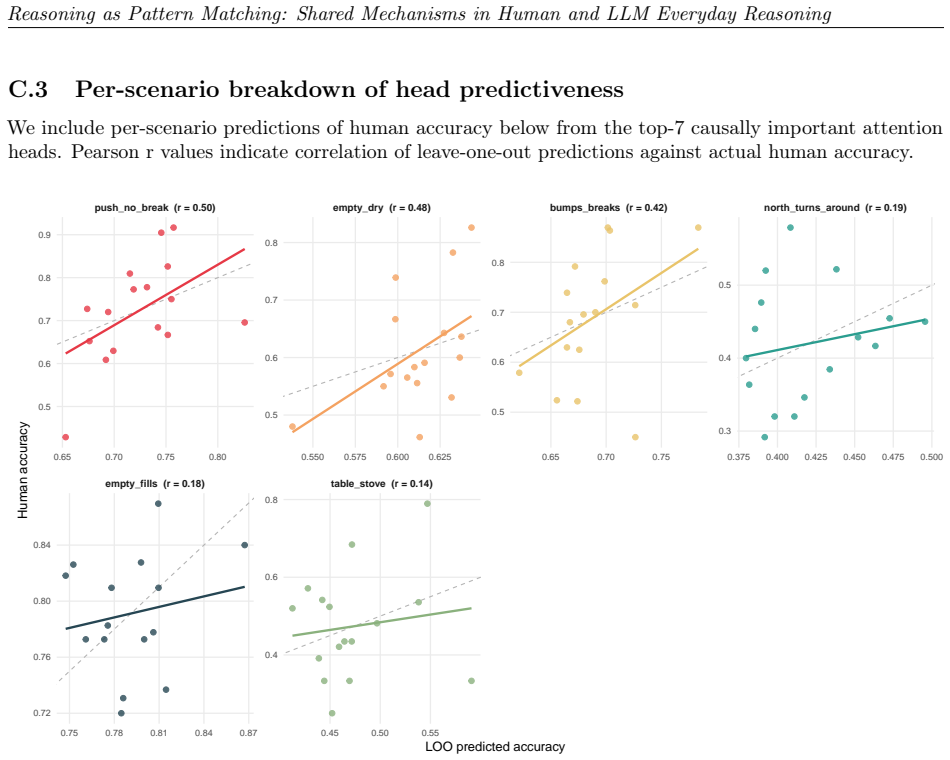
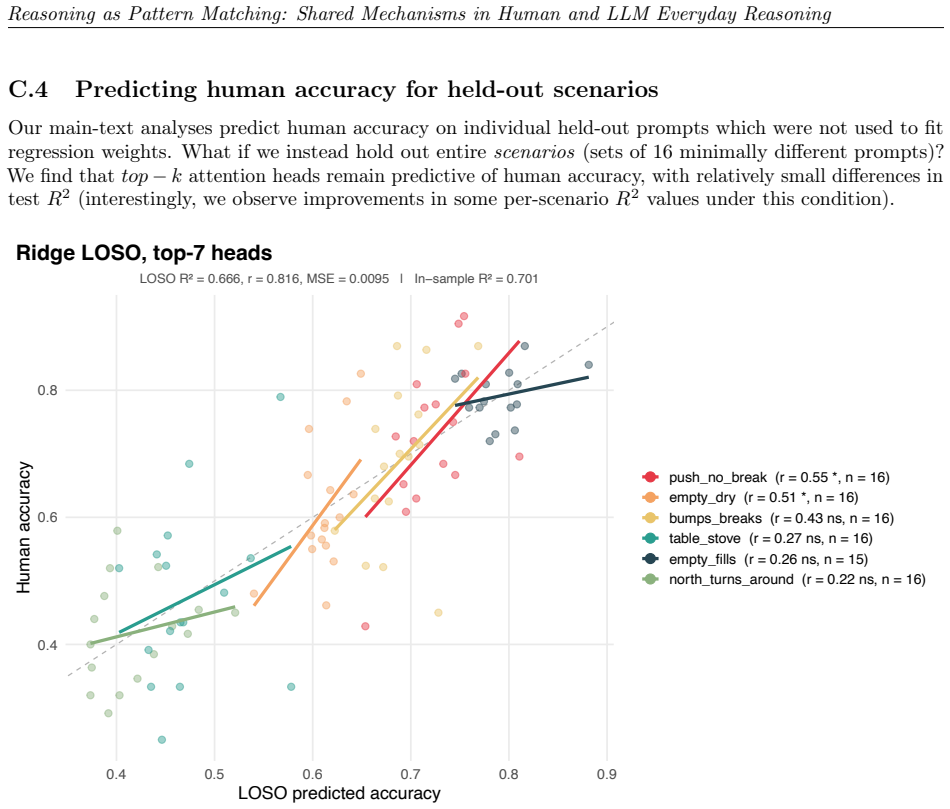
read the original abstract
When large language models (LLMs) fail to generalize or make haphazard errors in reasoning, it is often taken as evidence that LLMs are not truly reasoning, but rather performing a kind of pattern matching. The implication is that people's behavior does not exhibit the same types of failures because human reasoning uses principled and abstract world models. We evaluate human participants and 25 LLMs on their ability to engage in common-sense reasoning about a variety of everyday situations and observe similar patterns of errors in both people and models. We then identify the set of attention heads driving LLM responses and find that these heads implement a form of pattern-matching. These attention heads allow us to predict seemingly inexplicable reasoning errors in people caused by ostensibly irrelevant prompt details. Taken together, our results suggest that everyday causal reasoning in people and LLMs is more consistent with a form of pattern-matching than with abstract world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human participants and 25 LLMs exhibit similar error patterns (influence of irrelevant details, haphazard failures) on everyday causal reasoning tasks; that specific attention heads in the LLMs implement pattern-matching; and that these heads predict human errors from ostensibly irrelevant prompt details. On this basis the authors conclude that everyday causal reasoning in both people and LLMs is more consistent with pattern-matching than with abstract world models.
Significance. If the parallel error patterns and the predictive link from LLM attention heads to human errors survive rigorous controls and statistical evaluation, the work would supply a concrete mechanistic bridge between human and model behavior and would weaken the common claim that human reasoning relies on abstract models while LLMs rely only on surface patterns. The approach of using identified LLM components to generate falsifiable predictions about human performance is a methodological strength.
major comments (3)
- [Abstract] Abstract: the inference that the observed error signatures are 'more consistent with a form of pattern-matching than with abstract world models' is load-bearing for the central claim yet rests on an unexamined assumption. The manuscript provides no argument or data showing that an agent possessing an abstract causal model could not produce the same surface errors under incomplete retrieval or prompt interference; therefore the incompatibility conclusion does not follow from the reported parallels alone.
- [Abstract] Abstract: no experimental details, participant numbers, task descriptions, statistical tests, or controls are supplied for either the human or LLM evaluations. Without these it is impossible to determine whether the reported error patterns are reliable, replicable, or actually support the shared-mechanism conclusion.
- [Abstract] Abstract: the claim that the identified attention heads 'implement a form of pattern-matching' and 'allow us to predict' human errors is central to the mechanistic argument, yet the manuscript gives no description of how the heads were isolated, what their activation patterns are, or how the prediction to human data was performed and validated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that it requires expansion for experimental details and methodological descriptions to allow proper evaluation. We also acknowledge the need to clarify the logical basis for our conclusion of greater consistency with pattern-matching. We address each major comment below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the inference that the observed error signatures are 'more consistent with a form of pattern-matching than with abstract world models' is load-bearing for the central claim yet rests on an unexamined assumption. The manuscript provides no argument or data showing that an agent possessing an abstract causal model could not produce the same surface errors under incomplete retrieval or prompt interference; therefore the incompatibility conclusion does not follow from the reported parallels alone.
Authors: We thank the referee for highlighting this. Our claim is not one of strict incompatibility but of greater consistency, supported by the fact that the specific pattern-matching attention heads identified in LLMs predict human error rates on ostensibly irrelevant details. This predictive link would be surprising if human reasoning relied exclusively on abstract causal models that retrieve only relevant structures. That said, we agree an explicit argument addressing why abstract models should not exhibit these errors under the task conditions would strengthen the manuscript. We will add a paragraph in the Discussion section making this case. revision: partial
-
Referee: [Abstract] Abstract: no experimental details, participant numbers, task descriptions, statistical tests, or controls are supplied for either the human or LLM evaluations. Without these it is impossible to determine whether the reported error patterns are reliable, replicable, or actually support the shared-mechanism conclusion.
Authors: We agree that the abstract omits these elements, which are provided in the full manuscript's Methods and Results sections. In the revised version we will expand the abstract to include concise summaries of participant numbers, task descriptions, statistical tests, and controls so that the reliability of the error patterns can be assessed from the abstract alone. revision: yes
-
Referee: [Abstract] Abstract: the claim that the identified attention heads 'implement a form of pattern-matching' and 'allow us to predict' human errors is central to the mechanistic argument, yet the manuscript gives no description of how the heads were isolated, what their activation patterns are, or how the prediction to human data was performed and validated.
Authors: The abstract is intentionally high-level, but we accept that it should convey more about the approach. We will revise it to briefly note the isolation method (attention analysis combined with causal interventions), the relevant activation patterns, and the validation of the prediction to human data, drawing directly from the detailed description already present in the Methods and Results sections of the manuscript. revision: yes
Circularity Check
No circularity: central claims rest on independent empirical comparisons of error patterns and attention-head interventions.
full rationale
The derivation proceeds from collecting human and LLM responses on everyday reasoning tasks, observing parallel error patterns, identifying attention heads in LLMs via standard interpretability methods, and testing whether those heads predict human errors from irrelevant prompt details. None of these steps reduces by definition or by self-citation to the target conclusion; the pattern-matching interpretation is an inference from the data rather than presupposed in the measurement. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or described methods. The work is therefore self-contained against external benchmarks of human and model behavior.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/2308.03762. Renee Baillargeon. Physical reasoning in infancy.The cognitive neurosciences, pages 181–204,
-
[2]
Hoyeon Chang, Jinho Park, Hanseul Cho, Sohee Yang, Miyoung Ko, Hyeonbin Hwang, Seungpil Won, Dohaeng Lee, Youbin Ahn, and Minjoon Seo. Characterizing pattern matching and its limits on compositional task structures.arXiv preprint arXiv:2505.20278,
-
[3]
Chacha Chen, Matthew Jörke, Adam Goliński, Masha Fedzechkina, Guillermo Sapiro, Sinead Williamson, and Nicholas Foti. Llms are not (consistently) bayesian: Quantifying internal (in) consistencies of llms’ probabilistic beliefs.arXiv preprint arXiv:2605.06915,
-
[4]
A systematic comparison of syllogistic reasoning in humans and language models
Tiwalayo Eisape, Michael Tessler, Ishita Dasgupta, Fei Sha, Sjoerd Steenkiste, and Tal Linzen. A systematic comparison of syllogistic reasoning in humans and language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8425–8444,
2024
-
[5]
ISSN 1532-5946. doi: 10.3758/BF03196976. URLhttps://doi.org/10.3758/BF03196976. Chaz Firestone. Performance vs. competence in human–machine comparisons.Proceedings of the National Academy of Sciences, 117(43):26562–26571,
-
[6]
A theory of emergent in-context learning as implicit structure induction
Michael Hahn and Navin Goyal. A theory of emergent in-context learning as implicit structure induction. arXiv preprint arXiv:2303.07971,
-
[7]
60 Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning Dean S Hazineh, Zechen Zhang, and Jeffery Chiu. Linear latent world models in simple transformers: A case study on othello-gpt.arXiv preprint arXiv:2310.07582,
-
[8]
In-context learning creates task vectors.arXiv preprint arXiv:2310.15916,
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors.arXiv preprint arXiv:2310.15916,
-
[9]
Jennifer Hu and Roger Levy. Prompting is not a substitute for probability measurements in large language models.arXiv preprint arXiv:2305.13264,
-
[10]
Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
Pith/arXiv arXiv 2001
-
[11]
How do language models compose functions?arXiv preprint arXiv:2510.01685,
Apoorv Khandelwal and Ellie Pavlick. How do language models compose functions?arXiv preprint arXiv:2510.01685,
-
[12]
doi: 10.1016/0010-0285(85)90009-X
ISSN 00100285. doi: 10.1016/0010-0285(85)90009-X. URLhttps://linkinghub.elsevier.com/retrieve/pii/001002858590009X. John K Kruschke and Michael M Fragassi. The perception of causality: Feature binding in interacting objects. InProceedings of the eighteenth annual conference of the cognitive science society, pages 441–446. Routledge,
-
[13]
Language models struggle to use representations learned in-context.arXiv preprint arXiv:2602.04212,
61 Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning Michael A Lepori, Tal Linzen, Ann Yuan, and Katja Filippova. Language models struggle to use representations learned in-context.arXiv preprint arXiv:2602.04212,
-
[14]
Martha Lewis and Melanie Mitchell. Using Counterfactual Tasks to Evaluate the Generality of Analogical Reasoning in Large Language Models. URLhttp://arxiv.org/abs/2402.08955. Falk Lieder and Thomas L. Griffiths. Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.The Behavioral and Brain Sciences...
-
[15]
ISSN 1469-1825. doi: 10.1017/S0140525X1900061X. Tania Lombrozo. The structure and function of explanations.Trends in cognitive sciences, 10(10):464–470,
-
[16]
doi: 10.1016/j.cognition.2013.08.015
ISSN 0010-0277. doi: 10.1016/j.cognition.2013.08.015. URLhttp://www.sciencedirect. com/science/article/pii/S0010027713001728. Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. Dissociating language and thought in large language models.Trends in cognitive sciences, 28 (6):517–540,
-
[17]
R Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L Griffiths. Embers of autoregression: Understanding large language models through the problem they are trained to solve.arXiv preprint arXiv:2309.13638,
-
[18]
James A Michaelov, Seana Coulson, and Benjamin K Bergen
ISBN 978-0-674-36830-9. James A Michaelov, Seana Coulson, and Benjamin K Bergen. Can peanuts fall in love with distributional semantics?arXiv preprint arXiv:2301.08731,
-
[19]
URLhttps://doi.org/10.1037/14043-011
doi: 10.1037/14043-011. URLhttps://doi.org/10.1037/14043-011. Kanishka Misra and Kyle Mahowald. Language models learn rare phenomena from less rare phenomena: The case of the missing aanns. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 913–929,
-
[20]
doi: 10.1073/pnas.2215907120. URLhttps://www.pnas.org/doi/10.1073/pnas. 2215907120. Neel Nanda and Joseph Bloom. Transformerlens. https://github.com/TransformerLensOrg/ TransformerLens,
-
[21]
In-context learning and induction heads.arXiv preprint arXiv:2209.11895,
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895,
-
[22]
doi: 10.1017/S0140525X22002849
ISSN 1469-1825. doi: 10.1017/S0140525X22002849. D.E. Rumelhart, J.L. McClelland, and the PDP Research Group.Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volumes 1 and
-
[23]
Conceptual structure coheres in human cognition but not in large language models
Siddharth Suresh, Kushin Mukherjee, Xizheng Yu, Wei-Chun Huang, Lisa Padua, and Timothy Rogers. Conceptual structure coheres in human cognition but not in large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 722–738,
2023
-
[24]
Sean Trott. Toward a theory of generalizability in llm mechanistic interpretability research.arXiv preprint arXiv:2509.22831,
-
[25]
Tomer Ullman. Large language models fail on trivial alterations to theory-of-mind tasks.arXiv preprint arXiv:2302.08399,
-
[26]
doi: 10.1016/j.tics.2024.02.008
ISSN 1364-6613. doi: 10.1016/j.tics.2024.02.008. URL https://www.sciencedirect.com/science/article/pii/S1364661324000354. Lance Ying, Aydan Y Huang, Aviv Netanyahu, Andrei Barbu, Boris Katz, Joshua B Tenenbaum, and Tianmin Shu. Grounding social perception in intuitive physics.arXiv preprint arXiv:2603.27410,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.