CORE: Common Outcome Regularities from Action-Free Visual Demonstrations for Robot Manipulation
Pith reviewed 2026-06-30 07:01 UTC · model grok-4.3
The pith
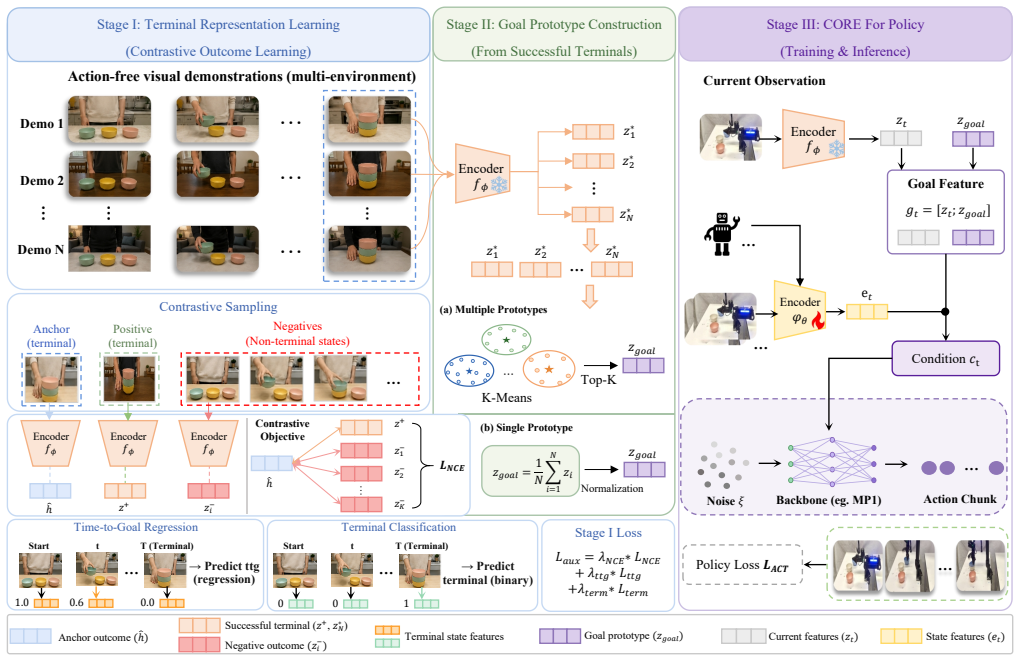
CORE extracts shared terminal state patterns from action-free videos to condition robot policies with visual goal prototypes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
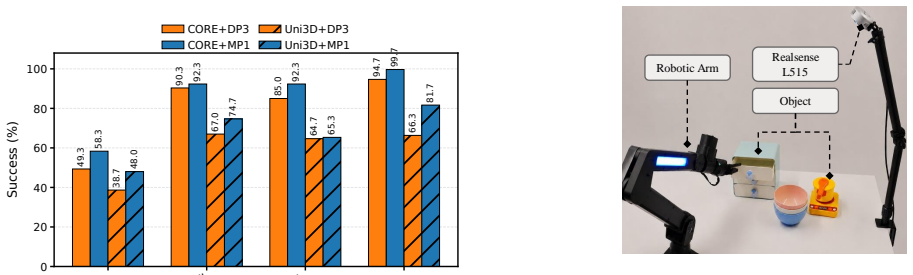
CORE establishes that visual goal prototypes formed by aggregating embeddings of successful terminal states from action-free demonstrations supply concrete geometric and physical constraints that raise policy success rates by up to 3.9, 11.1, and 17.0 percentage points on Meta-World, RoboTwin 2.0, and real-world tasks while outperforming text-conditioned variants.
What carries the argument
The terminal outcome encoder, trained with contrastive and auxiliary temporal objectives on visual demonstrations, whose embeddings are aggregated into visual goal prototypes that serve as global conditioning signals for robot policies.
If this is right
- Policies achieve higher success when conditioned on visual goal prototypes than when conditioned on language instructions.
- The method works across Meta-World, RoboTwin 2.0, and real robot manipulation without requiring action labels in the source videos.
- Focus on terminal outcomes rather than full trajectories reduces sensitivity to embodiment differences.
- Visual prototypes supply geometric constraints that language alone does not provide.
Where Pith is reading between the lines
- The same terminal-state clustering could be tested on navigation or assembly tasks where end configurations are also stable.
- Prototype quality likely improves with larger and more diverse sets of human videos for the same task.
- Combining the visual prototypes with sparse robot demonstrations might further close remaining performance gaps.
Load-bearing premise
Successful trajectories for the same task share stable terminal states with common object configurations, spatial relations, and contact constraints.
What would settle it
If embeddings of terminal states from successful demonstrations fail to form consistent clusters across videos or if policies conditioned on the resulting prototypes show no success-rate gain over unconditioned or text-only baselines, the central claim is falsified.
Figures



read the original abstract
Robot imitation learning often relies on costly robot demonstrations, while abundant action-free visual demonstrations, such as human videos, are difficult to use because they lack robot-executable actions and suffer from embodiment gaps. We propose CORE, a policy learning framework that extracts Common Outcome Regularities from visual demonstrations. Rather than transferring explicit actions across embodiments, CORE exploits a key observation: although successful trajectories for the same task can be diverse, their terminal states often share stable object configurations, spatial relations, and contact constraints. CORE first trains a terminal outcome encoder with contrastive and auxiliary temporal objectives, then aggregates successful terminal embeddings into visual goal prototypes, and finally injects these prototypes as global goal conditions into robot policies. Compared with language instructions, visual goal prototypes provide more concrete geometric and physical constraints for task completion. Across Meta-World, RoboTwin 2.0, and real-world manipulation, CORE improves the average success rate of the corresponding policy backbones by up to +3.9, +11.1, and +17.0 percentage points, respectively, and outperforms text-conditioned variants under the evaluated settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CORE, a framework to learn robot manipulation policies from action-free visual demonstrations (e.g., human videos) by exploiting the observation that successful trajectories for a task often converge to terminal states with shared object configurations, spatial relations, and contact constraints. CORE trains a terminal outcome encoder via contrastive and auxiliary temporal losses, aggregates successful terminal embeddings into visual goal prototypes, and injects these prototypes as global conditioning into policy backbones. It reports average success-rate gains of up to +3.9 pp on Meta-World, +11.1 pp on RoboTwin 2.0, and +17.0 pp in real-world settings over the respective policy backbones, while also outperforming text-conditioned variants.
Significance. If the gains are robustly attributable to the terminal prototypes rather than other factors and the key convergence assumption holds, the work offers a concrete route to leverage abundant action-free video data without explicit action transfer or embodiment alignment. The design choice of contrastive + temporal objectives on terminal states is standard yet well-motivated for this setting. No machine-checked proofs or parameter-free derivations are present; the contribution is empirical.
major comments (2)
- [Abstract] Abstract: the central claim of success-rate improvements (+3.9 / +11.1 / +17.0 pp) is stated without any experimental details, number of trials, variance, baselines, or statistical tests. This is load-bearing because the attribution of gains to 'common outcome regularities' cannot be evaluated from the given information.
- [Method] Method (key observation paragraph): the premise that successful trajectories reliably share low-variance terminal states with consistent spatial relations and contact constraints is presented without any quantitative support (e.g., measured variance of object poses, contact points, or terminal embedding distances across the human videos or Meta-World demos). If this variance remains high or the encoder collapses to appearance, the prototypes add little beyond generic visual conditioning, directly undermining the explanation for the reported gains.
minor comments (1)
- Notation for the terminal outcome encoder and prototype aggregation is introduced without an explicit equation or diagram reference, making the conditioning mechanism harder to follow.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of experimental details and the motivating assumption.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of success-rate improvements (+3.9 / +11.1 / +17.0 pp) is stated without any experimental details, number of trials, variance, baselines, or statistical tests. This is load-bearing because the attribution of gains to 'common outcome regularities' cannot be evaluated from the given information.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol. The full details (100 trials per task, 5 random seeds, standard deviations, and comparisons to policy backbones plus text-conditioned baselines) appear in Sections 4–5 and the supplementary material. We will revise the abstract to include a concise qualifier such as “evaluated over 100 trials per task with reported standard deviations” while respecting length limits. This change directly addresses the concern about evaluability of the claims. revision: yes
-
Referee: [Method] Method (key observation paragraph): the premise that successful trajectories reliably share low-variance terminal states with consistent spatial relations and contact constraints is presented without any quantitative support (e.g., measured variance of object poses, contact points, or terminal embedding distances across the human videos or Meta-World demos). If this variance remains high or the encoder collapses to appearance, the prototypes add little beyond generic visual conditioning, directly undermining the explanation for the reported gains.
Authors: The observation is presented as a motivating hypothesis supported by the downstream performance gains. We acknowledge that explicit quantification of terminal-state variance (object-pose variance, embedding distances) is absent from the current manuscript. We will add a new analysis subsection (and accompanying figure) that computes and reports these statistics on both the human-video and Meta-World demonstration sets, together with a check that the learned encoder does not collapse to appearance-only features. This addition will provide the requested quantitative grounding. revision: yes
Circularity Check
No circularity; method uses external demos and standard contrastive objectives without self-referential reduction.
full rationale
The paper states a key observation about terminal states of successful trajectories, trains an encoder via contrastive + temporal losses on action-free visual data, aggregates successful embeddings into prototypes, and conditions policies on them. None of the enumerated circularity patterns apply: the observation is presented as an external premise, not derived from the method; reported gains (+3.9 / +11.1 / +17.0 pp) are measured on independent benchmarks (Meta-World, RoboTwin, real-world) rather than fitted inputs renamed as predictions; no self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing. The derivation chain is self-contained against external data and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive and auxiliary temporal objective hyperparameters
axioms (1)
- domain assumption Successful trajectories share stable terminal states with common object configurations, spatial relations, and contact constraints
Reference graph
Works this paper leans on
-
[1]
Conference on robot learning , pages=
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning , author=. Conference on robot learning , pages=. 2020 , organization=
2020
-
[2]
Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation , author=. arXiv preprint arXiv:2506.18088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
International Conference on Learning Representations , volume=
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. International Conference on Learning Representations , volume=
-
[5]
The International Journal of Robotics Research , volume=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. The International Journal of Robotics Research , volume=. 2025 , publisher=
2025
-
[6]
Proceedings of Robotics: Science and Systems (RSS) , year=
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mp1: Meanflow tames policy learning in 1-step for robotic manipulation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[9]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Vip: Towards universal visual reward and representation via value-implicit pre-training , author=. arXiv preprint arXiv:2210.00030 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Crossing the human-robot embodiment gap with sim-to-real rl using one human demonstration,
Crossing the human-robot embodiment gap with sim-to-real rl using one human demonstration , author=. arXiv preprint arXiv:2504.12609 , year=
-
[11]
International Conference on Learning Representations , volume=
Latent action pretraining from videos , author=. International Conference on Learning Representations , volume=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
H-rdt: Human manipulation enhanced bimanual robotic manipulation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
World Action Models are Zero-shot Policies
World action models are zero-shot policies , author=. arXiv preprint arXiv:2602.15922 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Causal World Modeling for Robot Control
Causal World Modeling for Robot Control , author=. arXiv preprint arXiv:2601.21998 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos , author=. arXiv preprint arXiv:2510.21571 , year=
-
[17]
arXiv preprint arXiv:2505.08787 , year=
Uniskill: Imitating human videos via cross-embodiment skill representations , author=. arXiv preprint arXiv:2505.08787 , year=
-
[18]
Phantom: Training Robots Without Robots Using Only Human Videos
Phantom: Training robots without robots using only human videos , author=. arXiv preprint arXiv:2503.00779 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Masquerade: Learning from In-the-wild Human Videos using Data-Editing
Masquerade: Learning from in-the-wild human videos using data-editing , author=. arXiv preprint arXiv:2508.09976 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
From human videos to robot manipulation: A survey on scalable vision-language-action learning with human-centric data , author=. arXiv preprint arXiv:2606.00054 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
RT-1: Robotics Transformer for Real-World Control at Scale
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[23]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Behavioral Cloning from Observation
Behavioral cloning from observation , author=. arXiv preprint arXiv:1805.01954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in neural information processing systems , volume=
Visual reinforcement learning with imagined goals , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.