Computational Challenges in Token Economics: Bridging Economic Theory and AI System Design
Pith reviewed 2026-05-20 12:56 UTC · model grok-4.3
The pith
Computational feasibility is the governing constraint in applying token economics to AI inference systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We argue that computational feasibility is not merely one dimension of token economics, but its governing constraint: these challenges are driven by fundamental tensions among fine-grained valuation, low-latency execution, and allocation optimality under uncertainty. We introduce the Token Economics Trilemma as a conditional no-free-lunch principle that captures the inherent trade-offs among granularity, real-time performance, and optimality.
What carries the argument
The Token Economics Trilemma, which structures the problem space by capturing trade-offs among granularity in valuation, real-time performance in execution, and optimality in allocation under uncertainty.
If this is right
- Real-time value accounting systems must be developed to track token values at fine granularity without excessive overhead.
- Constrained resource allocation algorithms are needed that optimize under uncertainty while respecting latency requirements.
- AI system architectures should incorporate economic awareness to better manage token-based resource decisions.
- The trilemma suggests that improving one aspect of the system will likely require compromises in the others.
Where Pith is reading between the lines
- Future AI designs might need to prioritize certain trade-offs based on application needs, such as favoring speed in interactive systems.
- This framework could extend to other AI components beyond tokens, like attention mechanisms or model parameters.
- Empirical studies simulating the trilemma in actual inference setups could quantify the trade-off curves.
- Integration with existing economic models from distributed computing might yield hybrid solutions.
Load-bearing premise
The tensions among fine-grained valuation, low-latency execution, and allocation optimality under uncertainty are fundamental and irreducible rather than solvable through future engineering advances.
What would settle it
A demonstration of an AI inference system that simultaneously achieves high-granularity token valuation, sub-millisecond latency for decisions, and provably optimal allocation despite uncertainty would falsify the trilemma.
Figures


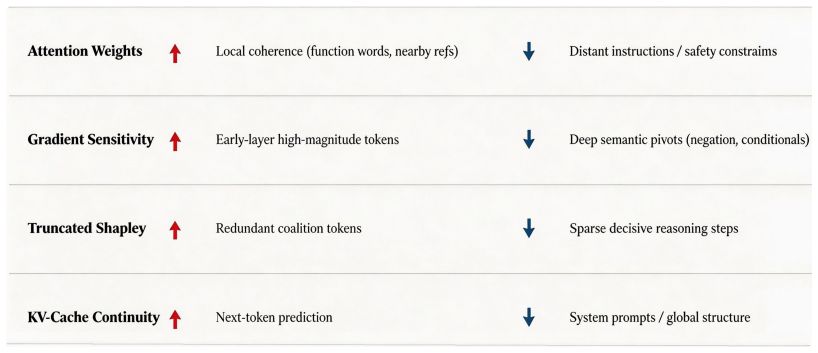

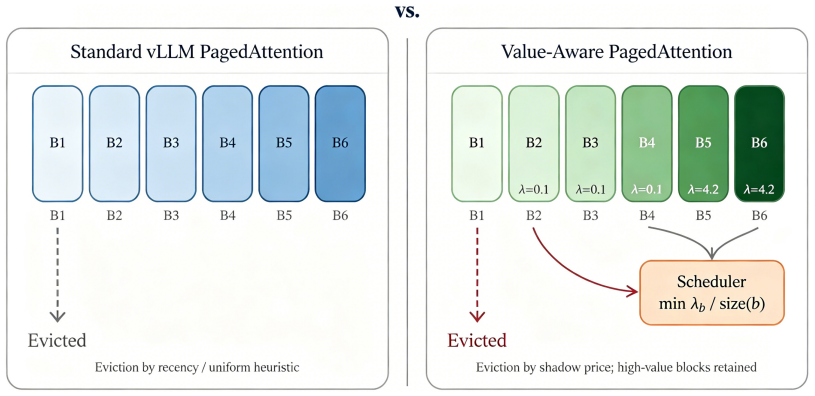
read the original abstract
Token economics has emerged as a useful lens for understanding resource allocation, value creation, and pricing in large language model systems. While recent work has increasingly treated tokens as economic primitives, there remains a substantial gap between high-level economic theory and the computational realities of modern AI infrastructure. This paper identifies and analyzes the key computational challenges that arise when token-economic principles are implemented in real-time inference systems. We argue that computational feasibility is not merely one dimension of token economics, but its governing constraint: these challenges are driven by fundamental tensions among fine-grained valuation, low-latency execution, and allocation optimality under uncertainty. To structure this problem space, we introduce the notion of \textbf{Computational Token Economics} and propose the \textbf{Token Economics Trilemma} -- a conditional no-free-lunch principle that captures the inherent trade-offs among granularity, real-time performance, and optimality. We further categorize the main technical challenges into three areas: real-time value accounting, constrained resource allocation, and economic-aware system architecture. Rather than presenting a complete solution, this paper aims to define a research agenda for bridging token economics and AI system design, highlighting open problems at the intersection of computational economics, machine learning systems, and AI infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that computational feasibility is the governing constraint in token economics for AI systems, driven by fundamental tensions among fine-grained valuation, low-latency execution, and allocation optimality under uncertainty. It introduces 'Computational Token Economics' and the 'Token Economics Trilemma' as a conditional no-free-lunch principle to structure the problem space, categorizes challenges into real-time value accounting, constrained resource allocation, and economic-aware system architecture, and positions the work as defining a research agenda rather than providing complete solutions or empirical demonstrations.
Significance. If the trilemma framing and challenge categorization prove useful in guiding future interdisciplinary research, this could be a significant contribution by highlighting open problems at the intersection of computational economics, machine learning systems, and AI infrastructure. The paper correctly identifies an emerging area and avoids overclaiming by explicitly stating it presents no complete solution. However, the absence of formal derivations, proofs, data, or demonstrations that the identified trade-offs are irreducible rather than engineering-contingent limits its immediate technical impact; its primary value is agenda-setting.
major comments (2)
- [Abstract] Abstract: The central claim that computational feasibility is the 'governing constraint' because the challenges are 'driven by fundamental tensions' and the Token Economics Trilemma captures 'inherent trade-offs' among granularity, real-time performance, and optimality rests on an unformalized premise. The manuscript introduces the trilemma by definition as a 'conditional no-free-lunch principle' without a mathematical statement, proof of conditional necessity, or concrete counter-examples showing why advances in algorithms or system architectures cannot relax one or more constraints simultaneously. This is load-bearing for the governing-constraint argument.
- [Challenge categorization sections] The categorization of challenges (real-time value accounting, constrained resource allocation, economic-aware architecture) is presented as structuring the problem space, but without reference to specific existing LLM inference implementations, performance measurements, or attempted mitigations, it is difficult to assess whether the tensions are fundamental or contingent on current design choices.
minor comments (1)
- [Abstract] The abstract and introduction could more explicitly reference motivating examples from current LLM serving systems (e.g., specific token pricing or scheduling mechanisms) to ground the trilemma in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the recognition that the manuscript is positioned as an agenda-setting contribution rather than a complete technical solution. Below we respond to each major comment and indicate planned revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that computational feasibility is the 'governing constraint' because the challenges are 'driven by fundamental tensions' and the Token Economics Trilemma captures 'inherent trade-offs' among granularity, real-time performance, and optimality rests on an unformalized premise. The manuscript introduces the trilemma by definition as a 'conditional no-free-lunch principle' without a mathematical statement, proof of conditional necessity, or concrete counter-examples showing why advances in algorithms or system architectures cannot relax one or more constraints simultaneously. This is load-bearing for the governing-constraint argument.
Authors: We agree that the Token Economics Trilemma is introduced as a conceptual organizing principle rather than a formally derived theorem with proofs or exhaustive counter-examples. The manuscript explicitly states its goal is to define a research agenda and highlight open problems at the intersection of fields, not to deliver complete formal resolutions. In revision we will expand the abstract and introduction to more explicitly discuss the conditional assumptions behind the trilemma, clarify that it is offered as a conditional no-free-lunch framing analogous to other conceptual trilemmas in systems research, and add brief illustrative examples from existing token-based inference pipelines to show how the three dimensions interact in practice. We will not add a full mathematical proof, as that would exceed the paper's stated scope, but the added discussion will better motivate why formalization is a valuable direction for future work. revision: partial
-
Referee: [Challenge categorization sections] The categorization of challenges (real-time value accounting, constrained resource allocation, economic-aware architecture) is presented as structuring the problem space, but without reference to specific existing LLM inference implementations, performance measurements, or attempted mitigations, it is difficult to assess whether the tensions are fundamental or contingent on current design choices.
Authors: We accept that referencing concrete LLM inference systems would help readers distinguish fundamental tensions from those tied to particular engineering choices. In the revised manuscript we will incorporate targeted references to representative implementations (for example, continuous batching techniques, speculative decoding, and memory-management strategies in popular serving frameworks) and briefly describe how their observed performance characteristics map onto the three challenge areas. These additions will be kept concise and will not shift the paper away from its agenda-setting purpose; they will serve only to ground the categorization in current practice. revision: yes
Circularity Check
No circularity: position paper introduces Token Economics Trilemma by definition as research agenda
full rationale
The manuscript is explicitly a position paper that defines Computational Token Economics and proposes the Token Economics Trilemma to structure open challenges. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The central framing is introduced directly as a conditional no-free-lunch principle capturing tensions among granularity, latency, and optimality; this is definitional rather than reduced from prior inputs, self-citations, or ansatzes. No self-citation load-bearing steps, uniqueness theorems imported from the authors, or renamings of known results are present. The paper positions itself as identifying a research agenda rather than deriving results that collapse to its own assumptions by construction, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token economics principles apply directly to resource allocation in real-time LLM inference systems
invented entities (2)
-
Token Economics Trilemma
no independent evidence
-
Computational Token Economics
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We argue that computational feasibility is not merely one dimension of token economics, but its governing constraint: these challenges are driven by fundamental tensions among fine-grained valuation, low-latency execution, and allocation optimality under uncertainty. ... the Token Economics Trilemma — a conditional no-free-lunch principle that captures the inherent trade-offs among granularity, real-time performance, and optimality.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.1 (Token Economics Trilemma, Informal). ... no online policy can simultaneously achieve Granularity: G=N ... Real-time: R≤1 ... Optimality: O=o(1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Token Economics for LLM Agents: A Dual-View Study from Computing and Economics
Y. Chen, J. Chen, C. He, Y. Li, Y. Ji, Y. Wu, D. Yang, L. Diao, L. Shou, H. Zhang, H. Li, and G. Chen, “Token economics for LLM agents: A dual-view study from computing and economics,”arXiv preprint arXiv:2605.09104, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Agentic AI Systems Should Be Designed as Marginal Token Allocators
S. Zhu, “Agentic AI systems should be designed as marginal token allocators,”arXiv preprint arXiv:2605.01214, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
W. Zhong, “Token is all you price,”arXiv preprint arXiv:2510.09859, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
The economics of large language models: Token allocation, fine-tuning, and optimal pricing,
D. Bergemann, A. Bonatti, and A. Smolin, “The economics of large language models: Token allocation, fine-tuning, and optimal pricing,” inProceedings of the 26th ACM Conference on Economics and Computation, 2025
work page 2025
-
[5]
AI token futures market: Commoditization of compute and derivatives contract design,
Y. Xing, “AI token futures market: Commoditization of compute and derivatives contract design,”arXiv preprint arXiv:2603.21690, 2026
-
[6]
Shapley-Coop: Credit assignment for emergent cooperation in self-interested LLM agents,
Y. Hua, H. Chen, S. Wang, W. Li, X. Wang, and J. Luo, “Shapley-Coop: Credit assignment for emergent cooperation in self-interested LLM agents,” inNeurIPS, 2025
work page 2025
-
[7]
TokenButler: Token Importance is Predictable
Y. Akhauri, A. F. AbouElhamayed, Y. Gao, C.-C. Chang, N. Jain, and M. S. Abdelfattah, “TokenButler: Token importance is predictable,”arXiv preprint arXiv:2503.07518, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
TokenShapley: Token level context attribution with shapley value,
Y. Xiao, Y. Zhu, S. Samyoun, W. Zhang, J. T. Wang, and J. Du, “TokenShapley: Token level context attribution with shapley value,” inFindings of ACL, 2025, pp. 3882–3894. 40
work page 2025
-
[9]
Utility-Aware Data Pricing: Token-Level Quality and Empirical Training Gain for LLMs
M. Xu, Q. Luo, and K. Li, “Utility-aware data pricing: Token-level quality and empirical training gain for LLMs,”arXiv preprint arXiv:2604.22893, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Is your LLM overcharging you? tokenization, transparency, and incentives,
A. A. Velasco, S. Tsirtsis, N. Okati, and M. Gomez-Rodriguez, “Is your LLM overcharging you? tokenization, transparency, and incentives,” inICML 2025 Workshop on Tokenization (TokShop), 2025
work page 2025
-
[11]
CoIn: Counting the invisible reasoning tokens in commercial opaque LLM APIs,
G. Sun, Z. Wang, B. Tian, M. Liu, Z. Shen, S. He, Y. He, W. Ye, Y. Wang, and A. Li, “CoIn: Counting the invisible reasoning tokens in commercial opaque LLM APIs,”arXiv preprint arXiv:2505.13778, 2025
-
[12]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
M. Reidet al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
A. Dubeyet al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. [14]RULER: What’s the Real Context Size of Your Long-Context Language Models?, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
T. Munkhdalai, M. Faruqui, and S. Gopal, “Leave no context behind: Efficient infinite context transformers with Infini-attention,”arXiv preprint arXiv:2404.07143, 2024
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, “Kimi k1.5: Scaling reinforcement learning with LLMs,”arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling llm test-time compute optimally can be more effective than scaling model parameters,”arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
SARATHI- SERVE: Efficient LLM inference by piggybacking decodes with chunked prefills,
A. Agrawal, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, and R. Ramjee, “SARATHI- SERVE: Efficient LLM inference by piggybacking decodes with chunked prefills,”arXiv preprint arXiv:2403.02310, 2024
-
[19]
Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Dis- aggregating prefill and decoding for goodput-optimized large language model serving,”arXiv preprint arXiv:2401.09670, 2024
-
[20]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache,
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V. Braverman, B. Chen, and X. Hu, “Kivi: A tuning-free asymmetric 2bit quantization for kv cache,” inICML, 2024
work page 2024
-
[21]
SnapKV: LLM Knows What You are Looking for Before Generation
Y. Li, Y. Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “SnapKV: LLM knows what you are looking for before generation,”arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, “DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model,”arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Arbitrage: Efficient reasoning via advantage-aware speculation,
M. Maheswaran, R. Tiwari, Y. Hu, K. Dilmen, C. Hooper, H. Xi, N. Lee, M. Farajtabar, M. W. Mahoney, K. Keutzer, and A. Gholami, “Arbitrage: Efficient reasoning via advantage-aware speculation,”arXiv preprint arXiv:2512.05033, 2025. 41
-
[24]
TopLoc: A locality sensitive hashing scheme for trustless verifiable inference,
J. M. Ong, M. D. Ferrante, A. Pazdera, R. Garner, S. Jaghouar, M. Basra, M. Ryabinin, and J. Hagemann, “TopLoc: A locality sensitive hashing scheme for trustless verifiable inference,” arXiv preprint arXiv:2501.16007, 2025
-
[25]
Inference economics: A new paradigm for the economics of artificial intelligence,
BRASS DIGITAL LAB, “Inference economics: A new paradigm for the economics of artificial intelligence,” BRASS DIGITAL LAB, Tech. Rep., 2026
work page 2026
-
[26]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Sto- ica, “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[27]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, J. Huang, C. Sun, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y. Sheng, “Sglang: Efficient execution of structured language model programs,” inNeurIPS, 2024, pp. 62 557–62 583
work page 2024
-
[28]
Flashattention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning,” in Proceedings of the ICLR, ser. ICLR, 2024
work page 2024
-
[29]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
J. Shah, G. Bikshandi, Y. Zhang, V. Thakkar, P. Ramani, and T. Dao, “Flashattention-3: Fast and accurate attention with asynchrony and low-precision,”arXiv preprint arXiv:2407.08608, 2024
work page internal anchor Pith review arXiv 2024
-
[30]
H 2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. R´ e, C. Barrett, Z. Wang, and B. Chen, “H 2o: Heavy-hitter oracle for efficient generative inference of large language models,” inNeurIPS, 2023
work page 2023
-
[31]
Z. Liu, A. Desai, F. Lian, H. Wang, H. Xie, Y. Zhang, T. Chen, and Z. Wang, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,” inNeurIPS, 2023
work page 2023
-
[32]
Efficient streaming language models with attention sinks,
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” inICLR, 2024
work page 2024
-
[33]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Z. Cai, Y. Zhang, B. Gao, Y. Liu, T. Li, K. Liu, H. Lin, X. Lu, and S. Han, “Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling,”arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Fast inference from transformers via speculative decoding,
Y. Leviathan, M. Kalman, and Y. Matias, “Fast inference from transformers via speculative decoding,” inICML, 2023
work page 2023
-
[35]
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, Z. Wong, Z. Chen, D. Arfeen, R. Abhyankar, and Z. Jia, “Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification,” inASPLOS, 2024, pp. 932–949
work page 2024
-
[36]
Medusa: Simple llm inference acceleration framework with multiple decoding heads,
T. Cai, Y. Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple llm inference acceleration framework with multiple decoding heads,” inICML, 2024
work page 2024
-
[37]
Eagle: Speculative sampling requires rethinking feature uncertainty,
Y. Li, F. Wei, C. Zhang, and H. Zhang, “Eagle: Speculative sampling requires rethinking feature uncertainty,” inICML, 2024
work page 2024
-
[38]
Lookahead decoding: Lossless generation accelera- tion for large language models,
Y. Fu, P. Bailis, I. Stoica, and H. Zhang, “Lookahead decoding: Lossless generation accelera- tion for large language models,” inICML, 2024. 42
work page 2024
-
[39]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “Frugalgpt: How to use large language models while reducing cost and improving performance,”arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
RouteLLM: Learning to Route LLMs with Preference Data
I. Ong, A. Almahairi, V. Wu, W.-L. Chiang, T. Wu, J. E. Gonzalez, and I. Stoica, “Routellm: Learning to route llms with preference data,”arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”TACL, vol. 12, pp. 157–173, 2024
work page 2024
-
[42]
Longbench: A bilingual, multitask benchmark for long context understanding,
Y. Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y. Dong, J. Tang, and J. Li, “Longbench: A bilingual, multitask benchmark for long context understanding,” inACL, 2024
work page 2024
-
[43]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inICLR, 2023
work page 2023
-
[44]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inNeurIPS, 2023
work page 2023
-
[45]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess` ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inNeurIPS, 2023
work page 2023
-
[46]
Voyager: An open-ended embodied agent with large language models,
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar, “Voyager: An open-ended embodied agent with large language models,”TMLR, 2024
work page 2024
-
[47]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,” inNeurIPS, 2024
work page 2024
-
[48]
Orca: A distributed serving system for transformer-based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for transformer-based generative models,” inOSDI, 2022, pp. 521–538
work page 2022
-
[49]
A. Borodin and R. El-Yaniv,Online Computation and Competitive Analysis. Cambridge, UK: Cambridge University Press, 1998
work page 1998
-
[50]
Introduction to online convex optimization,
E. Hazan, “Introduction to online convex optimization,”Foundations and Trends in Optimiza- tion, vol. 2, no. 3–4, pp. 157–325, 2016
work page 2016
-
[51]
Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services,
S. Gilbert and N. Lynch, “Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services,”ACM SIGACT News, vol. 33, no. 2, pp. 51–59, 2002
work page 2002
-
[52]
Efficient mechanisms for bilateral trading,
R. B. Myerson and M. A. Satterthwaite, “Efficient mechanisms for bilateral trading,”Journal of Economic Theory, vol. 29, no. 2, pp. 265–281, 1983
work page 1983
-
[53]
L. S. Shapley, “A value for n-person games,” inContributions to the Theory of Games II, H. W. Kuhn and A. W. Tucker, Eds. Princeton, NJ, USA: Princeton University Press, 1953
work page 1953
-
[54]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. R´ e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” inNeurIPS, 2022, pp. 16 344–16 359
work page 2022
-
[55]
Shadow in the cache: Unveiling and mitigating privacy risks of KV-cache in LLM inference,
Z. Luo, S. Shao, S. Zhang, L. Zhou, Y. Hu, C. Zhao, Z. Liu, and Z. Qin, “Shadow in the cache: Unveiling and mitigating privacy risks of KV-cache in LLM inference,” inProceedings of the 33rd Network and Distributed System Security Symposium (NDSS), 2026. 43
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.