Position Rebinding Cache Reuse: Replay-Free Visual Revisiting for Interleaved Multimodal Reasoning
Pith reviewed 2026-06-26 05:06 UTC · model grok-4.3
The pith
Rebinding positions to cached visual keys enables replay-free visual revisiting without attention distortion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
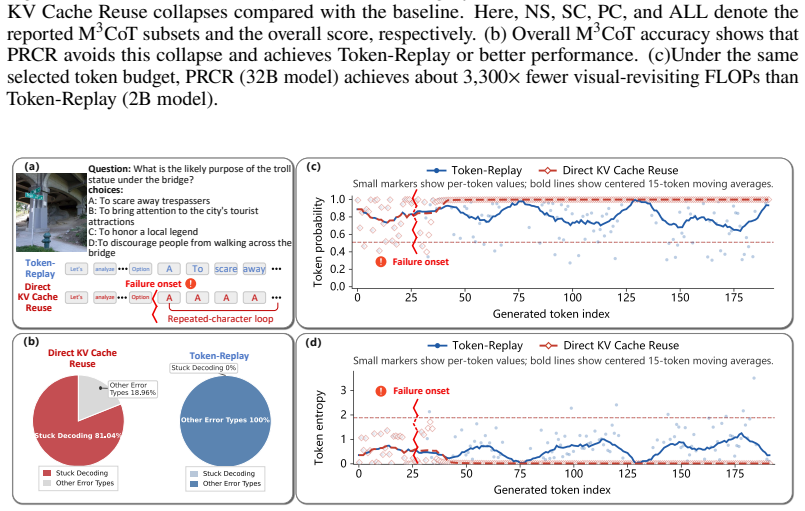
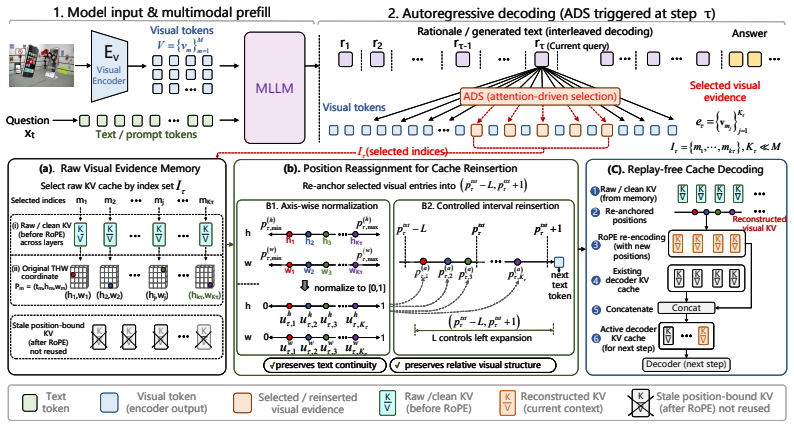
PRCR stores raw visual KV cache entries together with their original spatial coordinates, then reassigns position-compatible coordinates to selected entries and rebinds their keys before injecting the reconstructed cache into the active decoder cache, thereby reusing historical visual evidence while avoiding the autoregressive collapse that occurs with stale positional bindings.
What carries the argument
Position rebinding, which reconstructs visual evidence by reassigning coordinates to cached keys and rebinding them to match the current decoding state.
If this is right
- Multimodal models can revisit visual evidence during generation without repeating forward passes on the same tokens.
- Average accuracy on reasoning benchmarks rises by about 5 percent relative to replay baselines.
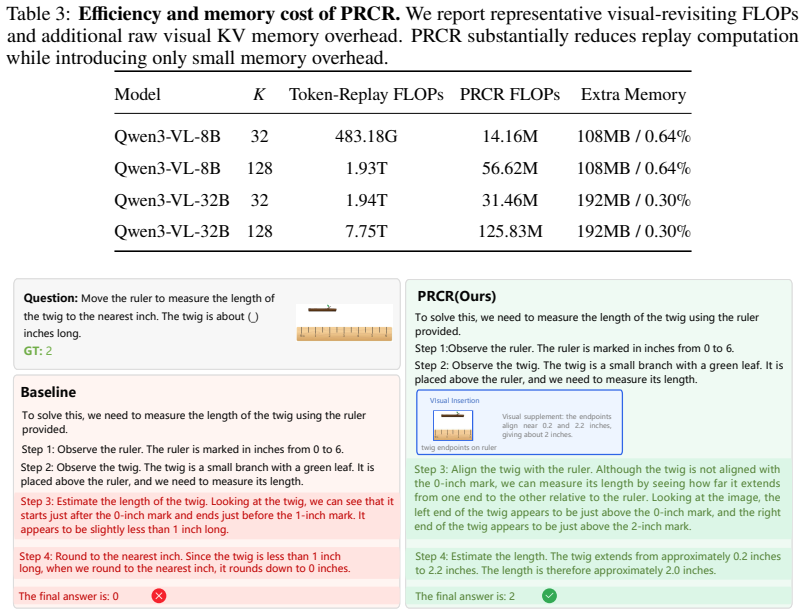
- Visual-revisiting computation drops by up to tens of thousands of times while matching replay-level performance.
- Textual positional continuity is maintained even as visual caches are reused across multiple reasoning steps.
Where Pith is reading between the lines
- The same rebinding idea might extend to audio or other sensory caches in long-horizon agents.
- PRCR could be combined with eviction policies to keep only the most reusable visual entries in memory.
- If coordinate reassignment proves robust, similar cache reuse might apply to non-visual modalities that suffer positional drift.
Load-bearing premise
Reassigning position-compatible coordinates to selected cached visual entries and rebinding their keys will preserve relative visual structure and avoid attention distortion under new decoding contexts.
What would settle it
A controlled comparison on an interleaved multimodal benchmark where PRCR produces lower accuracy or visible attention collapse than full token replay under identical model and prompt conditions.
Figures




read the original abstract
Interleaved multimodal reasoning improves visual grounding by revisiting visual evidence during multi-step generation, yet existing methods typically rely on token replay, repeatedly forwarding selected visual tokens. A natural shortcut is to reuse the historical visual key-value (KV) cache directly. However, we identify a critical failure mode of this strategy: cached visual keys are already bound to their original positional context. Such stale positional binding distorts attention under later decoding contexts and can trigger severe autoregressive decoding collapse. This failure suggests that effective cache reuse requires reconstructing visual evidence under positions compatible with the current decoding state, rather than directly copying position-bound historical cache entries. To this end, we propose Position Rebinding Cache Reuse (PRCR), a cache-level framework for replay-free visual revisiting. PRCR stores raw visual KV cache together with their original spatial coordinates, then reassigns position-compatible coordinates to select entries and rebinds their keys before injecting the reconstructed cache into the active decoder cache. This design reuses historical visual evidence while preserving textual positional continuity and relative visual structure. Experiments across multiple multimodal reasoning benchmarks show that PRCR achieves replay-level or better performance, improving average accuracy by 5 percent and reducing visual-revisiting computation by up to tens of thousands of times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Position Rebinding Cache Reuse (PRCR) to enable replay-free visual revisiting during interleaved multimodal reasoning. It identifies that direct reuse of historical visual KV cache entries fails because the keys remain bound to their original positional context, distorting attention and risking autoregressive collapse under new decoding states. PRCR stores raw visual KV entries with their original spatial coordinates, then reassigns position-compatible coordinates to selected entries and rebinds their keys before injection into the active decoder cache. The authors claim this preserves textual positional continuity and relative visual structure, achieving replay-level or superior performance with a 5% average accuracy gain and up to tens-of-thousands-fold reduction in visual-revisiting computation across multiple benchmarks.
Significance. If the rebinding step is shown to correctly update key interactions with the current positional context, the result would be significant for efficient long-context multimodal models. The approach targets a practical bottleneck in vision-language reasoning by eliminating repeated visual token forwarding while maintaining accuracy, and the reported efficiency gains could enable more complex interleaved tasks. The identification of the stale positional binding failure mode is a clear contribution independent of the specific fix.
major comments (1)
- [Abstract] Abstract: The rebinding operation is described only as 'rebinds their keys' after coordinate reassignment, with no equation, algorithm, pseudocode, or implementation detail on whether keys are recomputed via the projection matrix with new positional embeddings or via another adjustment. This is load-bearing for the central claim because the replay-free guarantee and the reported accuracy/compute gains rest entirely on the rebinding succeeding where direct cache reuse fails, as noted in the stress-test concern.
minor comments (1)
- [Abstract] Abstract: The experimental claims (5% accuracy gain, 'multiple multimodal reasoning benchmarks', 'tens of thousands of times' reduction) are stated without naming the benchmarks, baselines, number of runs, or error bars; these details belong in the main text but their absence from the abstract reduces verifiability.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity on the rebinding mechanism, which is indeed central to the PRCR contribution. We agree that the abstract's brevity leaves the precise implementation of key rebinding underspecified and will revise to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The rebinding operation is described only as 'rebinds their keys' after coordinate reassignment, with no equation, algorithm, pseudocode, or implementation detail on whether keys are recomputed via the projection matrix with new positional embeddings or via another adjustment. This is load-bearing for the central claim because the replay-free guarantee and the reported accuracy/compute gains rest entirely on the rebinding succeeding where direct cache reuse fails, as noted in the stress-test concern.
Authors: We acknowledge that the abstract provides only a high-level description of the rebinding step. In the full manuscript (Section 3.2 and Algorithm 1), the rebinding is implemented by re-computing the key projections using the original value vectors and the new position-compatible rotary embeddings (i.e., K' = W_k * V_original with updated RoPE angles derived from the reassigned coordinates), rather than a simple additive adjustment. This ensures the keys reflect the current positional context while preserving the cached visual content. We will revise the abstract to include a concise statement of this mechanism and add an explicit equation for the rebinding operation. We will also expand the stress-test discussion to quantify the failure of direct reuse versus PRCR. revision: yes
Circularity Check
No circularity: PRCR is an independent algorithmic design with separate empirical validation
full rationale
The paper proposes PRCR as a cache-reuse framework that stores raw visual KV entries with spatial coordinates, reassigns compatible positions, and rebinds keys. This design is stated directly in the abstract without reduction to fitted parameters, self-citations, or prior author results. No equations appear in the provided text, and the reported accuracy/efficiency gains are attributed to benchmark experiments rather than any quantity defined by construction from the method inputs. The central assumption about rebinding preserving structure is presented as a design hypothesis, not a self-referential derivation. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of key-value caches and positional encodings in decoder-only transformer models
invented entities (1)
-
Position Rebinding Cache Reuse (PRCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
2022
-
[2]
LLaVA-OneVision-1.5: Fully open framework for democratized multimodal training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, XiyaoWang,BinQin,YumengWang,ZizhenYan,ZiyongFeng,ZiweiLiu,BoLi,andJiankang Deng. LLaVA-OneVision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:250...
Pith/arXiv arXiv 2025
-
[3]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[4]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[5]
Perceptiontokensenhancevisualreasoninginmultimodallanguagemodels
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, andRanjayKrishna. Perceptiontokensenhancevisualreasoninginmultimodallanguagemodels. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3836–3845, 2025
2025
-
[6]
Chao Chen, Zhixin Ma, Yongqi Li, Yupeng Hu, Yinwei Wei, Wenjie Li, and Liqiang Nie. Reasoning in the dark: Interleaved vision-text reasoning in latent space.arXiv preprint arXiv:2510.12603, 2025
arXiv 2025
-
[7]
Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
LinChen,JinsongLi,XiaoyiDong,PanZhang,YuhangZang,ZehuiChen,HaodongDuan,Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
2024
-
[8]
M3CoT: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought
Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3CoT: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 8199–8221, 2024
2024
-
[9]
MINT-CoT:Enablinginterleavedvisualtokensinmathematicalchain-of-thought reasoning
Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, and HongshengLi. MINT-CoT:Enablinginterleavedvisualtokensinmathematicalchain-of-thought reasoning. InAdvances in Neural Information Processing Systems, 2025
2025
-
[10]
Visual thoughts: A unified perspective of understanding multimodal chain-of-thought
Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, and Libo Qin. Visual thoughts: A unified perspective of understanding multimodal chain-of-thought. InAdvances in Neural Information Processing Systems, 2025
2025
-
[11]
Comt: A novel benchmark for chain of multi-modal thought on large vision-language models
Zihui Cheng, Qiguang Chen, Jin Zhang, Hao Fei, Xiaocheng Feng, Wanxiang Che, Min Li, and Libo Qin. Comt: A novel benchmark for chain of multi-modal thought on large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23678–23686, 2025
2025
-
[12]
Drivingvqa: A dataset for interleaved visual chain-of-thought in real-world driving scenarios
Charles Corbière, Simon Roburin, Syrielle Montariol, Antoine Bosselut, and Alexandre Alahi. Drivingvqa: A dataset for interleaved visual chain-of-thought in real-world driving scenarios. InFindings of the Association for Computational Linguistics: EACL 2026, pages 3309–3333, 2026
2026
-
[13]
Instructblip: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. volume 36, pages 49250–49267, 2023
2023
-
[14]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19520–19529, 2025. 12
2025
-
[15]
Guangfu Guo, Xiaoqian Lu, Yue Feng, and Mingming Sun. Beyond static visual tokens: Structured sequential visual chain-of-thought reasoning.arXiv preprint arXiv:2603.26737, 2026
arXiv 2026
-
[16]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xiaoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3302–3310, 2025
2025
-
[17]
Wenyi Hong et al. GLM-4.1V-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
Pith/arXiv arXiv 2025
-
[18]
Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, and Shikun Zhang. Vlm-R3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought.arXiv preprint arXiv:2505.16192, 2025
arXiv 2025
-
[19]
MME-CoT: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency
DongzhiJiang,RenruiZhang,ZiyuGuo,YanweiLi,YuQi,XinyanChen,LiuhuiWang,Jianhan Jin, Claire Guo, Shen Yan, Bo Zhang, Chaoyou Fu, Peng Gao, and Hongsheng Li. MME-CoT: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness, and efficiency. InProceedings of the 42nd International Conference on Machine Learning, pages 27793–27...
2025
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: Bootstrapping language- image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, pages 19730–19742, 2023
2023
-
[21]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems, volume 36, pages 34892–34916, 2023
2023
-
[22]
Improved baselines with visual instructiontuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instructiontuning. InProceedingsoftheIEEE/CVFConferenceonComputerVisionandPattern Recognition, pages 26296–26306, 2024
2024
-
[23]
Let’s think with images efficiently! an interleaved-modal chain-of-thought reasoning framework with dynamic and precise visual thoughts
Xu Liu, Yongheng Zhang, Qiguang Chen, Yao Li, Sheng Wang, and Libo Qin. Let’s think with images efficiently! an interleaved-modal chain-of-thought reasoning framework with dynamic and precise visual thoughts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32213–32221, 2026
2026
-
[24]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
2022
-
[25]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyang Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations, 2024
2024
-
[26]
Visual CoT: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual CoT: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. InAdvances in Neural Information Processing Systems, volume 37, pages 8612–8642, 2024
2024
-
[27]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
Pith/arXiv arXiv 2025
-
[28]
Mitigating low-quality reasoning in mllms: Self-driven refined multimodal cot with selective thinking and step-wise visualenhancement
Chongjun Tu, Peng Ye, Dongzhan Zhou, Tao Chen, and Wanli Ouyang. Mitigating low-quality reasoning in mllms: Self-driven refined multimodal cot with selective thinking and step-wise visualenhancement. InProceedingsoftheAAAIConferenceonArtificialIntelligence,volume40, pages 9576–9584, 2026. 13
2026
-
[29]
Disentangling inter- and intra-video relations for multi-event video-text retrieval and grounding
Mengzhao Wang, Huafeng Li, Yafei Zhang, Jinxing Li, Dapeng Tao, and Zhengtao Yu. Disentangling inter- and intra-video relations for multi-event video-text retrieval and grounding. IEEE Transactions on Image Processing, 34:7558–7571, 2025
2025
-
[30]
WeiyunWang,ZhangweiGao,LixinGu,HengjunPu,LongCui,XingguangWei,ZhaoyangLiu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[31]
Timerefine: Temporal grounding with time refining video llm
XiziWang,FengCheng,ZiyangWang,HuiyuWang,MdMohaiminulIslam,LorenzoTorresani, Mohit Bansal, Gedas Bertasius, and David Crandall. Timerefine: Temporal grounding with time refining video llm. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5067–5078, 2026
2026
-
[32]
Self-consistencyimproveschainofthoughtreasoninginlanguage models
XuezhiWang,JasonWei,DaleSchuurmans, QuocV.Le,EdH.Chi,SharanNarang, Aakanksha Chowdhery,andDennyZhou. Self-consistencyimproveschainofthoughtreasoninginlanguage models. InInternational Conference on Learning Representations, 2023
2023
-
[33]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvancesinNeuralInformationProcessingSystems,volume35,pages24824–24837, 2022
2022
-
[34]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
2087
-
[35]
Chain-of-thought provably enables learn- ing the (otherwise) unlearnable
Chenxiao Yang, Zhiyuan Li, and David Wipf. Chain-of-thought provably enables learn- ing the (otherwise) unlearnable. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Timeexpert: An expert- guided video llm for video temporal grounding
Zuhao Yang, Yingchen Yu, Yunqing Zhao, Shijian Lu, and Song Bai. Timeexpert: An expert- guided video llm for video temporal grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24286–24296, 2025
2025
-
[37]
Mmmu: Amassivemulti-disciplinemultimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, DongfuJiang,WeimingRen,YuxuanSun,etal. Mmmu: Amassivemulti-disciplinemultimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[38]
Huanyu Zhang, Wenshan Wu, Chengzu Li, Ning Shang, Yan Xia, Yangyu Huang, Yifan Zhang, Li Dong, Zhang Zhang, Liang Wang, Tieniu Tan, and Furu Wei. Latent sketchpad: Sketching visual thoughts to elicit multimodal reasoning in MLLMs.arXiv preprint arXiv:2510.24514, 2025
arXiv 2025
-
[39]
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alexander J. Smola. Multimodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
Pith/arXiv arXiv 2023
-
[40]
Unsupervised visual chain-of- thought reasoning via preference optimization
Kesen Zhao, Beier Zhu, Qianru Sun, and Hanwang Zhang. Unsupervised visual chain-of- thought reasoning via preference optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2303–2312, 2025
2025
-
[41]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1702–1713, 2025
2025
-
[42]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 14
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.