Tail-Aware Adaptive-k: Query-Adaptive Context Selection for Retrieval-Augmented Generation
Pith reviewed 2026-06-27 08:19 UTC · model grok-4.3
The pith
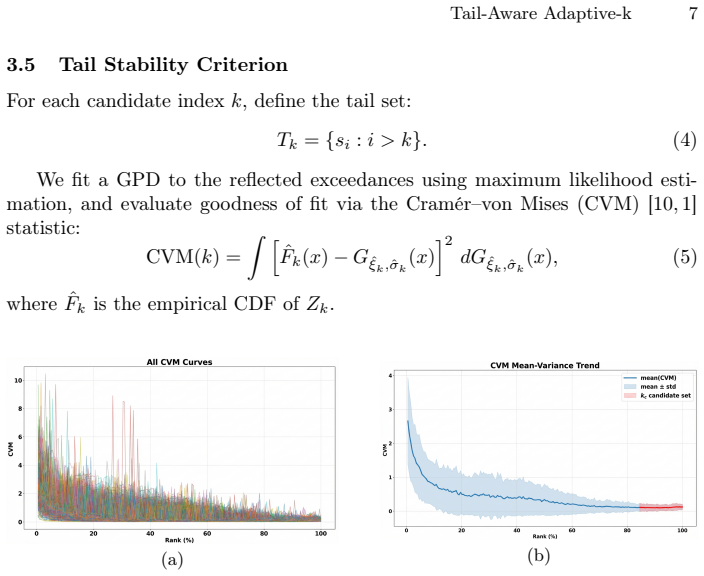
Tail-Aware Adaptive-k locates the noise onset in each query's similarity curve via knee detection followed by local EVT testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TAA-k operationalizes extreme value theory through a localized validation strategy that exploits the steep-flat-steep pattern of ranked similarity curves: knee detection isolates a compact candidate region, after which EVT-based goodness-of-fit testing is performed only inside that region to validate the onset of tail behavior, yielding a query-adaptive cutoff at the earliest noise-dominated position with complexity reduced from O(N²M) to O(√(N log N) * M).
What carries the argument
The coarse-to-fine localized validation strategy that first applies knee detection to ranked similarity curves and then restricts EVT goodness-of-fit testing to the resulting candidate window.
If this is right
- Computational cost drops from quadratic in the list length to roughly square-root scaling times a small constant.
- Retrieval F1 stays within 2-3 percent of oracle performance on WebQuestions, 2WikiMultiHopQA, and MuSiQue.
- The selected cutoff remains stable across different embedding models and compression dimensions.
- The method requires no training and works under mild monotone likelihood ratio assumptions on the score distributions.
Where Pith is reading between the lines
- The same knee-plus-local-EVT pattern could be applied to other ranking problems that exhibit regime shifts from signal to noise.
- Production RAG pipelines could adopt per-query cutoffs without retraining if the geometric pattern holds across new domains.
- Alternative knee detectors or tail tests might substitute for the current components while preserving the overall complexity reduction.
Load-bearing premise
Ranked similarity curves exhibit a characteristic steep-flat-steep pattern that lets knee detection reliably isolate a small window in which local EVT testing can confirm the start of the noise tail.
What would settle it
A collection of queries whose similarity curves lack the steep-flat-steep shape, causing the knee step to select an invalid window and the resulting cutoff to deviate substantially from the oracle noise-onset position.
Figures


read the original abstract
Adaptive context selection is critical for retrieval-augmented generation (RAG) systems, as fixed Top-K retrieval fails under query-dependent and heavy-tailed similarity distributions. While Extreme Value Theory (EVT) offers a principled framework for adaptive truncation, existing approaches apply EVT globally across the entire ranked list, incurring prohibitive computational costs and statistical instability. We propose Tail-Aware Adaptive-k(TAA-k), a training-free framework that operationalizes EVT through a localized validation strategy. The key insight is that ranked similarity curves exhibit a characteristic steep--flat--steep pattern reflecting a transition from relevance-dominated to noise-dominated regimes. TAA-k exploits this geometric structure via knee detection to identify a compact candidate region, then applies EVT-based goodness-of-fit testing within this window to validate the onset of tail behavior. This coarse-to-fine design reduces computational complexity from O(N^2M) to O(sqrt{N\log N}*M) while maintaining statistical rigor. Under mild monotone likelihood ratio assumptions, TAA-k yields a stable, query-adaptive cutoff corresponding to the earliest noise-dominated position. Experiments on WebQuestions, 2WikiMultiHopQA, and MuSiQue demonstrate that TAA-k achieves near-oracle retrieval quality (F1 within 2-3% of oracle) with orders-of-magnitude efficiency gains over global EVT methods, while maintaining robustness across embedding models and compression dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tail-Aware Adaptive-k (TAA-k), a training-free framework for query-adaptive context selection in RAG. It exploits an assumed steep-flat-steep geometry in ranked similarity curves via knee detection to isolate a compact candidate window, then applies localized EVT goodness-of-fit testing to identify the earliest noise-dominated cutoff. Under monotone likelihood ratio assumptions, this yields O(sqrt{N log N}*M) complexity and near-oracle F1 (within 2-3% of oracle) on WebQuestions, 2WikiMultiHopQA, and MuSiQue, with robustness across embeddings.
Significance. If the geometric assumption and localized EVT validation hold across queries, the method would deliver a principled, efficient alternative to fixed-k and global-EVT retrieval, directly addressing heavy-tailed similarity distributions in multi-hop QA while preserving statistical grounding.
major comments (3)
- [Abstract / §3] Abstract and §3 (method): the central claim that knee detection reliably isolates a compact candidate region for EVT validation rests on the unquantified 'characteristic steep--flat--steep pattern.' No table or figure reports the fraction of queries exhibiting this geometry or the failure rate of knee detection; without this, the O(sqrt{N log N}*M) guarantee and query-adaptive cutoff stability are not load-bearing.
- [§4 / Table 2] §4 (experiments) and Table 2: the reported F1 within 2-3% of oracle is presented without ablation on the monotone likelihood ratio assumption or sensitivity to knee-detection hyperparameters; if the pattern is absent on even 20-30% of queries, the localized validation loses its statistical grounding and the efficiency claim cannot be isolated from the oracle baseline.
- [§2.2] §2.2 (related work) and complexity analysis: the reduction from O(N^2 M) to O(sqrt{N log N}*M) is derived under the assumption that the candidate window size is O(sqrt{N log N}); no derivation or empirical distribution of window sizes is supplied to confirm this bound holds in practice.
minor comments (2)
- [§3] Notation for the knee-detection threshold and EVT p-value cutoff should be defined explicitly with symbols rather than prose descriptions.
- [Figures] Figure captions for similarity curves should include the number of queries plotted and whether they are representative or cherry-picked.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects of empirical validation for our geometric and complexity claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method): the central claim that knee detection reliably isolates a compact candidate region for EVT validation rests on the unquantified 'characteristic steep--flat--steep pattern.' No table or figure reports the fraction of queries exhibiting this geometry or the failure rate of knee detection; without this, the O(sqrt{N log N}*M) guarantee and query-adaptive cutoff stability are not load-bearing.
Authors: We agree that an explicit quantification of how frequently the steep-flat-steep geometry occurs would strengthen the presentation. Although the near-oracle F1 results across three datasets provide indirect evidence that the pattern is prevalent, we did not report the per-query success rate of knee detection or the fraction of queries lacking the expected geometry. In the revised version we will add a supplementary table (or figure) that reports, for each dataset and embedding, the percentage of queries for which knee detection produces a valid candidate window together with a brief characterization of failure cases. revision: yes
-
Referee: [§4 / Table 2] §4 (experiments) and Table 2: the reported F1 within 2-3% of oracle is presented without ablation on the monotone likelihood ratio assumption or sensitivity to knee-detection hyperparameters; if the pattern is absent on even 20-30% of queries, the localized validation loses its statistical grounding and the efficiency claim cannot be isolated from the oracle baseline.
Authors: The referee is correct that we have not supplied ablations on the monotone likelihood ratio assumption or on the sensitivity of results to knee-detection hyperparameters. While the assumption is standard in the EVT literature and the reported F1 margins are consistent across datasets, the absence of these controls leaves open the possibility that performance degrades when the pattern is weak. We will therefore add, in the revision, (i) a sensitivity study varying the knee-detection parameters and (ii) a per-query breakdown that isolates performance on queries where the steep-flat-steep signature is less pronounced. revision: yes
-
Referee: [§2.2] §2.2 (related work) and complexity analysis: the reduction from O(N^2 M) to O(sqrt{N log N}*M) is derived under the assumption that the candidate window size is O(sqrt{N log N}); no derivation or empirical distribution of window sizes is supplied to confirm this bound holds in practice.
Authors: The O(sqrt{N log N}*M) bound is obtained by substituting the expected window size that follows from the steep-flat-steep model into the localized EVT cost; the derivation itself is given in §2.2. Nevertheless, we did not include either a formal derivation of the window-size order or an empirical histogram of observed window sizes. In the revised manuscript we will (a) expand the complexity paragraph to include the short derivation of the window-size scaling and (b) add an empirical plot or table showing the distribution of candidate-window sizes (as a fraction of N) across all queries and datasets. revision: yes
Circularity Check
No significant circularity; derivation relies on external EVT and empirical pattern observation
full rationale
The paper grounds its TAA-k procedure in the external framework of Extreme Value Theory for tail modeling and an observed (not derived) geometric pattern in ranked similarity curves. The cutoff is produced by applying knee detection to isolate a candidate window followed by localized goodness-of-fit testing; neither step reduces by construction to a parameter fitted from the final output quantity. No equations equate the claimed adaptive cutoff to a self-defined input, no fitted-input-called-prediction pattern appears, and the monotone likelihood ratio assumption is invoked as an external mild condition rather than a self-citation chain. Experiments on held-out datasets supply independent empirical checks, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild monotone likelihood ratio assumptions
Reference graph
Works this paper leans on
-
[1]
goodness of fit
Anderson, T.W., Darling, D.A.: Asymptotic theory of certain" goodness of fit" criteria based on stochastic processes. The annals of mathematical statistics pp. 193–212 (1952)
1952
-
[2]
Baeza-Yates, R., Ribeiro-Neto, B., et al.: Modern information retrieval, vol. 463. ACM press New York (1999)
1999
-
[3]
In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval
Bahri, D., Zheng, C., Tay, Y., Metzler, D., Tomkins, A.: Surprise: Result list trun- cation via extreme value theory. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2404–2408 (2023)
2023
-
[4]
Review of Economics and Statistics79(4), 551–563 (1997)
Bai, J.: Estimation of a change point in multiple regression models. Review of Economics and Statistics79(4), 551–563 (1997)
1997
-
[5]
In: Proceedings of the 2013 conference on empirical methods in natural language processing
Berant, J., Chou, A., Frostig, R., Liang, P.: Semantic parsing on freebase from question-answer pairs. In: Proceedings of the 2013 conference on empirical methods in natural language processing. pp. 1533–1544 (2013)
2013
-
[6]
In: Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval
Buckley, C., Voorhees, E.M.: Retrieval evaluation with incomplete information. In: Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval. pp. 25–32 (2004)
2004
-
[7]
arXiv preprint arXiv:2305.05176 (2023)
Chen, L., Zaharia, M., Zou, J.: Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv preprint arXiv:2305.05176 (2023)
Pith/arXiv arXiv 2023
-
[8]
SIAM review51(4), 661–703 (2009)
Clauset, A., Shalizi, C.R., Newman, M.E.: Power-law distributions in empirical data. SIAM review51(4), 661–703 (2009)
2009
-
[9]
Coles,S.,Bawa,J.,Trenner,L.,Dorazio,P.:Anintroductiontostatisticalmodeling of extreme values, vol. 208. Springer (2001)
2001
-
[10]
Almqvist and Wiksell (1928)
Cramér, H.: On the composition of elementary errors: Statistical applications. Almqvist and Wiksell (1928)
1928
-
[11]
Embrechts, P., Klüppelberg, C., Mikosch, T.: Modelling extremal events: for insur- ance and finance, vol. 33. Springer Science & Business Media (2013)
2013
-
[12]
In: Proceedings of the 18th conference of the eu- ropean chapter of the association for computational linguistics: system demonstra- tions
Es, S., James, J., Anke, L.E., Schockaert, S.: Ragas: Automated evaluation of retrieval augmented generation. In: Proceedings of the 18th conference of the eu- ropean chapter of the association for computational linguistics: system demonstra- tions. pp. 150–158 (2024)
2024
-
[13]
Ethayarajh, K.: How contextual are contextualized word representations? compar- ing the geometry of bert, elmo, and gpt-2 embeddings. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th inter- national joint conference on natural language processing (EMNLP-IJCNLP). pp. 55–65 (2019)
2019
-
[14]
arXiv preprint arXiv:2312.109972(1) (2023)
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., Wang, H.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.109972(1) (2023)
Pith/arXiv arXiv 2023
-
[15]
Ho, X., Nguyen, A.K.D., Sugawara, S., Aizawa, A.: Constructing a multi-hop qa datasetforcomprehensiveevaluationofreasoningsteps.In:Proceedingsofthe28th International Conference on Computational Linguistics. pp. 6609–6625 (2020) 16 Ziyu Song ⋆, Jiaming Fang⋆, Kuangyu Li, Tuo Xia, and Chuanpeng Wang
2020
-
[16]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[17]
arXiv preprint arXiv:2112.09118 (2021)
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., Grave, E.: Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118 (2021)
Pith/arXiv arXiv 2021
-
[18]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Jiang, Z., Xu, F.F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., Yang, Y., Callan, J., Neubig, G.: Active retrieval augmented generation. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 7969–7992 (2023)
2023
-
[19]
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 6769–6781 (2020)
2020
-
[20]
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., Howard-Snyder, W., Chen, K., Kakade, S., Jain, P., et al.: Matryoshka representa- tionlearning.AdvancesinNeuralInformationProcessingSystems35,30233–30249 (2022)
2022
-
[21]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[22]
arXiv preprint arXiv:2504.03165 (2025)
Li, W., Liu, K., Zhang, X., Lei, X., Ma, W., Liu, Y.: Efficient dynamic clustering- based document compression for retrieval-augmented-generation. arXiv preprint arXiv:2504.03165 (2025)
arXiv 2025
-
[23]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track
Li, Z., Li, C., Zhang, M., Mei, Q., Bendersky, M.: Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 881–893 (2024)
2024
-
[24]
Transactions of the association for computational linguistics12, 157–173 (2024)
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P.: Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics12, 157–173 (2024)
2024
-
[25]
In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Liu, S., Xiao, F., Ou, W., Si, L.: Cascade ranking for operational e-commerce search. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 1557–1565 (2017)
2017
-
[26]
the Annals of Statistics pp
Pickands III, J.: Statistical inference using extreme order statistics. the Annals of Statistics pp. 119–131 (1975)
1975
-
[27]
arXiv preprint arXiv:2010.16061 (2020)
Powers, D.M.: Evaluation: from precision, recall and f-measure to roc, informed- ness, markedness and correlation. arXiv preprint arXiv:2010.16061 (2020)
arXiv 2010
-
[28]
Springer (2007)
Resnick, S.I.: Heavy-tail phenomena: probabilistic and statistical modeling. Springer (2007)
2007
-
[29]
Information Retrieval3(4), 333–389 (2009)
Robertson, S., Zaragoza, H.: The probabilistic relevance framework: Bm25 and beyond. Information Retrieval3(4), 333–389 (2009)
2009
-
[30]
In: 2024 IEEE 7th international conference on multimedia information processing and retrieval (MIPR)
Sawarkar, K., Mangal, A., Solanki, S.R.: Blended rag: Improving rag (retriever- augmented generation) accuracy with semantic search and hybrid query-based re- trievers. In: 2024 IEEE 7th international conference on multimedia information processing and retrieval (MIPR). pp. 155–161. IEEE (2024)
2024
-
[31]
In: In- ternational Conference on Machine Learning
Shi, F., Chen, X., Misra, K., Scales, N., Dohan, D., Chi, E.H., Schärli, N., Zhou, D.: Large language models can be easily distracted by irrelevant context. In: In- ternational Conference on Machine Learning. pp. 31210–31227. PMLR (2023) Tail-Aware Adaptive-k 17
2023
-
[32]
In: Proceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing
Taguchi, C., Maekawa, S., Bhutani, N.: Efficient context selection for long-context QA: No tuning, no iteration, just adaptive-k. In: Proceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing. pp. 20105–20130. Association for Computational Linguistics (2025)
2025
-
[33]
Transactions of the Association for Computational Linguistics10, 539–554 (2022)
Trivedi, H., Balasubramanian, N., Khot, T., Sabharwal, A.: Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics10, 539–554 (2022)
2022
-
[34]
Signal processing167, 107299 (2020)
Truong,C.,Oudre,L.,Vayatis,N.:Selectivereviewofofflinechangepointdetection methods. Signal processing167, 107299 (2020)
2020
-
[35]
In: International conference on ma- chine learning
Wang, T., Isola, P.: Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In: International conference on ma- chine learning. pp. 9929–9939. PMLR (2020)
2020
-
[36]
In: Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval
Xiao, S., Liu, Z., Zhang, P., Muennighoff, N., Lian, D., Nie, J.Y.: C-pack: Packed resources for general chinese embeddings. In: Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. pp. 641–649 (2024)
2024
-
[37]
In: Proceedings of the 2018 conference on empirical methods in natural language processing
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., Manning, C.D.: Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In: Proceedings of the 2018 conference on empirical methods in natural language processing. pp. 2369–2380 (2018)
2018
-
[38]
Statistics & Probability Letters6(3), 181–189 (1988)
Yao, Y.C.: Estimating the number of change-points via schwarz’criterion. Statistics & Probability Letters6(3), 181–189 (1988)
1988
-
[39]
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al.: Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176 (2025) 18 Ziyu Song ⋆, Jiaming Fang⋆, Kuangyu Li, Tuo Xia, and Chuanpeng Wang A Additional Analysis of Tail Stability Criterion We provide...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.