LC-Flow: Learning Local Continuous Optical Flow and Confidence from events
Pith reviewed 2026-06-30 14:06 UTC · model grok-4.3
The pith
LC-Flow maintains per-grid recurrent states to compute optical flow continuously from local events at arbitrary timestamps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
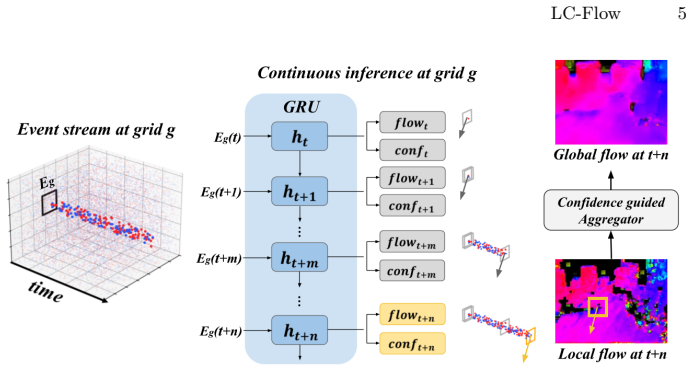
LC-Flow is the first temporally continuous learning-based optical flow estimator that operates purely from local events. A Continuous Local Recurrent Network maintains persistent hidden states per spatial grid, incrementally accumulating temporal context as events arrive. This produces sparse local flow estimates at arbitrary timestamps with full motion history. A jointly learned per-estimate filters unreliable outputs and supplies weights for a multi-scale confidence-guided aggregation that reconstructs globally consistent flow, achieving state-of-the-art performance among local methods on MVSEC and DSEC and a new overall state-of-the-art on MVSEC.
What carries the argument
Continuous Local Recurrent Network that maintains persistent hidden states per spatial grid and incrementally accumulates temporal context as events arrive, together with jointly learned scores used for filtering and aggregation.
If this is right
- Flow estimates can be requested at any timestamp without waiting for a new accumulation window.
- Each prediction carries explicit motion history from prior events rather than being recomputed statelessly.
- scores allow downstream tasks such as visual odometry to discard unreliable local measurements.
- The same scores provide principled weights that turn sparse local outputs into a globally consistent dense flow field.
- The method reports higher accuracy than prior local approaches on MVSEC and DSEC and surpasses heavy frame-based networks on the overall MVSEC benchmark.
Where Pith is reading between the lines
- The architecture could support online visual odometry pipelines that update pose estimates continuously rather than at fixed intervals.
- Similar per-location recurrent states might be applied to other asynchronous vision problems such as feature tracking or depth estimation from events.
- The separation of local estimation from global aggregation suggests a modular design that could incorporate additional constraints like smoothness without retraining the entire network.
- Testing on longer sequences with varying event rates would reveal whether hidden-state drift remains bounded in practice.
- keywords:[
Load-bearing premise
A per-grid recurrent hidden state can be maintained and updated incrementally from sparse asynchronous events without drift or instability caused by the aperture problem or long gaps between events at a given location.
What would settle it
Accuracy of the continuous local estimates measured on event sequences containing long temporal gaps at individual grid locations, compared against the same network run with artificially shortened gaps.
Figures


read the original abstract
Event cameras capture brightness changes asynchronously with microsecond resolution, yet existing optical flow methods fail to fully exploit this temporal continuity. Frame-based approaches impose artificial accumulation latency and suffer from domain overfitting, while model-based local methods operate statelessly, discarding temporal history between predictions and yielding inaccurate flows. We propose \textbf{LC-Flow}, the first temporally continuous, learning-based optical flow estimator that operates purely from local events. At its core, a Continuous Local Recurrent Network maintains persistent hidden states per spatial grid, incrementally accumulating temporal context as events arrive. Unlike frame-based methods constrained to fixed accumulation windows, and unlike stateless model-based methods that recompute motion from scratch at each step, LC-Flow produces sparse local flow estimates at arbitrary timestamps with full motion history. To address the inherent ambiguity of local observations, we jointly learn a confidence score that quantifies the reliability of each prediction, explicitly handling event sparsity and the aperture problem. This confidence serves a dual role: filtering unreliable estimates for downstream tasks such as visual odometry, and providing principled weights for a multi-scale confidence-guided aggregation that reconstructs globally consistent flow from the sparse local outputs. LC-Flow achieves state-of-the-art performance among local methods on both MVSEC and DSEC, while the confidence-guided aggregation establishes a new overall state-of-the-art on the MVSEC benchmark, surpassing heavy frame-based networks that rely on global spatial priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LC-Flow, a learning-based optical flow method for event cameras that uses a Continuous Local Recurrent Network to maintain persistent per-grid hidden states, enabling sparse local flow estimates at arbitrary timestamps with full temporal history. It jointly learns per-prediction confidence scores to handle sparsity and aperture ambiguity, using these for filtering and for multi-scale confidence-guided aggregation to produce dense flow. The method claims state-of-the-art results among local methods on MVSEC and DSEC, with the aggregated output setting a new overall SOTA on MVSEC.
Significance. If the recurrent stability and confidence calibration hold under the reported conditions, the work would meaningfully advance event-based vision by combining local operation with learned temporal continuity, moving beyond stateless model-based methods and latency-heavy frame-based ones. The dual use of confidence for both filtering and aggregation is a concrete engineering contribution, and the benchmark numbers (if robust to standard controls) would provide a useful reference point for future local continuous estimators.
major comments (3)
- [§3.2] §3.2 (Continuous Local Recurrent Network): The hidden-state update rule is described as incrementally accumulating context from asynchronous events, but no explicit decay, reset, or regularization term is introduced to bound error growth during long inter-event gaps at a given grid location. This directly bears on the central claim of stable 'full motion history' and on the reliability of the learned confidence scores.
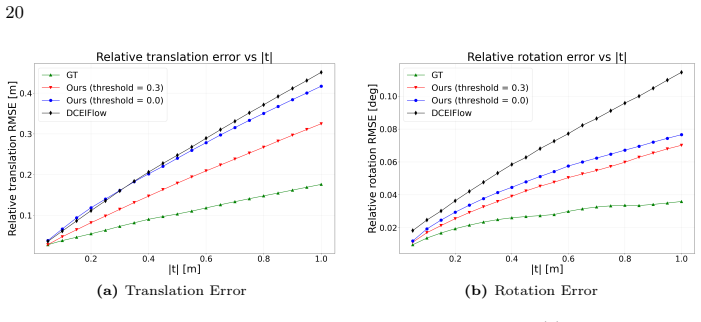
- [§5.1, Table 3] §5.1 and Table 3 (MVSEC quantitative results): The reported overall SOTA after confidence-guided aggregation is presented without an ablation that isolates the contribution of the recurrent hidden state versus the aggregation step alone, or versus a non-recurrent local baseline with the same aggregation. This makes it difficult to attribute the gains to the temporally continuous component.
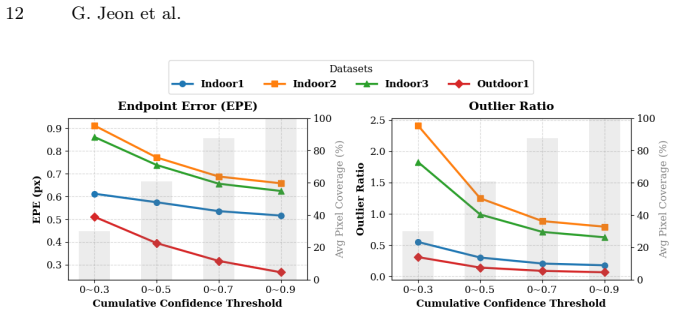
- [§4.3] §4.3 (confidence learning): The confidence is trained to quantify reliability under sparsity and aperture ambiguity, yet no quantitative evaluation (e.g., calibration plots or correlation with endpoint error on held-out sequences with controlled event density) is provided to verify that the scores actually track prediction quality rather than simply learning to down-weight difficult regions.
minor comments (2)
- [§3.2] Notation for the per-grid hidden state h_{i,j}(t) is introduced without an explicit statement of its dimensionality or initialization at t=0.
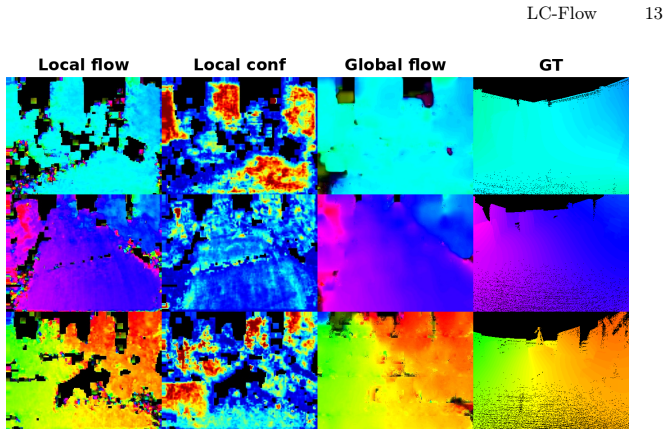
- [Figure 4] Figure 4 (qualitative results) would benefit from an additional column showing the per-pixel event density or inter-event gap duration to allow visual assessment of performance under the sparse regimes discussed in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will make corresponding revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Continuous Local Recurrent Network): The hidden-state update rule is described as incrementally accumulating context from asynchronous events, but no explicit decay, reset, or regularization term is introduced to bound error growth during long inter-event gaps at a given grid location. This directly bears on the central claim of stable 'full motion history' and on the reliability of the learned confidence scores.
Authors: We acknowledge the absence of an explicit decay or regularization term in the hidden-state update. The network is trained end-to-end to maintain stable representations from data, with confidence scores designed to indicate unreliable predictions. To directly address the concern regarding long inter-event gaps, we will introduce a decay factor in the update rule and add analysis of its impact on error accumulation in the revised manuscript. revision: yes
-
Referee: [§5.1, Table 3] §5.1 and Table 3 (MVSEC quantitative results): The reported overall SOTA after confidence-guided aggregation is presented without an ablation that isolates the contribution of the recurrent hidden state versus the aggregation step alone, or versus a non-recurrent local baseline with the same aggregation. This makes it difficult to attribute the gains to the temporally continuous component.
Authors: We agree that an ablation isolating the recurrent component is necessary to attribute performance gains. In the revised version, we will add experiments comparing the full recurrent model to a non-recurrent local baseline, evaluated both with and without the confidence-guided aggregation step. revision: yes
-
Referee: [§4.3] §4.3 (confidence learning): The confidence is trained to quantify reliability under sparsity and aperture ambiguity, yet no quantitative evaluation (e.g., calibration plots or correlation with endpoint error on held-out sequences with controlled event density) is provided to verify that the scores actually track prediction quality rather than simply learning to down-weight difficult regions.
Authors: We will include quantitative evaluations of the learned confidence scores in the revision, specifically calibration plots and correlation analysis with endpoint error on held-out sequences under controlled event densities, to verify alignment with prediction quality. revision: yes
Circularity Check
No significant circularity; derivation introduces independent recurrent architecture evaluated on external benchmarks
full rationale
The paper's central contribution is a Continuous Local Recurrent Network that maintains per-grid hidden states from asynchronous events, jointly learning confidence for aggregation. No equations, fitted parameters, or self-citations are shown that would make the claimed temporally continuous flow or SOTA results reduce to a definition or input by construction. Performance is reported on external benchmarks (MVSEC, DSEC) rather than internal fits, and the architecture is presented as a novel design choice without uniqueness theorems or ansatzes imported from prior self-work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(1), 361–372 (2020)
Akolkar, H., Ieng, S.H., Benosman, R.: Real-time high speed motion prediction using fast aperture-robust event-driven visual flow. IEEE Transactions on Pattern Analysis and Machine Intelligence44(1), 361–372 (2020)
2020
-
[2]
IEEE transactions on pattern analysis and machine intelligence 42(7), 1547–1556 (2020)
Almatrafi, M., Baldwin, R., Aizawa, K., Hirakawa, K.: Distance surface for event- based optical flow. IEEE transactions on pattern analysis and machine intelligence 42(7), 1547–1556 (2020)
2020
-
[3]
Baldwin, R.W., Liu, R., Almatrafi, M., Asari, V., Hirakawa, K.: Time-ordered re- cent event (tore) volumes for event cameras. IEEE Transactions on Pattern Analy- sis and Machine Intelligence45(2), 2519–2532 (2023).https://doi.org/10.1109/ TPAMI.2022.3172212
-
[4]
Proceedings of the IEEE102(10), 1537–1556 (2014) LC-Flow 15
Barranco, F., Fermüller, C., Aloimonos, Y.: Contour motion estimation for asyn- chronous event-driven cameras. Proceedings of the IEEE102(10), 1537–1556 (2014) LC-Flow 15
2014
-
[5]
IEEE Transactions on Intelligent Transportation Systems23(9), 15066–15078 (2021)
Brebion, V., Moreau, J., Davoine, F.: Real-time optical flow for vehicular percep- tion with low-and high-resolution event cameras. IEEE Transactions on Intelligent Transportation Systems23(9), 15066–15078 (2021)
2021
-
[6]
In: European Conference on Computer Vision
Cannici, M., Ciccone, M., Romanoni, A., Matteucci, M.: A differentiable recurrent surface for asynchronous event-based data. In: European Conference on Computer Vision. pp. 136–152. Springer (2020)
2020
-
[7]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: Empirical evaluation of gated recur- rent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Frontiers in Neuroscience17, 1160034 (2023)
Cuadrado, J., Rançon, U., Cottereau, B.R., Barranco, F., Masquelier, T.: Optical flow estimation from event-based cameras and spiking neural networks. Frontiers in Neuroscience17, 1160034 (2023)
2023
-
[9]
In: Proceed- ings of the AAAI conference on artificial intelligence
Ding, Z., Zhao, R., Zhang, J., Gao, T., Xiong, R., Yu, Z., Huang, T.: Spatio- temporal recurrent networks for event-based optical flow estimation. In: Proceed- ings of the AAAI conference on artificial intelligence. vol. 36, pp. 525–533 (2022)
2022
-
[10]
IEEE Robotics and Automation Letters6(3), 4947– 4954 (2021)
Gehrig, M., Aarents, W., Gehrig, D., Scaramuzza, D.: Dsec: A stereo event camera dataset for driving scenarios. IEEE Robotics and Automation Letters6(3), 4947– 4954 (2021)
2021
-
[11]
In: 2021 International Conference on 3D Vision (3DV)
Gehrig, M., Millhäusler, M., Gehrig, D., Scaramuzza, D.: E-raft: Dense optical flow from event cameras. In: 2021 International Conference on 3D Vision (3DV). pp. 197–206. IEEE (2021)
2021
-
[12]
Kendall, A., Gal, Y.: What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems30(2017)
2017
-
[13]
In: European conference on computer vision
Lee, C., Kosta, A.K., Zhu, A.Z., Chaney, K., Daniilidis, K., Roy, K.: Spike-flownet: event-based optical flow estimation with energy-efficient hybrid neural networks. In: European conference on computer vision. pp. 366–382. Springer (2020)
2020
-
[14]
Lin, S., Ma, Y., Chen, J., Wen, B.: Compressed event sensing (ces) volumes for event cameras133(1) (2024)
2024
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, D., Cheng, L., Wang, T., Sun, C.: Edcflow: Exploring temporally dense differ- ence maps for event-based optical flow estimation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1984–1993 (2025)
1984
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, H., Chen, G., Qu, S., Zhang, Y., Li, Z., Knoll, A., Jiang, C.: Tma: Temporal motion aggregation for event-based optical flow. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9685–9694 (2023)
2023
-
[17]
En- gineering Applications of Artificial Intelligence116, 105471 (2022)
Liu, Q., Chen, B.: Robust visual odometry using sparse optical flow network. En- gineering Applications of Artificial Intelligence116, 105471 (2022)
2022
- [18]
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nagata, J., Sekikawa, Y.: Tangentially elongated gaussian belief propagation for event-based incremental optical flow estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21940–21949 (2023)
2023
-
[20]
Sensors21(4), 1150 (2021)
Nagata, J., Sekikawa, Y., Aoki, Y.: Optical flow estimation by matching time sur- face with event-based cameras. Sensors21(4), 1150 (2021)
2021
-
[21]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Paredes-Vallés, F., De Croon, G.C.: Back to event basics: Self-supervised learning of image reconstruction for event cameras via photometric constancy. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3446–3455 (2021)
2021
-
[22]
In: Proceedings of the IEEE/CVF international conference on computer vision
Paredes-Vallés, F., Scheper, K.Y., De Wagter, C., De Croon, G.C.: Taming con- trast maximization for learning sequential, low-latency, event-based optical flow. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9695–9705 (2023) 16 G. Jeon et al
2023
- [23]
- [24]
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Sekikawa, Y., Hara, K., Saito, H.: Eventnet: Asynchronous recursive event pro- cessing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[26]
IEEE Transactions on Circuits and Systems for Video Technology22(9), 1377– 1387 (2012)
Senst, T., Eiselein, V., Sikora, T.: Robust local optical flow for feature tracking. IEEE Transactions on Circuits and Systems for Video Technology22(9), 1377– 1387 (2012)
2012
-
[27]
In: European Conference on Computer Vision
Shiba, S., Aoki, Y., Gallego, G.: Secrets of event-based optical flow. In: European Conference on Computer Vision. pp. 628–645. Springer (2022)
2022
-
[28]
IEEE Signal Processing Letters29, 2712–2716 (2023)
Shiba, S., Aoki, Y., Gallego, G.: Fast event-based optical flow estimation by triplet matching. IEEE Signal Processing Letters29, 2712–2716 (2023)
2023
-
[29]
IEEE Transactions on Image Processing31, 7237–7251 (2022)
Wan, Z., Dai, Y., Mao, Y.: Learning dense and continuous optical flow from an event camera. IEEE Transactions on Image Processing31, 7237–7251 (2022)
2022
-
[30]
Applied Sciences13(20), 11322 (2023)
Wang, X., Zhou, Y., Yu, G., Cui, Y.: A lightweight visual odometry based on lk optical flow tracking. Applied Sciences13(20), 11322 (2023)
2023
- [31]
-
[32]
arXiv preprint arXiv:2511.09072 (2025)
Yang, S., Yoon, Y., Jung, H.M., Lim, J.: Smf-vo: Direct ego-motion estimation via sparse motion fields. arXiv preprint arXiv:2511.09072 (2025)
-
[33]
arXiv preprint arXiv:2412.11284 (2024)
Yuan, D., Burner, L., Wu, J., Liu, M., Chen, J., Aloimonos, Y., Fermüller, C.: Learning normal flow directly from event neighborhoods. arXiv preprint arXiv:2412.11284 (2024)
-
[34]
In: Proceedings of the IEEE/CVF In- ternationalConferenceonComputerVision(ICCV).pp.7969–7979(October2025)
Yuan, D., Burner, L., Wu, J., Liu, M., Chen, J., Aloimonos, Y., Fermüller, C.: Learning normal flow directly from events. In: Proceedings of the IEEE/CVF In- ternationalConferenceonComputerVision(ICCV).pp.7969–7979(October2025)
-
[35]
IEEE Sensors Journal22(6), 5260– 5269 (2021)
Zeng,Q.,Gao,C.,Chen,Z.,Jin,Y.,Kan,Y.:Robustmonovisual-inertialodometry using sparse optical flow with edge detection. IEEE Sensors Journal22(6), 5260– 5269 (2021)
2021
-
[36]
Micromachines14(1), 203 (2023)
Zhang, Y., Lv, H., Zhao, Y., Feng, Y., Liu, H., Bi, G.: Event-based optical flow estimation with spatio-temporal backpropagation trained spiking neural network. Micromachines14(1), 203 (2023)
2023
-
[37]
IEEE Robotics and Automation Letters3(3), 2032–2039 (2018)
Zhu, A.Z., Thakur, D., Özaslan, T., Pfrommer, B., Kumar, V., Daniilidis, K.: The multivehicle stereo event camera dataset: An event camera dataset for 3d perception. IEEE Robotics and Automation Letters3(3), 2032–2039 (2018)
2032
-
[38]
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
Zhu, A.Z., Yuan, L., Chaney, K., Daniilidis, K.: Ev-flownet: Self-supervised optical flow estimation for event-based cameras. arXiv preprint arXiv:1802.06898 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Zhu, A.Z., Yuan, L., Chaney, K., Daniilidis, K.: Unsupervised event-based learning ofopticalflow,depth,andegomotion.In:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition. pp. 989–997 (2019)
2019
-
[40]
Zhuang, H., Fang, Z., Huang, X., Hou, K., Kong, D., Hu, C.: Ev-mgrflownet: Motion-guided recurrent network for unsupervised event-based optical flow with hybridmotion-compensationloss.IEEETransactionsonInstrumentationandMea- surement73, 1–15 (2024)
2024
-
[41]
1 presents quantitative results on the DSEC benchmark
Zubić, N., Gehrig, M., Scaramuzza, D.: State space models for event cameras (2024),https://arxiv.org/abs/2402.15584 Supplementary materials for LC-Flow: Learning Local Continuous Optical Flow and Confidence from events 1 Quantitative Results on DSEC Tab. 1 presents quantitative results on the DSEC benchmark. Our local estima- tor already outperforms the m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.