Prompt Perturbation for Reliable LLM Evaluation over Comparison Graphs
Pith reviewed 2026-06-27 01:00 UTC · model grok-4.3
The pith
Perturbing prompts generates multiple comparison graphs whose structural consistency filters out cyclic inconsistencies before ranking LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating perturbed variants of each prompt, constructing comparison graphs from the resulting judgments, and filtering out structurally inconsistent comparison patterns across those graphs, the approach reduces cyclic inconsistencies and yields more reliable LLM rankings when standard aggregation methods are applied to the filtered set.
What carries the argument
Prompt perturbation framework that builds multiple comparison graphs per original prompt and applies graph-level structural consistency checks to filter comparisons before ranking.
If this is right
- Leaderboards become less sensitive to minor prompt wording changes.
- Standard ranking algorithms can be used without first solving the full intransitivity problem.
- The same filtering step applies to any pairwise comparison setup that produces directed graphs.
- Inconsistencies involving ties are also reduced when they fail the cross-graph consistency test.
Where Pith is reading between the lines
- The method could be tested by holding out a subset of prompts and checking whether filtered rankings better predict held-out human judgments than unfiltered ones.
- If perturbation strength is varied, one could measure the trade-off between the amount of data removed and the drop in observed cycles.
- The approach suggests that consistency across prompt variants may serve as a proxy for evaluation reliability in other open-ended generation tasks.
Load-bearing premise
Structural consistency across graphs from perturbed prompt variants reliably flags and removes only noisy or invalid comparisons without discarding valid preference data or creating new selection bias.
What would settle it
Run the method on a dataset with known human-validated preferences and measure whether the fraction of removed comparisons that humans later judge as correct exceeds the fraction retained, or whether intransitivity rates remain high after filtering.
Figures

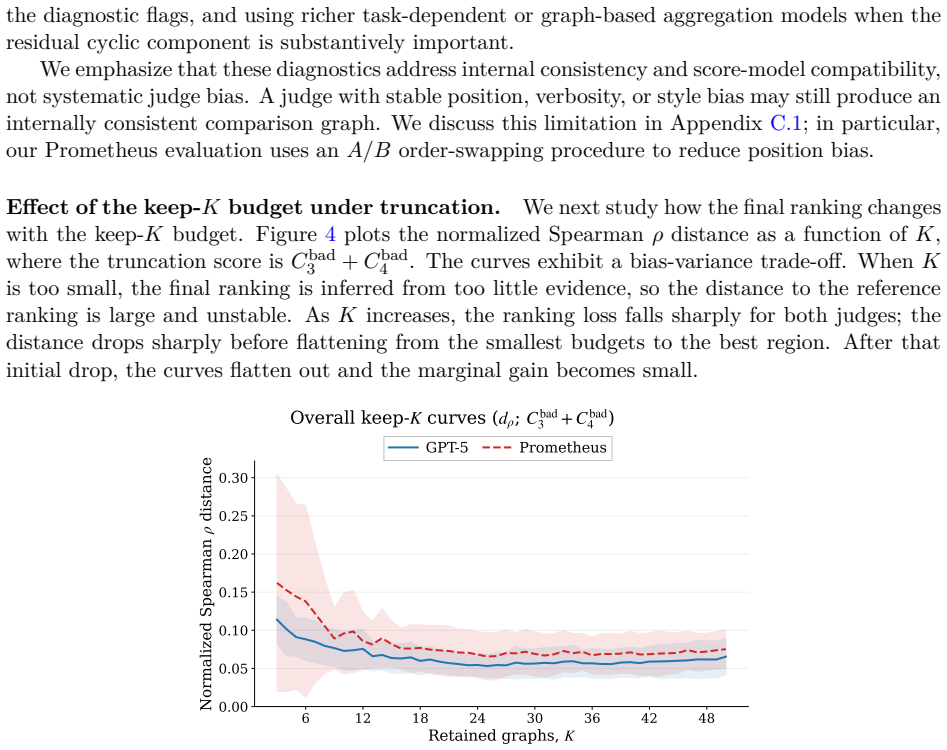
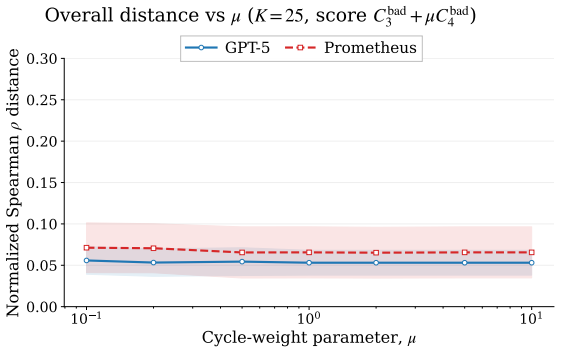
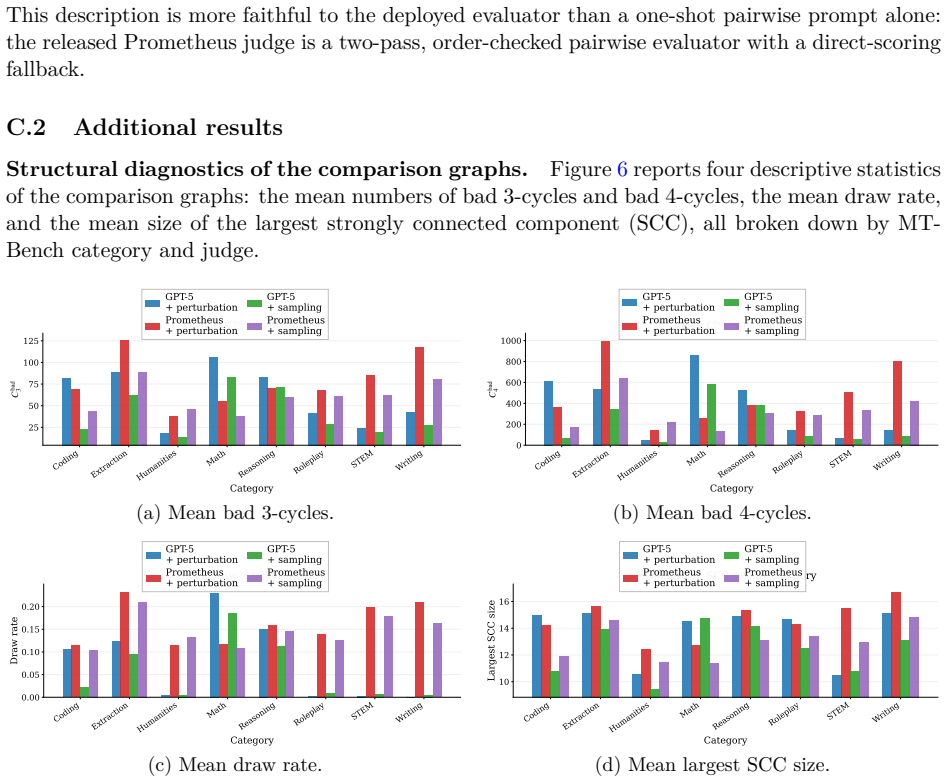
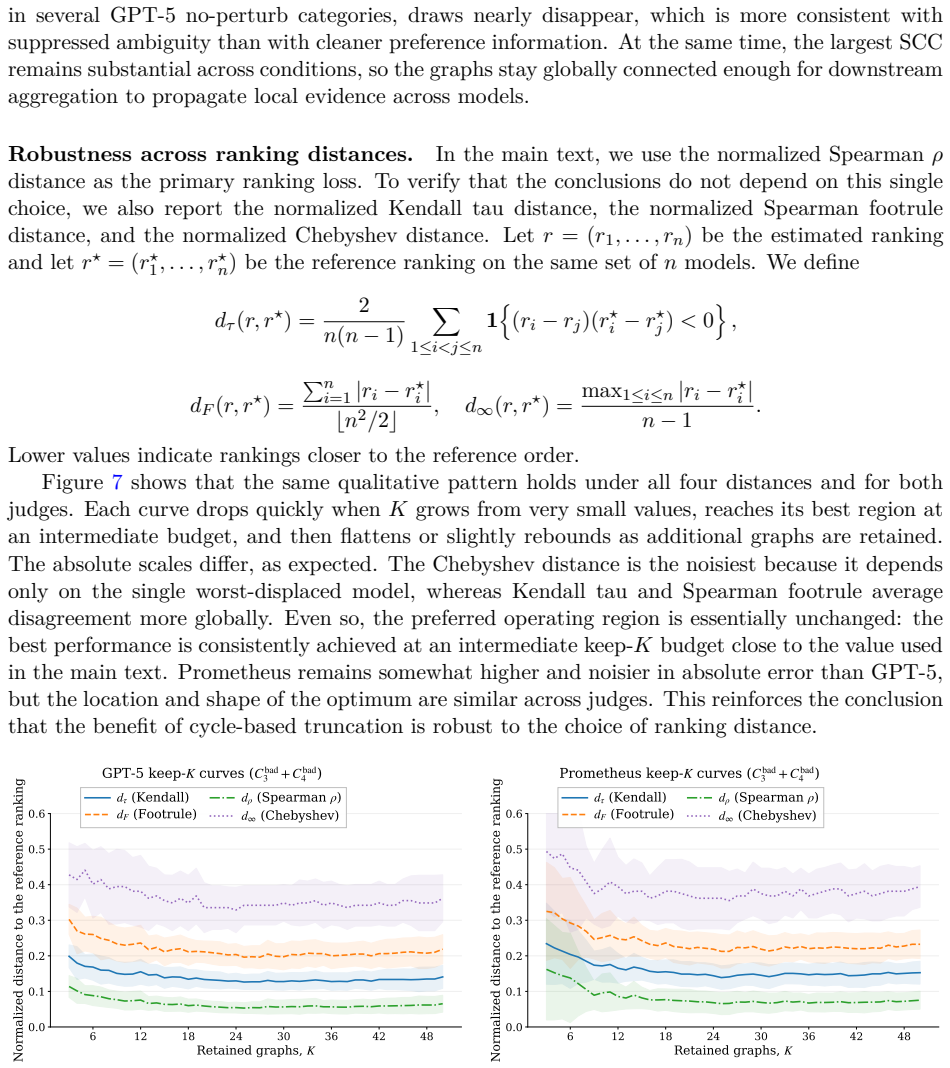

read the original abstract
Evaluating large language models (LLMs) is important for understanding their capabilities, comparing competing systems, and supporting the deployment of reliable models in practice. For open-ended tasks, pairwise evaluation has become a popular paradigm, in which two responses to the same prompt are compared and the resulting judgments are aggregated into an overall ranking. A central challenge of this paradigm is intransitivity: the induced comparison outcomes may fail to support any coherent global ranking. For example, one may observe cyclic preferences such as $A \succ B \succ C \succ A$, or inconsistencies involving ties such as $A \equiv B\equiv C\neq A$. Such contradictions make the resulting leaderboard unstable and challenging to interpret. In this paper, we propose a prompt perturbation framework for improving the consistency of pairwise LLM evaluation. Our approach generates perturbed variants of each prompt, uses the resulting comparison graphs to identify and filter out structurally inconsistent comparison patterns, and then applies standard ranking methods to the filtered comparisons. A key feature of the proposed framework is that graph-level structural consistency is incorporated explicitly into the evaluation pipeline before ranking aggregation. This provides a simple and principled way to reduce cyclic inconsistencies and improve the reliability of LLM rankings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a prompt perturbation framework for pairwise LLM evaluation over comparison graphs. It generates perturbed variants of each prompt, constructs comparison graphs from the resulting judgments, identifies and filters out structurally inconsistent comparison patterns, and applies standard ranking methods to the filtered comparisons, with the goal of reducing cyclic inconsistencies such as A ≻ B ≻ C ≻ A and improving the reliability of LLM rankings.
Significance. If the filtering step based on graph-level structural consistency across perturbations can be shown to remove noise-induced inconsistencies while preserving underlying preference signal, the framework could offer a practical improvement to the stability of LLM leaderboards. The approach explicitly incorporates consistency checks before aggregation, which is a clear conceptual contribution, but the absence of any reported experiments, datasets, or analysis leaves the practical impact unassessed.
major comments (2)
- [Abstract] Abstract (framework description paragraph): the central claim that the method 'provides a simple and principled way to reduce cyclic inconsistencies' rests on the unstated assumption that perturbations preserve preferences while exposing only noise; no formal definition of the perturbation operator or the precise criterion for 'structurally inconsistent comparison patterns' is supplied, making it impossible to verify whether the filter introduces selection bias.
- [Abstract] Abstract: no experimental results, error analysis, validation datasets, or comparison against baselines are presented, so the claim that the filtered comparisons improve reliability cannot be evaluated; this is load-bearing because the soundness of the pipeline cannot be determined from the method description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the two major points below and commit to revisions that strengthen the formalization and add empirical validation.
read point-by-point responses
-
Referee: [Abstract] Abstract (framework description paragraph): the central claim that the method 'provides a simple and principled way to reduce cyclic inconsistencies' rests on the unstated assumption that perturbations preserve preferences while exposing only noise; no formal definition of the perturbation operator or the precise criterion for 'structurally inconsistent comparison patterns' is supplied, making it impossible to verify whether the filter introduces selection bias.
Authors: We agree that the abstract does not supply formal definitions or explicitly state the core assumption. In the revised manuscript we will add a precise definition of the perturbation operator (as a distribution over prompt variants) and a graph-theoretic criterion for structural inconsistency (e.g., violation of transitivity or tie consistency across the perturbation ensemble). We will also include a short discussion of the modeling assumption and a brief analysis of possible selection bias induced by the filter. revision: yes
-
Referee: [Abstract] Abstract: no experimental results, error analysis, validation datasets, or comparison against baselines are presented, so the claim that the filtered comparisons improve reliability cannot be evaluated; this is load-bearing because the soundness of the pipeline cannot be determined from the method description alone.
Authors: The submitted manuscript presents only the conceptual framework. We acknowledge that the reliability claim cannot be assessed without experiments. In the revision we will add (i) experiments on standard pairwise LLM evaluation benchmarks, (ii) error analysis of filtered vs. unfiltered graphs, (iii) comparison against baseline aggregation methods, and (iv) ablation studies on the perturbation and filtering steps. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a procedural pipeline (generate prompt perturbations, build comparison graphs, filter inconsistent patterns, apply ranking) without equations, fitted parameters, predictions, or derivations. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim is a methodological proposal whose validity rests on external validation rather than internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[AAA+23] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
[AAHR25] Aryan Agrawal, Lisa Alazraki, Shahin Honarvar, and Marek Rei. Enhancing LLM robustness to perturbed instructions: An empirical study.arXiv preprint arXiv:2504.02733,
-
[3]
Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050,
38 [CHZ+25] Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, and Bingsheng He. Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050,
-
[4]
Training Verifiers to Solve Math Word Problems
[CKB+21] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
[DGLH24] Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length- controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Re-evaluating automatic LLM system ranking for alignment with human preference
[GLH+25] MingqiGao, YixinLiu, XinyuHu, XiaojunWan, JonathanBragg, andArmanCohan. Re-evaluating automatic LLM system ranking for alignment with human preference. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4605–4629,
2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[GYZ+25] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-R1: Incen- tivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
[HBB+20] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Prometheus 2: An open source language model specialized in evaluating other language models
[KSL+24] Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, GrahamNeubig, MoontaeLee, KyungjaeLee, andMinjoonSeo. Prometheus 2: An open source language model specialized in evaluating other language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4334–4353,
2024
-
[10]
LLMs Get Lost In Multi-Turn Conversation
[LHZN25] Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
G-Eval: NLG evaluation using GPT-4 with better human alignment
[LIX+23] Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522,
2023
-
[12]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
[LPM+23] Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, KellieLu, ColtonBishop, EthanHall, VictorCarbune, AbhinavRastogi, etal. RLAIF vs. RLHF: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Large language models sensitivity to the order of options in multiple-choice questions
[PH24] Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2006–2017,
2024
-
[14]
Prompt perturbation consistency learning for robust language models
40 [QNM+24] Yao Qiang, Subhrangshu Nandi, Ninareh Mehrabi, Greg Ver Steeg, Anoop Kumar, Anna Rumshisky, and Aram Galstyan. Prompt perturbation consistency learning for robust language models. InFindings of the Association for Computational Linguis- tics: EACL 2024, pages 1357–1370,
2024
-
[15]
[SSW23] Jiuding Sun, Chantal Shaib, and Byron C Wallace. Evaluating the zero-shot robust- ness of instruction-tuned language models.arXiv preprint arXiv:2306.11270,
-
[16]
LLaMA: Open and Efficient Foundation Language Models
[TLI+23] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
[UPT+24] Shivani Upadhyay, Ronak Pradeep, Nandan Thakur, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. A large-scale study of rele- vance assessments with large language models: An initial look.arXiv preprint arXiv:2411.08275,
-
[18]
[WSZ+25] Yidong Wang, Yunze Song, Tingyuan Zhu, Xuanwang Zhang, Zhuohao Yu, Hao Chen, Chiyu Song, Qiufeng Wang, Cunxiang Wang, Zhen Wu, et al. Trust- judge: Inconsistencies of LLM-as-a-judge and how to alleviate them.arXiv preprint arXiv:2509.21117,
-
[19]
Investigating non-transitivity in LLM-as-a-judge.arXiv preprint arXiv:2502.14074,
41 [XRRK25] Yi Xu, Laura Ruis, Tim Rocktäschel, and Robert Kirk. Investigating non-transitivity in LLM-as-a-judge.arXiv preprint arXiv:2502.14074,
-
[20]
JudgeLM: Fine-tuned Large Language Models are Scalable Judges, March 2025
[ZWW23] Lianghui Zhu, Xinggang Wang, and Xinlong Wang. Judgelm: Fine-tuned large lan- guage models are scalable judges.arXiv preprint arXiv:2310.17631,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.