Litmus: Zero-Label, Code-Driven Metric Specification for Evaluating AI Systems
Pith reviewed 2026-06-26 08:15 UTC · model grok-4.3
The pith
Litmus derives evaluation metrics for AI systems directly from their source code without using any labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
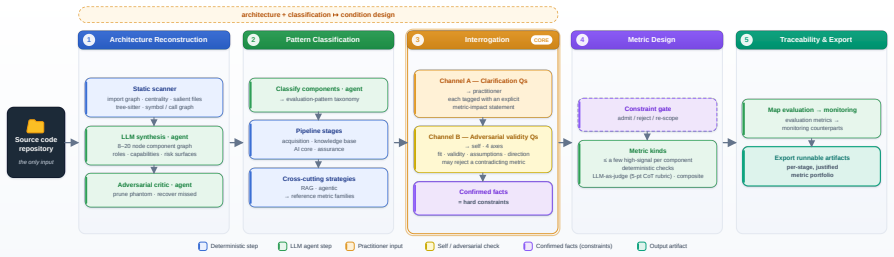
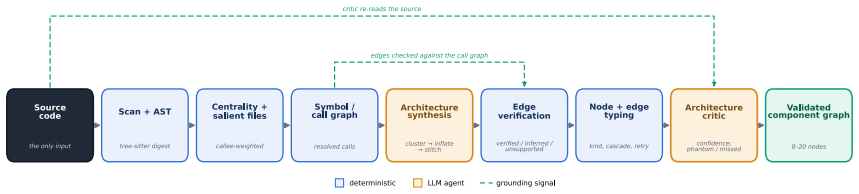
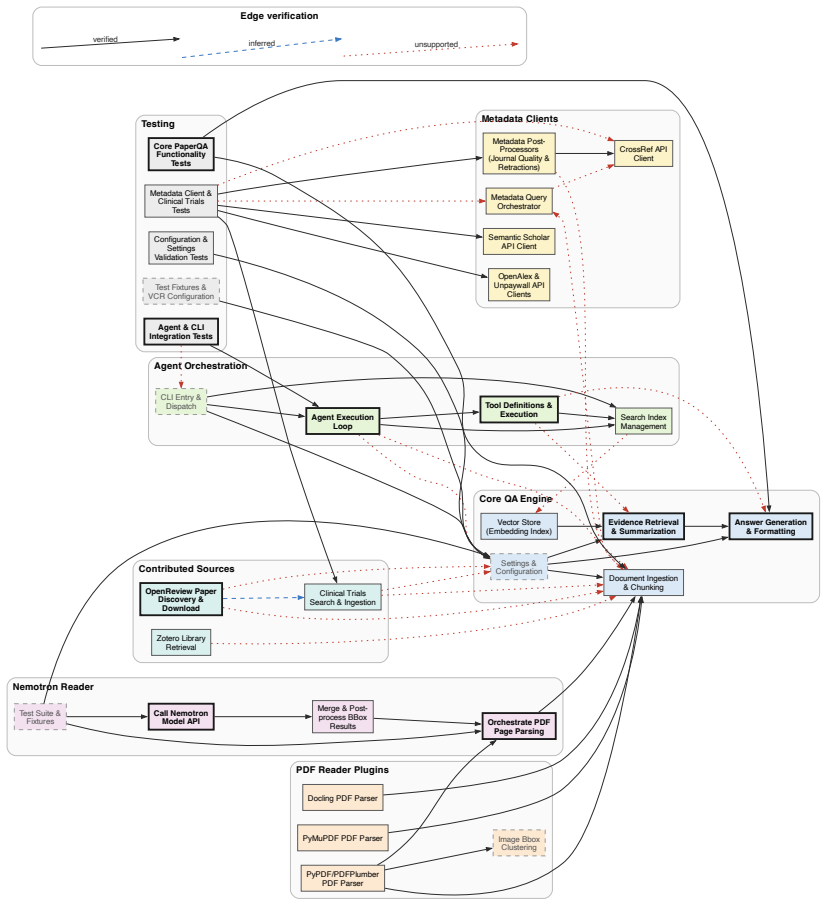
Litmus identifies what must be measured and why from source code and interrogation, then converts those answers into constraints for a justified per-stage metric portfolio. Evaluated on financial account grouping, scientific QA, and inherent risk assessment pipelines, it achieves broadest concern coverage, spans more stages, near-zero redundancy, and first in validity, with Spearman ρ=0.72 on scientific QA compared to less than 0.47 for baselines.
What carries the argument
Eliciting evaluation intent from source code and targeted interrogation to generate constraints that construct a per-stage metric portfolio.
Load-bearing premise
Source code analysis combined with targeted interrogation can accurately determine the necessary evaluation criteria without any labels or external goal knowledge.
What would settle it
An experiment where experts identify a key evaluation concern from the pipeline's purpose that Litmus's code analysis and questions entirely miss, resulting in incomplete metric coverage.
Figures

read the original abstract
As agentic LLM systems move from prototypes to deployment across increasingly diverse domains, evaluating them has become both more important and more difficult. The challenge is not only that individual metrics may be unreliable, but that evaluation goals are often left implicit. Without a clear account of what a system is expected to do, how it can fail, and which failures matter, metric choices become difficult to justify, interpret, or validate. We present Litmus, a zero-label system that designs evaluation and monitoring metrics for AI pipelines by eliciting evaluation intent from source code and targeted interrogation. Instead of assuming that the evaluation target is already known, Litmus first identifies what must be measured and why, then converts those answers into constraints for constructing a justified, per-stage metric portfolio. We evaluate Litmus on three real, code-defined AI pipelines - financial account grouping, scientific QA, and inherent risk assessment - against AutoMetrics and three DynamicRubric baselines. Litmus achieves the broadest or tied-broadest concern coverage, spans more pipeline stages, produces a near-zero-redundancy portfolio, and ranks first in validity against per-row quality labels on all three pipelines - decisively on scientific QA (Spearman $\rho=0.72$ vs. less than $0.47$ for every baseline), and within overlapping confidence intervals in relation to two components of the audit framework despite using no labels during metric design. Our results support a shift from automatic metric implementation to automatic metric specification: before asking which metric to compute, evaluation systems should ask what must be measured and why.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Litmus, a zero-label system that designs evaluation metrics for AI pipelines by analyzing source code and performing targeted interrogation to elicit what must be measured and why, then converts those into constraints for per-stage metric portfolios. Evaluated on three code-defined pipelines (financial account grouping, scientific QA, inherent risk assessment) against AutoMetrics and DynamicRubric baselines, Litmus is claimed to achieve broadest or tied-broadest concern coverage, span more stages, near-zero redundancy, and top validity (Spearman ρ=0.72 on scientific QA vs. <0.47 for all baselines; within CI for two audit components).
Significance. If the zero-label property and empirical comparisons hold, the work supports a shift from automatic metric implementation to specification, providing a principled way to justify metrics without labels. The use of real pipelines, explicit coverage/redundancy metrics, and label-based validity checks (while designing without labels) are strengths that could influence evaluation practices for agentic systems.
major comments (2)
- [§3 (targeted interrogation and zero-label definition)] The load-bearing zero-label claim (§3, interrogation protocol description) rests on the assumption that targeted interrogation can identify evaluation intent from code alone without importing external goal knowledge. The protocol must surface expected behaviors and failure modes to produce the reported coverage and ρ=0.72 gains; any effective questions about success criteria appear to elicit the very knowledge the method disclaims. This needs explicit clarification on question generation and knowledge boundaries, as it directly affects whether performance advantages can be attributed to a pure zero-label regime versus the interrogation step.
- [Experimental results table (scientific QA pipeline)] Table reporting Spearman correlations (scientific QA row): the validity comparison uses per-row quality labels for evaluation, yet the design is zero-label. The paper should detail how the elicited concerns map to the label criteria used for ρ computation; without this, it is unclear whether the 0.72 result reflects alignment with the intended goals or an artifact of the validation labels.
minor comments (2)
- [Abstract and §4] The abstract states 'three DynamicRubric baselines' but does not name or differentiate them; the methods section should list their exact configurations for reproducibility.
- [§3.2] Notation for 'concern coverage' and 'stage span' is introduced without a formal definition or pseudocode; adding a small table or equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help strengthen the presentation of the zero-label property and validation procedure. We address each major comment below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3 (targeted interrogation and zero-label definition)] The load-bearing zero-label claim (§3, interrogation protocol description) rests on the assumption that targeted interrogation can identify evaluation intent from code alone without importing external goal knowledge. The protocol must surface expected behaviors and failure modes to produce the reported coverage and ρ=0.72 gains; any effective questions about success criteria appear to elicit the very knowledge the method disclaims. This needs explicit clarification on question generation and knowledge boundaries, as it directly affects whether performance advantages can be attributed to a pure zero-label regime versus the interrogation step.
Authors: The interrogation protocol relies exclusively on a fixed library of general question templates generated from static code analysis (control-flow graphs, type signatures, and exception paths) with no domain-specific success criteria supplied as input. These templates are identical across all three pipelines. We acknowledge that the current §3 description leaves the knowledge boundary implicit. In revision we will add the precise template-generation algorithm, an example trace for the scientific QA pipeline, and an explicit statement that no external goal statements or label-derived knowledge enter the process. This will allow readers to verify that the reported gains derive from systematic code-driven elicitation rather than imported knowledge. revision: yes
-
Referee: [Experimental results table (scientific QA pipeline)] Table reporting Spearman correlations (scientific QA row): the validity comparison uses per-row quality labels for evaluation, yet the design is zero-label. The paper should detail how the elicited concerns map to the label criteria used for ρ computation; without this, it is unclear whether the 0.72 result reflects alignment with the intended goals or an artifact of the validation labels.
Authors: The quality labels serve only as an external validation instrument and were withheld during concern elicitation and metric construction. Each Litmus-elicited concern is mapped post hoc to the label rubric dimensions (factual correctness, reasoning completeness, source attribution) by matching the natural-language description of the concern to the rubric item it most directly addresses. We will insert a new subsection (and accompanying table) that lists the 14 elicited concerns for the scientific QA pipeline alongside their corresponding label dimensions, together with the Spearman contribution of each mapped group. This addition will make transparent that the ρ=0.72 improvement tracks better coverage of the intended evaluation dimensions rather than an artifact of the validation labels. revision: yes
Circularity Check
No circularity; results from external empirical benchmarks on pipelines
full rationale
The paper describes Litmus as a zero-label method using source code and targeted interrogation to elicit intent, then constructs metric portfolios and validates them empirically against baselines on three real pipelines via coverage, redundancy, stage span, and Spearman ρ (e.g., 0.72 on scientific QA). No derivation, equation, or claim reduces by construction to its inputs; the central results are independent comparisons to AutoMetrics and DynamicRubric baselines using per-row quality labels for validation only. No self-citations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear in the load-bearing steps. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 8038–8047
A survey on neural question generation: Meth- ods, applications, and prospects. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 8038–8047. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language mod- els resolve real-...
2024
-
[2]
InIn- ternational Conference on Learning Representations
Agentbench: Evaluating llms as agents. InIn- ternational Conference on Learning Representations. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: Nlg evaluation using gpt-4 with better human align- ment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522. Ass...
2023
-
[3]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
LLM evaluators recognize and favor their own generations.Preprint, arXiv:2404.13076. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. BLEU: a method for automatic eval- uation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Compu- tational Linguistics, pages 311–318. Yujia Qin, Shihao Liang, Yinin...
Pith/arXiv arXiv 2002
-
[4]
In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 314–324
Deconstructing NLG evaluation: Evaluation practices, assumptions, and their implications. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 314–324. Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, ...
2022
-
[5]
not found
Webarena: A realistic web environment for building autonomous agents. InInternational Con- ference on Learning Representations. A Reference Failure-Concerns The coverage axis for the account-grouping pipeline uses the following fixed list of ten failure- concerns: (1) account assigned to a semantically wrong group; (2) group inconsistent with / contra- di...
-
[6]
how the system actually works,
-
[7]
which components are AI-core versus supporting or operational,
-
[8]
PRIORITY ORDER:
which components should receive metrics first. PRIORITY ORDER:
-
[9]
Evaluability and observability
-
[10]
processing
Framework alignment EXECUTION TRUTH: - Infer the real runtime/dataflow from code, not from names. - Identify triggers, transformations, external calls, storage boundaries, branching logic, outputs, and feedback paths. - Prefer fewer truthful nodes over many shallow nodes. - Collapse helpers into parent nodes unless a helper has a distinct evaluation or ob...
-
[11]
Every source file must belong to exactly one subsystem
-
[12]
Minimize cross-subsystem call edges (high cohesion, low coupling)
-
[13]
Document Retrieval
Name subsystems by what they DO, not what they ARE (e.g. "Document Retrieval" not " Module A")
-
[14]
Infrastructure nodes (databases, caches, queues, vector stores) form their own subsystem only if they have 3+ files; otherwise attach to their primary consumer
-
[15]
Entry points (API routes, Lambda handlers, CLI) group together unless they serve clearly different domains
-
[16]
If two groups of files implement different domain pipelines -- different domain vocabulary, inputs/outputs, or end- to-end flow -- they MUST be separate subsystems
Keep DISTINCT business/domain modules separate. If two groups of files implement different domain pipelines -- different domain vocabulary, inputs/outputs, or end- to-end flow -- they MUST be separate subsystems. Never collapse them into one bucket
-
[17]
Domain Logic
Do NOT emit catch-all subsystems with vague names like "Domain Logic", "Core Logic", "Business Logic", "Processing", or " Miscellaneous" that lump unrelated domains together. Split such a group into its constituent domains, each named for what it does
-
[18]
Return ONLY valid JSON matching the schema
Choose the number of subsystems (3-8) that reflects the codebase's actual distinct domains and infrastructure -- do not over- merge to hit a smaller count. Return ONLY valid JSON matching the schema. No markdown. {JSON schema} Stitch-pass system prompt (connects nodes across subsys- tems). You are a cross-subsystem edge generator. Connect architecture nod...
-
[19]
Only create edges between nodes in DIFFERENT subsystems
-
[20]
data_flow: subsystemA.output -> subsystemB.input
For every edge, populate evidenceCalls with caller->callee symbol pairs when symbol evidence is available. If no symbol evidence exists, use descriptive evidence like "data_flow: subsystemA.output -> subsystemB.input"
-
[21]
Do NOT duplicate edges that already exist within subsystems
-
[22]
Use the CROSS-SUBSYSTEM SYMBOL EDGES section (if present) to identify which files call across subsystem boundaries, then connect the architecture nodes that own those files
-
[23]
No subsystem may be isolated
CONNECTIVITY IS THE TOP PRIORITY: Every subsystem MUST have at least one edge connecting it to another subsystem. No subsystem may be isolated
-
[24]
If symbol evidence is absent for a subsystem, infer edges from data flow patterns (e.g., orchestration calls processing, entry points feed pipelines, data subsystems serve compute subsystems)
-
[25]
Return ONLY valid JSON matching the schema
Generate enough edges to make the graph navigable -- aim for at least one edge per subsystem pair that has a logical data flow relationship. Return ONLY valid JSON matching the schema. No markdown. {JSON schema} Architecture critic system prompt (temperature 0). You are an architecture critic. Your job is to review an architecture graph produced by anothe...
-
[26]
PHANTOM NODES: Nodes that claim source files that don't exist
-
[27]
MISSED NODES: High-importance files not represented by any node
-
[28]
WRONG EDGES: Claimed data flow that doesn't match import structure
-
[29]
ai_core
MISCLASSIFIED ROLES: Nodes labeled as " ai_core" that don't use AI libraries
-
[30]
Assume the synthesizer made mistakes
DUPLICATE NODES: Two nodes representing the same component For each node, provide: - confidence (0-1): how confident you are this node is accurate - issues: list of problems found (empty if none) - suggestions: list of improvements Be adversarial. Assume the synthesizer made mistakes. Verify claims against the code. Return ONLY valid JSON matching the sch...
-
[31]
Classify each component into a pattern stage from the framework catalog
-
[32]
prompt_chain
Detect cross-cutting strategies that span multiple components. Unlike a per-component classifier, you can see the entire graph topology and detect graph-level patterns. {catalog: PATTERN STAGES and CROSS-CUTTING STRATEGIES as JSON} CROSS-CUTTING DETECTION RULES: RAG (Retrieval-Augmented Generation): - Retriever component feeding into a generator component...
-
[33]
If the component is itself an LLM-as-Judge / scorer / grader THAT EVALUATES ANOTHER AI MODEL'S OUTPUT ( not domain objects) -> "judge"
-
[34]
Else if the component is part of an agent loop (tool-calling, ReAct, planning) -> "agentic"
-
[35]
Else if the component retrieves external context and feeds it to an LLM (or is the retriever in a clear retriever-> generator pipeline) -> "rag"
-
[36]
evidence_match
Else if the component compares/reconciles evidence between two sources -> "evidence_match"
-
[37]
prompt_chain
Else if the component is one step in a sequential multi-LLM chain -> "prompt_chain"
-
[38]
none" A component's pipelinePattern is INDEPENDENT of its patternStage -- e.g. a RAG retriever has pipelinePattern=
Else (deterministic ETL, schema validation, infra glue, plain inference with no retrieval, etc.) -> "none" A component's pipelinePattern is INDEPENDENT of its patternStage -- e.g. a RAG retriever has pipelinePattern="rag" AND patternStage="knowledge_base". Do NOT return "none" just because the component is non-LLM; only pick "none" when no 16 LLM-pipeline...
-
[39]
PIPELINE FIT -- does this metric make logical sense for where this component sits? - What does this component actually consume from upstream, and what does it emit downstream? - Can this component genuinely influence what the metric measures, or does the real signal live in a different component entirely? ( e.g. a retriever being scored on generation qual...
-
[40]
non-empty retrieval result
VALIDITY CONDITIONS -- under what specific conditions does this metric produce signal ? - Enumerate the runtime conditions that must hold for the number to be meaningful (e.g. "non-empty retrieval result", " English query", "user session has prior turn", "source doc contains the entity being cited"). - Identify cases where the metric will return a value b...
-
[41]
compare to ground truth
DATA & SIGNAL ASSUMPTIONS -- what must be true of the system for this measurement to work? - List every artefact/signal the measurement depends on: labels, ground truth, judge model, traced IDs, structured logs, schemas, embedding store, golden datasets, 17 cost tracking, user feedback signal, etc. - Cross-check the source digest: do those artefacts actua...
-
[42]
function call count
QUALITY CHECKS -- apply the REJECT / FLAG criteria below. ======================= REJECT if: ======================= - Metric fails PIPELINE FIT: it measures something this component can't actually influence, or it fits the role generically rather than this component's actual behaviour. - Metric fails VALIDITY CONDITIONS: the conditions for it to mean any...
-
[43]
Deterministic counters/ rates/percentiles already arrive via the PRE-CHOSEN METRICS block (user prompt) and are merged automatically -- do NOT duplicate them
MAXIMUM {maxMetrics} LLM-JUDGE METRICS this call may emit. Deterministic counters/ rates/percentiles already arrive via the PRE-CHOSEN METRICS block (user prompt) and are merged automatically -- do NOT duplicate them. Quality over quantity -- fewer, deeper metrics
-
[44]
accuracy
DOMAIN-SPECIFIC: Each metric must reflect what this component ACTUALLY DOES. A retriever needs retrieval precision -- not generic "accuracy". A prompt builder needs instruction completeness -- not "latency". An agent orchestrator needs convergence score -- not "response quality". Ask: "What are the specific ways this component can fail?"
-
[45]
Relevancy and clarity are separate metrics, not one
ONE CRITERION PER METRIC: Never combine unrelated dimensions. Relevancy and clarity are separate metrics, not one
-
[46]
Use LLM-as-Judge ONLY for semantic quality that cannot be computed deterministically
RIGHT TOOL: Use code-based computation for anything measurable (format, thresholds, regex, counts, latency). Use LLM-as-Judge ONLY for semantic quality that cannot be computed deterministically. RETRIEVAL METRICS ARE NOT LLM-JUDGE: Retrieval relevance, precision@k, recall@k , MRR, NDCG, and context relevancy are computable via embedding similarity or fram...
-
[47]
NO REDUNDANCY: If two candidate metrics are correlated, keep only the one with higher signal
-
[48]
Non-deterministic components MUST have at least one LLM-as-Judge metric with a 3- point scoring rubric and CoT
-
[49]
Every threshold MUST include a justification grounded in the component's risk surface and blast radius -- no arbitrary numbers
-
[50]
traceability = citation coverage + link strength + evidence breadth), design a composite metric with weighted sub-metrics and a formula
COMPOSITE WHEN NATURAL: If a quality dimension has genuinely distinct sub- dimensions (e.g. traceability = citation coverage + link strength + evidence breadth), design a composite metric with weighted sub-metrics and a formula. Do NOT force composite structure when a single measurement suffices -- set both to null
-
[51]
Monitoring metrics should have a null scoringRubric
-
[52]
Accuracy + Latency is NOT a valid composite
COMPOSITE ANTI-PATTERN: NEVER combine orthogonal dimensions into a composite. Accuracy + Latency is NOT a valid composite. A composite is ONLY valid when sub-metrics measure the SAME quality from different angles (e.g. retrieval quality = precision + recall + MRR). If in doubt, use separate single-dimension metrics
-
[53]
X_grounding
GRANULAR JUDGES -- NO VAGUE UMBRELLA METRICS: When a component has internal sub -modules, tiers, or distinct LLM stages, design one metric per unique sub-concern -- each targeting a specific tier's distinct function. NEVER emit a broad module-level metric (e.g. "X_grounding", " 20 X_semantic_correctness", "X_output_quality ") that spans multiple tiers. In...
-
[54]
cost_per_quality
COST_PER_QUALITY TRIPLE-EMIT: For category ="cost_per_quality" you MUST emit a langfuseConfig containing ALL THREE of: (a ) costScorer reading usage.totalCost / usage.cost / sum_costDetails, (b) qualityScorer referencing one of the OTHER metrics in this same component's set via pairedMetricName (a quality/groundedness/ safety metric -- never another cost ...
-
[55]
Explain how they correlate -- e.g
TRACEABILITY LINKS: Map each evaluation metric to its closest monitoring counterpart(s). Explain how they correlate -- e.g. a latency spike may indicate quality degradation
-
[56]
For each gap, explain what is missing and suggest how to address it (e
MONITORING GAPS: Identify evaluation metrics that lack a runtime monitoring counterpart. For each gap, explain what is missing and suggest how to address it (e. g. add periodic sampling, add a new monitoring metric)
-
[57]
> 500ms for 5 minutes
ALERT CONFIGURATIONS: For each monitoring metric (existing and suggested), propose an alert config with: - A threshold condition (e.g. "> 500ms for 5 minutes") - A severity level (critical, warning, or info) - A recommended action when the alert fires
-
[58]
Reference actual source files when available
INTEGRATION POINTS: Identify specific files and code locations where instrumentation should be added for monitoring. Reference actual source files when available. GUIDELINES: - Every evaluation metric should ideally have at least one monitoring counterpart - Alerts should be actionable -- each alert must have a clear action to take - Severity should refle...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.