Ellipsoid Control: A White-list Jailbreak Defense via Benign Latent Modeling
Pith reviewed 2026-06-30 13:08 UTC · model grok-4.3
The pith
Ellipsoid Control elicits refusal on jailbreaks by constraining updates inside a benign latent ellipsoid fitted from safe data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
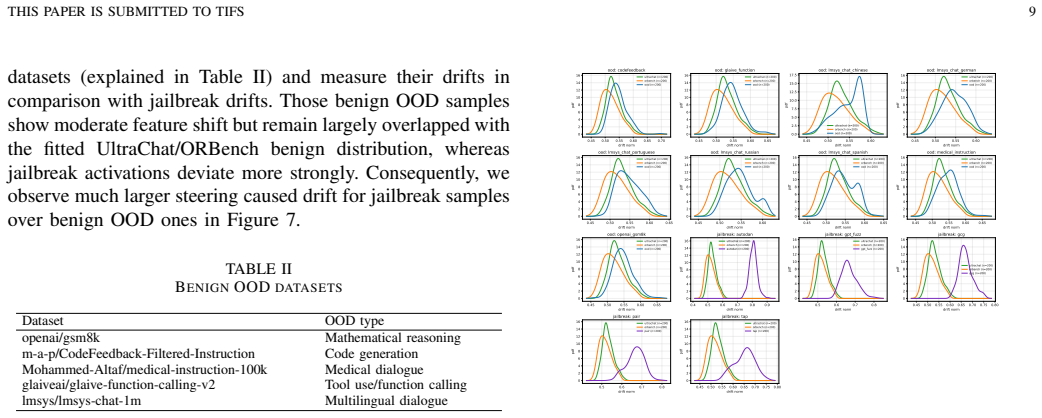
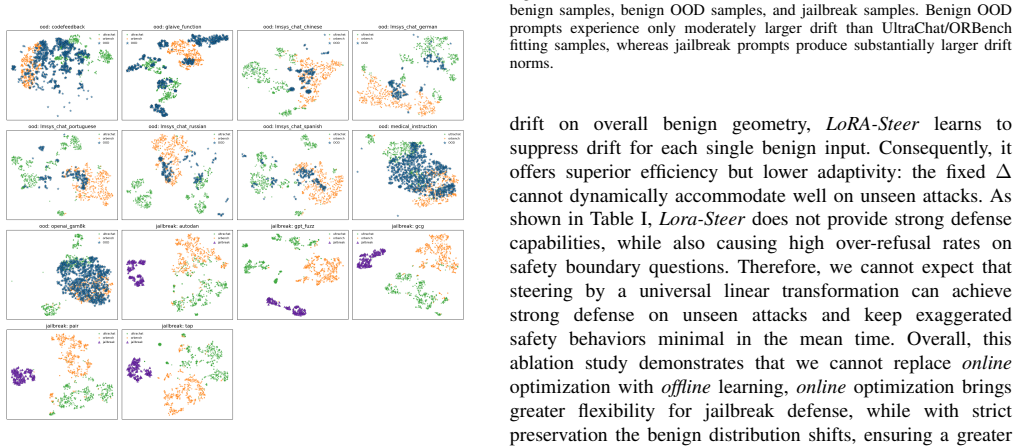
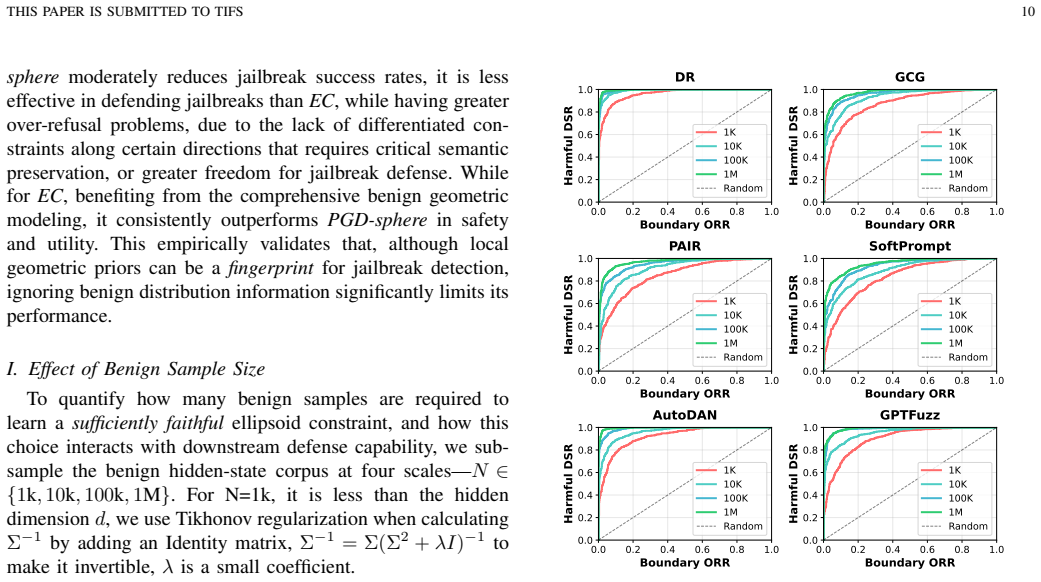
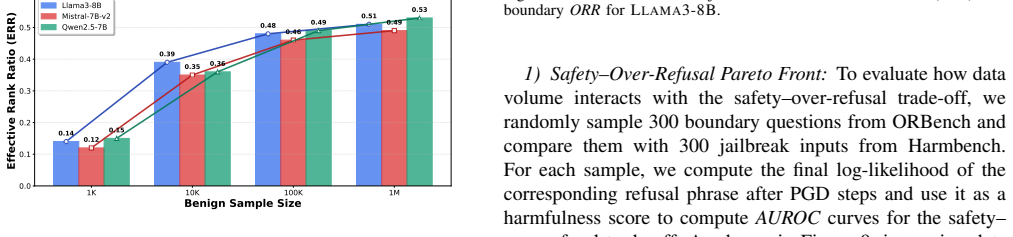
Ellipsoid Control is a test-time defense that fits an anisotropic ellipsoid from benign activations to tightly constrain the search space of projected gradient descent, allowing the model to generate refusal responses on arbitrary inputs while keeping the benign latent geometry intact and thus preserving utility on harmless tasks.
What carries the argument
An anisotropic benign-geometry ellipsoid fitted from benign activations that bounds the latent-space updates performed by projected gradient descent to elicit refusal.
If this is right
- Refusal can be elicited on unseen jailbreaks without any coverage of harmful distributions.
- Utility on benign tasks degrades less than with defenses that fit directly to harmful examples.
- The defense separates protection of the benign region from estimation of the harmful region.
- Safety gains remain consistent across different LLMs, attack methods, and safety-boundary tests.
Where Pith is reading between the lines
- Task-specific ellipsoids could be fitted to give finer control over different kinds of safe behavior.
- The result suggests that preserving latent geometry may matter more for utility than directly modeling attacks.
- Periodic refitting on new benign data could adapt the boundary as the model's normal usage evolves.
Load-bearing premise
That an anisotropic ellipsoid fitted from abundant benign data can constrain projected gradient descent updates tightly enough to minimize distortion of the benign latent geometry while still allowing refusal to be elicited on arbitrary inputs.
What would settle it
A jailbreak input on which the constrained projected gradient descent either fails to produce refusal or produces a measurable accuracy drop on standard benign benchmarks would falsify the central claim.
Figures

read the original abstract
Representation engineering (RepE) defenses have shown strong robustness against jailbreak attacks on large language models (LLMs). However, these methods fundamentally rely on black-list supervision: they learn jailbreak-to-refusal activation transformations from harmful or jailbreak data that are inherently incomplete and continuously evolving. Hence, the performance of RepE-based defenses becomes tightly coupled to the quality and coverage of collected harmful samples, leaving models vulnerable to unseen attacks. This reliance also obscures the distinction between defenses that fit known harmful distributions and defenses that protect a benign latent region without estimating the harmful distribution. We adopt the opposite, the white-list perspective, by leveraging the accessibility and abundance of benign data. The goal is to elicit refusal on arbitrary inputs while ensuring that harmless inputs are not falsely rejected. This shifts the core research question to: How can we design a robust benign-latent preservation mechanism such that the benign latent distribution remains intact while refusal is elicited? To answer this, we propose Ellipsoid Control, a test-time defense. It performs projected gradient descent that can elicit refusal on arbitrary inputs, aiming to improve defense effectiveness. At the same time, an anisotropic benign-geometry ellipsoid is fitted from abundant benign data to constrain the update to minimize distortion of the benign latent geometry. This tight constraint helps preserve model utility. Across multiple LLMs, jailbreak attacks, benign tasks, and safety-boundary evaluations, Ellipsoid Control consistently enhances safety while better preserving utility, demonstrating the effectiveness of the white-list approach for jailbreak defense
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Ellipsoid Control, a test-time white-list defense for LLMs against jailbreaks. It fits an anisotropic ellipsoid from abundant benign data to constrain PGD updates that elicit refusal on arbitrary inputs, aiming to preserve benign latent geometry and model utility while enhancing safety. The paper claims this approach consistently improves safety across multiple LLMs, jailbreak attacks, benign tasks, and safety-boundary evaluations while better preserving utility compared to black-list methods.
Significance. If the empirical claims hold, the work would be significant for shifting RepE defenses from black-list to white-list paradigms, potentially offering better robustness to evolving and unseen attacks by focusing on preserving benign regions rather than modeling harmful ones. The geometric constraint via ellipsoid could provide a principled way to balance safety and utility.
major comments (1)
- [Abstract] Abstract: The abstract states that Ellipsoid Control 'consistently enhances safety while better preserving utility' across evaluations but supplies no quantitative results, baselines, error bars, or experimental details; the central empirical claim cannot be assessed from the provided text alone.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that Ellipsoid Control 'consistently enhances safety while better preserving utility' across evaluations but supplies no quantitative results, baselines, error bars, or experimental details; the central empirical claim cannot be assessed from the provided text alone.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these metrics (including baselines, safety gains, utility preservation rates, and error bars) in the experimental sections. In the revised version we will update the abstract to incorporate representative numerical findings from those sections so that the central claims are directly assessable from the abstract alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper fits an anisotropic ellipsoid to abundant external benign activation data and uses the resulting region to constrain projected gradient descent updates that elicit refusal. The central claim is an empirical demonstration of improved safety-utility trade-off across multiple LLMs, attacks, and tasks. No derivation step reduces by construction to its own fitted parameters, no load-bearing self-citation chain is invoked, and the white-list framing is independent of the target refusal behavior. The method remains falsifiable on held-out data.
Axiom & Free-Parameter Ledger
free parameters (1)
- ellipsoid parameters
axioms (1)
- domain assumption Benign data is abundant and representative of the benign latent distribution
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lam- ple, “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
A. G. Qwen Team, “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Iron: Private inference on transformers,
M. Hao, H. Li, H. Chen, P. Xing, G. Xu, and T. Zhang, “Iron: Private inference on transformers,” inAdvances in Neural Information Processing Systems, vol. 35, 2022
2022
-
[5]
Efficient and privacy-enhanced federated learning for industrial artificial intelligence,
M. Hao, H. Li, X. Luo, G. Xu, H. Yang, and S. Liu, “Efficient and privacy-enhanced federated learning for industrial artificial intelligence,”IEEE Transactions on Industrial Informatics, vol. 16, no. 10, pp. 6532–6542, 2020
2020
-
[6]
Scalable zero-knowledge proofs for non- linear functions in machine learning,
M. Hao, H. Chen, H. Li, C. Weng, Y . Zhang, H. Yang, and T. Zhang, “Scalable zero-knowledge proofs for non- linear functions in machine learning,” in33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, 2024, pp. 3819–3836
2024
-
[7]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
S. Yi, Y . Liu, Z. Sun, T. Cong, X. He, J. Song, K. Xu, and Q. Li, “Jailbreak attacks and defenses against large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2407.04295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Improving alignment and robustness with circuit breakers,
A. Zou, L. Phan, J. Wang, D. Duenas, M. Lin, M. Andriushchenko, J. Z. Kolter, M. Fredrikson, and D. Hendrycks, “Improving alignment and robustness with circuit breakers,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, A. G...
2024
-
[9]
A. Sheshadri, A. Ewart, P. Guo, A. Lynch, C. Wu, V . Hebbar, H. Sleight, A. C. Stickland, E. Perez, D. Hadfield-Menell, and S. Casper, “Targeted latent adversarial training improves robustness to persistent harmful behaviors in llms,”CoRR, vol. abs/2407.15549,
-
[10]
Meng, C., Choi, K., Song, J., and Ermon, S
[Online]. Available: https://doi.org/10.48550/arXiv. 2407.15549
work page internal anchor Pith review doi:10.48550/arxiv
-
[11]
Refusal in Language Models Is Mediated by a Single Direction
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Pan- ickssery, W. Gurnee, and N. Nanda, “Refusal in language models is mediated by a single direction, 2024,”URL https://arxiv. org/abs/2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
G. Shen, D. Zhao, Y . Dong, X. He, and Y . Zeng, “Jailbreak antidote: Runtime safety-utility balance via sparse representation adjustment in large language models,”CoRR, vol. abs/2410.02298, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2410.02298
-
[13]
Programming refusal with conditional activation steering,
B. W. Lee, I. Padhi, K. N. Ramamurthy, E. Miehling, P. L. Dognin, M. Nagireddy, and A. Dhurandhar, “Programming refusal with conditional activation steering,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=Oi47wc10sm
2025
-
[14]
Soft prompt threats: Attacking safety alignment and unlearning in open-source llms through the embedding space,
L. Schwinn, D. Dobre, S. Xhonneux, G. Gidel, and S. G ¨unnemann, “Soft prompt threats: Attacking safety alignment and unlearning in open-source llms through the embedding space,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 20...
2024
-
[15]
arXiv preprint arXiv:2405.20947 , year=
J. Cui, W.-L. Chiang, I. Stoica, and C.-J. Hsieh, “Or- bench: An over-refusal benchmark for large language models,”arXiv preprint arXiv:2405.20947, 2024
-
[16]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. A. Forsyth, and D. Hendrycks, “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21- 27, 2024. OpenReview.net, 2024. [Online]. ...
2024
-
[17]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N. Jain, A. Schwarzschild, Y . Wen, G. Somepalli, J. Kirchenbauer, P.-y. Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Baseline defenses for adversarial attacks against aligned language models,” arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Defending large language models against jailbreak attacks via semantic smoothing,
J. Ji, B. Hou, A. Robey, G. J. Pappas, H. Hassani, THIS PAPER IS SUBMITTED TO TIFS 14 Y . Zhang, E. Wong, and S. Chang, “Defending large language models against jailbreak attacks via semantic smoothing,”CoRR, vol. abs/2402.16192, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.16192
-
[19]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
A. Robey, E. Wong, H. Hassani, and G. J. Pappas, “Smoothllm: Defending large language models against jailbreaking attacks,”arXiv preprint arXiv:2310.03684, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Defending against alignment-breaking attacks via robustly aligned llm,
B. Cao, Y . Cao, L. Lin, and J. Chen, “Defending against alignment-breaking attacks via robustly aligned llm,” arXiv preprint arXiv:2309.14348, 2023
-
[21]
Intention analysis makes llms a good jailbreak defender,
Y . Zhang, L. Ding, L. Zhang, and D. Tao, “Intention analysis makes llms a good jailbreak defender,”CoRR abs/2401.06561, vol. 12, p. 14, 2024
-
[22]
Gradient cuff: De- tecting jailbreak attacks on large language models by exploring refusal loss landscapes,
X. Hu, P.-Y . Chen, and T.-Y . Ho, “Gradient cuff: De- tecting jailbreak attacks on large language models by exploring refusal loss landscapes,” inNeural Information Processing Systems, 2024
2024
-
[23]
Gradsafe: detect- ing unsafe prompts for llms via safety-critical gradient analysis,
Y . Xie, M. Fang, R. Pi, and N. Gong, “Gradsafe: detect- ing unsafe prompts for llms via safety-critical gradient analysis,” inProc. 62nd Annual Meeting of the Associa- tion for Computational Linguistics (Long Papers), 2024
2024
-
[24]
HSF: defending against jailbreak attacks with hidden state filtering,
C. Qian, H. Zhang, L. Sha, and Z. Zheng, “HSF: defending against jailbreak attacks with hidden state filtering,” inCompanion Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025 - 2 May 2025, G. Long, M. Blumestein, Y . Chang, L. Lewin-Eytan, Z. H. Huang, and E. Yom- Tov, Eds. ACM, 2025, pp. 2078–2087. [Online]. A...
-
[25]
Y . Jiang, X. Gao, T. Peng, Y . Tan, X. Zhu, B. Zheng, and X. Yue, “Hiddendetect: Detecting jailbreak attacks against large vision-language models via monitoring hidden states,”CoRR, vol. abs/2502.14744, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502. 14744
-
[26]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnieret al., “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan et al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[29]
Enhancing chat language models by scaling high-quality instructional conversations,
N. Ding, Y . Chen, B. Xu, Y . Qin, S. Hu, Z. Liu, M. Sun, and B. Zhou, “Enhancing chat language models by scaling high-quality instructional conversations,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computation...
-
[30]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[31]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Ad- vances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[32]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generat- ing stealthy jailbreak prompts on aligned large language models,”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “GPTFUZZER: red teaming large language models with auto-generated jailbreak prompts,”CoRR, vol. abs/2309.10253, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2309. 10253
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309 2023
-
[35]
Jailbreaking Black Box Large Language Models in Twenty Queries
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,”arXiv preprint arXiv:2310.08419, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
T. B. Thompson and M. Sklar. Breaking circuit breakers. [Online]. Available: https://confirmlabs.org/posts/circuit breaking.html
-
[37]
L. Sheng, C. Shen, W. Zhao, J. Fang, X. Liu, Z. Liang, X. Wang, A. Zhang, and T.-S. Chua, “Alphasteer: Learn- ing refusal steering with principled null-space con- straint,”arXiv preprint arXiv:2506.07022, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.