WebChallenger: A Reliable and Efficient Generalist Web Agent
Pith reviewed 2026-06-27 13:43 UTC · model grok-4.3
The pith
WebChallenger reaches 56.3 percent on WebArena and similar scores on other benchmarks with off-the-shelf open-weight models by building three cognitive mechanisms on a DOM-derived page memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
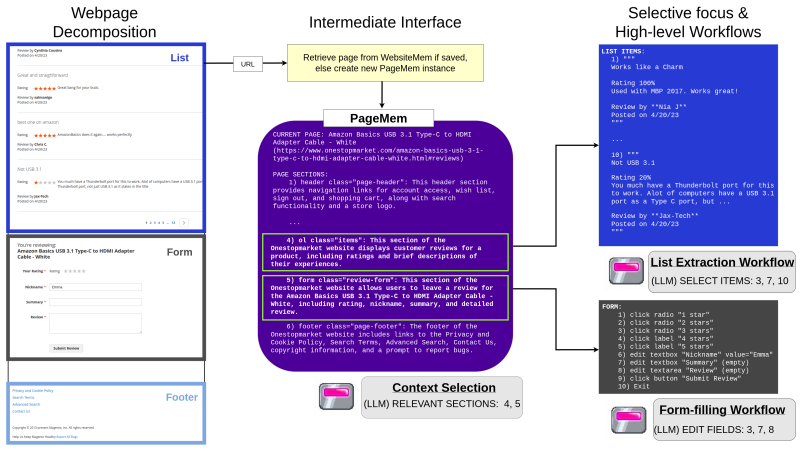
The central claim is that a single structured page representation, PageMem, constructed deterministically from the DOM as a hierarchy of semantic sections with short summaries, supplies the shared substrate for three mechanisms that replicate human cognitive advantages and thereby let open-weight models achieve competitive web-navigation performance across benchmarks without site-specific fine-tuning or proprietary reasoning models.
What carries the argument
PageMem, a deterministic hierarchy of semantic sections extracted from the DOM together with short summaries, which serves as the common substrate for the divide-and-conquer observation pipeline, the lightweight exploration-and-memory map, and the compound action workflows.
If this is right
- The agent can process only task-relevant sections after skimming summaries, lowering token usage per step.
- A single traversal of each site produces a reusable map that persists across tasks on that domain.
- Common multi-step patterns become single agent actions that manage partial state changes internally.
- The same PageMem substrate supports all three mechanisms, removing the need for per-site adapters.
- Open-weight models without fine-tuning reach performance levels previously associated only with frontier proprietary systems.
Where Pith is reading between the lines
- The same PageMem construction could be applied to non-browser interfaces whose state is exposed as a tree, such as mobile UIs or desktop applications.
- If section summaries prove stable across layout changes, the approach could reduce the frequency of full DOM re-parsing in long sessions.
- The lightweight memory map might be extended to track cross-site transitions when tasks span multiple domains.
- Compound workflows could be learned from interaction traces rather than hand-specified, further lowering the engineering burden.
Load-bearing premise
The claim that PageMem plus the three mechanisms generalize across arbitrary websites without site-specific adapters or retraining rests on the premise that DOM-derived semantic sections remain stable and sufficient for task-relevant reasoning on unseen sites and layouts.
What would settle it
A clear drop in success rate on a new website whose DOM sections change frequently or whose layout renders the semantic hierarchy uninformative would show that the generalization premise does not hold.
Figures

read the original abstract
Autonomous web navigation remains challenging for LLM agents, and the strongest generalist systems rely on proprietary reasoning models whose inference cost is prohibitive for the repetitive tasks where such agents would be most useful. We argue this gap stems not from insufficient model capability but from agent architectures that fail to replicate three human cognitive advantages: selective attention to relevant page regions, persistent memory of website structure, and procedural fluency with common interaction patterns. We introduce WebChallenger, a web agent framework that addresses each gap through architecture design rather than model scale, built around PageMem: a structured page representation deterministically constructed from the DOM that exposes each page as a hierarchy of semantic sections with short summaries. On this shared substrate we build three mechanisms that mirror the three cognitive advantages: a divide-and-conquer observation pipeline that lets the agent skim section summaries and extract details only from task-relevant regions; a lightweight exploration and memory system that traverses each website once to build a reusable map of pages and element behaviors; and compound action workflows that collapse common multi-step interactions into single agent actions, handling partial state changes automatically. Because all three operate over PageMem, the framework generalizes across websites without site-specific adapters. Using off-the-shelf open-weight models without fine-tuning, our system achieves 56.3% on WebArena, 48.7% on VisualWebArena, 51.0% on Online-Mind2Web, and 70.9% on WorkArena, approaching frontier proprietary systems at a fraction of the cost. Our code is released at https://github.com/jayoohwang1/webchallenger
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebChallenger, a web agent framework centered on PageMem—a deterministic, DOM-derived hierarchy of semantic sections with summaries—plus three mechanisms (divide-and-conquer observation, exploration/memory map, and compound action workflows) that together aim to replicate human-like selective attention, persistent memory, and procedural fluency. Using off-the-shelf open-weight models without fine-tuning, it reports success rates of 56.3% on WebArena, 48.7% on VisualWebArena, 51.0% on Online-Mind2Web, and 70.9% on WorkArena, claiming these approach frontier proprietary systems at lower cost while generalizing across websites without site-specific adapters or retraining. Code is released at the provided GitHub link.
Significance. If the reported results and generalization hold, the work would be significant for showing that targeted architectural choices can narrow the gap to proprietary systems using accessible open models, with direct implications for cost-effective deployment on repetitive web tasks. The open release of code is a strength that supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: the benchmark success rates are presented without ablations, error bars, variance across runs, or explicit details on partial-success scoring criteria; these omissions are load-bearing for the central claim of approaching frontier performance.
- [Abstract] Abstract / §1 (implied in the generalization argument): the claim that PageMem plus the three mechanisms enable generalization across arbitrary websites without site-specific adapters rests on the premise that DOM-derived semantic sections remain stable and sufficient on unseen sites and non-standard layouts, yet no robustness experiments, failure-mode analysis on atypical DOMs, or cross-benchmark transfer results are described to test this premise.
minor comments (1)
- [Abstract] Abstract: the GitHub link is given but the manuscript does not specify which exact benchmark configurations, model versions, or evaluation scripts are released to allow exact reproduction of the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing where revisions are warranted and providing clarifications based on the manuscript content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the benchmark success rates are presented without ablations, error bars, variance across runs, or explicit details on partial-success scoring criteria; these omissions are load-bearing for the central claim of approaching frontier performance.
Authors: We acknowledge that the abstract, being a concise summary, omits these details. The full manuscript provides ablations (Section 5), variance across runs with error bars (Table 2 and Appendix C), and explicit partial-success scoring criteria (Section 4.2). To strengthen the abstract's support for the claims, we will revise it to briefly reference the evaluation protocol and direct readers to the detailed results. revision: yes
-
Referee: [Abstract] Abstract / §1 (implied in the generalization argument): the claim that PageMem plus the three mechanisms enable generalization across arbitrary websites without site-specific adapters rests on the premise that DOM-derived semantic sections remain stable and sufficient on unseen sites and non-standard layouts, yet no robustness experiments, failure-mode analysis on atypical DOMs, or cross-benchmark transfer results are described to test this premise.
Authors: The generalization claim is supported by consistent results across four benchmarks spanning diverse websites, layouts, and interaction types (WebArena, VisualWebArena, Online-Mind2Web, WorkArena) without any site adapters or retraining. PageMem's deterministic DOM-derived hierarchy is designed for stability across arbitrary sites. While dedicated robustness experiments on atypical DOMs are not separately reported, the multi-benchmark evaluation serves as an implicit test of cross-site transfer. We will add a dedicated paragraph in the revised §1 and §6 discussing potential failure modes on non-standard layouts. revision: partial
Circularity Check
No circularity: architecture is design choice, results measured on external benchmarks
full rationale
The paper presents WebChallenger as an engineering framework whose core components (PageMem construction from DOM, divide-and-conquer observation, exploration/memory map, compound workflows) are introduced as explicit design decisions rather than outputs of any fitted parameters or self-referential equations. Performance numbers (56.3% WebArena, etc.) are reported as direct measurements on public external benchmarks using off-the-shelf models; no derivation chain reduces a claimed prediction back to its own inputs by construction. No self-citations appear in the provided text, and the generalization premise is stated as an architectural property rather than proven via internal equations or prior author work invoked as uniqueness theorems. This is a standard non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DOM structure can be deterministically partitioned into a hierarchy of semantic sections with short summaries that preserve task-relevant information.
invented entities (1)
-
PageMem
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2401.13649. Koh, J. Y ., McAleer, S., Fried, D., and Salakhutdinov, R. Tree search for language model agents,
-
[2]
Kuntz, T., Duzan, A., Zhao, H., Croce, F., Kolter, Z., Flammarion, N., and Andriushchenko, M
URLhttps://arxiv.org/abs/2407.01476. Kuntz, T., Duzan, A., Zhao, H., Croce, F., Kolter, Z., Flammarion, N., and Andriushchenko, M. Os-harm: A benchmark for measuring safety of computer use agents, 2025. URL https://arxiv. org/abs/2506.14866. 11 Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Effic...
arXiv 2025
-
[3]
URLhttps://arxiv.org/abs/2505.00684. Lù, X. H., Kasner, Z., and Reddy, S. Weblinx: Real-world website navigation with multi-turn dialogue, 2024. URLhttps://arxiv.org/abs/2402.05930. Marino, K. and Marasovi´c, A. Computer use survey: A visual survey of computer use agents, 2025. URLhttps://kennethmarino.com/computeruse/computeruse.html. Marreed, S., Oved, ...
-
[4]
URLhttps://arxiv.org/abs/2504.06821. Wu, C. H., Shah, R., Koh, J. Y ., Salakhutdinov, R., Fried, D., and Raghunathan, A. Dissecting adversarial robustness of multimodal lm agents, 2025. URL https://arxiv.org/abs/2406. 12814. Wu, X., Hong, G., Chen, Y ., Liu, M., Jin, F., Pan, X., Dai, J., and Liu, B. When bots take the bait: Exposing and mitigating the em...
arXiv 2025
-
[5]
URLhttps://arxiv.org/abs/2401.01614. Zheng, B., Fatemi, M. Y ., Jin, X., Wang, Z. Z., Gandhi, A., Song, Y ., Gu, Y ., Srinivasa, J., Liu, G., Neubig, G., and Su, Y . Skillweaver: Web agents can self-improve by discovering and honing skills, 2025a. URLhttps://arxiv.org/abs/2504.07079. Zheng, B., Liao, Z., Salisbury, S., Liu, Z., Lin, M., Zheng, Q., Wang, Z...
Pith/arXiv arXiv 2026
-
[6]
URLhttps://arxiv.org/abs/2307.13854. A Implementation Details A.1 PageMem We provide the details of our memory structure and describe the PageMem construction process. Each PageMem is built in two stages: DIVIDEPAGE(Algorithm 1) recursively partitions the live DOM tree into an ordered list of empty PageSections forming the structural skeleton of the page,...
Pith/arXiv arXiv 2024
-
[7]
n) {page_n} You should carefully think step-by-step to determine whether any of the pages would likely be useful for completing the task
{page_2} ... n) {page_n} You should carefully think step-by-step to determine whether any of the pages would likely be useful for completing the task. Include all pages that have the potential to be helpful for completing the task in any way. Provide your reasoning as: *THOUGHTS**: your reasoning steps Finally, select the relevant pages by providing a com...
-
[8]
You should carefully think step-by-step to determine which elements might help progress the task
{element_2} ... You should carefully think step-by-step to determine which elements might help progress the task. Provide your full reasoning process as: *THOUGHTS**: your reasoning steps 30 Finally, select one or more elements by providing the indices of your choices separated by commas: *SELECT ELEMENTS**: indices of selected element(s) (e.g. "1, 7") No...
-
[9]
You are only required to complete the steps explicitly defined by the instructions
-
[10]
As long as there are any next steps that need to be taken, the task completion status should be false
-
[11]
Tasks that involve buying an item should only be considered complete after adding the item to the cart and completing the full checkout process
-
[12]
show me the most expensive
If the user asks you to show them an item (e.g. "show me the most expensive ...", "show me the most recent ...", "find me a ..." etc.), then the task is not complete until the full details of the item are displayed by clicking its link
-
[13]
open my latest
If the task instructions asks you to open a page (e.g. "open my latest ..."), then the task is not fully complete until you have clicked the link for the page. Provide your thought process followed by your answer in this format: *THOUGHTS**: your reasoning process *TASK COMPLETE**: task completion status (True/False) FinalAnswer You are an intelligent vir...
-
[14]
**CHOICE**: 14
{field} ... n) {field} Think carefully about the task and identify the input fields that you need to select, then provide your reasoning as: *THOUGHT**: reasoning Finally, provide the list the of all form fields that should be updated for the task by providing a comma-separated sequence of integers corresponding to the indices of your choices as: *EDIT FI...
-
[15]
n) {option_n} Think step-by-step about the actions needed to complete the task and then answer with the value to enter into the selected input field
{option_2} ... n) {option_n} Think step-by-step about the actions needed to complete the task and then answer with the value to enter into the selected input field. If the task specifies an exact input option to select then your answer should match. Otherwise, choose the option that most closely matches with the task instructions given the task context. P...
-
[16]
The URL must be for the same website as the current page
-
[17]
OneStopMarket
Pay close attention to the previous URLs you have visited in order to help understand the URL structure used by the website. Provide your full reasoning process followed by your answer for the URL in this format: *THOUGHTS**: your reasoning steps *ANSWER**: URL 36 E.3 Other Prompts E.3.1 WebArena Multi-site You are an autonomous AI assistant who performs ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.