STAR-KV: Low-Rank KV Cache Compression via Soft Thresholding for Adaptive Rank Control
Pith reviewed 2026-06-27 18:32 UTC · model grok-4.3
The pith
A differentiable soft thresholding mechanism allows adaptive low-rank compression of the KV cache at head and block levels with up to 75% reduction and minimal accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STAR-KV achieves adaptive low-rank KV cache compression through a differentiable thresholding mechanism that selects optimal ranks at both attention-head and block levels, a hybrid decomposition strategy that applies different low-rank factorizations according to the sensitivity of key and value projections, and a low-rank-aware mixed precision quantization that leverages data statistics for near lossless low-bit quantization. Evaluated across multiple LLMs and benchmarks, this delivers up to 75% KV cache compression and up to 20x overall reduction when combined with quantization, along with up to 6.9x speedup for the attention module and 3.1x end-to-end generation throughput.
What carries the argument
The differentiable thresholding mechanism that enables optimal rank selection at attention-head and block levels.
If this is right
- KV cache memory footprint drops by up to 75 percent while accuracy stays close to the original model.
- Combining the compression with quantization yields up to 20 times overall KV cache size reduction.
- Attention module execution speeds up by as much as 6.9 times and end-to-end generation throughput by 3.1 times.
- The same framework applies across different LLMs and benchmarks without per-model retuning.
Where Pith is reading between the lines
- The per-head and per-block rank decisions could be applied to compress other transformer activations beyond the KV cache.
- The approach might allow longer context windows on hardware that previously hit memory limits.
- Further pairing with speculative decoding or other inference accelerations could produce multiplicative speed gains.
Load-bearing premise
The differentiable thresholding mechanism enables optimal rank selection at attention-head and block levels while maintaining minimal accuracy degradation, without requiring model-specific retuning or introducing training instability.
What would settle it
Applying the method to a new LLM on a standard benchmark where accuracy drops more than the minimal degradation reported or where compression falls short of 75% without retuning would show the central claim does not hold.
Figures








read the original abstract
Low-rank projection has emerged as a promising approach for compressing the KV cache by exploiting hidden-dimension redundancy. However, prior methods rely on fixed or heuristic rank selection and struggle to achieve aggressive compression with minimal accuracy degradation. We propose STAR-KV, an adaptive low-rank KV cache compression framework with fine-grained rank control. STAR-KV encompasses 1) a differentiable thresholding mechanism that enables optimal rank selection at both attention-head and block levels, 2) a hybrid decomposition strategy that applies different low-rank factorizations according to the sensitivity of key and value projections, and 3) a low-rank-aware mixed precision quantization that leverages data statistics for near lossless low-bit quantization. Evaluated across multiple LLMs and benchmarks, STAR-KV achieves up to 75% KV cache compression and up to 20x overall KV cache reduction when combined with quantization. Enabled by custom Triton-based GPU kernels, STAR-KV delivers up to 6.9x speedup for the attention module and 3.1x end-to-end generation throughput. Our code is publicly available at: https://github.com/PriyanshBhatnagar/STAR-KV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STAR-KV, an adaptive low-rank KV cache compression framework for LLMs featuring (1) a differentiable soft thresholding mechanism for per-head and per-block rank selection, (2) a hybrid decomposition strategy that applies different factorizations to key and value projections according to sensitivity, and (3) low-rank-aware mixed-precision quantization. It reports up to 75% KV cache compression (20× when combined with quantization), 6.9× attention-module speedup, and 3.1× end-to-end generation throughput across multiple LLMs and benchmarks, with publicly available code.
Significance. If the empirical claims hold and the adaptive mechanism generalizes without per-model retuning, the work would be a meaningful engineering advance for memory- and compute-efficient LLM inference. The public code and combination of adaptive rank control with quantization are concrete strengths that support reproducibility and practical impact.
major comments (2)
- [Method section (differentiable thresholding and hybrid decomposition)] The central claim that the differentiable thresholding mechanism enables optimal, stable rank selection at head/block levels without model-specific retuning or training instability is load-bearing for the reported 75% compression and 6.9× speedup. No analysis of gradient stability through the soft-threshold operator, convergence of the rank parameters, or cross-model transfer without retuning is provided.
- [Experimental evaluation] The experimental results section reports specific compression ratios, speedups, and accuracy numbers, yet provides insufficient detail on baselines, exact accuracy metrics, number of runs, statistical significance, and fair comparison of the custom Triton kernels, making it impossible to verify whether the claims are supported.
minor comments (2)
- [Abstract] The abstract states results are obtained 'across multiple LLMs and benchmarks' without naming them; adding the specific models and tasks would improve clarity.
- [Method section] Notation for the soft-threshold operator and the low-rank-aware quantizer could be made more explicit by including the forward/backward equations and the precise definition of the mixed-precision levels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Method section (differentiable thresholding and hybrid decomposition)] The central claim that the differentiable thresholding mechanism enables optimal, stable rank selection at head/block levels without model-specific retuning or training instability is load-bearing for the reported 75% compression and 6.9× speedup. No analysis of gradient stability through the soft-threshold operator, convergence of the rank parameters, or cross-model transfer without retuning is provided.
Authors: We agree that explicit analysis of gradient flow and convergence would strengthen the presentation. The soft-thresholding operator is constructed to be sub-differentiable, with non-zero gradients passed only through active components (analogous to proximal operators in sparse optimization). In the revised manuscript we will insert a new subsection (3.4) containing: (i) the gradient derivation, (ii) training curves for the learned rank parameters across layers, and (iii) an expanded transfer experiment showing that the same hyper-parameters yield comparable compression on Llama-2-7B, Mistral-7B, and Qwen-7B without per-model retuning. These additions will be accompanied by the already-public code. revision: yes
-
Referee: [Experimental evaluation] The experimental results section reports specific compression ratios, speedups, and accuracy numbers, yet provides insufficient detail on baselines, exact accuracy metrics, number of runs, statistical significance, and fair comparison of the custom Triton kernels, making it impossible to verify whether the claims are supported.
Authors: We accept that the current experimental section lacks sufficient detail for independent verification. In the revision we will expand Section 4 with: a complete baseline table including citations and implementation sources; precise metric definitions (WikiText-2 perplexity, zero-shot accuracy on the listed tasks); results from five independent runs reported as mean ± standard deviation; paired t-test p-values against the strongest baseline; and a dedicated paragraph describing the Triton kernels, hardware (A100-80GB), and identical evaluation protocol used for all methods. These changes will make the reported speedups and accuracy numbers fully reproducible. revision: yes
Circularity Check
No circularity; empirical engineering method with external validation
full rationale
The paper introduces STAR-KV as a practical compression framework relying on differentiable soft thresholding, hybrid K/V decomposition, and low-rank-aware quantization. All performance claims (75% compression, speedups) are presented as outcomes of empirical evaluation across multiple LLMs and benchmarks, with public code provided. No equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central mechanisms are proposed ansatzes validated externally rather than derived from prior results by the same authors in a load-bearing way.
Axiom & Free-Parameter Ledger
free parameters (2)
- soft thresholding parameters
- mixed precision levels
axioms (1)
- domain assumption Low-rank approximation can capture redundancy in KV projections without significant information loss
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
URL https://arxiv.org/abs/ 2305.13245. Ashkboos, S., Mohtashami, A., Croci, M. L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J. Quarot: Outlier-free 4-bit inference in ro- tated llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/ 2404.00456. Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y ., Tang, J., and Li, J. Longbench: A bilingual, multitask benchmark for long context understanding,
-
[3]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
URL https: //arxiv.org/abs/2308.14508. Chang, C.-C., Lin, W.-C., Lin, C.-Y ., Chen, C.-Y ., Hu, Y .- F., Wang, P.-S., Huang, N.-C., Ceze, L., Abdelfattah, M. S., and Wu, K.-C. Palu: Kv-cache compression with low-rank projection. InThe Thirteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Ding, Y ., Zhang, L. L., Zhang, C., Xu, Y ., Shang, N., Xu, J., Yang, F., and Yang, M. Longrope: Extending llm context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dodge, J., Sap, M., Marasovi ´c, A., Agnew, W., Ilharco, G., Groeneveld, D., Mitchell, M., and Gardner, M. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Moens, M.-F., Huang, X., Specia, L., and Yih, S. W.-t. (eds.),Pro- ceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1286–...
-
[7]
URL https://zenodo.org/records/12608602. Gholami, A., Yao, Z., Kim, S., Hooper, C., Mahoney, M. W., and Keutzer, K. Ai and memory wall.IEEE Micro, 44 (3):33–39,
-
[8]
URL https://arxiv.org/abs/2407.21783. Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y . S., Keutzer, K., and Gholami, A. Kvquant: Towards 10 million context length llm infer- ence with kv cache quantization,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B
URL https: //arxiv.org/abs/2401.18079. Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models?,
-
[10]
RULER: What's the Real Context Size of Your Long-Context Language Models?
URLhttps://arxiv.org/abs/2404.06654. Ji, T., Guo, B., Wu, Y ., Guo, Q., Shen, L., Chen, Z., Qiu, X., Zhang, Q., and Gui, T. Towards economical inference: Enabling deepseek’s multi-head latent attention in any 11 STAR-KV: Low-Rank KV Cache Compression via Soft Thresholding for Adaptive Rank Control transformer-based llms.arXiv preprint arXiv:2502.14837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https: //arxiv.org/abs/2310.06825. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th sym- posium on operating systems principles, pp. 611–626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
How long can context length of open-source LLMs truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Fol- lowing,
Li, D., Shao, R., Xie, A., Sheng, Y ., Zheng, L., Gonzalez, J., Stoica, I., Ma, X., and Zhang, H. How long can context length of open-source LLMs truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Fol- lowing,
2023
-
[13]
URL https://openreview.net/ forum?id=LywifFNXV5. Li, J., Zhang, Y ., Hassan, M. Y ., Chafekar, T., Cai, T., Ren, Z., Guo, P., Karimzadeh, F., Wang, C., and Gan, C. Com- mvq: Commutative vector quantization for kv cache com- pression.arXiv preprint arXiv:2506.18879,
-
[14]
Lin, B., Zeng, Z., Xiao, Z., Kou, S., Hou, T., Gao, X., Zhang, H., and Deng, Z. Matryoshkakv: Adaptive kv compression via trainable orthogonal projection.arXiv preprint arXiv:2410.14731,
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024a. Liu, H., Yan, W., Zaharia, M., and Abbeel, P. World model on million-length video and language with blockwise ringattention. InThe...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
URL https:// openreview.net/forum?id=HN8V0flwJF. Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V ., Chen, B., and Hu, X. Kivi: A tuning-free asym- metric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024b. Lozhkov, A., Ben Allal, L., von Werra, L., and Wolf, T. Fineweb-edu: the finest collection of educational content,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Pointer Sentinel Mixture Models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Saxena, U., Saha, G., Choudhary, S., and Roy, K
URL https://arxiv.org/abs/ 2510.24273. Saxena, U., Saha, G., Choudhary, S., and Roy, K. Eigen attention: Attention in low-rank space for kv cache com- pression,
-
[19]
Eigen attention: Attention in low-rank space for KV cache compression
URL https://arxiv.org/abs/ 2408.05646. Shah, J., Bikshandi, G., Zhang, Y ., Thakkar, V ., Ramani, P., and Dao, T. Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems, 37:68658–68685,
-
[20]
ISSN 0925-2312. doi: 10.1016/j.neucom. 2023.127063. URL https://doi.org/10.1016/ j.neucom.2023.127063. Su, Y ., Zhou, Y ., Qiu, Q., Li, J., Xia, Q., Li, P., Duan, X., Wang, Z., and Zhang, M. Accurate kv cache quan- tization with outlier tokens tracing.arXiv preprint arXiv:2505.10938,
-
[21]
Llama 2: Open Foundation and Fine-Tuned Chat Models
URL https://arxiv.org/abs/2307.09288. Tseng, A., Chee, J., Sun, Q., Kuleshov, V ., and De Sa, C. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.arXiv preprint arXiv:2402.04396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Efficient Streaming Language Models with Attention Sinks
URL https://arxiv.org/abs/ 2309.17453. Yan, X., Li, Z., Zhang, T., Qin, H., Kong, L., Zhang, Y ., and Yang, X. Recalkv: Low-rank kv cache compression via head reordering and offline calibration,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Recalkv: Low-rank kv cache compression via head reordering and offline calibration, 2025
URL https://arxiv.org/abs/2505.24357. Zhang, R., Wang, K., Liu, L., Wang, S., Cheng, H., Zhang, C., and Shen, Y . Lorc: Low-rank compression for llms kv cache with a progressive compression strategy.arXiv preprint arXiv:2410.03111,
-
[24]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
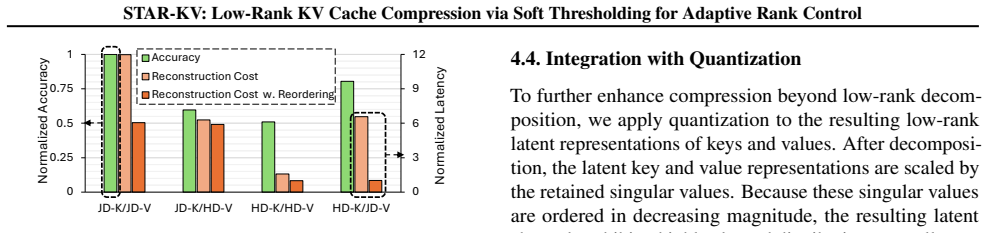
URL https: //arxiv.org/abs/2306.14048. 13 STAR-KV: Low-Rank KV Cache Compression via Soft Thresholding for Adaptive Rank Control A. Appendix A.1. Ablation Studies A.1.1. STATIC VS. ADAPTIVERANKSELECTION We compare adaptive rank selection against static low-rank compression. Static rank selection assigns auniformrank budget across all decoder blocks and at...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
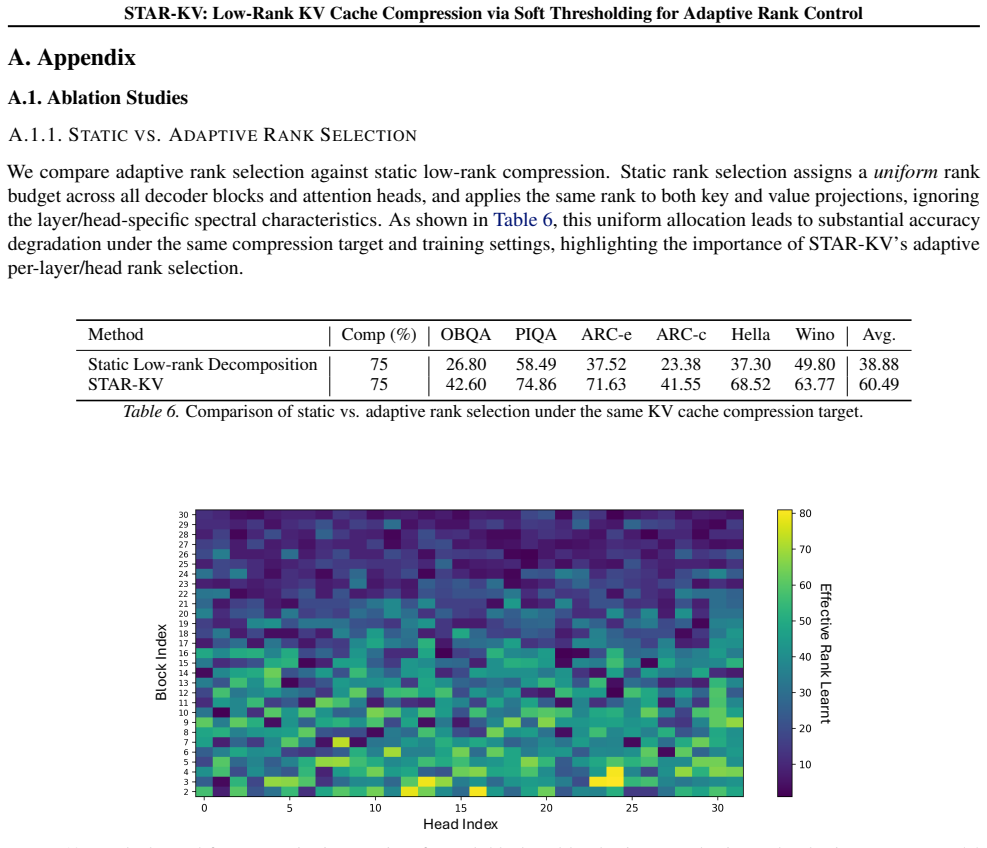
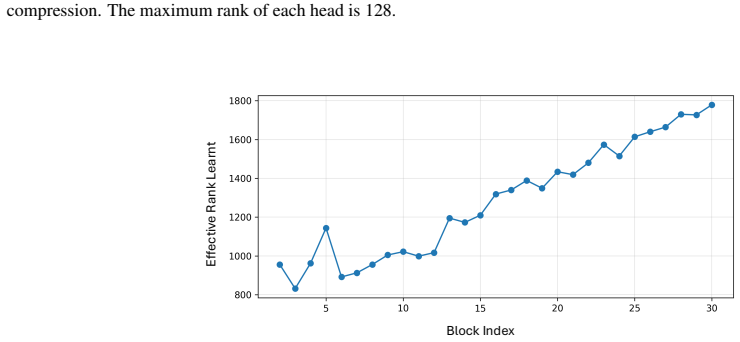
10 and Fig
Fig. 10 and Fig. 11 present the rank maps learned by the key and value projections, respectively, using our adaptive rank selection strategy based on the soft-thresholding mechanism. 14 STAR-KV: Low-Rank KV Cache Compression via Soft Thresholding for Adaptive Rank Control A.1.2. STABILITY OFLEARNEDRANKPROFILES We further analyze whether the learned rank p...
2024
-
[26]
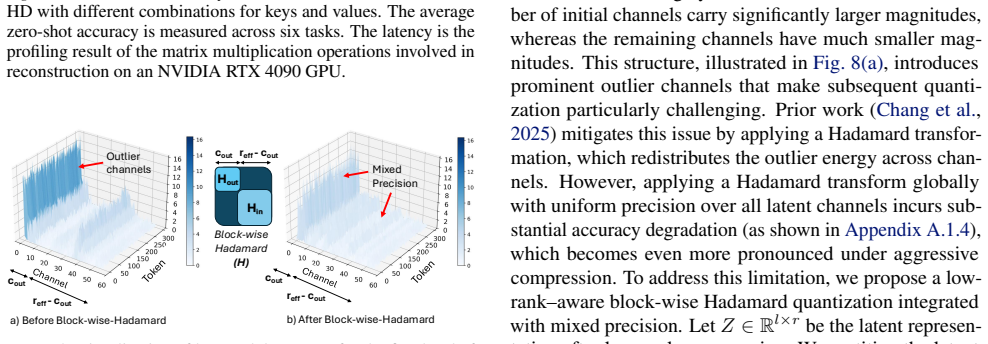
Table 9 isolates the roles of structured rotation and mixed-precision quantization
the proposed block-wise Hadamard with mixed precision. Table 9 isolates the roles of structured rotation and mixed-precision quantization. Applying a single global Hadamard with uniform 3-bit quantization improves robustness over naive quantization but still exhibits noticeable accuracy degradation, as it cannot selectively protect high-magnitude channels...
2025
-
[27]
On Mistral-7B-Instruct-v0.2, STAR-KV achieves a higher zero-shot average than ReCalKV at the same 60% KV cache compression rate. On LLaMA-2-13B, STAR-KV substantially outperforms Palu at 60% compression and remains competitive even at 75% compression. Model Method Comp (%) Wiki2 C4 LM Avg. OBQA PIQA ARC-e ARC-c Hella Wino Avg. Mistral-7B-Inst. Baseline 0 ...
-
[28]
At a context length of 128K, STAR-KV achieves a 2.9×speedup, and adding 4-bit KV quantization increases the speedup to 4.3×
Here, we limit the context length and batch size to a value that fits inside the GPU memory with the PyTorch SDPA baseline. At a context length of 128K, STAR-KV achieves a 2.9×speedup, and adding 4-bit KV quantization increases the speedup to 4.3×. A.6. Implementation Optimizations Operation Fusion.RoPE is often implemented as bandwidth-bound element-wise...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.