Stable Routing for Mixture-of-Experts in Class-Incremental Learning
Pith reviewed 2026-05-20 13:10 UTC · model grok-4.3
The pith
Aligning old-class routing to historical distributions stabilizes expandable mixture-of-experts in class-incremental learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
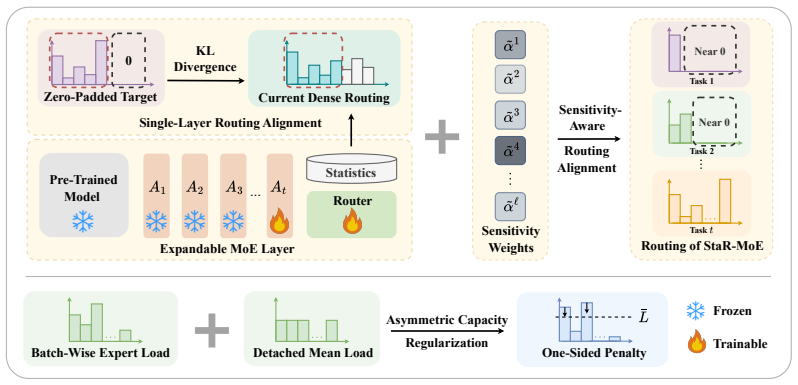
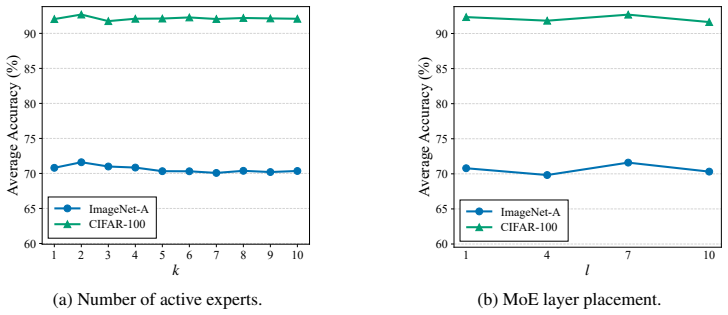
Expandable mixture-of-experts architectures for class-incremental learning require two complementary properties: stable old-class routing to preserve knowledge and sufficient capacity utilization for new-class adaptation. StaR-MoE realizes these properties through sensitivity-aware routing alignment, which matches the router's present behavior on old classes to historical routing distributions via sensitivity-guided constraints, together with asymmetric capacity regularization that encourages effective use of the expanded expert pool without eroding class-specific specialization.
What carries the argument
Sensitivity-aware routing alignment, which enforces that the current router's assignments for old-class samples remain close to their historical distributions by means of sensitivity-guided constraints.
If this is right
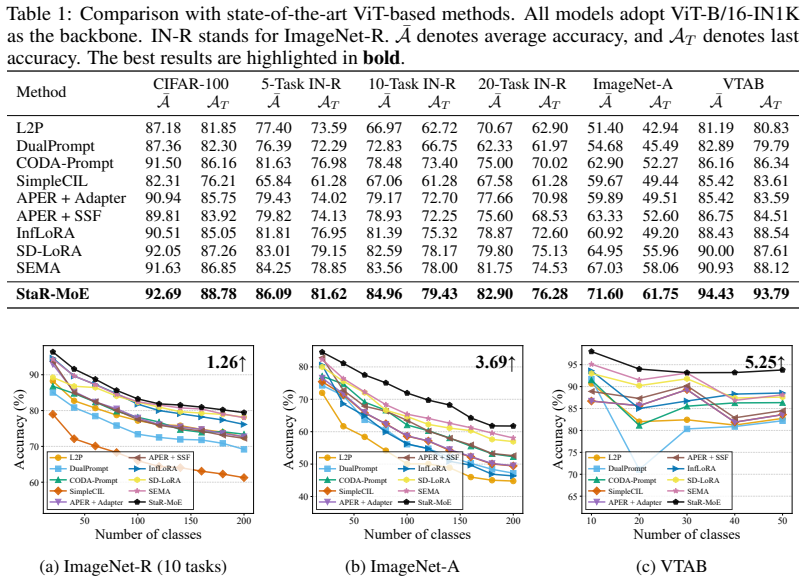
- StaR-MoE raises both average accuracy and last-task accuracy above prior state-of-the-art methods on four standard class-incremental learning benchmarks.
- Old-class knowledge remains more intact because expert assignments for those classes change less after new experts are introduced.
- New classes still receive adequate expert capacity because the regularization term remains asymmetric and does not force every sample onto old experts.
- The framework demonstrates that routing-level interventions can be added on top of frozen-expert expandable MoE without redesigning the underlying architecture.
Where Pith is reading between the lines
- The same sensitivity-guided alignment idea could be tested in other continual settings where model components are added incrementally, such as expanding transformer layers or growing neural architecture search outputs.
- If routing drift turns out to be the dominant interference mechanism, monitoring router sensitivity might serve as a general diagnostic for forgetting in any expert-based or modular continual-learning system.
- The approach leaves open whether similar constraints could be applied at the feature level rather than the routing level when experts are not strictly additive.
Load-bearing premise
The main source of interference is routing drift from expert expansion, and constraining the router to match historical distributions for old classes will preserve knowledge without preventing effective learning of new classes.
What would settle it
On any standard CIL benchmark, measure the change in routing probability vectors for old-class samples before and after each expert addition; if StaR-MoE does not produce measurably smaller changes than an unconstrained MoE baseline, or if removing the alignment term eliminates the reported accuracy gains, the central claim is falsified.
Figures



read the original abstract
Class-incremental learning (CIL) requires models to learn new classes sequentially while preserving prior knowledge. Recently, approaches that combine pre-trained models with mixture-of-experts (MoE) have received increasing attention in CIL: they typically expand experts during learning and employ a router to assign weights across experts. However, existing MoE methods often overlook routing drift induced by expert expansion. Once new experts are introduced, the router may reassign samples from earlier classes to newly added experts, thereby perturbing previously established expert compositions and causing interference even when old experts remain frozen. We argue that expandable MoE in CIL requires two complementary properties: stable old-class routing for knowledge preservation and sufficient capacity utilization for new-class adaptation. To this end, we propose Stable Routing for MoE (StaR-MoE), a routing-level framework for expandable MoE in CIL. By incorporating sensitivity-aware routing alignment, StaR-MoE aligns current old-class routing behavior with historical routing distributions through sensitivity-guided constraints. Complementarily, StaR-MoE introduces asymmetric capacity regularization to encourage effective utilization of the expanded expert pool without compromising class-specific routing specialization. Extensive experiments across four standard CIL benchmarks demonstrate that StaR-MoE consistently improves both average and last accuracy over state-of-the-art methods, highlighting the importance of stable routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StaR-MoE, a routing-level framework for expandable mixture-of-experts models in class-incremental learning. It identifies routing drift from expert expansion as a source of interference and introduces two components: sensitivity-aware routing alignment, which constrains current old-class routing to match historical distributions, and asymmetric capacity regularization, which promotes utilization of the expanded expert pool. Experiments across four standard CIL benchmarks report consistent gains in both average and last accuracy over prior state-of-the-art methods.
Significance. If the empirical results hold under closer scrutiny, the work is significant for highlighting routing stability as a distinct and actionable requirement in MoE-based CIL. The paired design of alignment for preservation and asymmetric regularization for plasticity offers a practical balance that prior expandable-MoE approaches appear to have under-emphasized. The multi-benchmark evaluation provides direct support for the central claim that stable routing reduces interference without sacrificing adaptation.
major comments (1)
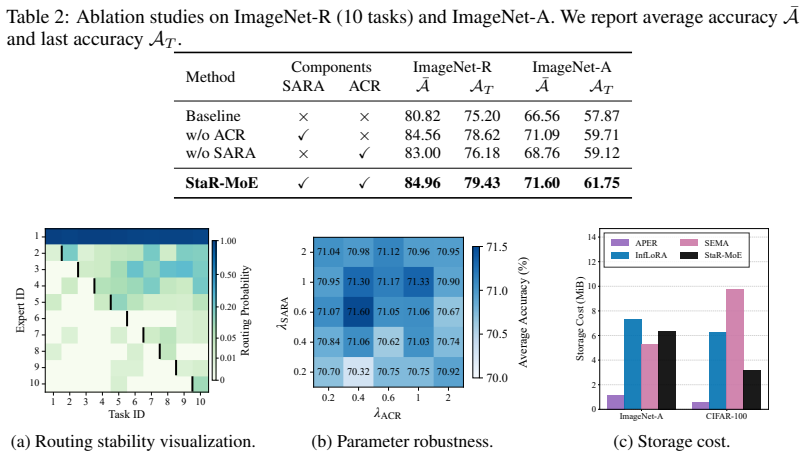
- [§3.2] §3.2 (sensitivity-aware routing alignment): the claim that aligning to historical routing distributions preserves knowledge without unduly restricting plasticity rests on the untested premise that historical router outputs for old classes remain near-optimal after expert expansion; an ablation that varies the alignment strength hyper-parameter and reports both old-class routing consistency (e.g., expert-assignment overlap) and new-class accuracy would directly test whether the constraint is load-bearing or merely additive.
minor comments (3)
- [Tables 1–2] Table 1 and Table 2: error bars or standard deviations across the reported runs are not shown; adding them would allow readers to judge whether the modest last-accuracy gains (typically 1–3 points) are statistically reliable.
- [§4.3] §4.3 (asymmetric capacity regularization): the precise form of the asymmetry (e.g., the weighting between old and new experts) is described only qualitatively; an explicit equation or pseudocode would improve reproducibility.
- [Figure 3] Figure 3: the visualization of routing distributions before and after alignment would benefit from a quantitative metric (e.g., KL divergence) in the caption to make the visual comparison more precise.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the specific suggestion to strengthen the analysis of sensitivity-aware routing alignment. We will incorporate the recommended ablation in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (sensitivity-aware routing alignment): the claim that aligning to historical routing distributions preserves knowledge without unduly restricting plasticity rests on the untested premise that historical router outputs for old classes remain near-optimal after expert expansion; an ablation that varies the alignment strength hyper-parameter and reports both old-class routing consistency (e.g., expert-assignment overlap) and new-class accuracy would directly test whether the constraint is load-bearing or merely additive.
Authors: We agree that an explicit ablation varying the alignment strength would provide stronger empirical support for the claim that historical routing distributions remain near-optimal for old classes post-expansion. In the revision we will add a study that sweeps the alignment strength hyper-parameter, reporting old-class routing consistency (expert-assignment overlap) together with new-class accuracy. This will clarify whether the constraint is load-bearing for the observed gains. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces StaR-MoE as a new routing-level framework that adds sensitivity-aware routing alignment (to match historical distributions) and asymmetric capacity regularization (to enable new-class adaptation). These are presented as complementary design choices motivated by the problem of routing drift, not as re-derivations or fits of prior quantities. The abstract and described properties contain no equations that reduce predictions to fitted inputs by construction, nor load-bearing self-citations that substitute for independent justification. Empirical gains across four CIL benchmarks are reported as external validation rather than tautological outcomes. The derivation remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Residual Learning for Image Recognition , author =. Proceedings of the
-
[2]
An Image is Worth 16x16 Words:
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , booktitle =. An Image is Worth 16x16 Words:
-
[3]
Psychology of Learning and Motivation , volume =
Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem , author =. Psychology of Learning and Motivation , volume =
-
[4]
Class-Incremental Learning: A Survey , author =. 2024 , publisher =
work page 2024
-
[5]
A Comprehensive Survey of Continual Learning: Theory, Method and Application , author =. 2024 , publisher =
work page 2024
-
[6]
Class-Incremental Learning: Survey and Performance Evaluation on Image Classification , author =. 2022 , publisher =
work page 2022
-
[7]
Nature Machine Intelligence , volume =
Three Types of Incremental Learning , author =. Nature Machine Intelligence , volume =. 2022 , publisher =
work page 2022
-
[8]
Learning to Prompt for Continual Learning , author =. Proceedings of the
-
[9]
Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas , booktitle =
-
[10]
Ge, Chendi and Wang, Xin and Zhang, Zeyang and Chen, Hong and Fan, Jiapei and Huang, Longtao and Xue, Hui and Zhu, Wenwu , booktitle =. Dynamic Mixture of Curriculum
-
[11]
Self-Expansion of Pre-trained Models with Mixture of Adapters for Continual Learning , author =. Proceedings of the
-
[12]
S-Prompts Learning with Pre-Trained Transformers: An
Wang, Yabin and Huang, Zhiwu and Hong, Xiaopeng , booktitle =. S-Prompts Learning with Pre-Trained Transformers: An
-
[13]
Liang, Yan-Shuo and Li, Wu-Jun , booktitle =
-
[14]
Wu, Yichen and Piao, Hongming and Huang, Long-Kai and Wang, Renzhen and Li, Wanhua and Pfister, Hanspeter and Meng, Deyu and Ma, Kede and Wei, Ying , booktitle =
-
[15]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
- [16]
-
[17]
Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt , booktitle =
-
[18]
Deep Learning Using Rectified Linear Units (
Agarap, Abien Fred , journal =. Deep Learning Using Rectified Linear Units (
-
[19]
International Conference on Learning Representations , year =
Towards a Unified View of Parameter-Efficient Transfer Learning , author =. International Conference on Learning Representations , year =
-
[20]
Expert Gate: Lifelong Learning with a Network of Experts , author =. Proceedings of the
-
[21]
Advances in Neural Information Processing Systems 33 , pages =
Dark Experience for General Continual Learning: A Strong, Simple Baseline , author =. Advances in Neural Information Processing Systems 33 , pages =
- [22]
- [23]
-
[24]
Task-Agnostic Guided Feature Expansion for Class-Incremental Learning , author =. Proceedings of the
-
[25]
International Conference on Learning Representations , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. International Conference on Learning Representations , year =
-
[26]
He, Jiangpeng and Duan, Zhihao and Zhu, Fengqing , booktitle =
-
[27]
Learning Multiple Layers of Features from Tiny Images , author =
-
[28]
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization , author =. Proceedings of the
- [29]
-
[30]
Moment Matching for Multi-Source Domain Adaptation , author =. Proceedings of the
-
[31]
International Journal of Computer Vision , volume =
Revisiting Class-Incremental Learning with Pre-Trained Models: Generalizability and Adaptivity Are All You Need , author =. International Journal of Computer Vision , volume =. 2025 , publisher =
work page 2025
-
[32]
Expandable Subspace Ensemble for Pre-Trained Model-Based Class-Incremental Learning , author =. Proceedings of the
-
[33]
Emerging Properties in Self-Supervised Vision Transformers , author =. Proceedings of the
-
[34]
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H. , booktitle =
-
[35]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
A large-scale study of representation learning with the visual task adaptation benchmark , author=. arXiv preprint arXiv:1910.04867 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[36]
Proceedings of the European Conference on Computer Vision , pages =
Memory Aware Synapses: Learning What (Not) to Forget , author =. Proceedings of the European Conference on Computer Vision , pages =
-
[37]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=. 2017 , publisher=
work page 2017
-
[38]
Proceedings of the 34th International Conference on Machine Learning , pages=
Continual learning through synaptic intelligence , author=. Proceedings of the 34th International Conference on Machine Learning , pages=
-
[39]
Proceedings of the 42nd International Conference on Machine Learning , year =
Addressing Imbalanced Domain-Incremental Learning through Dual-Balance Collaborative Experts , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[40]
Advances in Neural Information Processing Systems 36 , pages =
Hierarchical Decomposition of Prompt-Based Continual Learning: Rethinking Obscured Sub-Optimality , author =. Advances in Neural Information Processing Systems 36 , pages =
-
[41]
Zhang, Gengwei and Wang, Liyuan and Kang, Guoliang and Chen, Ling and Wei, Yunchao , booktitle =
-
[42]
Dual-Teacher Class-Incremental Learning with Data-Free Generative Replay , author =. Proceedings of the
-
[43]
Adaptive Plasticity Improvement for Continual Learning , author =. Proceedings of the
-
[44]
Proceedings of the European Conference on Computer Vision , pages =
Visual Prompt Tuning , author =. Proceedings of the European Conference on Computer Vision , pages =
-
[45]
Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters , author =. Proceedings of the
-
[46]
International Conference on Learning Representations , year =
Lifelong Learning with Dynamically Expandable Networks , author =. International Conference on Learning Representations , year =
-
[47]
Proceedings of the 36th International Conference on Machine Learning , pages=
Learn to grow: A continual structure learning framework for overcoming catastrophic forgetting , author=. Proceedings of the 36th International Conference on Machine Learning , pages=
-
[48]
Sokar, Ghada and Mocanu, Decebal Constantin and Pechenizkiy, Mykola , journal =. 2021 , publisher =
work page 2021
-
[49]
Advances in Neural Information Processing Systems 30 , pages =
Gradient Episodic Memory for Continual Learning , author =. Advances in Neural Information Processing Systems 30 , pages =
-
[50]
Advances in Neural Information Processing Systems 35 , pages =
Exploring Example Influence in Continual Learning , author =. Advances in Neural Information Processing Systems 35 , pages =
-
[51]
Trends in Cognitive Sciences , volume =
Catastrophic Forgetting in Connectionist Networks , author =. Trends in Cognitive Sciences , volume =. 1999 , publisher =
work page 1999
-
[52]
Psychological Review , volume =
Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights from the Successes and Failures of Connectionist Models of Learning and Memory , author =. Psychological Review , volume =. 1995 , publisher =
work page 1995
-
[53]
Class-Incremental Learning with
Huang, Linlan and Cao, Xusheng and Lu, Haori and Liu, Xialei , booktitle =. Class-Incremental Learning with
-
[54]
Guo, Xiaohan and Cai, Yusong and Liu, Zejia and Wang, Zhengning and Pan, Lili and Li, Hongliang , journal =
- [55]
-
[56]
Chen, Shoufa and Ge, Chongjian and Tong, Zhan and Wang, Jiangliu and Song, Yibing and Wang, Jue and Luo, Ping , booktitle=
-
[57]
Nair, Vinod and Hinton, Geoffrey E. , booktitle=. Rectified linear units improve
-
[58]
Journal of Machine Learning Research , volume =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , volume =
-
[59]
Huai, Tianyu and Zhou, Jie and Wu, Xingjiao and Chen, Qin and Bai, Qingchun and Zhou, Ze and He, Liang , booktitle =
-
[60]
Advances in Neural Information Processing Systems 37 , pages =
Mixture of Experts Meets Prompt-Based Continual Learning , author =. Advances in Neural Information Processing Systems 37 , pages =
-
[61]
Advances in Neural Information Processing Systems 13 , pages =
Incorporating Second-Order Functional Knowledge for Better Option Pricing , author =. Advances in Neural Information Processing Systems 13 , pages =
-
[62]
Transactions on Machine Learning Research , issn=
Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA , author=. Transactions on Machine Learning Research , issn=
-
[63]
Sun, Hai-Long and Zhou, Da-Wei and Ye, Han-Jia and Zhan, De-Chuan , journal =
-
[64]
International Conference on Learning Representations , year =
Divide and Not Forget: Ensemble of Selectively Trained Experts in Continual Learning , author =. International Conference on Learning Representations , year =
-
[65]
Sun, Hai-Long and Zhou, Da-Wei and Zhao, Hanbin and Gan, Le and Zhan, De-Chuan and Ye, Han-Jia , booktitle=
-
[66]
International Conference on Learning Representations , year =
One-Prompt Strikes Back: Sparse Mixture of Experts for Prompt-Based Continual Learning , author =. International Conference on Learning Representations , year =
-
[67]
Prototype augmentation and self-supervision for incremental learning , author=. Proceedings of the
-
[68]
Van der Maaten, Laurens and Hinton, Geoffrey , journal=. Visualizing data using t-
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.