Surflo: Consistent 3D Surface Flow Model with Global State
Pith reviewed 2026-06-27 06:57 UTC · model grok-4.3
The pith
Surflo compresses any number of unposed views into one global latent and decodes consistent 3D surface points at arbitrary resolution via flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
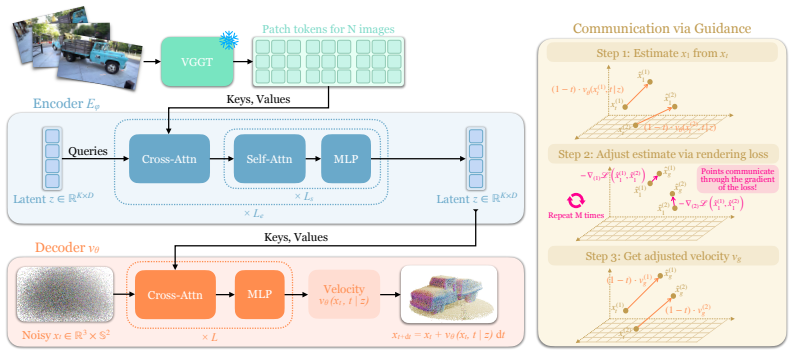
Surflo compresses a variable number of unposed RGB views into K latent tokens that encode one global state and decodes oriented 3D surface points by transporting them from noise onto the surface via flow matching; photometric gradient guidance injected during ODE integration suppresses inconsistencies that arise from independent per-point decoding, yielding the only feed-forward method that pairs a global latent with arbitrary-resolution output.
What carries the argument
Global latent tokens that encode 3D state from unposed views, paired with flow-matching transport of individual points from noise to surface and photometric guidance during integration.
If this is right
- The output point count can be chosen after the latent is computed, scaling from a few thousand to a million points without retraining.
- No explicit camera poses or view alignment step is required at inference time.
- Inference speed remains constant with respect to the number of input views once the latent is formed.
- The same global state supports both sparse and dense surface sampling in a single forward pass.
Where Pith is reading between the lines
- The global latent could serve as a drop-in replacement for per-view feature maps in other multi-view pipelines that currently duplicate computation across views.
- Because decoding is independent per point, the method might extend directly to streaming or incremental view addition without recomputing the entire output.
- The photometric guidance term suggests that consistency can be enforced at inference without changing the training loss, opening a route to test-time adaptation on new domains.
Load-bearing premise
A fixed number of latent tokens can hold enough 3D geometry from any number of unposed views to let independent per-point flow decoding stay consistent without explicit poses or alignment.
What would settle it
Running the same latent on two different random samplings of output points and measuring whether the resulting surfaces differ by more than the error of optimization-based baselines when the number of input views is increased.
Figures





read the original abstract
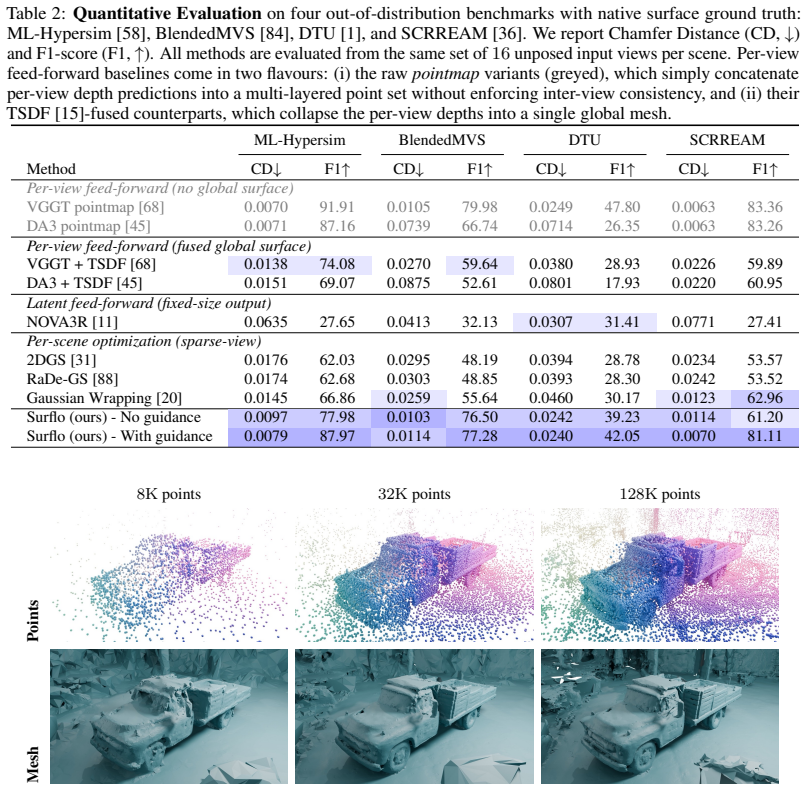
Geometry is invariant to viewpoint, which makes any collection of images a redundant encoding of a single 3D state. Existing feed-forward reconstruction models fail to exploit this: per-view methods emit overlapping, unaligned pointmaps that grow linearly with input count, while global-latent methods commit to a fixed, low-resolution output. We introduce Surflo, which compresses a variable number of unposed RGB views into K latent tokens-one global state-and decodes oriented 3D surface points by independently transporting them from noise onto the surface via flow matching. This frees the output from any fixed grid or token budget: the same latent yields from a few thousand to a million points in a single forward pass. To suppress the local inconsistencies inherent to independent per-point decoding, an inference-time guidance term correlates nearby points by injecting a photometric gradient during ODE integration. Surflo matches or surpasses feed-forward baselines on surface metrics, runs an order of magnitude faster than optimization-based methods that require hundreds of views, and is the only feed-forward approach to combine a global latent with arbitrary-resolution decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Surflo, a feed-forward 3D surface reconstruction model that compresses a variable number of unposed RGB views into a fixed set of K latent tokens representing one global 3D state. Oriented surface points are then decoded at arbitrary resolution by independently transporting noise samples onto the surface via flow matching; an inference-time photometric gradient term is added during ODE integration to enforce local consistency across points. The method is claimed to match or exceed feed-forward baselines on surface metrics while running an order of magnitude faster than optimization-based approaches that require hundreds of views.
Significance. If the central claims hold, the work would be significant for demonstrating that a compact global latent can support consistent, arbitrary-resolution surface decoding without explicit poses or view alignment, while delivering practical speed advantages over per-view or optimization-heavy pipelines. The combination of flow matching with photometric guidance at inference time is a distinctive technical choice that could influence subsequent latent-based 3D models.
major comments (2)
- [Abstract / method description] Abstract / method description: the claim that K fixed latent tokens suffice to encode a complete, canonical 3D state from an arbitrary number of unposed views is load-bearing for both the consistency guarantee and the arbitrary-resolution decoding result. The only cross-point mechanism described is the local photometric gradient injected during ODE integration; if the latent compression fails to canonicalize geometry across views, independent per-point trajectories will diverge even under guidance. This assumption requires either a theoretical argument or targeted ablations (e.g., varying input count while holding K fixed) to support the headline metrics.
- [Abstract] Abstract: the performance statements ('matches or surpasses feed-forward baselines on surface metrics' and 'order of magnitude faster than optimization-based methods') are presented without reference to specific tables, datasets, or baselines. Because the soundness assessment rests on these quantitative claims, the absence of supporting experimental details in the provided manuscript text makes it impossible to verify whether the latent actually produces usable 3D representations.
minor comments (2)
- The abstract refers to 'K latent tokens' without indicating how K is selected or its typical scale relative to input view count.
- Notation for the flow-matching ODE and the photometric guidance term should be introduced with explicit equations even in the abstract-level description to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we respond point-by-point to the major comments, providing clarifications drawn from the manuscript and indicating where revisions may be appropriate.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract / method description: the claim that K fixed latent tokens suffice to encode a complete, canonical 3D state from an arbitrary number of unposed views is load-bearing for both the consistency guarantee and the arbitrary-resolution decoding result. The only cross-point mechanism described is the local photometric gradient injected during ODE integration; if the latent compression fails to canonicalize geometry across views, independent per-point trajectories will diverge even under guidance. This assumption requires either a theoretical argument or targeted ablations (e.g., varying input count while holding K fixed) to support the headline metrics.
Authors: We agree that validating the sufficiency of the fixed-K latent is central. Section 3.1 details how the view-agnostic encoder uses multi-view cross-attention to aggregate all input images into the K tokens, explicitly targeting a canonical 3D state. Section 4.3 reports targeted ablations that vary input view count (3 to 100) while holding K fixed; surface metrics remain stable, supporting that the latent encodes complete geometry. The photometric guidance then enforces local consistency during decoding. We can add a short theoretical paragraph on viewpoint invariance in the revision if requested. revision: partial
-
Referee: [Abstract] Abstract: the performance statements ('matches or surpasses feed-forward baselines on surface metrics' and 'order of magnitude faster than optimization-based methods') are presented without reference to specific tables, datasets, or baselines. Because the soundness assessment rests on these quantitative claims, the absence of supporting experimental details in the provided manuscript text makes it impossible to verify whether the latent actually produces usable 3D representations.
Authors: The abstract follows standard conventions by summarizing headline results at a high level. Full experimental details, including exact baselines (e.g., PixelNeRF, MonoSDF), datasets (DTU, BlendedMVS), and quantitative tables (Table 1 for surface metrics, Table 2 for runtime), appear in Section 4 of the manuscript. For example, Surflo reports lower mean Chamfer distance than feed-forward baselines while achieving ~10x faster inference than optimization methods requiring hundreds of views. We do not believe abstract-level references to tables are necessary or conventional, but can insert a brief pointer to Section 4 if the editor prefers. revision: no
Circularity Check
No circularity detected in derivation
full rationale
The provided abstract and description introduce Surflo as a compression of variable unposed views into fixed latent tokens followed by independent flow-matching transport with optional photometric guidance. No equations, parameter fits, or self-citations are shown that reduce the claimed consistency or arbitrary-resolution output to a tautology of the inputs. The method description relies on standard flow matching and external photometric terms without self-definitional loops or fitted-input predictions. The central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Geometry is invariant to viewpoint, making any collection of images a redundant encoding of a single 3D state.
Reference graph
Works this paper leans on
-
[1]
Large-scale data for multiple-view stereopsis.International Journal of Computer Vision (IJCV), 120:153–168, 2016
Henrik Aanæs, Rasmus Ramsbøl Jensen, George V ogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-scale data for multiple-view stereopsis.International Journal of Computer Vision (IJCV), 120:153–168, 2016
2016
-
[2]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[3]
Albergo, Nicholas M
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research (JMLR),
-
[4]
Visual imitation enables contextual humanoid control
Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllister, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, and Angjoo Kanazawa. Visual imitation enables contextual humanoid control. InProceedings of the Conference on Robot Learning (CoRL), 2025
2025
-
[5]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 843–852, 2023
2023
-
[6]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip- NeRF 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[7]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Zip-NeRF: Anti-aliased grid-based neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[8]
Chan, Koki Nagano, Matthew A
Eric R. Chan, Koki Nagano, Matthew A. Chan, Alexander W. Bergman, Jeong Joon Park, Axel Levy, Miika Aittala, Shalini De Mello, Tero Karras, and Gordon Wetzstein. Generative novel view synthesis with 3D-aware diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4217–4229, 2023
2023
-
[9]
ReconViaGen: Towards accurate multi-view 3D 11 object reconstruction via generation
Jiahao Chang, Chongjie Ye, Yushuang Wu, Yuantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, and Xiaoguang Han. ReconViaGen: Towards accurate multi-view 3D 11 object reconstruction via generation. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2510.23306
arXiv 2026
-
[10]
pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19457–19467, 2024. Best Paper Runner-Up
2024
-
[11]
NOV A3R: Non-pixel-aligned visual transformer for amodal 3D reconstruction
Weirong Chen, Chuanxia Zheng, Ganlin Zhang, Andrea Vedaldi, and Daniel Cremers. NOV A3R: Non-pixel-aligned visual transformer for amodal 3D reconstruction. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2603.04179
arXiv 2026
-
[12]
Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[13]
MVSplat: Efficient 3D Gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. MVSplat: Efficient 3D Gaussian splatting from sparse multi-view images. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[14]
McCann, Marc L
Hyungjin Chung, Jeongsol Kim, Michael T. McCann, Marc L. Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[15]
A volumetric method for building complex models from range images
Brian Curless and Marc Levoy. A volumetric method for building complex models from range images. InACM SIGGRAPH Conference Proceedings, 1996
1996
-
[16]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[17]
Don’t drop your samples! coherence-aware training benefits conditional diffusion
Nicolas Dufour, Victor Besnier, Vicky Kalogeiton, and David Picard. Don’t drop your samples! coherence-aware training benefits conditional diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6264–6273, 2024
2024
-
[18]
Nicolas Dufour, Lucas Degeorge, Arijit Ghosh, Vicky Kalogeiton, and David Picard. MIRO: Multi-reward conditioned pretraining improves t2i quality and efficiency.arXiv preprint arXiv:2510.25897, 2025
Pith/arXiv arXiv 2025
-
[19]
Srinivasan, Jonathan T
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole. CAT3D: Create anything in 3D with multi-view diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[20]
Diego Gomez, Nissim Maruani, Antoine Guédon, Maks Ovsjanikov, and George Drettakis. From blobs to spokes: High-fidelity surface reconstruction via oriented Gaussians.arXiv preprint arXiv:2604.07337, 2026
Pith/arXiv arXiv 2026
-
[21]
Radiant foam: Real-time differentiable ray tracing
Shrisudhan Govindarajan, Daniel Rebain, Kwang Moo Yi, and Andrea Tagliasacchi. Radiant foam: Real-time differentiable ray tracing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4135–4145, 2025
2025
-
[22]
SuGaR: Surface-aligned Gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering
Antoine Guédon and Vincent Lepetit. SuGaR: Surface-aligned Gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5354–5363, 2024
2024
-
[23]
MILo: Mesh-in-the-loop Gaussian splatting for detailed and efficient surface reconstruction.ACM Transactions on Graphics (Proc
Antoine Guédon, Diego Gomez, Nissim Maruani, Bingchen Gong, George Drettakis, and Maks Ovsjanikov. MILo: Mesh-in-the-loop Gaussian splatting for detailed and efficient surface reconstruction.ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 44(6), 2025
2025
-
[24]
MAtCha Gaussians: At- las of Charts for High-Quality Geometry and Photorealism From Sparse Views
Antoine Guédon, Tomoki Ichikawa, Kohei Yamashita, and Ko Nishino. MAtCha Gaussians: At- las of Charts for High-Quality Geometry and Photorealism From Sparse Views. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 12
2025
-
[25]
Moayed Haji-Ali, Willi Menapace, Ivan Skorokhodov, Dogyun Park, Anil Kag, Michael Vasilkovsky, Sergey Tulyakov, Vicente Ordonez, and Aliaksandr Siarohin. One model, many budgets: Elastic latent interfaces for diffusion transformers.arXiv preprint arXiv:2603.12245, 2026
arXiv 2026
-
[26]
Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J. Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon. Manifold Preserving Guided Diffusion. InInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[27]
Peter Hedman, Julien Philip, True Price, Jan-Michael Frahm, George Drettakis, and Gabriel J. Brostow. Deep blending for free-viewpoint image-based rendering.ACM Transactions on Graphics (Proc. SIGGRAPH Asia), 37(6), 2018
2018
-
[28]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[29]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[30]
LRM: Large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[31]
2D Gaussian splat- ting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2D Gaussian splat- ting for geometrically accurate radiance fields. InACM SIGGRAPH Conference Proceedings, 2024
2024
-
[32]
Scalable adaptive computation for iterative generation
Allan Jabri, David Fleet, and Ting Chen. Scalable adaptive computation for iterative generation. arXiv preprint arXiv:2212.11972, 2022
arXiv 2022
-
[33]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver: General perception with iterative attention. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[34]
Perceiver IO: A general architecture for structured inputs and outputs
Andrew Jaegle, Sébastien Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A general architecture for structured inputs and outputs. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[35]
Pow3R: Empowering unconstrained 3D reconstruction with camera and scene priors
Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, and Jérôme Revaud. Pow3R: Empowering unconstrained 3D reconstruction with camera and scene priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1071–1081, 2025
2025
-
[36]
SCRREAM: SCan, register, REnder and map: A framework for annotating accurate and dense 3D indoor scenes with a benchmark
Hyun Jun Jung, Weihang Li, Shun-Cheng Wu, William Bittner, Nikolas Brasch, Jifei Song, Eduardo Pérez-Pellitero, Zhensong Zhang, Arthur Moreau, Nassir Navab, and Benjamin Busam. SCRREAM: SCan, register, REnder and map: A framework for annotating accurate and dense 3D indoor scenes with a benchmark. InAdvances in Neural Information Processing Systems (NeurI...
2024
-
[37]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[38]
Poisson surface reconstruction
Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. In Symposium on Geometry Processing (SGP), 2006
2006
-
[39]
MapAnything: Universal feed-forward metric 3D reconstruc- tion
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, To- bias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. MapAnything: Universal feed-forward metric 3D reconstruc- tion....
2026
-
[40]
3D Gaus- sian splatting for real-time radiance field rendering.ACM Transactions on Graphics (Proc
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3D Gaus- sian splatting for real-time radiance field rendering.ACM Transactions on Graphics (Proc. SIGGRAPH), 42(4), 2023
2023
-
[41]
Vergleichende Betrachtungen über neuere geometrische Forschungen.Mathematis- che Annalen, 43:63–100, 1893
Felix Klein. Vergleichende Betrachtungen über neuere geometrische Forschungen.Mathematis- che Annalen, 43:63–100, 1893
-
[42]
Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (Proc
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (Proc. SIGGRAPH), 36(4), 2017
2017
-
[43]
Grounding image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3D with MASt3R. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[44]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[45]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[46]
DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Xingpeng Sun, Rohan Ashok, Aniruddha Mukherjee, Hao Kang, Xiangrui Kong, Gang Hua, Tianyi Zhang, Bedrich Benes, and Aniket Bera. DL3DV-10K: A large-scale scene dataset for deep learning-based 3D vision. InProceedings of the IEEE/CVF Conf...
2024
-
[47]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[48]
Mukund Varma, Zexiang Xu, and Hao Su
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, T. Mukund Varma, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3D mesh in 45 seconds without per-shape optimization. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[49]
Zero-1-to-3: Zero-shot one image to 3D object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3D object. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[50]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[51]
Wonder3D: Single image to 3D using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3D: Single image to 3D using cross-domain diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[52]
Lorensen and Harvey E
William E. Lorensen and Harvey E. Cline. Marching cubes: A high resolution 3D surface construction algorithm. InACM SIGGRAPH Computer Graphics, volume 21, pages 163–169, 1987
1987
-
[53]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision (ECCV), 2020
2020
-
[54]
Instant neural graph- ics primitives with a multiresolution hash encoding.ACM Transactions on Graphics (Proc
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graph- ics primitives with a multiresolution hash encoding.ACM Transactions on Graphics (Proc. SIGGRAPH), 41(4), 2022
2022
-
[55]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-E: A system for generating 3D point clouds from complex prompts.arXiv preprint arXiv:2212.08751, 2022. 14
Pith/arXiv arXiv 2022
-
[56]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[57]
Barron, and Ben Mildenhall
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. DreamFusion: Text-to-3D using 2D diffusion. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[58]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[59]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
2022
-
[60]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021
2021
-
[61]
Loss-guided diffusion models for plug-and-play controllable generation
Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[62]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
2021
-
[63]
Splatter image: Ultra-fast single-view 3D reconstruction
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Splatter image: Ultra-fast single-view 3D reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10208–10217, 2024
2024
-
[64]
Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[65]
Least-Squares Estimation of Transformation Parameters Between Two Point Patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991
Shinji Umeyama. Least-Squares Estimation of Transformation Parameters Between Two Point Patterns.IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(4):376–380, 1991
1991
-
[66]
LION: Latent point diffusion models for 3D shape generation
Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. LION: Latent point diffusion models for 3D shape generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[67]
3D reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3D reconstruction with spatial memory. InInternational Conference on 3D Vision (3DV), 2025. arXiv:2408.16061, 2024
Pith/arXiv arXiv 2025
-
[68]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. Best Paper Award
2025
-
[69]
NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[70]
Efros, and Angjoo Kanazawa
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3D perception model with persistent state. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10510–10522, 2025
2025
-
[71]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5261–5271, 2025. 15
2025
-
[72]
MoGe-2: Accurate monocular geometry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. MoGe-2: Accurate monocular geometry with metric scale and sharp details. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[73]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jérôme Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[74]
π3: Permutation-equivariant visual geometry learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2507.13347
Pith/arXiv arXiv 2026
-
[75]
Pro- lificDreamer: High-fidelity and diverse text-to-3D generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificDreamer: High-fidelity and diverse text-to-3D generation with variational score distillation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[76]
NeRFbusters: Removing ghostly artifacts from casually captured NeRFs
Frederik Warburg, Ethan Weber, Matthew Tancik, Aleksander Holynski, and Angjoo Kanazawa. NeRFbusters: Removing ghostly artifacts from casually captured NeRFs. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[77]
Dongxu Wei, Qi Xu, Zhiqi Li, Hangning Zhou, Cong Qiu, Hailong Qin, Mu Yang, Zhaopeng Cui, and Peidong Liu. Any 3D scene is worth 1K tokens: 3D-grounded representation for scene generation at scale.arXiv preprint arXiv:2604.11331, 2025. Project: https://wswdx. github.io/3DRAE/
Pith/arXiv arXiv 2025
-
[78]
Srinivasan, Dor Verbin, Jonathan T
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P. Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, and Aleksander Holynski. ReconFusion: 3D reconstruction with diffusion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21551–21561, 2024
2024
-
[79]
Ziyuan Xia, Jingyi Xu, Chong Cui, Yuanhong Yu, Jiazhao Zhang, Qingsong Yan, Tao Ni, Junbo Chen, Xiaowei Zhou, Hujun Bao, Ruizhen Hu, and Sida Peng. Habitat-gs: A high-fidelity navigation simulator with dynamic gaussian splatting.arXiv preprint arXiv:2604.12626, 2026
Pith/arXiv arXiv 2026
-
[80]
Structured 3D latents for scalable and versatile 3D generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3D latents for scalable and versatile 3D generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.