Modular Diffusion Models for Structured Visual Recognition
Pith reviewed 2026-06-26 10:26 UTC · model grok-4.3
The pith
Modular Diffusion Models decompose the diffusion process into independent task-specific modules to learn distributions over structured visual outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
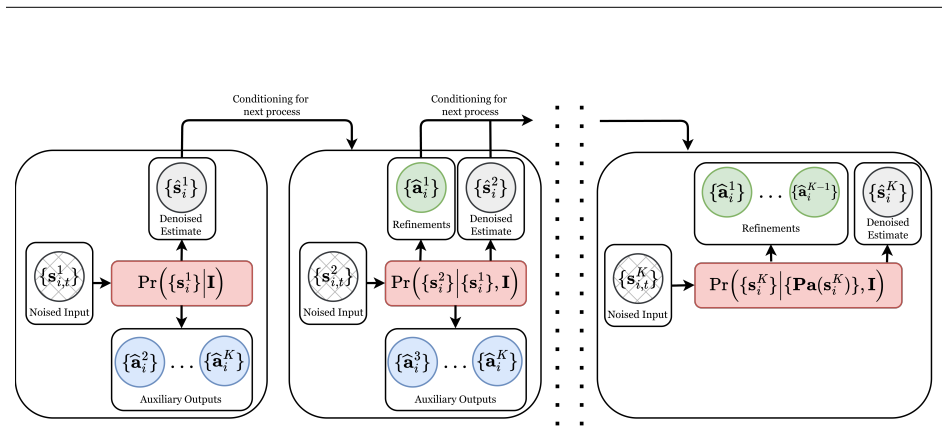
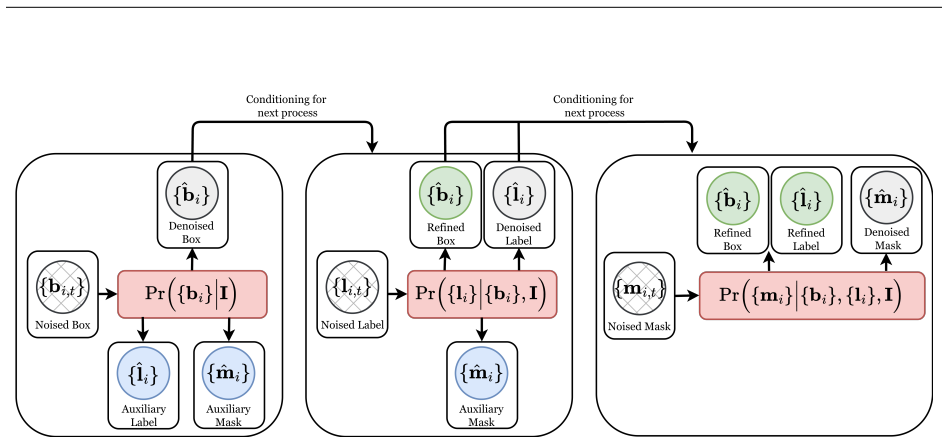
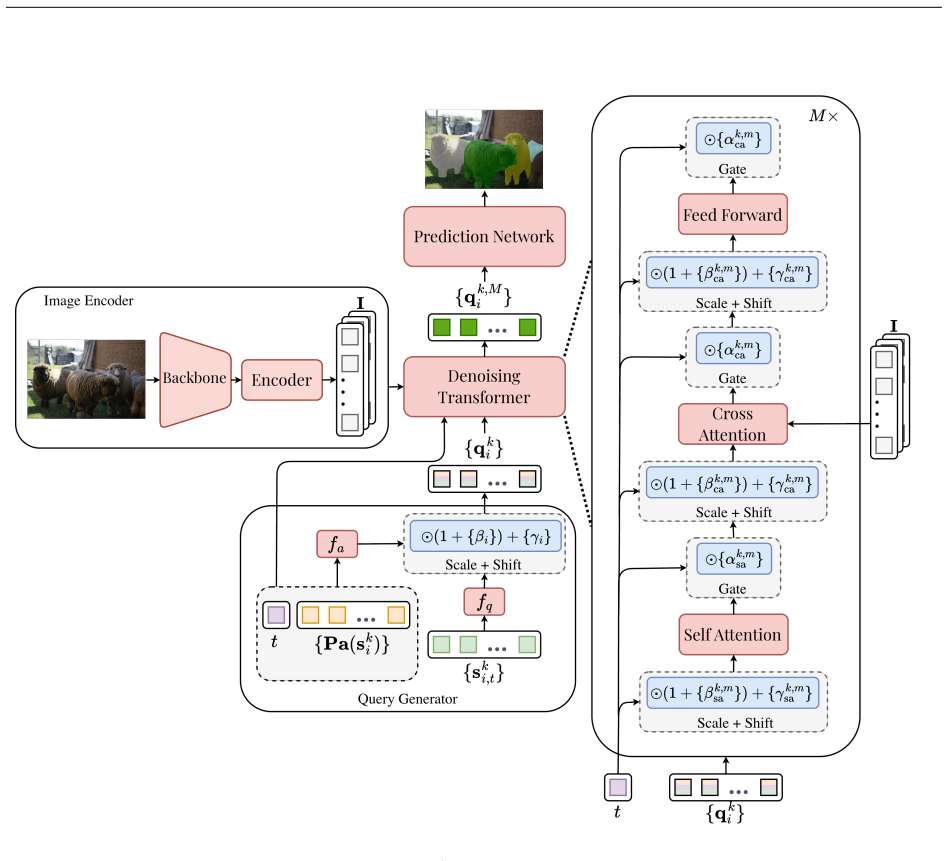
MDMs decompose the diffusion process into distinct, task-specific modules, each focused on capturing a different aspect of the structured information space, such as object categories, spatial locations, and inter-object relationships. This modular design allows each component to be learned independently, with seamless integration at inference without additional training, and enables the diffusion process to operate over heterogeneous output spaces common in structured learning tasks.
What carries the argument
Modular decomposition of the diffusion process into task-specific modules for separate aspects of structured outputs
If this is right
- The same trained modules can be recombined to produce distributions for object detection, instance segmentation, or scene graph generation without task-specific retraining.
- Models can output multimodal predictions that reflect ambiguities such as partial occlusions or boundary uncertainty.
- Heterogeneous outputs (continuous coordinates and discrete categories) are handled inside one diffusion process without custom loss terms or architectures.
- Independent module training reduces the need to optimize a single model over the full joint structured space.
Where Pith is reading between the lines
- The separation of modules could make it easier to diagnose which part of a prediction carries most uncertainty in a given image.
- The framework may transfer to non-vision structured prediction tasks where outputs mix continuous and discrete variables.
- Because modules train separately, the approach might lower the total data needed to model complex joint distributions compared with end-to-end training.
Load-bearing premise
The modular decomposition permits independent learning of components and seamless integration at inference time without additional training even when operating over heterogeneous output spaces such as continuous boxes and discrete labels.
What would settle it
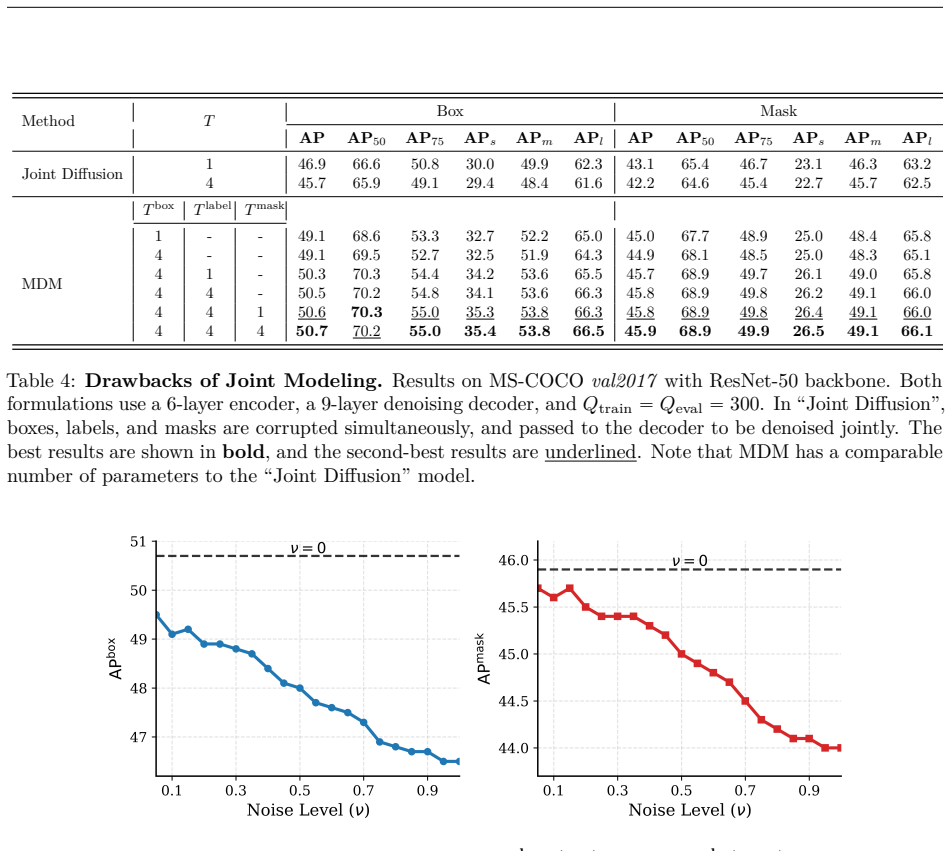
Train separate modules for bounding-box regression and class prediction on identical images, then combine their outputs at inference and check whether the joint distribution matches what a single jointly-trained model would produce; large mismatch would falsify seamless integration.
Figures


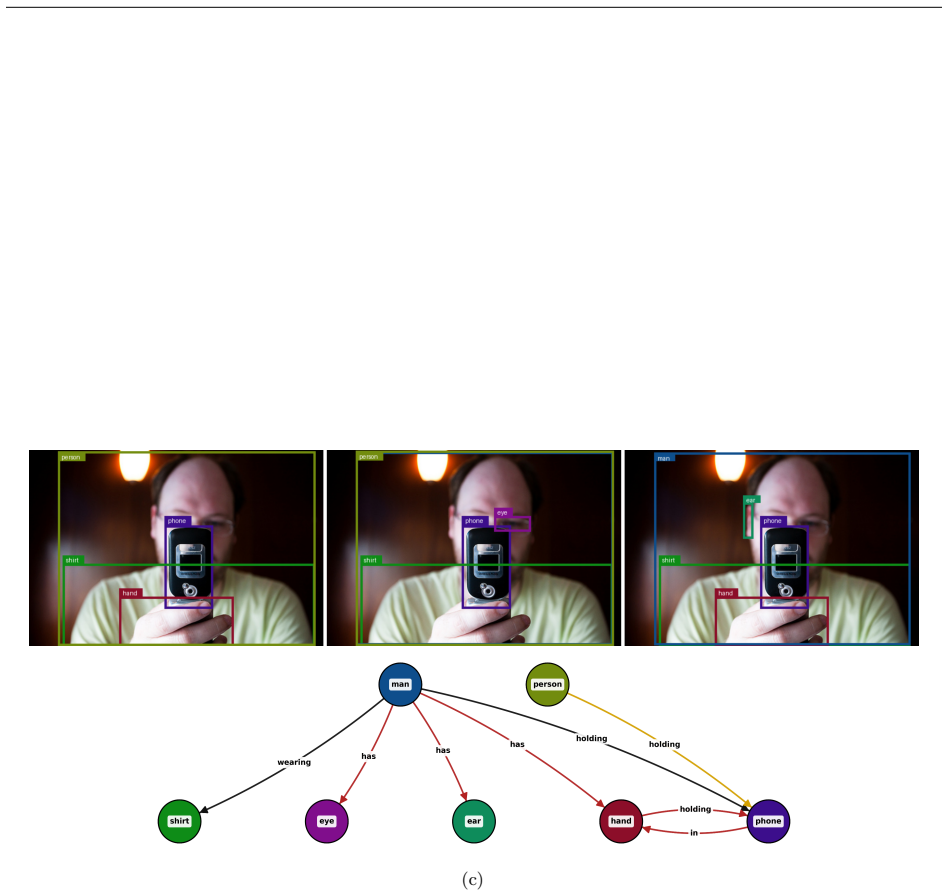
read the original abstract
Traditional supervised methods for structured visual recognition tasks -- such as object detection, segmentation, and scene graph generation -- often produce deterministic, fixed outputs, limiting their ability to capture the inherent uncertainty in complex visual scenes. As a consequence, such point estimates are unable to capture the prediction uncertainty (or multi modality) intrinsic to these problems, often arising from natural ambiguities (e.g., ambiguity in size of partially occluded objects, local ambiguity of exact segmentation boundary, etc.) as well as noise and sparsity of training data. To address this limitation, we present Modular Diffusion Models (MDMs), a simple and novel framework that learns a distribution over structured outputs for a given input image. MDMs decompose the diffusion process into distinct, task-specific modules, each focused on capturing a different aspect of the structured information space, such as object categories, spatial locations, and inter-object relationships. This modular design allows each component to be learned independently, with seamless integration at inference without additional training. Furthermore, the modularity of MDMs enables the diffusion process to easily operate over the heterogeneous output space common in many structured learning tasks (e.g., a continuous bounding boxes and discrete class labels). Experimental results over three distinct structured tasks -- object detection, instance segmentation, and scene graph generation -- highlight the benefits of our proposed framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Modular Diffusion Models (MDMs) for structured visual recognition tasks including object detection, instance segmentation, and scene graph generation. MDMs decompose the diffusion process into independent task-specific modules that each model a distinct aspect of the structured output (object categories, spatial locations, inter-object relationships). The framework claims that modules can be trained separately yet combined seamlessly at inference time without retraining, while naturally handling heterogeneous output spaces such as continuous bounding boxes and discrete class labels, thereby capturing prediction uncertainty and multi-modality.
Significance. If the claimed independent training and consistent joint sampling are shown to hold via an explicit composition mechanism, the approach would offer a modular, extensible way to model distributions over complex structured outputs in vision, moving beyond deterministic point estimates and enabling better handling of ambiguities.
major comments (1)
- [Abstract] Abstract: The central claim that task-specific modules can be learned independently and integrated seamlessly at inference without additional training (especially across heterogeneous continuous/discrete spaces) lacks any stated composition rule, joint reverse-process definition, or compatibility mechanism (e.g., product-of-experts scores, shared latent, or sequential conditioning). This is load-bearing because independent diffusion reverse processes on mismatched variable types are not guaranteed to yield a coherent joint distribution without such a rule.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to explicitly state the composition mechanism in the abstract. The full manuscript details how independent modules are combined, and we will revise the abstract accordingly to address this load-bearing point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that task-specific modules can be learned independently and integrated seamlessly at inference without additional training (especially across heterogeneous continuous/discrete spaces) lacks any stated composition rule, joint reverse-process definition, or compatibility mechanism (e.g., product-of-experts scores, shared latent, or sequential conditioning). This is load-bearing because independent diffusion reverse processes on mismatched variable types are not guaranteed to yield a coherent joint distribution without such a rule.
Authors: We agree the abstract omits an explicit statement of the composition rule. The manuscript body defines the joint reverse process via sequential conditioning: each task-specific module performs its reverse diffusion step conditioned on the partially denoised outputs of prior modules (with continuous variables like boxes using Gaussian transitions and discrete variables like classes using categorical transitions). Compatibility across heterogeneous spaces is ensured by a shared time-step schedule and a product-of-experts combination of the individual score functions at each step. We will revise the abstract to include a concise description of this mechanism (e.g., 'modules are combined at inference via sequential conditioning and product-of-experts score aggregation during the joint reverse process'). This directly addresses the concern about coherent joint distributions. revision: yes
Circularity Check
No significant circularity; framework is a design proposal without self-referential derivations
full rationale
The paper presents MDMs as an architectural framework that decomposes diffusion into task-specific modules for independent training and plug-and-play inference. No equations, fitted parameters, or derivation steps are exhibited in the abstract or described claims that reduce by construction to the inputs (e.g., no self-definitional ratios, no 'prediction' that is a renamed fit, and no load-bearing self-citations or uniqueness theorems). The central claims are forward-looking design assertions rather than a closed mathematical chain, making the work self-contained against external benchmarks with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096,
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096,
-
[2]
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. Hydra-sgg: Hybrid relation assignment for one-stage scene graph generation.arXiv preprint arXiv:2409.10262,
-
[3]
Diffusiondet: Diffusion model for object detection
Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Diffusiondet: Diffusion model for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 19830–19843, 2023a. Tianshui Chen, Weihao Yu, Riquan Chen, and Liang Lin. Knowledge-embedded routing network for scene graph generation. InProceedings of the IEEE/CVF Confere...
-
[4]
Reltr: Relation transformer for scene graph generation
Yuren Cong, Michael Ying Yang, and Bodo Rosenhahn. Reltr: Relation transformer for scene graph generation. arXiv preprint arXiv:2201.11460,
-
[5]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data. arXiv preprint arXiv:2211.15089,
-
[6]
Diffusioninst: Diffusion model for instance segmentation
Zhangxuan Gu, Haoxing Chen, and Zhuoer Xu. Diffusioninst: Diffusion model for instance segmentation. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2730–2734. IEEE,
2024
-
[7]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
-
[8]
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196,
-
[9]
Dab-detr: Dynamic anchor boxes are better queries for detr.arXiv preprint arXiv:2201.12329,
Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. Dab-detr: Dynamic anchor boxes are better queries for detr.arXiv preprint arXiv:2201.12329,
-
[10]
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer.arXiv preprint arXiv:2407.17140,
-
[11]
Long-tail learning via logit adjustment.arXiv preprint arXiv:2007.07314,
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment.arXiv preprint arXiv:2007.07314,
arXiv 2007
-
[12]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241. Springer,
2015
-
[13]
Relationformer: A unified framework for image-to-graph generation.arXiv preprint arXiv:2203.10202,
Suprosanna Shit, Rajat Koner, Bastian Wittmann, Johannes Paetzold, Ivan Ezhov, Hongwei Li, Jiazhen Pan, Sahand Sharifzadeh, Georgios Kaissis, Volker Tresp, et al. Relationformer: A unified framework for image-to-graph generation.arXiv preprint arXiv:2203.10202,
-
[14]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
Pith/arXiv arXiv 2010
-
[15]
Digress: Discrete denoising diffusion for graph generation.arXiv preprint arXiv:2209.14734,
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, Volkan Cevher, and Pascal Frossard. Digress: Discrete denoising diffusion for graph generation.arXiv preprint arXiv:2209.14734,
-
[16]
Mengyu Wang, Henghui Ding, Jun Hao Liew, Jiajun Liu, Yao Zhao, and Yunchao Wei. Segrefiner: Towards model-agnostic segmentation refinement with discrete diffusion process.arXiv preprint arXiv:2312.12425,
-
[17]
Qi Yan, Zhengyang Liang, Yang Song, Renjie Liao, and Lele Wang. Swingnn: Rethinking permutation invariance in diffusion models for graph generation.arXiv preprint arXiv:2307.01646,
-
[18]
Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. Efficient detr: improving end-to-end object detector with dense prior.arXiv preprint arXiv:2104.01318,
-
[19]
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605,
-
[20]
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159,
Pith/arXiv arXiv 2010
-
[21]
32 A Appendix A.1 Transformer Architecture for Scene Graph Generation In Section 5.2 of the main paper we briefly describe that for the task of scene graph generation, we instantiate the MDM framework with a denoising decoder consisting of three components – a subject decoder, an object decoder, and a predicate decoder. In this section we detail how the t...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.