PRISM: Latent Composition Consistency for Single-Image Reflection Removal
Pith reviewed 2026-07-01 05:57 UTC · model grok-4.3
The pith
PRISM reframes single-image reflection removal as linear separation in pretrained VAE latent space, recovering transmission and reflection layers via flow matching with consistency losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
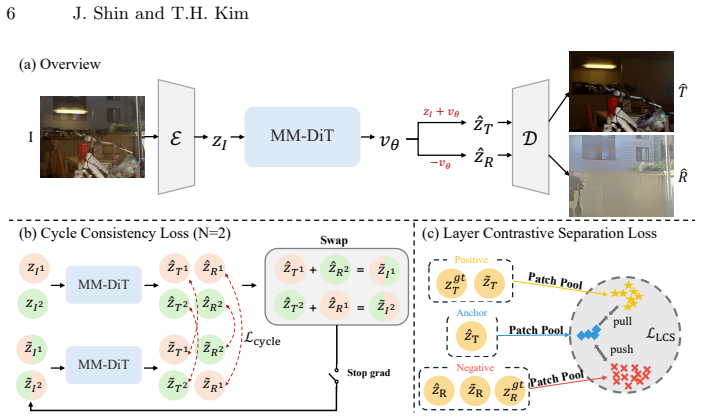
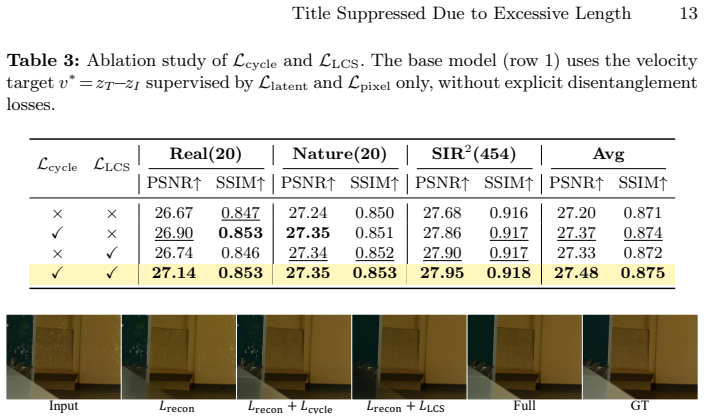
By moving the decomposition into the latent space of a pretrained VAE and treating the mixture as approximately additive, a flow-matching model on a FLUX backbone can jointly recover transmission and reflection layers; the Latent Composition Consistency strategy (swapping reflection latents and applying cycle loss) and Layer Contrastive Separation loss together enforce robust disentanglement without explicit reflection targets.
What carries the argument
Pretrained VAE latent space treated as an approximate additive decomposition domain, with a flow-matching velocity field on FLUX backbone, enforced by Latent Composition Consistency (LCC) via latent swapping and cycle loss plus Layer Contrastive Separation (LCS) via patch-level contrastive learning.
If this is right
- Both transmission and reflection layers are recovered in a single forward pass without separate networks.
- The method requires no explicit reflection targets thanks to the contrastive loss.
- Performance gains hold across six standard benchmarks with improved generalization to uncontrolled images.
- The latent-space formulation avoids the nonlinear entanglement of sRGB pixel formation.
Where Pith is reading between the lines
- The same latent-space additive assumption and consistency losses could transfer to other single-image layer-separation tasks such as shadow removal or intrinsic image decomposition.
- If VAE latents from different backbones show similar layer incoherence, the approach may generalize beyond the FLUX model used here.
- The cycle-consistency mechanism via latent swapping offers a template for self-supervised training in other ill-posed inverse problems where paired data are scarce.
Load-bearing premise
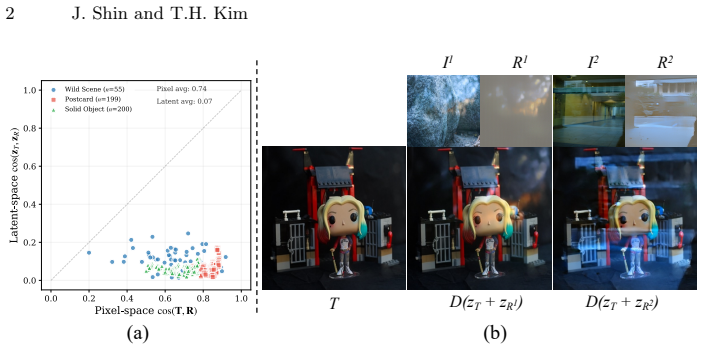
Pretrained VAE latent spaces have substantially lower coherence between transmission and reflection layers than pixel space, so an approximate additive formulation works for decomposition.
What would settle it
A controlled test on the same six benchmarks where PRISM fails to exceed the prior state-of-the-art quantitative scores or shows no improvement on in-the-wild images would falsify the central claim.
Figures



read the original abstract
Single-image reflection removal (SIRR) seeks to recover the transmission layer from a mixture corrupted by reflections -- a severely ill-posed problem. Existing methods operate in pixel space, where the nonlinear sRGB formation model entangles the two layers and limits generalization. We observe that pretrained VAE latent spaces exhibit substantially lower coherence between image layers compared to pixel space, providing a more favorable working space for decomposition. Building on this finding, we propose \textbf{PRISM} (Pretrained-latent Reflection Image Separation Model), which reinterprets SIRR as a latent linear separation problem. Under an approximate additive formulation in latent space, PRISM learns a flow matching velocity field on a pretrained FLUX backbone that recovers both transmission and reflection in a single forward pass. To enforce robust disentanglement, we introduce a Latent Composition Consistency (LCC) strategy that constructs synthetic mixtures by swapping reflection latents across samples and enforces consistent decomposition via a cycle loss. We further propose a Layer Contrastive Separation (LCS) loss that promotes semantic separation between layers through patch-level contrastive learning, without requiring explicit reflection targets. Experiments on six benchmarks demonstrate that PRISM consistently outperforms state-of-the-art methods by significant margins, with strong generalization to in-the-wild images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, which reinterprets single-image reflection removal (SIRR) as latent linear separation under an approximate additive model in the pretrained FLUX VAE latent space. It trains a flow-matching velocity field on the FLUX backbone to recover transmission and reflection layers in one pass, augmented by a Latent Composition Consistency (LCC) cycle loss that swaps reflection latents across synthetic mixtures and a Layer Contrastive Separation (LCS) patch-level contrastive loss. Experiments on six benchmarks are reported to show consistent outperformance of prior SOTA methods with improved in-the-wild generalization.
Significance. If the central premise that pretrained VAE latents exhibit sufficiently low layer coherence to support an approximate additive decomposition holds and is validated, the work could meaningfully shift SIRR methods away from pixel-space nonlinear entanglement toward more favorable latent representations, with potential benefits for generalization. The use of a pretrained generative backbone and the introduction of LCC/LCS losses without explicit reflection targets are notable design choices that merit evaluation.
major comments (3)
- [§3] §3 (Method), around the latent additive formulation: the claim that 'pretrained VAE latent spaces exhibit substantially lower coherence between image layers' and thereby enable an 'approximate additive formulation' is load-bearing for reinterpreting SIRR as latent linear separation, yet the manuscript provides no direct quantification (e.g., mean ||E(I) − E(T) − E(R)||_2 or cosine similarity statistics) comparing additivity error in VAE latent space versus pixel space on the training or benchmark mixtures. Without this measurement the flow-matching objective may be learning a nonlinear correction rather than exploiting linearity, undermining the stated advantage.
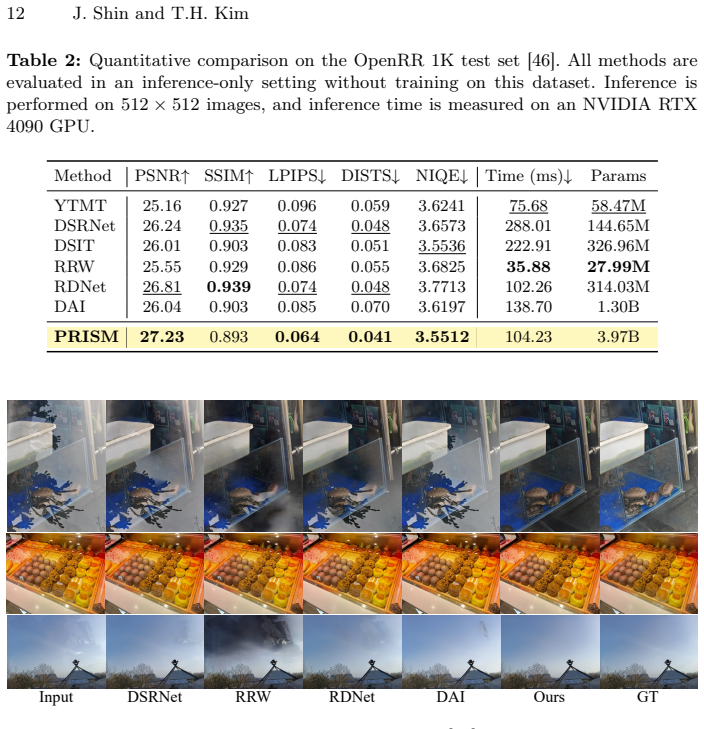
- [§4] §4 (Experiments), Table 1 or equivalent benchmark table: the reported 'significant margins' over SOTA are presented without accompanying error bars, statistical significance tests, or ablation isolating the contribution of the latent-space assumption versus the LCC/LCS losses; if the additivity error is large, these margins could be attributable to the flow-matching architecture alone rather than the claimed latent decomposition.
- [§3.3] §3.3 (LCC strategy): the cycle loss is defined on synthetic mixtures created by swapping reflection latents, but the manuscript does not report the distribution of the resulting additivity residuals or verify that the swapped latents remain within the support of the VAE decoder; large residuals would make the consistency enforcement operate on an unverified premise.
minor comments (2)
- [§3] Notation for the VAE encoder E and the flow-matching velocity field should be introduced with explicit functional forms (e.g., v_θ(z_t, t)) at first use to avoid ambiguity when discussing the approximate linearity.
- [§4] The abstract states 'strong generalization to in-the-wild images' but the corresponding qualitative results section would benefit from a failure-case analysis or quantitative metric on a held-out wild set rather than selected visuals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: [§3] §3 (Method), around the latent additive formulation: the claim that 'pretrained VAE latent spaces exhibit substantially lower coherence between image layers' and thereby enable an 'approximate additive formulation' is load-bearing for reinterpreting SIRR as latent linear separation, yet the manuscript provides no direct quantification (e.g., mean ||E(I) − E(T) − E(R)||_2 or cosine similarity statistics) comparing additivity error in VAE latent space versus pixel space on the training or benchmark mixtures. Without this measurement the flow-matching objective may be learning a nonlinear correction rather than exploiting linearity, undermining the stated advantage.
Authors: We agree that direct quantification of additivity error is important to support the central premise. In the revised manuscript we will add explicit measurements (mean L2 residuals and cosine similarities) comparing additivity error in FLUX VAE latent space versus pixel space on both the synthetic training mixtures and the benchmark data. This will clarify the degree to which the flow-matching objective exploits approximate linearity. revision: yes
-
Referee: [§4] §4 (Experiments), Table 1 or equivalent benchmark table: the reported 'significant margins' over SOTA are presented without accompanying error bars, statistical significance tests, or ablation isolating the contribution of the latent-space assumption versus the LCC/LCS losses; if the additivity error is large, these margins could be attributable to the flow-matching architecture alone rather than the claimed latent decomposition.
Authors: We acknowledge that error bars, statistical tests, and component ablations are needed for rigorous attribution. The revision will include standard deviations across multiple training runs, paired statistical significance tests against prior methods, and an ablation table that isolates the latent-space formulation from the LCC and LCS losses. revision: yes
-
Referee: [§3.3] §3.3 (LCC strategy): the cycle loss is defined on synthetic mixtures created by swapping reflection latents, but the manuscript does not report the distribution of the resulting additivity residuals or verify that the swapped latents remain within the support of the VAE decoder; large residuals would make the consistency enforcement operate on an unverified premise.
Authors: We will add to §3.3 the distribution (mean, std, quantiles) of additivity residuals for the swapped-latent mixtures and will verify decoder support by reporting reconstruction PSNR/SSIM of the swapped latents. These statistics will confirm that the LCC cycle operates on mixtures consistent with the VAE's learned manifold. revision: yes
Circularity Check
No circularity; empirical method with observational modeling choice
full rationale
The paper presents PRISM as a data-driven architecture that reinterprets SIRR via an observational modeling choice (lower layer coherence in pretrained VAE latents) and evaluates it empirically on six benchmarks. No derivation chain, equations, or fitted parameters are shown that reduce any claimed result to its own inputs by construction. The approximate additive formulation is stated as an assumption based on observation rather than derived or self-referential. No self-citations are load-bearing in the provided text. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained VAE latent spaces exhibit substantially lower coherence between image layers compared to pixel space
- domain assumption An approximate additive formulation holds in latent space
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2018)
Blau, Y., Michaeli, T.: The perception-distortion tradeoff. In: CVPR (2018)
2018
-
[2]
IEEE Transactions on Cybernetics (2020)
Chang, Y., Jung, C., Sun, J.: Joint reflection removal and depth estimation from a single image. IEEE Transactions on Cybernetics (2020)
2020
-
[3]
In: ICML (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: ICML (2020)
2020
-
[4]
IEEE TPAMI (2020)
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unifying structure and texture similarity. IEEE TPAMI (2020)
2020
-
[5]
In: ICCV (2021)
Dong, Z., Xu, K., Yang, Y., Bao, H., Xu, W., Lau, R.W.: Location-aware single image reflection removal. In: ICCV (2021)
2021
-
[6]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[7]
IJCV88(2), 303–338 (2010)
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The PAS- CAL visual object classes (VOC) challenge. IJCV88(2), 303–338 (2010)
2010
-
[8]
In: ICCV (2017)
Fan, Q., Yang, J., Hua, G., Chen, B., Wipf, D.: A generic deep architecture for single image reflection removal and image smoothing. In: ICCV (2017)
2017
-
[9]
In: CVPR (2020)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR (2020)
2020
-
[10]
NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
2020
-
[11]
In: AAAI (2026)
Hu, J., Yang, C., Zhou, Z., Fang, J., Yang, X., Tian, Q., Shen, W.: Dereflection any image with diffusion priors and diversified data. In: AAAI (2026)
2026
-
[12]
NeurIPS (2021)
Hu, Q., Guo, X.: Trash or treasure? an interactive dual-stream strategy for single image reflection separation. NeurIPS (2021)
2021
-
[13]
In: CVPR (2023)
Hu, Q., Guo, X.: Single image reflection separation via component synergy. In: CVPR (2023)
2023
-
[14]
NeurIPS (2024)
Hu, Q., Wang, H., Guo, X.: Single image reflection separation via dual-stream interactive transformers. NeurIPS (2024)
2024
-
[15]
In: Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (2023)
Im, E.W., Shin, J., Baik, S., Kim, T.H.: Deep variational bayesian modeling of haze degradation process. In: Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (2023)
2023
-
[16]
In: CVPR (2025)
Kee, E., Pikielny, A., Blackburn-Matzen, K., Levoy, M.: Removing reflections from raw photos. In: CVPR (2025)
2025
-
[17]
In: CVPR (2020)
Kim, S., Huo, Y., Yoon, S.E.: Single image reflection removal with physically-based training images. In: CVPR (2020)
2020
-
[18]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Labs, B.F.: Flux 2 klein 4b.https://blackforestlabs.ai(2025)
2025
-
[20]
In: CVPR (2020)
Li, C., Yang, Y., He, K., Lin, S., Hopcroft, J.E.: Single image reflection removal through cascaded refinement. In: CVPR (2020)
2020
-
[21]
In: CVPR (2014)
Li, Y., Brown, M.S.: Single image layer separation using relative smoothness. In: CVPR (2014)
2014
-
[22]
In: ECCV (2024)
Lin, X., He, J., Chen, Z., Lyu, Z., Dai, B., Yu, F., Qiao, Y., Ouyang, W., Dong, C.: Diffbir: Toward blind image restoration with generative diffusion prior. In: ECCV (2024)
2024
-
[23]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) Title Suppressed Due to Excessive Length 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
In: ICLR (2017)
Loshchilov, I., Hutter, F.: SGDR: Stochastic gradient descent with warm restarts. In: ICLR (2017)
2017
-
[27]
In: ICML (2023)
Luo, Z., Gustafsson, F.K., Zhao, Z., Sjölund, J., Schön, T.B.: Image restoration with mean-reverting stochastic differential equations. In: ICML (2023)
2023
-
[28]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
completely blind
Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE Sign. Process. Letters (2012)
2012
-
[30]
IJCV (1997)
Nayar, S.K., Fang, X.S., Boult, T.: Separation of reflection components using color and polarization. IJCV (1997)
1997
-
[31]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
In: ECCV (2020)
Park, T., Efros, A.A., Zhang, R., Zhu, J.Y.: Contrastive learning for unpaired image-to-image translation. In: ECCV (2020)
2020
-
[33]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[34]
In: CVPR (2015)
Shih,Y.,Krishnan,D.,Durand,F.,Freeman,W.T.:Reflectionremovalusingghost- ing cues. In: CVPR (2015)
2015
-
[35]
In: ICCV (2025)
Shin, J., Chung, S., Yang, Y., Kim, T.H.: Hazeflow: Revisit haze physical model as ode and non-homogeneous haze generation for real-world dehazing. In: ICCV (2025)
2025
-
[36]
In: ICML (2023)
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: ICML (2023)
2023
-
[37]
In: ICCV (2017)
Wan, R., Shi, B., Duan, L.Y., Tan, A.H., Kot, A.C.: Benchmarking single-image reflection removal algorithms. In: ICCV (2017)
2017
-
[38]
IJCV (2021)
Wan, R., Shi, B., Li, H., Duan, L.Y., Kot, A.C.: Face image reflection removal. IJCV (2021)
2021
-
[39]
NeurIPS (2024)
Wang, L., Cheng, K., Lei, S., Wang, S., Yin, W., Lei, C., Long, X., Lu, C.T.: Dc- gaussian: Improving 3d gaussian splatting for reflective dash cam videos. NeurIPS (2024)
2024
-
[40]
IEEE Trans
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process.13(4), 600–612 (2004)
2004
-
[41]
In: CVPR (2019)
Wei, K., Yang, J., Fu, Y., Wipf, D., Huang, H.: Single image reflection removal exploiting misaligned training data and network enhancements. In: CVPR (2019)
2019
-
[42]
Wu, C., Li, J., Zhou, J., Lin, J., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: AAAI (2024)
Wu, G., Jiang, J., Jiang, K., Liu, X.: Learning from history: Task-agnostic model contrastive learning for image restoration. In: AAAI (2024)
2024
-
[44]
In: CVPR (2021)
Wu, H., Qu, Y., Lin, S., Zhou, J., Qiao, R., Zhang, Z., Xie, Y., Ma, L.: Contrastive learning for compact single image dehazing. In: CVPR (2021)
2021
-
[45]
In: ICCV (2023)
Xia, B., Zhang, Y., Wang, S., Wang, Y., Wu, X., Tian, Y., Yang, W., Van Gool, L.: Diffir: Efficient diffusion model for image restoration. In: ICCV (2023)
2023
-
[46]
In: ICIP
Yang, K., Ouyang, L., Sun, H., Cai, J., Fu, L., Ding, J., Ho, C.M., Meng, Z.: Openrr-1k: A scalable dataset for real-world reflection removal. In: ICIP. IEEE (2025) 18 J. Shin and T.H. Kim
2025
-
[47]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[48]
In: CVPR (2018)
Zhang, X., Ng, R., Chen, Q.: Single image reflection separation with perceptual losses. In: CVPR (2018)
2018
-
[49]
In: CVPR (2025)
Zhao, H., Li, M., Hu, Q., Guo, X.: Reversible decoupling network for single image reflection removal. In: CVPR (2025)
2025
-
[50]
In: CVPR (2021)
Zheng, Q., Shi, B., Chen, J., Jiang, X., Duan, L.Y., Kot, A.C.: Single image reflec- tion removal with absorption effect. In: CVPR (2021)
2021
-
[51]
In: CVPR (2024)
Zhu, Y., Zhao, W., Li, A., Tang, Y., Zhou, J., Lu, J.: Flowie: Efficient image enhancement via rectified flow. In: CVPR (2024)
2024
-
[52]
Lpixel only
Zhu, Y., Fu, X., Jiang, P.T., Zhang, H., Sun, Q., Chen, J., Zha, Z.J., Li, B.: Revisiting single image reflection removal in the wild. In: CVPR (2024) Title Suppressed Due to Excessive Length 19 PRISM: Latent Composition Consistency for Single-Image Reflection Removal Supplementary Material Overview This supplementary material provides additional experime...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.