Audio--Image Alignment as a Continued-Pretraining Stage Improves Low-Resource ASR
Pith reviewed 2026-06-25 23:19 UTC · model grok-4.3
The pith
Aligning audio representations with image representations from paired data improves ASR accuracy on low-resource languages after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
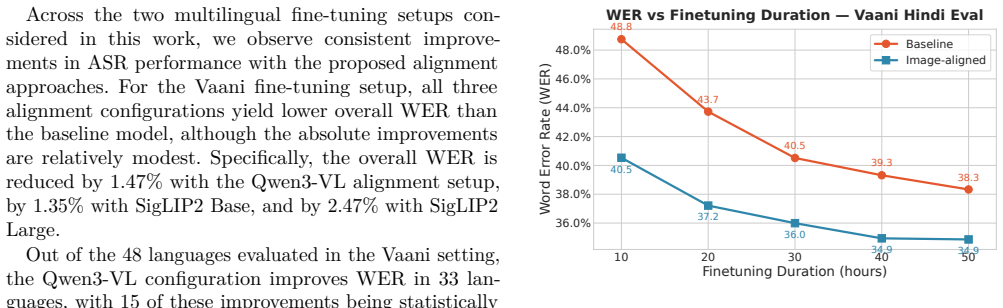
The central claim is that a representation alignment stage using paired audio and image data acts as an effective continued-pretraining step. It adapts a pretrained audio encoder without transcriptions so that subsequent supervised fine-tuning on low-resource language data produces higher ASR accuracy than direct fine-tuning alone.
What carries the argument
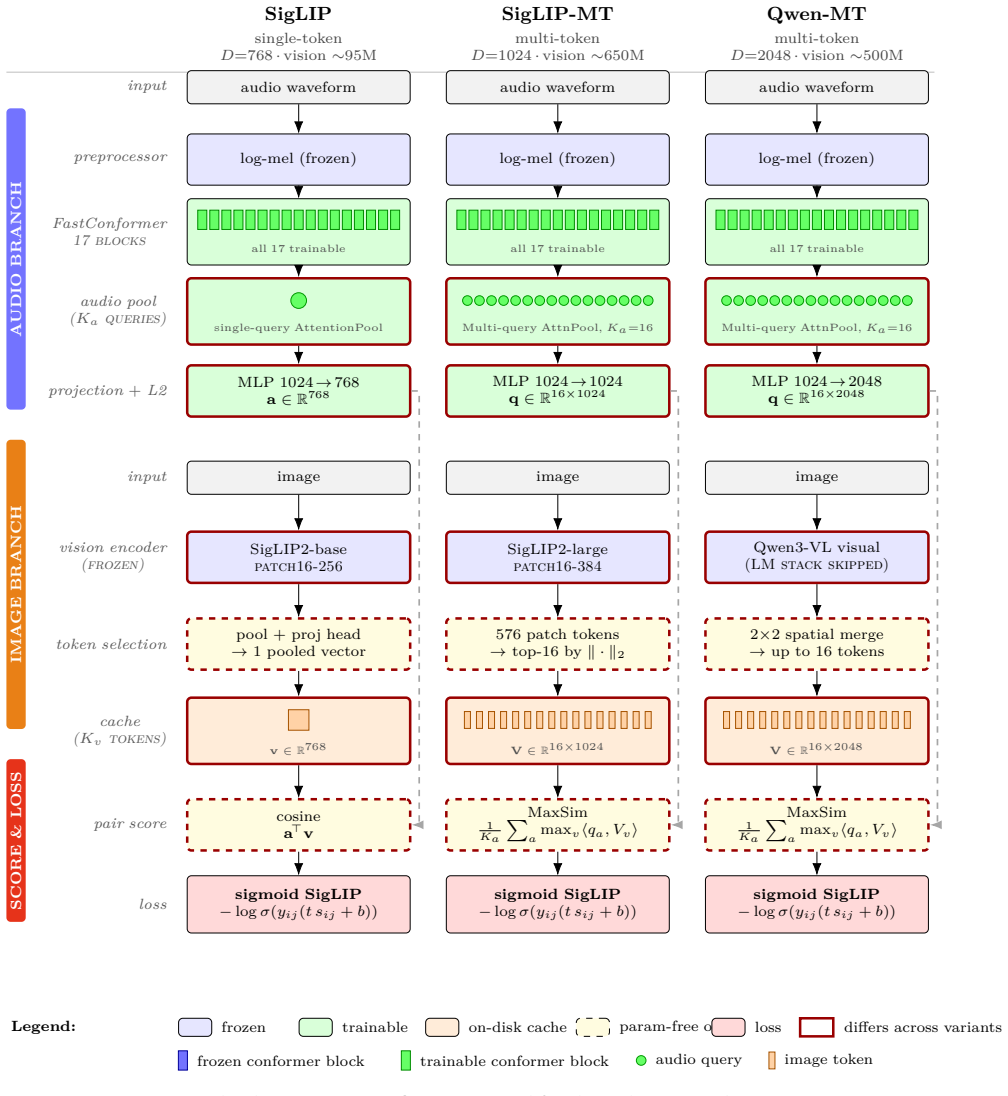
The representation alignment stage, which matches audio representations to image representations extracted from paired audio-image data to adapt the audio encoder before supervised fine-tuning.
If this is right
- Models that receive the alignment stage before fine-tuning achieve improved word error rates on low-resource ASR tasks.
- The gains appear across multiple different vision encoders paired with the same audio encoder.
- The method supplies a transcription-free adaptation route that can be placed between pretraining and supervised fine-tuning.
- Performance improvements remain consistent when the alignment uses naturally collected audio-image pairs.
Where Pith is reading between the lines
- The same alignment idea could be tested with other unpaired modalities if suitable paired data can be collected without labels.
- It may lower the total transcribed speech volume required to reach a target accuracy level.
- One could measure whether the adapted encoder shows better zero-shot transfer to entirely unseen languages.
Load-bearing premise
The alignment of audio and image representations on the paired dataset produces features that transfer to improved ASR accuracy after fine-tuning rather than the gains arising from dataset-specific properties or training schedule differences.
What would settle it
Repeating the fine-tuning experiments with an equivalent amount of extra audio-only training in place of the alignment stage and observing no accuracy difference would show that the image alignment itself is not responsible for the reported gains.
Figures

read the original abstract
Thousands of languages are spoken worldwide, yet many remain under-resourced for Automatic Speech Recognition (ASR) due to the limited availability of high-quality transcribed speech data. Collecting accurate transcriptions is often costly and labor-intensive, particularly for low-resource languages. In this work, we investigate the use of aligned audio-image pairs to adapt pretrained audio encoders without requiring transcription data before supervised fine-tuning. Our proposed representation alignment stage is introduced between large-scale pretraining and supervised ASR fine-tuning. Specifically, image representations extracted from pretrained vision encoders are aligned with audio representations to further adapt a pretrained audio encoder. For this alignment process, we utilize the Vaani dataset, in which images serve as prompts for speech collection, naturally providing paired audio-image data. We evaluate the proposed approach using multiple vision encoders and a pretrained FastConformer audio encoder. Experimental results demonstrate that models fine-tuned after representation alignment consistently achieve improved ASR performance compared to direct fine-tuning. These findings highlight the potential of audio-image representation alignment as an effective transcription-free adaptation strategy for enhancing ASR systems in low-resource language settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inserting an audio-image representation alignment stage (using pretrained vision encoders aligned to a FastConformer audio encoder on the Vaani dataset) between large-scale pretraining and supervised ASR fine-tuning yields consistent improvements in low-resource ASR performance compared to direct fine-tuning, without requiring any transcription data.
Significance. If the central empirical claim holds after proper controls, the work would demonstrate a practical transcription-free continued-pretraining strategy that leverages naturally paired audio-image data for low-resource language adaptation; this could be valuable given the scale of under-resourced languages and the availability of the Vaani collection.
major comments (2)
- [Abstract] Abstract: the central claim rests on the statement that 'models fine-tuned after representation alignment consistently achieve improved ASR performance compared to direct fine-tuning,' yet the provided text supplies no quantitative WER/CER numbers, no statistical significance tests, and no description of data splits or alignment loss implementation, preventing verification of the result.
- [Results / Experimental Setup] Experimental design (as described in the abstract and results): the only reported baseline is direct fine-tuning; no audio-only continued-pretraining control (e.g., masked spectrogram prediction or audio contrastive loss) is performed on the identical Vaani audio. This is load-bearing because any lift could arise from extra gradient steps or dataset exposure rather than the cross-modal alignment itself.
minor comments (2)
- [Abstract] Abstract: the description of how image representations are extracted and aligned (multiple vision encoders, loss formulation) remains high-level; adding a brief equation or pseudocode would clarify the method.
- [Experimental Setup] The manuscript mentions evaluation on multiple vision encoders and a pretrained FastConformer but does not specify which languages or exact Vaani subsets are used; this detail belongs in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and experimental controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim rests on the statement that 'models fine-tuned after representation alignment consistently achieve improved ASR performance compared to direct fine-tuning,' yet the provided text supplies no quantitative WER/CER numbers, no statistical significance tests, and no description of data splits or alignment loss implementation, preventing verification of the result.
Authors: The abstract is intended as a high-level summary; the full quantitative results (WER/CER values, significance tests, data splits) and implementation details (alignment loss, Vaani usage) appear in Sections 3 and 4. To improve verifiability at a glance, we will revise the abstract to include representative WER improvements and a brief description of the alignment procedure and loss. revision: yes
-
Referee: [Results / Experimental Setup] Experimental design (as described in the abstract and results): the only reported baseline is direct fine-tuning; no audio-only continued-pretraining control (e.g., masked spectrogram prediction or audio contrastive loss) is performed on the identical Vaani audio. This is load-bearing because any lift could arise from extra gradient steps or dataset exposure rather than the cross-modal alignment itself.
Authors: This is a valid and important point. An audio-only continued-pretraining control on the same Vaani audio is needed to isolate the benefit of cross-modal alignment from additional gradient steps or data exposure. We will add this baseline (using an audio-only self-supervised objective such as masked spectrogram prediction) in the revised experiments and results. revision: yes
Circularity Check
No circularity: empirical experimental comparison
full rationale
The paper describes an experimental pipeline in which a representation alignment stage on paired audio-image data from Vaani is inserted between large-scale pretraining and supervised ASR fine-tuning. Performance is then measured by comparing fine-tuned ASR word-error rates against a direct-fine-tuning baseline. No equations, fitted parameters, or first-principles derivations appear in the provided text. The central claim is therefore an empirical observation rather than a quantity that reduces to its own inputs by construction. No self-citations are used to import uniqueness theorems, ansatzes, or load-bearing premises. The result is self-contained as a controlled experimental comparison and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baevski, H
A. Baevski, H. Zhou, A. Mohamed, M. Auli. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.NeurIPS, 2020
2020
-
[2]
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, A. Mohamed. HuBERT: Self- Supervised Speech Representation Learning by Masked Prediction of Hidden Units.IEEE/ACM TASLP, 2021
2021
-
[3]
Ivanko, D
D. Ivanko, D. Ryumin, A. Karpov. A Review of Recent Advances on Deep Learning Methods for Audio-Visual Speech Recognition.Mathematics, vol. 11, no. 12, p. 2665, 2023
2023
-
[4]
Gupta, Y
A. Gupta, Y. Miao, L. Neves, and F. Metze. Visual Features for Context-Aware Speech Recognition. InProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017
2017
-
[5]
Chiu et al
C.-C. Chiu et al. Self-supervised Learning with Random- projection Quantizer for Speech Recognition.ICML, 2022
2022
-
[6]
Gulati et al
A. Gulati et al. Conformer: Convolution-augmented Transformer for Speech Recognition.Interspeech, 2020
2020
-
[7]
Rekesh et al
D. Rekesh et al. Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition.ASRU, 2023
2023
-
[8]
Radford et al
A. Radford et al. Learning Transferable Visual Models from Natural Language Supervision.ICML, 2021
2021
-
[9]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[10]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y. Xia, B. Mustafa, et al. SigLIP 2: Multilingual Vision- Language Encoders with Improved Semantic Understand- ing, Localization, and Dense Features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[11]
Khattab, M
O. Khattab, M. Zaharia. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.SIGIR, 2020
2020
-
[12]
Shih, H.-F
Y.-J. Shih, H.-F. Wang, H.-J. Chang, L. Berry, H.-y. Lee, D. Harwath. SpeechCLIP: Integrating Speech with Pre- Trained Vision and Language Model.SLT, 2022
2022
-
[13]
Guzhov, F
A. Guzhov, F. Raue, J. Hees, A. Dengel. AudioCLIP: Extending CLIP to Image, Text and Audio.ICASSP, 2022
2022
-
[14]
Vaani Multilingual In- dic Speech Corpus
ARTPARK-IISc. Vaani Multilingual In- dic Speech Corpus. Hugging Face Hub: ARTPARK-IISc/vaani-transcription-part, 2024
2024
-
[15]
O. Kuchaiev et al. NeMo: A toolkit for building AI applications using Neural Modules.arXiv:1909.09577, 2019
arXiv 1909
-
[16]
A. Graves. Sequence Transduction with Recurrent Neural Networks.ICML Workshop, 2012
2012
-
[17]
Xu et al
H. Xu et al. Efficient Sequence Transduction by Jointly Predicting Tokens and Durations.ICML, 2023
2023
-
[18]
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Ku- mar, S. Sharma, V. Sanka, D. Tewari, H. Dhand, A. Ka- mat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh. VAANI: Capturing the Language Landscape for an Inclusive Digital India.arXiv preprint arXiv:2603.28714, 2026
Pith/arXiv arXiv 2026
-
[19]
Loshchilov, F
I. Loshchilov, F. Hutter. Decoupled Weight Decay Regularization.ICLR, 2019
2019
-
[20]
D. S. Park et al. SpecAugment: A Simple Data Aug- mentation Method for Automatic Speech Recognition. Interspeech, 2019
2019
-
[21]
T. Kudo, J. Richardson. SentencePiece: A simple and lan- guage independent subword tokenizer and detokenizer for Neural Text Processing.EMNLP System Demonstrations, 2018. [22]jiwer : a fast and lightweight word error rate computation library. https://github.com/jitsi/jiwer
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.