SalArt-VQA: Diagnosing Whether VLMs Understand Salient Artifacts in Generated Images
Pith reviewed 2026-06-27 09:37 UTC · model grok-4.3
The pith
High accuracy detecting artifacts in AI-generated images does not mean vision-language models understand those artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
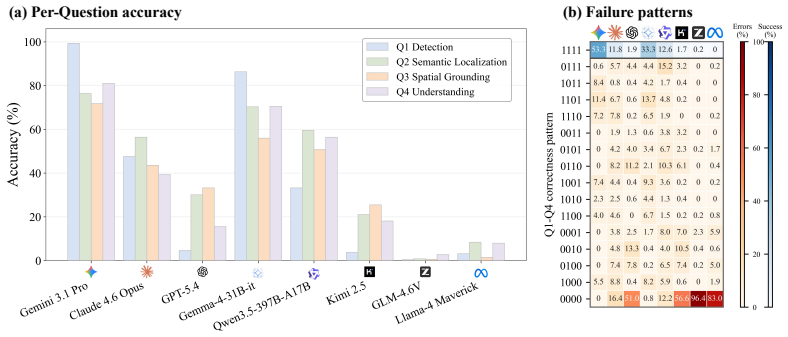
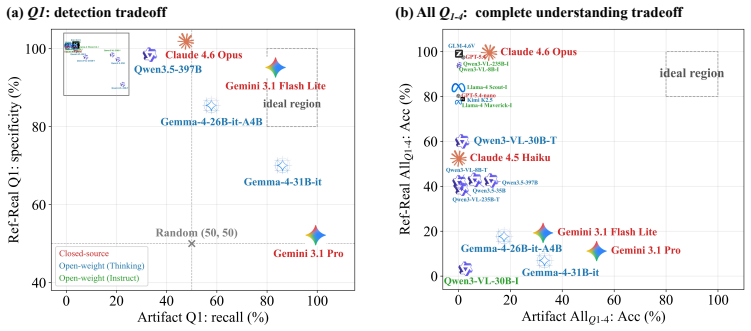
High artifact detection accuracy alone does not imply grounded artifact understanding. The strongest of 20 evaluated VLMs reaches 99.37 percent detection recall on artifact images but answers all four artifact-side questions correctly on only 53.26 percent of those images. Reference comparisons reveal that sensitive models frequently make unsupported artifact claims while conservative models largely avoid false alarms by missing real artifacts.
What carries the argument
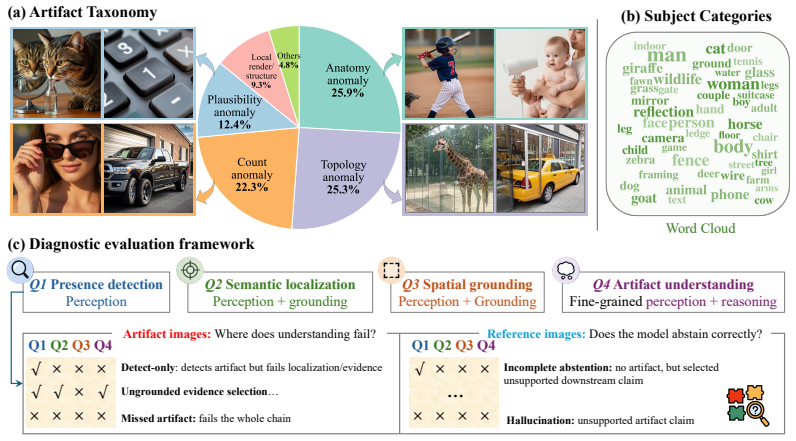
SalArt-VQA benchmark, which supplies human-authored multiple-choice questions across artifact images, matched real references, and paired generated references to test four aligned capabilities: presence detection, semantic localization, spatial grounding, and evidence-grounded defect identification.
Load-bearing premise
The human-authored questions and the three reference image splits correctly isolate presence detection, localization, grounding, and evidence support without being distorted by phrasing or selection biases.
What would settle it
A VLM that maintains greater than 90 percent detection recall while also answering all four artifact questions correctly on more than 70 percent of artifact images would undermine the claim that detection accuracy hides understanding failures.
Figures



read the original abstract
Vision-language models (VLMs) are increasingly used to detect whether AI-generated images contain visible artifacts, yet their ability to analyze such artifacts remains poorly understood. A correct image-level decision can still hide important failures: a model may correctly flag an artifact while relying on the wrong visual cue, selecting the wrong region, or describing a defect that the image does not support. To evaluate these behaviors directly, we introduce SalArt-VQA, a diagnostic benchmark for fine-grained SALient ARTifact understanding in AI-generated images. SalArt-VQA contains 950 images and 3,681 human-authored multiple-choice questions spanning artifact images, matched real reference images, and paired generated reference images. Four aligned question types evaluate presence detection, semantic localization, spatial grounding, and evidence-grounded defect identification, while the reference splits test calibration and abstention when the annotated defect is absent. Across 20 VLMs, SalArt-VQA reveals failures that image-level detection accuracy hides: the strongest model reaches 99.37% detection recall on artifact images but answers all four artifact-side questions correctly on only 53.26% of images. Comparing artifact images with artifact-free references reveals a sensitivity-calibration tradeoff: sensitive models often make unsupported artifact claims, while conservative models avoid false alarms largely by missing real artifacts. These results show that high artifact detection accuracy alone does not imply grounded artifact understanding. SalArt-VQA exposes these hidden failure modes and provides a fine-grained evaluation of whether VLM artifact claims are supported by local visual evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SalArt-VQA, a diagnostic VQA benchmark with 950 images and 3,681 human-authored multiple-choice questions spanning artifact images, matched real references, and paired generated references. Four aligned question types probe presence detection, semantic localization, spatial grounding, and evidence-grounded defect identification. Evaluation across 20 VLMs shows that high image-level detection recall (99.37% for the strongest model) does not translate to high joint accuracy on all four artifact-side questions (53.26%), revealing hidden failure modes and a sensitivity-calibration tradeoff when comparing artifact images to artifact-free references. The central claim is that detection accuracy alone does not imply grounded artifact understanding.
Significance. If the benchmark construction and question design hold up under scrutiny, the work offers a valuable fine-grained evaluation framework for VLM artifact analysis that goes beyond coarse image-level metrics. This is significant for the field because VLMs are increasingly deployed for detecting artifacts in generated images, and the reported gap plus the calibration tradeoff provide concrete evidence of limitations in current models' visual grounding and evidence-based reasoning.
major comments (2)
- [Benchmark construction] Benchmark construction section: The manuscript provides no details on inter-annotator agreement, question validation procedures, or pilot testing for the 3,681 human-authored questions. This is load-bearing because the central claim that the four question types isolate presence detection, semantic localization, spatial grounding, and evidence-grounded identification (without confounding from phrasing or image selection) rests on the assumption that the questions are reliable probes; without agreement metrics or validation, the 53.26% joint accuracy gap cannot be confidently attributed to model failures rather than question artifacts.
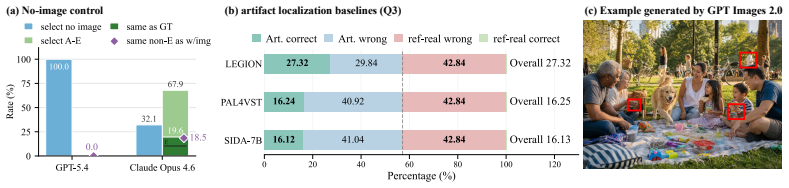
- [Reference splits] Reference splits description: The criteria and verification process for constructing the matched real reference images and paired generated reference images (to ensure they are artifact-free and properly control for abstention/calibration) are not specified. This directly affects the sensitivity-calibration tradeoff analysis, as any mismatch in image selection could confound the comparison between artifact images and references.
minor comments (2)
- [Abstract] Abstract: The total number of evaluated models (20) and the exact definition of 'joint accuracy on all four artifact-side questions' could be stated more explicitly for readers who encounter only the abstract.
- [Results] Table or results section: Clarify whether the 53.26% figure is computed per-image (all four questions correct) or aggregated differently, and report per-question-type accuracies alongside the joint metric.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback. We appreciate the emphasis on transparency in benchmark construction and reference selection, as these details are important for validating our diagnostic claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: The manuscript provides no details on inter-annotator agreement, question validation procedures, or pilot testing for the 3,681 human-authored questions. This is load-bearing because the central claim that the four question types isolate presence detection, semantic localization, spatial grounding, and evidence-grounded identification (without confounding from phrasing or image selection) rests on the assumption that the questions are reliable probes; without agreement metrics or validation, the 53.26% joint accuracy gap cannot be confidently attributed to model failures rather than question artifacts.
Authors: We agree that the absence of inter-annotator agreement metrics and validation procedures is a limitation in the current manuscript. The paper describes the question types and their alignment to the four capabilities but does not report agreement statistics or pilot testing details. In the revised version, we will add a dedicated subsection to Benchmark Construction that includes: the annotation protocol (number of annotators, training), inter-annotator agreement (e.g., Fleiss' kappa on question validity and answer selection), pilot testing results on a held-out subset, and quality filtering steps. This addition will strengthen the attribution of the observed joint accuracy gap to model behavior rather than question artifacts. revision: yes
-
Referee: [Reference splits] Reference splits description: The criteria and verification process for constructing the matched real reference images and paired generated reference images (to ensure they are artifact-free and properly control for abstention/calibration) are not specified. This directly affects the sensitivity-calibration tradeoff analysis, as any mismatch in image selection could confound the comparison between artifact images and references.
Authors: We acknowledge that the manuscript does not specify the selection criteria or verification process for the matched real and paired generated reference images. These references were intended to be artifact-free controls, but the details are missing. In the revision, we will expand the Reference Splits section to describe: the criteria used (e.g., semantic and stylistic matching, manual verification by multiple annotators confirming absence of the targeted artifacts), the verification procedure (independent review rounds), and any quantitative checks (e.g., artifact detection scores on references). This will better support the sensitivity-calibration tradeoff analysis and address potential confounds. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical benchmark (SalArt-VQA) consisting of 950 images and 3,681 human-authored multiple-choice questions across four aligned question types and three reference splits. It reports direct VLM evaluation results (e.g., 99.37% detection recall vs. 53.26% joint accuracy) without any derivations, equations, fitted parameters, or self-citation chains that reduce claims to inputs by construction. The work is self-contained as a diagnostic evaluation against external model outputs and human-authored ground truth; no load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-authored multiple-choice questions and matched reference images accurately measure presence detection, semantic localization, spatial grounding, and evidence-grounded defect identification.
Reference graph
Works this paper leans on
-
[1]
AI: Can AI detect AI-generated images? , author=
AI vs. AI: Can AI detect AI-generated images? , author=. Journal of Imaging , volume=. 2023 , publisher=
2023
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
2024 4th International Conference on Ubiquitous Computing and Intelligent Information Systems (ICUIS) , pages=
A Comparative Review of AI-Generated vs Real Images and Classification Techniques , author=. 2024 4th International Conference on Ubiquitous Computing and Intelligent Information Systems (ICUIS) , pages=. 2024 , organization=
2024
-
[4]
arXiv preprint arXiv:2412.06248 , year=
Rendering-Refined Stable Diffusion for Privacy Compliant Synthetic Data , author=. arXiv preprint arXiv:2412.06248 , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
A bias-free training paradigm for more general ai-generated image detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
arXiv preprint arXiv:2406.19435 , year=
A sanity check for ai-generated image detection , author=. arXiv preprint arXiv:2406.19435 , year=
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Bridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Perceptual artifacts localization for image synthesis tasks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hierarchical fine-grained image forgery detection and localization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Trufor: Leveraging all-round clues for trustworthy image forgery detection and localization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[12]
arXiv preprint arXiv:2411.13842 , year=
Detecting human artifacts from text-to-image models , author=. arXiv preprint arXiv:2411.13842 , year=
-
[13]
arXiv preprint arXiv:2509.19589 , year=
Synthesizing Artifact Dataset for Pixel-level Detection , author=. arXiv preprint arXiv:2509.19589 , year=
-
[14]
arXiv preprint arXiv:2601.19430 , year=
Unveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection , author=. arXiv preprint arXiv:2601.19430 , year=
-
[15]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Characterizing photorealism and artifacts in diffusion model-generated images , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
2025
-
[16]
arXiv preprint arXiv:2410.09732 , year=
Loki: A comprehensive synthetic data detection benchmark using large multimodal models , author=. arXiv preprint arXiv:2410.09732 , year=
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Legion: Learning to ground and explain for synthetic image detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
The Fourteenth International Conference on Learning Representations , year=
FakeXplain: AI-Generated Image Detection via Human-Aligned Grounded Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[20]
arXiv preprint arXiv:2602.09475 , year=
ArtifactLens: Hundreds of Labels Are Enough for Artifact Detection with VLMs , author=. arXiv preprint arXiv:2602.09475 , year=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Grounded language-image pre-training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
European conference on computer vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[23]
URL https://openreview
Gpt4roi: Instruction tuning large language model on region-of-interest, 2024 , author=. URL https://openreview. net/forum , volume=
2024
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Glamm: Pixel grounding large multimodal model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Lmm-det: Make large multimodal models excel in object detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[27]
European Conference on Computer Vision , pages=
Blink: Multimodal large language models can see but not perceive , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[30]
Proceedings of the 3rd Workshop on Advances in Language and Vision Research (ALVR) , pages=
Negative object presence evaluation (nope) to measure object hallucination in vision-language models , author=. Proceedings of the 3rd Workshop on Advances in Language and Vision Research (ALVR) , pages=
-
[31]
Evaluating and Mitigating Object Hallucination in Large Vision-Language Models: Can They Still See Removed Objects? , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[32]
2026 , howpublished =
2026
-
[33]
2025 , howpublished =
2025
-
[34]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[35]
Image and Vision Computing , volume=
Qualitative failures of image generation models and their application in detecting deepfakes , author=. Image and Vision Computing , volume=. 2023 , publisher=
2023
-
[36]
arXiv preprint arXiv:1906.08172 , year=
Mediapipe: A framework for building perception pipelines , author=. arXiv preprint arXiv:1906.08172 , year=
Pith/arXiv arXiv 1906
-
[37]
arXiv preprint arXiv:2408.00714 , year=
Sam 2: Segment anything in images and videos , author=. arXiv preprint arXiv:2408.00714 , year=
-
[38]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[39]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[40]
2026 , howpublished =
Gemma 4 Model Card , author =. 2026 , howpublished =
2026
-
[41]
2026 , month = feb, day =
Gemini 3.1 Pro Model Card , author =. 2026 , month = feb, day =
2026
-
[42]
2026 , month = feb, howpublished =
System Card: Claude Opus 4.6 , author =. 2026 , month = feb, howpublished =
2026
-
[43]
2026 , month = April, howpublished =
System Card: Claude Opus 4.6 , author =. 2026 , month = April, howpublished =
2026
-
[44]
2025 , month = oct, howpublished =
System Card: Claude Haiku 4.5 , author =. 2025 , month = oct, howpublished =
2025
-
[45]
2026 , howpublished =
GPT-5.4 Thinking System Card , author =. 2026 , howpublished =
2026
-
[46]
2025 , eprint=
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2025 , eprint=
2025
-
[47]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[48]
2025 , month = apr, day =
Llama 4 Model Card , author =. 2025 , month = apr, day =
2025
-
[49]
2026 , howpublished =
GPT Image 2 , author =. 2026 , howpublished =
2026
-
[50]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Sida: Social media image deepfake detection, localization and explanation with large multimodal model , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.