GeoDrive-Bench: Benchmarking Region-Specific Multimodal Reasoning in Autonomous Driving
Pith reviewed 2026-06-28 14:43 UTC · model grok-4.3
The pith
Vision-language models for autonomous driving perform inconsistently across regions because they lack robust awareness of local traffic conventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
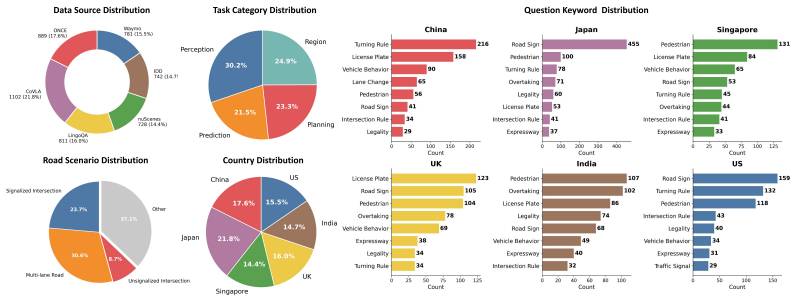
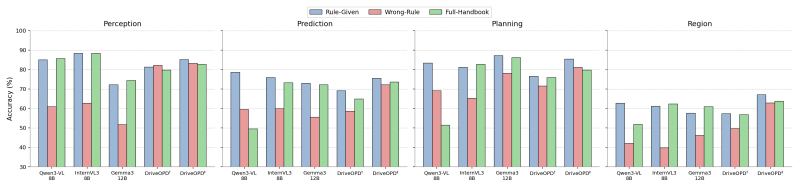
GeoDrive-Bench supplies 5,053 human-validated questions across six countries that each require a model to combine visual evidence with implicit local traffic conventions to select the correct action among perception, prediction, planning, and region-reasoning options; no country label is provided. A distillation algorithm is introduced that injects region-specific traffic-rule knowledge directly into the model's representations. Experiments on nine state-of-the-art VLMs reveal large accuracy gaps between geo-driving cultures on every task, while the authors' baseline models show measurable gains in cross-region performance, indicating that present VLMs do not yet possess reliable region-awar
What carries the argument
GeoDrive-Bench, a curated collection of 5,053 QA pairs that force inference from visual scenes plus unspoken local traffic conventions, paired with a distillation algorithm that embeds region-specific rule knowledge into VLM representations.
If this is right
- Existing VLMs display large performance differences across the six countries on perception, prediction, planning, and region-reasoning tasks.
- The proposed distillation method produces baseline models that improve geo-cultural reasoning uniformly across regions.
- Current VLMs still lack the region-aware intelligence required for safe deployment in varied global driving environments.
- GeoDrive-Bench functions as both a diagnostic test and a training resource for building more deployable autonomous-driving foundation models.
Where Pith is reading between the lines
- If the performance gaps persist, any worldwide rollout of driving VLMs would need systematic region-by-region adaptation rather than a single global model.
- Models might begin to treat subtle visual markers such as sign styles or vehicle types as implicit location signals, which could be measured in follow-up experiments.
- The same curation approach could be applied to other multimodal tasks where unspoken local conventions matter, such as region-specific legal or medical image reasoning.
Load-bearing premise
The benchmark questions can be answered correctly only by combining visual evidence with implicit local traffic conventions rather than by surface-level image features or any explicit country information.
What would settle it
A single VLM that reaches near-ceiling accuracy with no statistically significant difference across all six countries on the full set of 5,053 questions, or a controlled test showing that the same questions can be solved at high accuracy using only generic visual features without any region-specific knowledge.
Figures




read the original abstract
Vision-language models (VLMs) for autonomous driving have shown promising performance, but their ability to handle region-specific traffic rules remains underexplored, raising uncertainties about their deployment across diverse global settings. We therefore introduce GeoDrive-Bench, a novel benchmark that enables the systematic investigation of VLMs' geo-culturally grounded driving reasoning. We curated 5,053 human-validated multiple-choice QA pairs across six countries covering diverse driving cultures. Specifically, we emphasize four driving tasks: perception, prediction, planning, and region reasoning. Each question requires models to infer the correct driving behavior from visual evidence and local traffic conventions without explicit country labels. Beyond evaluation, we further design a distillation algorithm that injects region-specific traffic-rule knowledge into the internal representations of VLMs, enabling models to better align visual scene understanding with local driving policies. Experiments on nine state-of-the-art VLMs show substantial performance variations across geo-driving cultures for each task, while our proposed baseline models exhibit improved geo-cultural reasoning across regions. These results suggest that current VLMs still lack robust region-aware driving intelligence and highlight GeoDrive-Bench as a diagnostic and training-oriented testbed for deployable autonomous driving foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoDrive-Bench, a benchmark of 5,053 human-validated multiple-choice QA pairs spanning six countries and four driving tasks (perception, prediction, planning, region reasoning). Questions are asserted to require joint visual and implicit geo-cultural inference without explicit country labels. The authors additionally propose a distillation algorithm to inject region-specific traffic knowledge into VLMs. Experiments on nine state-of-the-art VLMs report substantial cross-region performance gaps, while the authors' baseline models show improved geo-cultural reasoning; the work concludes that current VLMs lack robust region-aware driving intelligence.
Significance. If the benchmark questions demonstrably require geo-cultural inference beyond surface-level visual or textual cues, the dataset and distillation method would provide a valuable diagnostic and training resource for assessing and improving VLMs in globally deployable autonomous driving systems, where regional traffic conventions vary substantially.
major comments (2)
- [Abstract] Abstract: The central claim that performance variations demonstrate missing region-aware intelligence rests on the premise that the 5,053 QA pairs force inference from visual evidence plus implicit local traffic conventions rather than surface cues (sign text, vehicle models, road markings, language) or inferable labels. The abstract asserts human validation and absence of explicit country labels but supplies no quantitative check (e.g., inter-annotator agreement on cue independence, ablation of region-specific elements, or solvability after masking geo-cues) that would be required to secure this premise; without such evidence the observed gaps could arise from training-data biases or general VLM weaknesses instead.
- [Abstract] Abstract (curation paragraph): No details are provided on the question-construction or validation process (e.g., how annotators were instructed to avoid explicit or inferable country signals, what fraction of questions were rejected during validation, or any pilot study measuring answerability from non-driving features). This information is load-bearing for interpreting the reported cross-country variations as evidence of missing geo-cultural reasoning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger justification of the benchmark's design in the abstract. We address each point below and commit to revisions that improve clarity without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that performance variations demonstrate missing region-aware intelligence rests on the premise that the 5,053 QA pairs force inference from visual evidence plus implicit local traffic conventions rather than surface cues (sign text, vehicle models, road markings, language) or inferable labels. The abstract asserts human validation and absence of explicit country labels but supplies no quantitative check (e.g., inter-annotator agreement on cue independence, ablation of region-specific elements, or solvability after masking geo-cues) that would be required to secure this premise; without such evidence the observed gaps could arise from training-data biases or general VLM weaknesses instead.
Authors: We agree that quantitative checks would further secure the premise. Section 3 of the full manuscript details the human validation protocol, where country-specific annotators were explicitly instructed to create questions requiring local traffic conventions beyond visible cues, and all questions were reviewed for absence of explicit country labels. While we did not conduct the specific ablations or cue-masking experiments suggested, the consistent cross-region gaps across nine diverse VLMs provide supporting evidence. We will revise the abstract to reference these validation steps and add a limitations paragraph discussing potential surface cues. revision: partial
-
Referee: [Abstract] Abstract (curation paragraph): No details are provided on the question-construction or validation process (e.g., how annotators were instructed to avoid explicit or inferable country signals, what fraction of questions were rejected during validation, or any pilot study measuring answerability from non-driving features). This information is load-bearing for interpreting the reported cross-country variations as evidence of missing geo-cultural reasoning.
Authors: The full manuscript (Sections 3.1–3.2) describes the construction process, including annotator instructions to avoid inferable signals, the use of a pilot study to confirm answerability from driving features, and rejection criteria during validation. We will expand the abstract with a concise summary of these elements, including key statistics on the validation process. revision: yes
Circularity Check
No circularity: benchmark curation and empirical evaluation are independent of fitted inputs or self-citation chains
full rationale
The paper presents a new dataset of 5,053 human-validated QA pairs across six countries and reports direct empirical results on nine VLMs plus a proposed distillation baseline. No equations, parameter fits, or derivations appear in the provided text. The central claim (performance variations indicate lack of region-aware intelligence) rests on the benchmark's construction and measured accuracies rather than reducing to any self-defined quantity, fitted subset renamed as prediction, or load-bearing self-citation. Curation is described as external human validation without explicit country labels, and the distillation step is presented as an added contribution rather than a circular justification of the benchmark itself. This is a standard empirical benchmark paper with no detectable circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
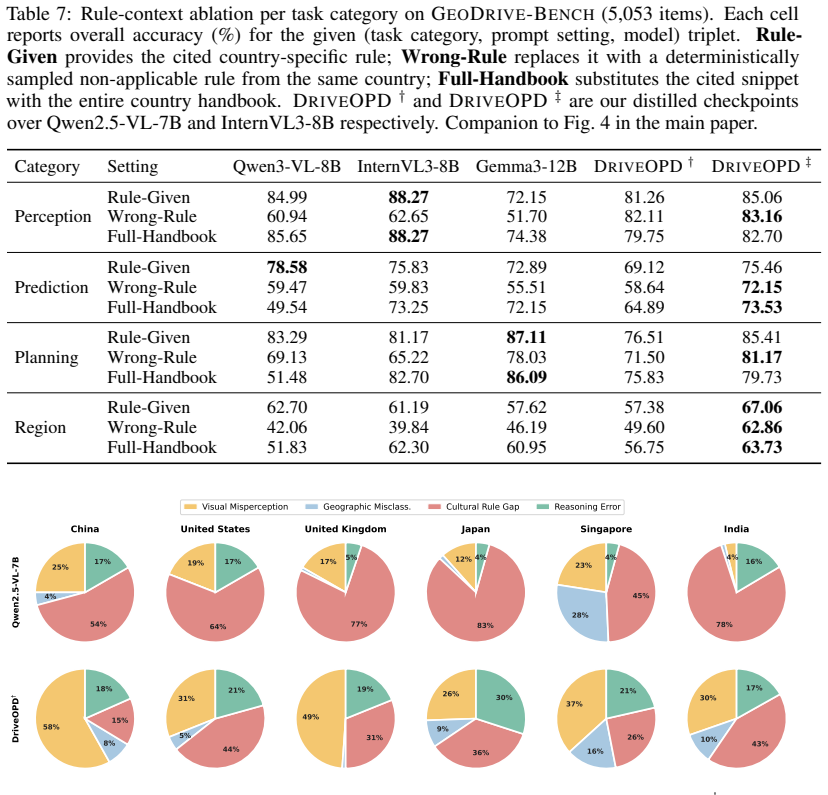
[1]
Claude sonnet 4.6
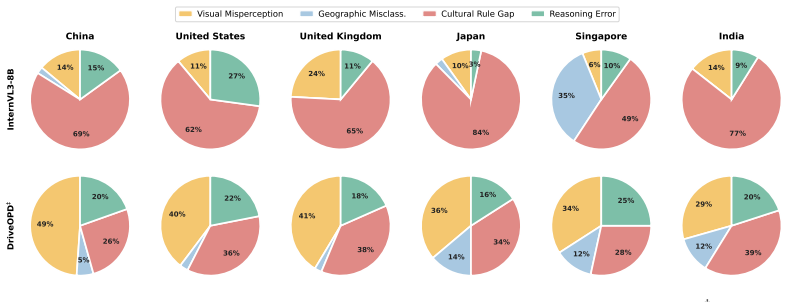
Anthropic. Claude sonnet 4.6. https://www.anthropic.com/claude, 2025. Large language model
2025
-
[2]
Covla: Comprehensive vision-language-action dataset for autonomous driving
Hidehisa Arai, Keita Miwa, Kento Sasaki, Kohei Watanabe, Y u Y amaguchi, Shunsuke Aoki, and Issei Y amamoto. Covla: Comprehensive vision-language-action dataset for autonomous driving. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages 1933–1943. IEEE, 2025
2025
-
[3]
Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, V arun Bankiti, Alex H Lang, Sourabh V ora, V enice Erin Liong, Qiang Xu, Anush Krish- nan, Y u Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 11621–11631, 2020
2020
-
[6]
Automated evaluation of large vision-language models on self-driving corner cases
Kai Chen, Y anze Li, Wenhua Zhang, Y anxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, et al. Automated evaluation of large vision-language models on self-driving corner cases. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages 7817–7826. IEEE, 2025
2025
-
[7]
Impromptu vla: Open weights and open data for driving vision-language- action models
Haohan Chi, Huan-ang Gao, Ziming Liu, Jianing Liu, Chenyu Liu, Jinwei Li, Kaisen Y ang, Y angcheng Y u, Zeda Wang, Wenyi Li, et al. Impromptu vla: Open weights and open data for driving vision-language- action models. arXiv preprint arXiv:2505.23757, 2025
-
[8]
Holistic au- tonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic au- tonomous driving understanding by bird’s-eye-view injected multi-modal large models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13668–13677, 2024
2024
-
[9]
Towards understanding worldwide cross-cultural differences in implicit driving cues: Review, comparative analysis, and research roadmap
Y ongqi Dong, Chang Liu, Yiyun Wang, and Zhe Fu. Towards understanding worldwide cross-cultural differences in implicit driving cues: Review, comparative analysis, and research roadmap. In 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC) , pages 1569–1575. IEEE, 2024
2024
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex V aughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Xianda Guo, Ruijun Zhang, Yiqun Duan, Y uhang He, Dujun Nie, Wenke Huang, Chenming Zhang, Shuai Liu, Hao Zhao, and Long Chen. Surds: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models. arXiv preprint arXiv:2411.13112, 2024
-
[12]
Driveaction: A benchmark for exploring human-like driving decisions in vla models
Y uhan Hao, Zhengning Li, Lei Sun, Weilong Wang, Naixin Yi, Sheng Song, Caihong Qin, Mofan Zhou, Yifei Zhan, and Xianpeng Lang. Driveaction: A benchmark for exploring human-like driving decisions in vla models. arXiv preprint arXiv:2506.05667, 2025
-
[13]
Carscenes: Semantic vlm dataset for safe autonomous driving
Y uankai He and Weisong Shi. Carscenes: Semantic vlm dataset for safe autonomous driving. arXiv preprint arXiv:2511.10701, 2025
-
[14]
Benchmarking neural network robustness to common corruptions and perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. Proceedings of the International Conference on Learning Representations , 2019
2019
-
[15]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Y ang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 17853–17862, 2023
2023
-
[16]
Nuscenes-mqa: Integrated evaluation of captions and qa for autonomous driving datasets using markup annotations
Y uichi Inoue, Y uki Y ada, Kotaro Tanahashi, and Y u Y amaguchi. Nuscenes-mqa: Integrated evaluation of captions and qa for autonomous driving datasets using markup annotations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages 930–938, 2024
2024
-
[17]
Drivelmm-o1: A step-by-step reasoning dataset and large multimodal model for driving scenario understanding
Ayesha Ishaq, Jean Lahoud, Ketan More, Omkar Thawakar, Ritesh Thawkar, Dinura Dissanayake, Noor Ahsan, Y uhao Li, Fahad Shahbaz Khan, Hisham Cholakkal, et al. Drivelmm-o1: A step-by-step reasoning dataset and large multimodal model for driving scenario understanding. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , page...
2025
-
[18]
V ad: V ectorized scene representation for efficient autonomous driv- ing
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. V ad: V ectorized scene representation for efficient autonomous driv- ing. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 8340–8350, 2023
2023
-
[19]
Sdpo: Segment-level direct preference optimization for social agents
Aobo Kong, Wentao Ma, Shiwan Zhao, Y ongbin Li, Y uchuan Wu, Ke Wang, Xiaoqian Liu, Qicheng Li, Y ong Qin, and Fei Huang. Sdpo: Segment-level direct preference optimization for social agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 12409–12423, 2025
2025
-
[20]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Y u, Joseph Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles , pages 611–626, 2023
2023
-
[21]
Driving everywhere with large language model policy adaptation
Boyi Li, Y ue Wang, Jiageng Mao, Boris Ivanovic, Sushant V eer, Karen Leung, and Marco Pavone. Driving everywhere with large language model policy adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14948–14957, 2024
2024
-
[22]
Llava- next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Y uheng Li, Bo Li, Y uanhan Zhang, Sheng Shen, and Y ong Jae Lee. Llava- next: Improved reasoning, ocr, and world knowledge, January 2024. URL https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[23]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Y ang, Qing Jiang, Chunyuan Li, Jianwei Y ang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European conference on computer vision , pages 38–55. Springer, 2024
2024
-
[24]
Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving
Y uechen Luo, Fang Li, Shaoqing Xu, Zhiyi Lai, Lei Y ang, Qimao Chen, Ziang Luo, Zixun Xie, Shengyin Jiang, Jiaxin Liu, et al. Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving. arXiv preprint arXiv:2509.13769, 2025
-
[25]
Dolphins: Multimodal language model for driving
Yingzi Ma, Y ulong Cao, Jiachen Sun, Marco Pavone, and Chaowei Xiao. Dolphins: Multimodal language model for driving. In European Conference on Computer Vision, pages 403–420. Springer, 2024
2024
-
[26]
One million scenes for autonomous driving: Once dataset
Jiageng Mao, Minzhe Niu, Chenhan Jiang, Xiaodan Liang, Y amin Li, Chaoqiang Y e, Wei Zhang, Zhenguo Li, Jie Y u, Chunjing Xu, et al. One million scenes for autonomous driving: Once dataset. 2021
2021
-
[27]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, and Oleg Sinavski. Lingoqa: Visual question answering for autonomous driving. arXiv preprint arXiv:2312.14115, 2023
-
[28]
Xianhui Meng, Y uchen Zhang, Zhijian Huang, Zheng Lu, Ziling Ji, Y aoyao Yin, Hongyuan Zhang, Guangfeng Jiang, Y andan Lin, Long Chen, et al. Is your vlm for autonomous driving safety-ready? a comprehensive benchmark for evaluating external and in-cabin risks. arXiv preprint arXiv:2511.14592 , 2025
-
[29]
NVIDIA, Y an Wang, Wenjie Luo, Junjie Bai, Y ulong Cao, Tong Che, Ke Chen, Y uxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, Liang Feng, Greg Heinrich, Jack Huang, Peter Karkus, Boyi Li, Pinyi Li, Tsung-Yi Lin, Dongran Liu, Ming-Y u Liu, Langechuan Liu, Zhijian Liu, Jason Lu, Y unxiang Mao, Pavlo Molchanov, Lindsey Pavao, Zhenghao Peng, Mike Ranzinger...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Y ang Jiao, and Y u-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4542–4550, 2024
2024
-
[31]
Lmdrive: Closed-loop end-to-end driving with large language models
Hao Shao, Y uxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Y u Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 15120–15130, 2024
2024
-
[32]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning. arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. In European conference on computer vision , pages 256–274. Springer, 2024. 12
2024
-
[34]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Qwen Team. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Nuscenes- spatialqa: A spatial understanding and reasoning benchmark for vision-language models in autonomous driving
Kexin Tian, Jingrui Mao, Y unlong Zhang, Jiwan Jiang, Y ang Zhou, and Zhengzhong Tu. Nuscenes- spatialqa: A spatial understanding and reasoning benchmark for vision-language models in autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 4567– 4576, 2025
2025
-
[37]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Y ang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xian- peng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Idd: A dataset for exploring problems of autonomous navigation in unconstrained environments
Girish V arma, Anbumani Subramanian, Anoop Namboodiri, Manmohan Chandraker, and CV Jawahar. Idd: A dataset for exploring problems of autonomous navigation in unconstrained environments. In 2019 IEEE winter conference on applications of computer vision (WACV) , pages 1743–1751. IEEE, 2019
2019
-
[39]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfac- tual reasoning
Shihao Wang, Zhiding Y u, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfac- tual reasoning. In Proceedings of the computer vision and pattern recognition conference , pages 22442– 22452, 2025
2025
-
[40]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Impact of regional driving behav- ior differences on traffic flow
Y uting Wang, Zhaocheng He, Wangyong Xing, and Chengchuang Lin. Impact of regional driving behav- ior differences on traffic flow. Scientific Reports, 15(1):9027, 2025
2025
-
[42]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives
Shaoyuan Xie, Lingdong Kong, Y uhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 6585–6597, 2025. 13
2025
-
[43]
Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios,
Runsheng Xu, Hubert Lin, Wonseok Jeon, Hao Feng, Y uliang Zou, Liting Sun, John Gorman, Kate Tolstaya, Sarah Tang, Brandyn White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125, 2025
-
[44]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Y ujia Zhang, Enze Xie, Zhen Zhao, Y ong Guo, Kwan-Y ee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters , 9(10):8186–8193, 2024
2024
-
[45]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. arXiv preprint arXiv:2505.17685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Opendrivevla: Towards end- to-end autonomous driving with large vision language action model
Xingcheng Zhou, Xuyuan Han, Feng Y ang, Y unpu Ma, and Alois C Knoll. Opendrivevla: Towards end- to-end autonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463 , 2025
-
[47]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Y un Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforce- ment fine-tuning. arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Y e, Lixin Gu, Hao Tian, Y uchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025. 14 A Overview Our appendix includes the following sections:
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Prompt templates for every evaluation setting and the full training recipe of D RIVE OPD (algorithm, data, hyperparameters, compute)
Section B: Additional Implementation Details. Prompt templates for every evaluation setting and the full training recipe of D RIVE OPD (algorithm, data, hyperparameters, compute)
-
[50]
Full image-perturbation table, per-category rule-context ablation, and error-type analysis on the Qwen2.5-VL family
Section C: Additional Results. Full image-perturbation table, per-category rule-context ablation, and error-type analysis on the Qwen2.5-VL family
-
[51]
The 13 culture-specific traffic categories, the 20-section per-country traffic-rule handbook, the counterfactual verification protocol, and the annotation tool used by human reviewers
Section D: Benchmark Construction Details. The 13 culture-specific traffic categories, the 20-section per-country traffic-rule handbook, the counterfactual verification protocol, and the annotation tool used by human reviewers
-
[52]
Additional qualitative comparisons between base VLMs and DRIVEOPD across countries
Section E: Extended Case Studies. Additional qualitative comparisons between base VLMs and DRIVEOPD across countries
-
[53]
this country
Section F: Broader Impact. Discussion of the broader implications of G EODRIVE - BENCH . B Additional Implementation Details B.1 D RIVE OPD Training Details We instantiate D RIVE OPD on top of two open-source VLM backbones, Qwen2.5-VL-7B [ 4] and InternVL3-8B [ 48], yielding the two checkpoints denoted as D RIVE OPD † and D RIVE OPD ‡ in the main paper. B...
2016
-
[54]
Read s c e n e _ s t a t e to confirm what is ac tu al ly visible
-
[55]
Apply c a n d i d a t e _ r u l e ( NOT o r i g i n _ r u l e ) to the scene
-
[56]
Pick the option that becomes correct under c a n d i d a t e _ r u l e
-
[57]
a n s w e r _ u n d e r _ c a n d i d a t e
Compare against o r i g i n _ g t . Output STRICT JSON , no c o m m e n t a r y : { " a n s w e r _ u n d e r _ c a n d i d a t e " : " A | B | C | D " , " d i f f e r s _ f r o m _ o r i g i n " : true | false , " reason " : " < one - s ent en ce r a t i o n a l e g ro un de d in candidate_rule >" } Dec is io n : a c a n d i d a t e QA pair is R ET AI NE...
-
[58]
Look at the image c a r e f u l l y
-
[59]
Decide whether the pr ov ide d G T _ a n s w e r is s u p p o r t e d by the image under the country - spe ci fi c traffic context
-
[60]
verdict
Output a JSON record with the verdict , your confidence , a one - p a r a g r a p h rationale , and ( for I N C O R R E C T ve rdi ct s ) the option you believe is act ua ll y correct . Inputs : s c e n e _ i m a g e : the c a n d i d a t e driving frame country : the country g o v e r n i n g the rules for this item que st io n : the multiple - choice q ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.