Found in Conversation: LLMs Teach Themselves to Close the Multi-Turn Gap
Pith reviewed 2026-06-30 13:31 UTC · model grok-4.3
The pith
LLMs can teach themselves to recover single-turn performance in multi-turn conversations via self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
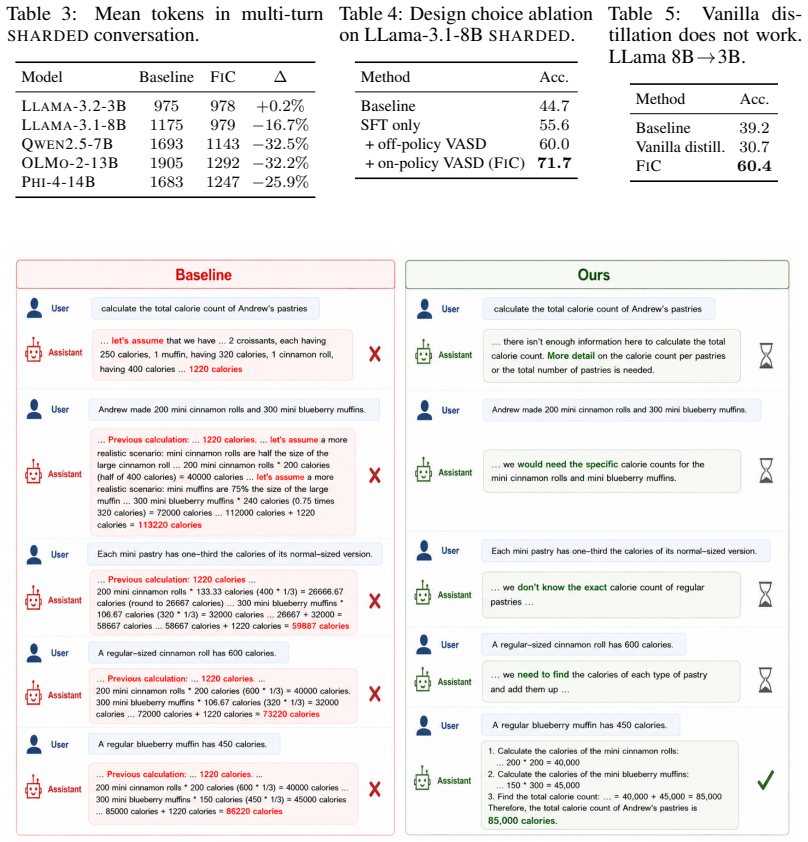
By treating the single-turn view of each task as teacher and the multi-turn view as student, View-Asymmetric Self-Distillation lets a model distill its own strong single-turn responses into improved multi-turn behavior, recovering at least 92 percent of single-turn performance across Llama, Qwen, Phi, and OLMo models sized 3B to 14B and reaching 100 percent on two Llama backbones.
What carries the argument
View-Asymmetric Self-Distillation, which distills from the model's single-turn responses as teacher signal into its multi-turn responses as student.
If this is right
- Multi-turn conversations become more efficient and helpful while single-turn performance stays unchanged.
- No external stronger model is required, since the method relies only on the target model's own single-turn outputs.
- The same recovery holds across four model families and a range of sizes from 3B to 14B parameters.
- Self-generated data can be used directly for this distillation step without external supervision.
Where Pith is reading between the lines
- The approach may reduce reliance on human-written multi-turn training data for conversational agents.
- Similar view-asymmetric distillation could be tested on other underspecified tasks such as long-context reasoning or tool use.
- Iterating the process multiple times might produce further gains or reveal limits of self-generated teacher signals.
Load-bearing premise
The single-turn view supplies an unbiased teacher signal for the multi-turn student without degrading other capabilities or injecting artifacts from self-generated data.
What would settle it
A post-training evaluation showing clear drops on held-out single-turn tasks or measurable increases in hallucination rates traceable to the self-distilled data would falsify the claim that capabilities remain intact.
Figures

read the original abstract
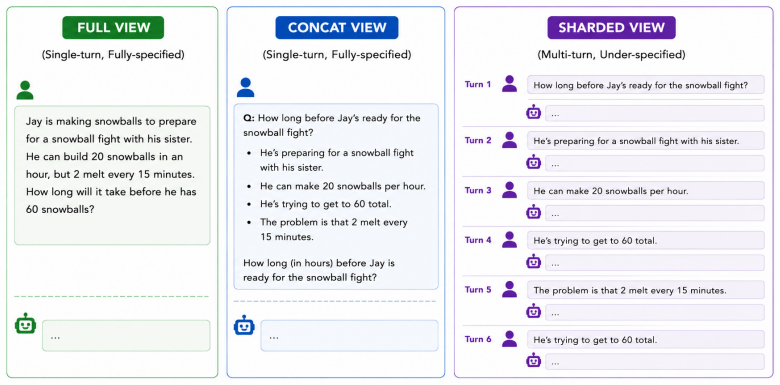
Large Language Model (LLM) interactions are typically underspecified, with users clarifying all necessary details across multiple conversational turns. Yet recent work shows that LLMs perform far worse in this multi-turn setting than in a single turn with same information being available at once, a phenomenon termed "Lost-in-Conversation." However, bridging this gap effectively remains an open problem. Here we introduce Found in Conversation (FiC), a training framework where a model teaches itself to find and recover its single-turn competence given underspecified multi-turn prompts. We develop View-Asymmetric Self-Distillation, which distills across two views of the same task information--single-turn view for the teacher, multi-turn view for the student--transferring strong single-turn behavior into weak multi-turn behavior. This requires no stronger external teacher, which is unavailable as even frontier LLMs exhibit this gap. Across model families (Llama, Qwen, Phi, and OLMo) and sizes (3B-14B), FiC recovers at least 92% of single-turn performance and reaches 100% on two Llama backbones, yielding more efficient and helpful multi-turn conversations with single-turn capabilities intact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Found in Conversation (FiC), a self-distillation training framework called View-Asymmetric Self-Distillation in which an LLM uses its own single-turn view of a task as teacher to improve its multi-turn (underspecified) view as student. The goal is to recover single-turn competence in multi-turn settings without external teachers. Across Llama, Qwen, Phi, and OLMo families (3B–14B), the method is reported to recover ≥92% of single-turn performance and 100% on two Llama backbones.
Significance. If the reported recovery rates are supported by rigorous experiments, the work would be significant for conversational LLM applications: it offers a scalable, self-contained way to mitigate the documented multi-turn performance drop without relying on stronger external models. The view-asymmetric distillation approach is a concrete contribution that could improve efficiency and helpfulness in real multi-turn interactions while preserving other capabilities.
major comments (2)
- Abstract and Methods: the central empirical claim (≥92% recovery, 100% on two Llama backbones) is load-bearing, yet the abstract supplies no information on task definitions, how single-turn vs. multi-turn views are constructed from the same underlying information, number of turns, datasets, or evaluation metrics. Without these details it is impossible to verify that the single-turn teacher signal remains unbiased for the multi-turn student.
- [Results] Results section: the cross-family and cross-size consistency is asserted, but no baselines, variance estimates, number of runs, or ablations on capability drift / other tasks are referenced. This leaves the claim that single-turn capabilities remain intact unsupported and prevents assessment of whether the 92% figure reflects genuine transfer or evaluation artifacts.
minor comments (1)
- The abstract states that FiC yields 'more efficient and helpful multi-turn conversations' but does not define or report separate metrics for efficiency or helpfulness beyond the recovery percentage.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [—] Abstract and Methods: the central empirical claim (≥92% recovery, 100% on two Llama backbones) is load-bearing, yet the abstract supplies no information on task definitions, how single-turn vs. multi-turn views are constructed from the same underlying information, number of turns, datasets, or evaluation metrics. Without these details it is impossible to verify that the single-turn teacher signal remains unbiased for the multi-turn student.
Authors: We agree that the abstract should include sufficient detail for readers to understand the experimental setup and verify the unbiased nature of the teacher signal. In the revised version we will expand the abstract to specify task definitions, how single-turn and multi-turn views are derived from identical underlying information, the number of turns, the datasets, and the evaluation metrics, while ensuring the methods section explicitly describes the view-asymmetric construction that keeps the single-turn teacher unbiased. revision: yes
-
Referee: [Results] Results section: the cross-family and cross-size consistency is asserted, but no baselines, variance estimates, number of runs, or ablations on capability drift / other tasks are referenced. This leaves the claim that single-turn capabilities remain intact unsupported and prevents assessment of whether the 92% figure reflects genuine transfer or evaluation artifacts.
Authors: We acknowledge that the results section would benefit from explicit reporting of these elements to substantiate the claims. The revised manuscript will add relevant baselines, variance estimates, the number of runs, and ablations on capability drift and other tasks to demonstrate that single-turn performance remains intact and that the reported recovery rates reflect genuine transfer rather than artifacts. revision: yes
Circularity Check
No significant circularity; empirical self-distillation framework is self-contained
full rationale
The paper introduces View-Asymmetric Self-Distillation as an empirical training procedure that uses single-turn task views as the teacher signal to improve multi-turn student behavior, with no stronger external model required. Reported outcomes (≥92% recovery of single-turn performance across Llama/Qwen/Phi/OLMo families, 100% on two Llama backbones) are framed as measured experimental results from applying the method rather than quantities algebraically forced by the method's own definitions or fitted parameters. The abstract and described framework contain no equations, no self-citations invoked as load-bearing uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known patterns as new derivations. The central claim therefore rests on the falsifiable empirical hypothesis that the single-turn teacher signal transfers without introducing artifacts, which is tested by the reported recovery rates and does not reduce to a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
URLhttps://openreview.net/forum?id=CrzAj0kZjR. Anthropic. Introducing Claude, 2023. URL https://www.anthropic.com/index/ introducing-claude/. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml.20251026 2023
-
[2]
contain on the order of 100 instructions per task, which limits the resolution of recovery-rate estimates. We mitigate this by averaging n= 10 simulations per instance (amounting to roughly 1,000 scored conversations per model-condition cell) and by reporting consistent trends across five backbones and three out-of-domain tasks, but a larger, more diverse...
2025
-
[3]
let’s assume
Do NOT assume, fabricate, or guess any values not explicitly stated by the user. If a quantity is unknown, state that it is unknown -- never substitute a hypothetical value or use phrases like "let’s assume" or "for example, $200 each"
-
[4]
If any value is still missing, withhold computation and instead state what information is still needed
Do NOT compute a final numerical answer until ALL quantities required for the calculation have been explicitly provided by the user. If any value is still missing, withhold computation and instead state what information is still needed
-
[5]
I still need the following information to solve this: [list]
When information is incomplete, respond with "I still need the following information to solve this: [list]" rather than filling in gaps yourself
-
[6]
Do not hesitate or ask for confirmation -- if the math can be done with the given values, do it
HOWEVER, as soon as you have enough explicitly stated values to perform the calculation, you MUST compute and present the final numerical answer immediately. Do not hesitate or ask for confirmation -- if the math can be done with the given values, do it. PROMPT-SELFCHECK. You are solving a mathematical problem where the user will provide information gradu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.