MAIL++: Multi-Modal Bi-directional Agent Layer for Vision-Language Models
Pith reviewed 2026-06-29 22:37 UTC · model grok-4.3
The pith
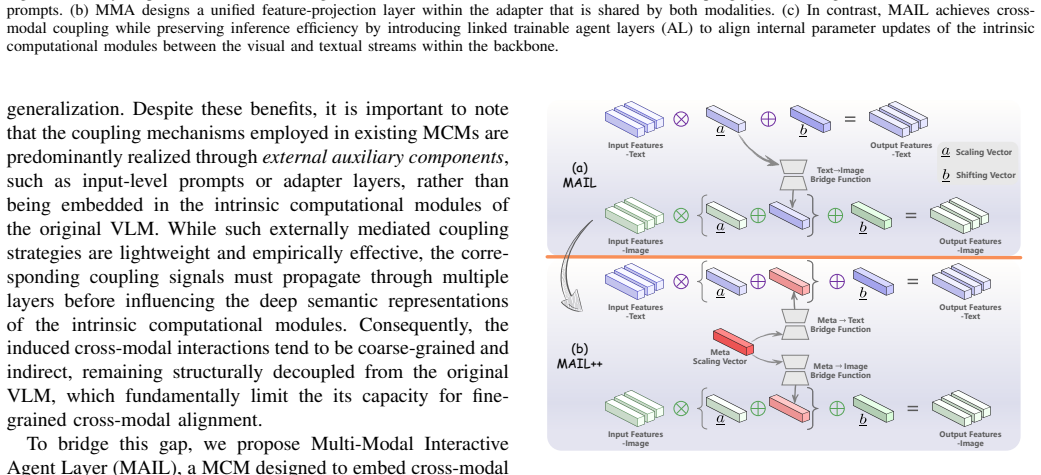
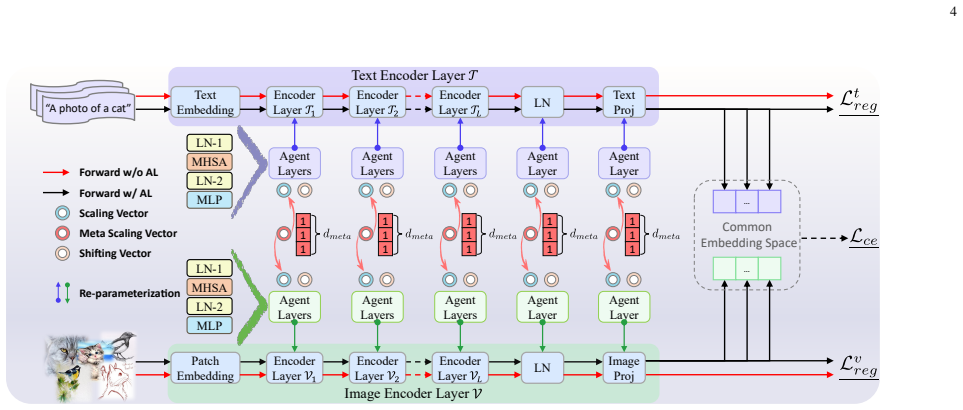
MAIL inserts lightweight agent layers after LayerNorm in vision-language models to directly couple vision and language streams during adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
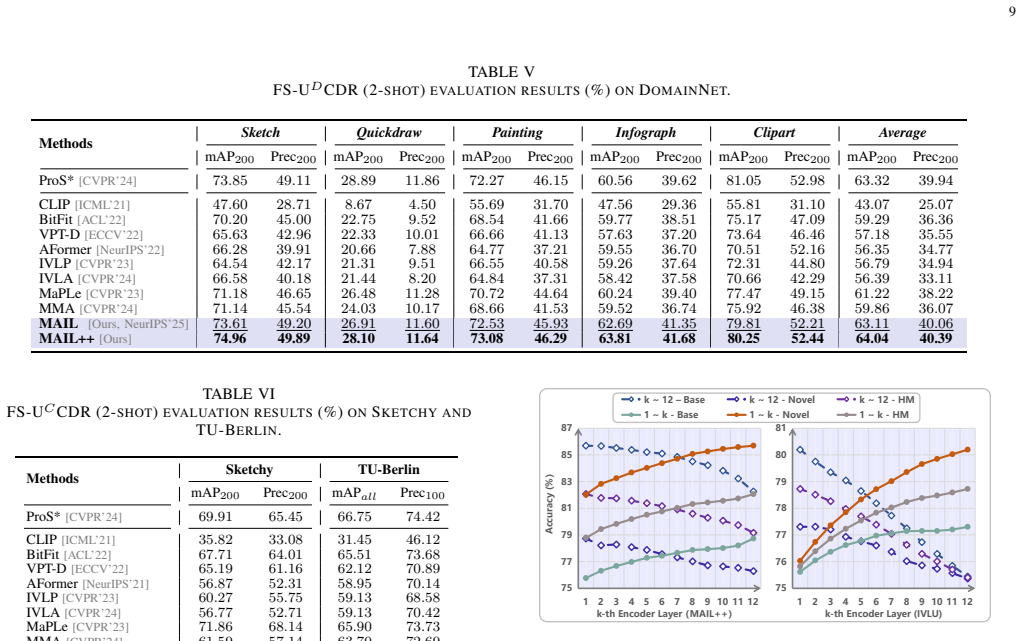
MAIL freezes the VLM backbone and inserts lightweight agent layers after core modules such as LayerNorm; a bottleneck-based text-to-image bridge jointly optimizes the paired layers across modalities to coordinate adaptation. MAIL++ extends the design with a meta agent layer, meta-text bridge, and meta-image bridge for bidirectional exchange. All agent layers re-parameterize into the backbone at inference, keeping original efficiency. The approach yields higher accuracy than existing PEFT methods on few-shot image classification and few-shot universal cross-domain retrieval.
What carries the argument
Multi-Modal Interactive Agent Layer (MAIL) with bottleneck text-to-image bridge and meta bridges that jointly adapt paired vision and language computation modules inside the frozen VLM.
If this is right
- Direct insertion of coupling inside existing modules improves representational expressiveness over external auxiliary modules.
- Re-parameterization at inference restores the original VLM speed and memory footprint.
- Bidirectional meta bridges in MAIL++ further strengthen cross-modal coordination beyond one-way bridges.
- The method remains applicable to any VLM whose forward pass contains modules such as LayerNorm.
Where Pith is reading between the lines
- The same agent-layer pattern could be tested on non-CLIP VLMs or on tasks requiring generation rather than retrieval.
- If the approximation holds, the approach may reduce the need for task-specific prompt engineering in multimodal settings.
- Scaling the meta bridges to deeper layers or larger models would be a direct next measurement.
Load-bearing premise
Lightweight agent layers placed after modules like LayerNorm can structurally stand in for the parameter changes of full fine-tuning and still support effective cross-modal coordination via the bottleneck and meta bridges.
What would settle it
A controlled run on the same few-shot classification and retrieval benchmarks where MAIL or MAIL++ accuracy falls below the best prior PEFT baseline while keeping the same frozen backbone and training budget.
Figures


read the original abstract
Adapting large vision-language models (VLMs) such as CLIP to downstream tasks remains challenging, as full fine-tuning is computationally prohibitive and prone to overfitting in low-data regimes. Parameter-efficient fine-tuning (PEFT) alleviates these issues with lightweight prompt- or adapter-based modules, and cross-modal coupling has proven especially effective by strengthening interactions between vision and language. However, existing coupling mechanisms predominantly rely on external auxiliary modules, leading to indirect, coarse-grained interactions that are structurally decoupled from the original VLM and thus limit representational expressiveness. In this paper, we propose Multi-Modal Interactive Agent Layer (MAIL), a PEFT paradigm that embeds cross-modal coupling directly into the intrinsic computation modules of VLMs. MAIL freezes the backbone and inserts lightweight agent layers after core modules, such as LayerNorm, to approximate the parameter updates induced by full fine-tuning. To couple visual and textual streams at this level, we introduce a bottleneck-based text-to-image bridge that jointly optimizes paired agent layers across modalities, coordinating the adaptation of corresponding computation modules. We further present MAIL++, which enables bidirectional cross-modal exchange through a meta agent layer, a meta-text bridge, and a meta-image bridge. At inference time, all agent layers are re-parameterized into the frozen backbone, preserving the original computational efficiency. Extensive experiments on few-shot image classification and few-shot universal cross-domain retrieval demonstrate that MAIL and MAIL++ consistently outperform state-of-the-art PEFT methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAIL, a parameter-efficient fine-tuning (PEFT) paradigm for vision-language models that freezes the backbone and inserts lightweight agent layers after core modules such as LayerNorm to approximate full fine-tuning parameter updates. Cross-modal coupling is achieved via a bottleneck-based text-to-image bridge that jointly optimizes paired agent layers; MAIL++ extends this with bidirectional exchange using a meta agent layer and meta bridges. All agent layers are re-parameterized into the frozen backbone at inference. The central empirical claim is that MAIL and MAIL++ consistently outperform state-of-the-art PEFT methods on few-shot image classification and few-shot universal cross-domain retrieval.
Significance. If the approximation mechanism is rigorously justified and the reported gains hold under standard controls, the approach would offer a structurally integrated alternative to external auxiliary modules for cross-modal adaptation, potentially improving representational expressiveness in low-data regimes while preserving inference efficiency.
major comments (2)
- [Method (abstract and presumed §3)] The central claim that post-LayerNorm (and similar) agent layers structurally approximate the parameter updates of full fine-tuning lacks any re-parameterization identity, gradient-matching argument, or loss-landscape equivalence. LayerNorm normalizes activations and does not contain the linear weights whose deltas full fine-tuning would produce; the bottleneck and meta bridges are described only as jointly optimizing paired layers for coordination, without a derivation showing functional equivalence.
- [Abstract / Experiments] The abstract asserts that MAIL and MAIL++ "consistently outperform state-of-the-art PEFT methods," yet supplies no quantitative results, tables, datasets, shot counts, or statistical controls. Without these, the superiority claim cannot be evaluated and remains unsupported by the provided text.
minor comments (2)
- [Method] Notation for the bottleneck bridge, meta bridges, and re-parameterization step should be introduced with explicit equations rather than prose descriptions alone.
- [Method] Clarify whether the agent layers are inserted after every LayerNorm or only selected ones, and whether this choice is ablated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and are prepared to revise the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Method (abstract and presumed §3)] The central claim that post-LayerNorm (and similar) agent layers structurally approximate the parameter updates of full fine-tuning lacks any re-parameterization identity, gradient-matching argument, or loss-landscape equivalence. LayerNorm normalizes activations and does not contain the linear weights whose deltas full fine-tuning would produce; the bottleneck and meta bridges are described only as jointly optimizing paired layers for coordination, without a derivation showing functional equivalence.
Authors: We thank the referee for this observation. The manuscript positions the post-LayerNorm agent layers as a structural mechanism to approximate the effects of full fine-tuning updates on the core computation modules, motivated by the typical placement of linear transformations after normalization in VLM architectures. This is presented as a design heuristic supported by empirical performance rather than a formal mathematical identity. We will revise Section 3 to explicitly clarify this distinction, expand the motivation for the placement and bridging mechanism, and emphasize that the approach is validated through downstream task results rather than theoretical equivalence proofs. revision: yes
-
Referee: [Abstract / Experiments] The abstract asserts that MAIL and MAIL++ "consistently outperform state-of-the-art PEFT methods," yet supplies no quantitative results, tables, datasets, shot counts, or statistical controls. Without these, the superiority claim cannot be evaluated and remains unsupported by the provided text.
Authors: We agree that the abstract would benefit from concrete quantitative support for the performance claim. In the revised version we will incorporate key results, including average accuracy gains on few-shot classification (e.g., across ImageNet, CIFAR-100 and other benchmarks at 1/2/4/8/16 shots) and retrieval metrics, along with the primary datasets and comparison baselines referenced in the experiments section. revision: yes
Circularity Check
No derivation chain; empirical PEFT method validated by experiments
full rationale
The paper describes an empirical PEFT architecture (MAIL/MAIL++) that inserts agent layers after modules like LayerNorm and claims they approximate full fine-tuning updates via bottleneck bridges, with re-parameterization at inference. No equations, derivations, or mathematical claims appear in the provided text. The central assertions rest on experimental outperformance rather than any reduction of outputs to inputs by construction, self-citation of uniqueness theorems, or fitted parameters renamed as predictions. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
R. Bommasani, “On the opportunities and risks of foundation models,” arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inProc. Int. Conf. Mach. Learn, 2021, pp. 8748–8763
2021
-
[3]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778
2016
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inProc. Int. Conf. Learn. Representations, 2021
2021
-
[5]
Q. He, “A unified metric architecture for ai infrastructure: A cross-layer taxonomy integrating performance, efficiency, and cost,” arXiv:2511.21772, 2025
-
[6]
Cp-clip: Core- periphery feature alignment clip for zero-shot medical image analysis,
X. Yu, Z. Wu, L. Zhang, J. Zhang, Y . Lyu, and D. Zhu, “Cp-clip: Core- periphery feature alignment clip for zero-shot medical image analysis,” inProc. Int. Conf. Med. Image Comput. Comput.-Assist. Interv., 2024, pp. 88–97
2024
-
[7]
Vpl: Visual proxy learning framework for zero-shot medical image diagnosis,
J. Liu, T. Hu, H. Xiong, J. Du, Y . Feng, J. Wu, J. Zhou, and Z. Liu, “Vpl: Visual proxy learning framework for zero-shot medical image diagnosis,” inFindings of ACL: EMNLP 2024, 2024, pp. 9978–9992
2024
-
[8]
Medclip: Contrastive learning from unpaired medical images and text,
Z. Wang, Z. Wu, D. Agarwal, and J. Sun, “Medclip: Contrastive learning from unpaired medical images and text,” inProc. Conf. Empir. Methods Nat. Lang. Process., vol. 2022, 2022, pp. 3876–3887
2022
-
[9]
Pros: Prompting-to-simulate generalized knowledge for universal cross-domain retrieval,
K. Fang, J. Song, L. Gao, P. Zeng, Z.-Q. Cheng, X. Li, and H. T. Shen, “Pros: Prompting-to-simulate generalized knowledge for universal cross-domain retrieval,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 17 292–17 301
2024
-
[10]
Depro: Domain ensemble using decoupled prompts for universal cross-domain retrieval,
K. Chen, P. Fang, and H. Xue, “Depro: Domain ensemble using decoupled prompts for universal cross-domain retrieval,” inProc. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr., 2025, pp. 958–967
2025
-
[11]
Distill clip (dclip): Enhancing image-text retrieval via cross-modal transformer distillation,
D. Csizmadia, A. Codreanu, V . Sim, V . Prabhu, M. Lu, K. Zhu, S. O’Brien, and V . Sharma, “Distill clip (dclip): Enhancing image-text retrieval via cross-modal transformer distillation,”arXiv:2505.21549, 2025
-
[12]
Building a multi-modal spatiotemporal expert for zero-shot action recognition with clip,
Y . Yu, C. Cao, Y . Zhang, Q. Lv, L. Min, and Y . Zhang, “Building a multi-modal spatiotemporal expert for zero-shot action recognition with clip,” inProc. AAAI Conf. Artif. Intell., vol. 39, no. 9, 2025, pp. 9689– 9697
2025
-
[13]
Leveraging temporal contextu- alization for video action recognition,
M. Kim, D. Han, T. Kim, and B. Han, “Leveraging temporal contextu- alization for video action recognition,” inProc. Eur. Conf. Comput. Vis., 2024, pp. 74–91
2024
-
[14]
Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization,
Z. Weng, X. Yang, A. Li, Z. Wu, and Y .-G. Jiang, “Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization,” inProc. Int. Conf. Mach. Learn, 2023, pp. 36 978– 36 989
2023
-
[16]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”Int. J. Comput. Vis., vol. 130, no. 9, pp. 2337–2348, 2022
2022
-
[17]
Conditional prompt learning for vision-language models,
——, “Conditional prompt learning for vision-language models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 16 816–16 825
2022
-
[18]
Visual-language prompt tuning with knowledge-guided context optimization,
H. Yao, R. Zhang, and C. Xu, “Visual-language prompt tuning with knowledge-guided context optimization,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 6757–6767
2023
-
[19]
Self-regulating prompts: Foundational model adaptation without forgetting,
M. U. Khattak, S. T. Wasim, M. Naseer, S. Khan, M.-H. Yang, and F. S. Khan, “Self-regulating prompts: Foundational model adaptation without forgetting,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 15 190–15 200
2023
-
[20]
Maple: Multi-modal prompt learning,
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, “Maple: Multi-modal prompt learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 19 113–19 122
2023
-
[21]
Mmrl: Multi-modal representation learning for vision-language models,
Y . Guo and X. Gu, “Mmrl: Multi-modal representation learning for vision-language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2025, pp. 25 015–25 025
2025
-
[22]
The Power of Scale for Parameter-Efficient Prompt Tuning
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,”arXiv:2104.08691, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Tip-adapter: Training-free adaption of clip for few-shot classification,
R. Zhang, W. Zhang, R. Fang, P. Gao, K. Li, J. Dai, Y . Qiao, and H. Li, “Tip-adapter: Training-free adaption of clip for few-shot classification,” inProc. Eur. Conf. Comput. Vis., 2022, pp. 493–510
2022
-
[24]
Clip-adapter: Better vision-language models with feature adapters,
P. Gao, S. Geng, R. Zhang, T. Ma, R. Fang, Y . Zhang, H. Li, and Y . Qiao, “Clip-adapter: Better vision-language models with feature adapters,”Int. J. Comput. Vis., vol. 132, no. 2, pp. 581–595, 2024
2024
-
[25]
Mma: Multi-modal adapter for vision-language models,
L. Yang, R.-Y . Zhang, Y . Wang, and X. Xie, “Mma: Multi-modal adapter for vision-language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 23 826–23 837
2024
-
[26]
Scaling & shifting your features: A new baseline for efficient model tuning,
D. Lian, D. Zhou, J. Feng, and X. Wang, “Scaling & shifting your features: A new baseline for efficient model tuning,” inAdv. Neural Inf. Process. Syst., vol. 35, 2022, pp. 109–123
2022
-
[27]
Multi-modal interactive agent layer for few-shot universal cross-domain retrieval and beyond,
K. Chen, P. Fang, and H. Xue, “Multi-modal interactive agent layer for few-shot universal cross-domain retrieval and beyond,” inAdv. Neural Inf. Process. Syst., vol. 38, 2025
2025
-
[28]
Vilt: Vision-and-language transformer without convolution or region supervision,
W. Kim, B. Son, and I. Kim, “Vilt: Vision-and-language transformer without convolution or region supervision,” inProc. Int. Conf. Mach. Learn, 2021, pp. 5583–5594
2021
-
[29]
Align before fuse: Vision and language representation learning with momentum distillation,
J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi, “Align before fuse: Vision and language representation learning with momentum distillation,”Adv. Neural Inf. Process. Syst., vol. 34, pp. 9694–9705, 2021
2021
-
[30]
Vlmo: Unified vision-language pre- 12 training with mixture-of-modality-experts,
H. Bao, W. Wang, L. Dong, Q. Liu, O. K. Mohammed, K. Aggarwal, S. Som, S. Piao, and F. Wei, “Vlmo: Unified vision-language pre- 12 training with mixture-of-modality-experts,”Adv. Neural Inf. Process. Syst., vol. 35, pp. 32 897–32 912, 2022
2022
-
[31]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inProc. Int. Conf. Mach. Learn, 2022, pp. 12 888–12 900
2022
-
[32]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”Adv. Neural Inf. Process. Syst., vol. 36, pp. 34 892–34 916, 2023
2023
-
[33]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inProc. Int. Conf. Mach. Learn, 2019, pp. 2790–2799
2019
-
[34]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inProc. Int. Conf. Learn. Representations, 2022
2022
-
[35]
Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,
E. B. Zaken, Y . Goldberg, and S. Ravfogel, “Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,” in Proc. Annu. Meet. Assoc. Comput. Linguist., 2022, pp. 1–9
2022
-
[36]
Learning with enriched inductive biases for vision-language models,
L. Yang, R.-Y . Zhang, Q. Chen, and X. Xie, “Learning with enriched inductive biases for vision-language models,”Int. J. Comput. Vis., vol. 133, no. 6, pp. 3746–3761, 2025
2025
-
[37]
Not all features matter: Enhancing few-shot CLIP with adaptive prior refinement,
X. Zhu, R. Zhang, B. He, A. Zhou, D. Wang, B. Zhao, and P. Gao, “Not all features matter: Enhancing few-shot CLIP with adaptive prior refinement,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2023, pp. 2605– 2615
2023
-
[38]
Task residual for tuning vision-language models,
T. Yu, Z. Lu, X. Jin, Z. Chen, and X. Wang, “Task residual for tuning vision-language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 10 899–10 909
2023
-
[39]
Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners,
R. Zhang, X. Hu, B. Li, S. Huang, H. Deng, Y . Qiao, P. Gao, and H. Li, “Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 15 211–15 222
2023
-
[40]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdv. Neural Inf. Process. Syst., vol. 30, 2017, pp. 5998–6008
2017
-
[41]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2009, pp. 248–255
2009
-
[42]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,
L. Fei-Fei, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshop, 2004, pp. 178–178
2004
-
[43]
Cats and dogs,
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. Jawahar, “Cats and dogs,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2012, pp. 3498–3505
2012
-
[44]
3d object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representations for fine-grained categorization,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2013, pp. 554–561
2013
-
[45]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” inProc. Indian Conf. Comput. Vis. Graph. Image Process., 2008, pp. 722–729
2008
-
[46]
Food-101–mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” inProc. Eur. Conf. Comput. Vis., 2014, pp. 446–461
2014
-
[47]
Fine-Grained Visual Classification of Aircraft
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine- grained visual classification of aircraft,”arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[48]
Sun database: Large-scale scene recognition from abbey to zoo,
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sun database: Large-scale scene recognition from abbey to zoo,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2010, pp. 3485–3492
2010
-
[49]
A dataset of 101 human action classes from videos in the wild,
K. Soomro, A. R. Zamir, and M. Shah, “A dataset of 101 human action classes from videos in the wild,”Center for Research in Computer Vision, vol. 2, no. 11, pp. 1–7, 2012
2012
-
[50]
Describing textures in the wild,
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2014, pp. 3606–3613
2014
-
[51]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,”IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 12, no. 7, pp. 2217–2226, 2019
2019
-
[52]
Do imagenet classifiers generalize to imagenet?
B. Recht, R. Roelofs, L. Schmidt, and V . Shankar, “Do imagenet classifiers generalize to imagenet?” inProc. Int. Conf. Mach. Learn, 2019, pp. 5389–5400
2019
-
[53]
Learning robust global representations by penalizing local predictive power,
H. Wang, S. Ge, Z. Lipton, and E. P. Xing, “Learning robust global representations by penalizing local predictive power,”Adv. Neural Inf. Process. Syst., vol. 32, pp. 10 506–10 518, 2019
2019
-
[54]
Natural adversarial examples,
D. Hendrycks, K. Zhao, S. Basart, J. Steinhardt, and D. Song, “Natural adversarial examples,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 15 262–15 271
2021
-
[55]
The many faces of robustness: A critical analysis of out-of-distribution generalization,
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Parajuli, M. Guoet al., “The many faces of robustness: A critical analysis of out-of-distribution generalization,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 8340–8349
2021
-
[56]
Moment matching for multi-source domain adaptation,
X. Peng, Q. Bai, X. Xia, Z. Huang, K. Saenko, and B. Wang, “Moment matching for multi-source domain adaptation,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 1406–1415
2019
-
[57]
The sketchy database: learning to retrieve badly drawn bunnies,
P. Sangkloy, N. Burnell, C. Ham, and J. Hays, “The sketchy database: learning to retrieve badly drawn bunnies,”ACM Trans. Graph., vol. 35, no. 4, pp. 1–12, 2016
2016
-
[58]
Deep sketch hashing: Fast free-hand sketch-based image retrieval,
L. Liu, F. Shen, Y . Shen, X. Liu, and L. Shao, “Deep sketch hashing: Fast free-hand sketch-based image retrieval,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2017, pp. 2862–2871
2017
-
[59]
How do humans sketch objects?
M. Eitz, J. Hays, and M. Alexa, “How do humans sketch objects?”ACM Trans. Graph., vol. 31, no. 4, pp. 1–10, 2012
2012
-
[60]
Sketchnet: Sketch classification with web images,
H. Zhang, S. Liu, C. Zhang, W. Ren, R. Wang, and X. Cao, “Sketchnet: Sketch classification with web images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2016, pp. 1105–1113
2016
-
[61]
Tcp: Textual-based class-aware prompt tuning for visual-language model,
H. Yao, R. Zhang, and C. Xu, “Tcp: Textual-based class-aware prompt tuning for visual-language model,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 23 438–23 448
2024
-
[62]
Divergence-enhanced knowledge-guided context optimization for visual-language prompt tun- ing,
Y . Li, M. Cheng, X. Han, and W. Song, “Divergence-enhanced knowledge-guided context optimization for visual-language prompt tun- ing,” inProc. Int. Conf. Learn. Representations, 2025
2025
-
[63]
Bi-modality individual- aware prompt tuning for visual-language model,
H. Yao, R. Zhang, H. Lyu, Y . Zhang, and C. Xu, “Bi-modality individual- aware prompt tuning for visual-language model,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 8, pp. 6352–6368, 2025
2025
-
[64]
Frequency-based comprehensive prompt learning for vision-language models,
L. Liu, N. Wang, C. Chen, D. Liu, X. Yang, X. Gao, and T. Liu, “Frequency-based comprehensive prompt learning for vision-language models,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 12, pp. 11 974–11 989, 2025
2025
-
[65]
Hierarchical cross- modal prompt learning for vision-language models,
H. Zheng, S. Yang, Z. He, J. Yang, and Z. Huang, “Hierarchical cross- modal prompt learning for vision-language models,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2025, pp. 1891–1901
2025
-
[66]
Promptkd: Unsupervised prompt distillation for vision-language mod- els,
Z. Li, X. Li, X. Fu, X. Zhang, W. Wang, S. Chen, and J. Yang, “Promptkd: Unsupervised prompt distillation for vision-language mod- els,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2024, pp. 26 617–26 626
2024
-
[67]
Adapt- former: Adapting vision transformers for scalable visual recognition,
S. Chen, C. Ge, Z. Tong, J. Wang, Y . Song, J. Wang, and P. Luo, “Adapt- former: Adapting vision transformers for scalable visual recognition,” in Adv. Neural Inf. Process. Syst., vol. 35, 2022, pp. 16 664–16 678
2022
-
[68]
Visual prompt tuning,
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inProc. Eur. Conf. Comput. Vis., 2022, pp. 709–727. Kaixiang Chenreceived the BSc degree from Zhejiang University of Technology, Hangzhou, China, in 2021, the MEng degree from the Nanjing University of Aeronautics and Astronautics, Nanjing, China, in ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.