Efficient Test-time Inference for Generative Planning Models with OCL Search
Pith reviewed 2026-06-28 18:51 UTC · model grok-4.3
The pith
A modified Open-Closed List search gives generative planning models an efficient test-time inference procedure by pairing fast rollouts with heuristics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a modified version of classical Open-Closed List search provides an efficient inference procedure that synergizes a generative model performing fast rollouts from intermediate states and a heuristic model prioritizing reasoning paths, with novel exploration control mechanisms, outperforming both neurosymbolic search baselines and classical solvers in computational efficiency and solution quality across multiple combinatorial planning domains.
What carries the argument
Modified Open-Closed List (OCL) search that integrates a generative model for fast rollouts and a heuristic model for path prioritization together with new exploration control mechanisms.
If this is right
- The approach outperforms neurosymbolic search baselines in both computational efficiency and solution quality.
- It achieves higher solution quality than classical solvers across multiple combinatorial domains.
- The method requires no domain-specific tuning or post-hoc adjustments.
- Novel exploration controls enable stable integration of the two learned models inside the OCL framework.
Where Pith is reading between the lines
- Classical search structures can be updated with separate learned rollout and heuristic components to mitigate distribution shift at inference time.
- Similar pairings of generative and evaluative models could be tested in other constrained generation tasks such as program synthesis.
- The relative contribution of the generative versus heuristic component could be measured by ablating one while keeping the OCL skeleton fixed.
Load-bearing premise
The generative model must produce accurate fast rollouts from intermediate states and the heuristic model must reliably prioritize better reasoning paths without post-hoc fixes.
What would settle it
Running the method on a standard planning benchmark where the generative model produces inaccurate rollouts from partial states and finding no improvement over baselines would falsify the central claim.
Figures

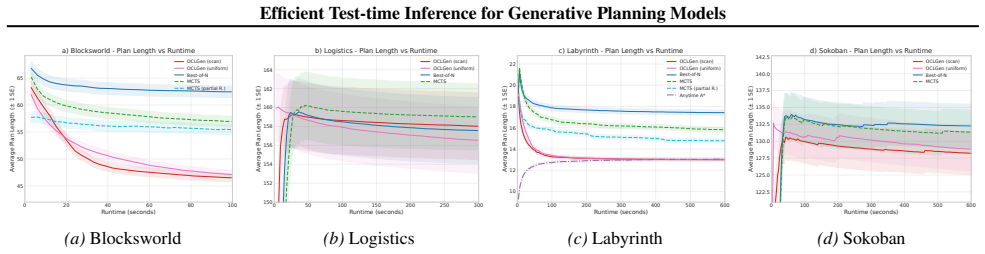
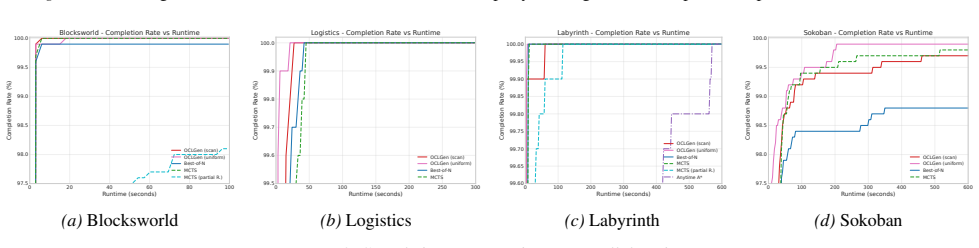

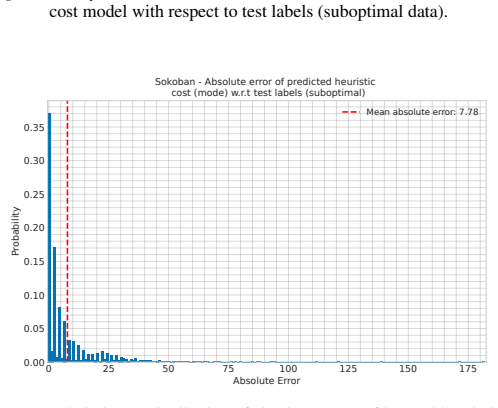
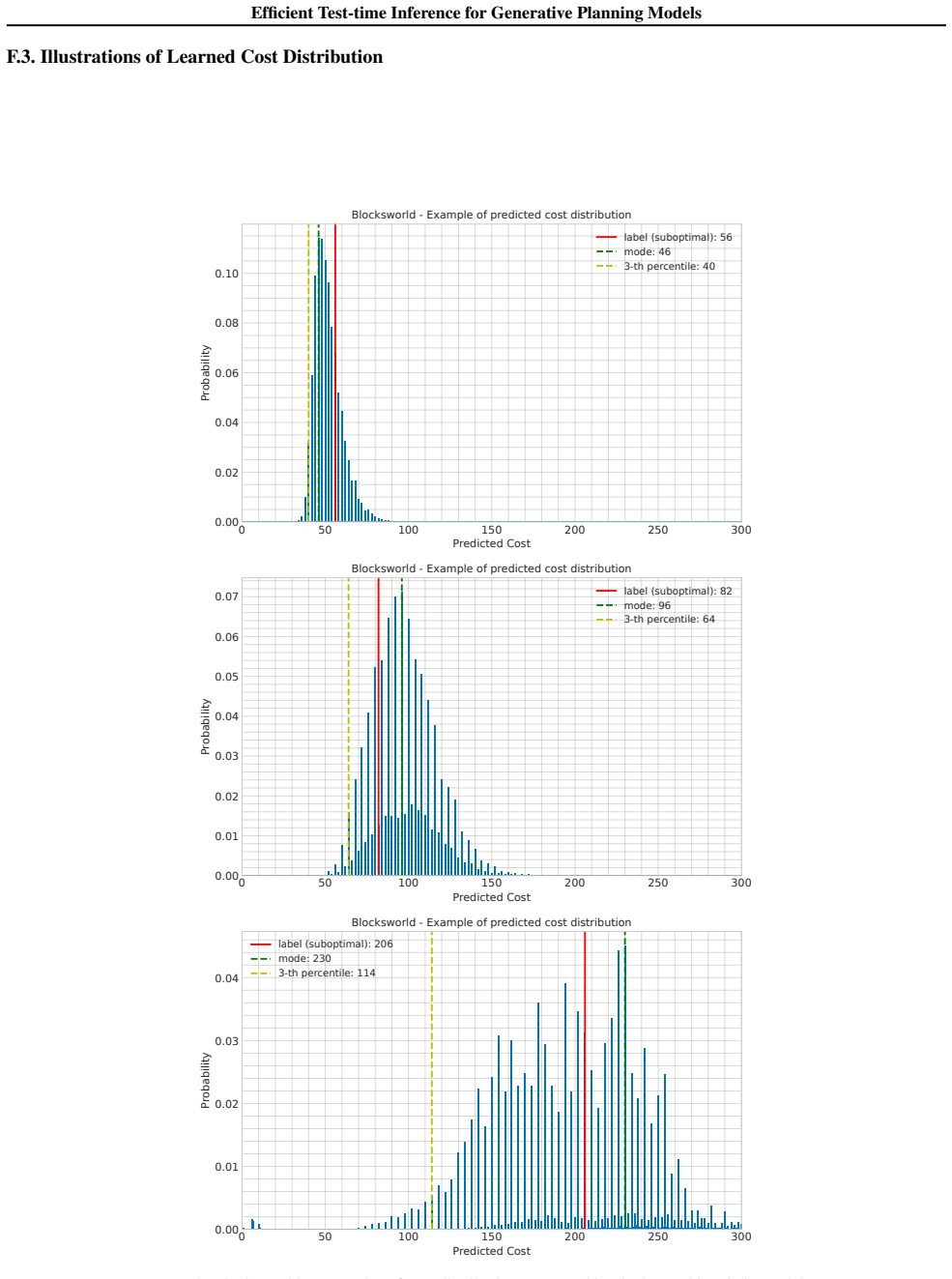
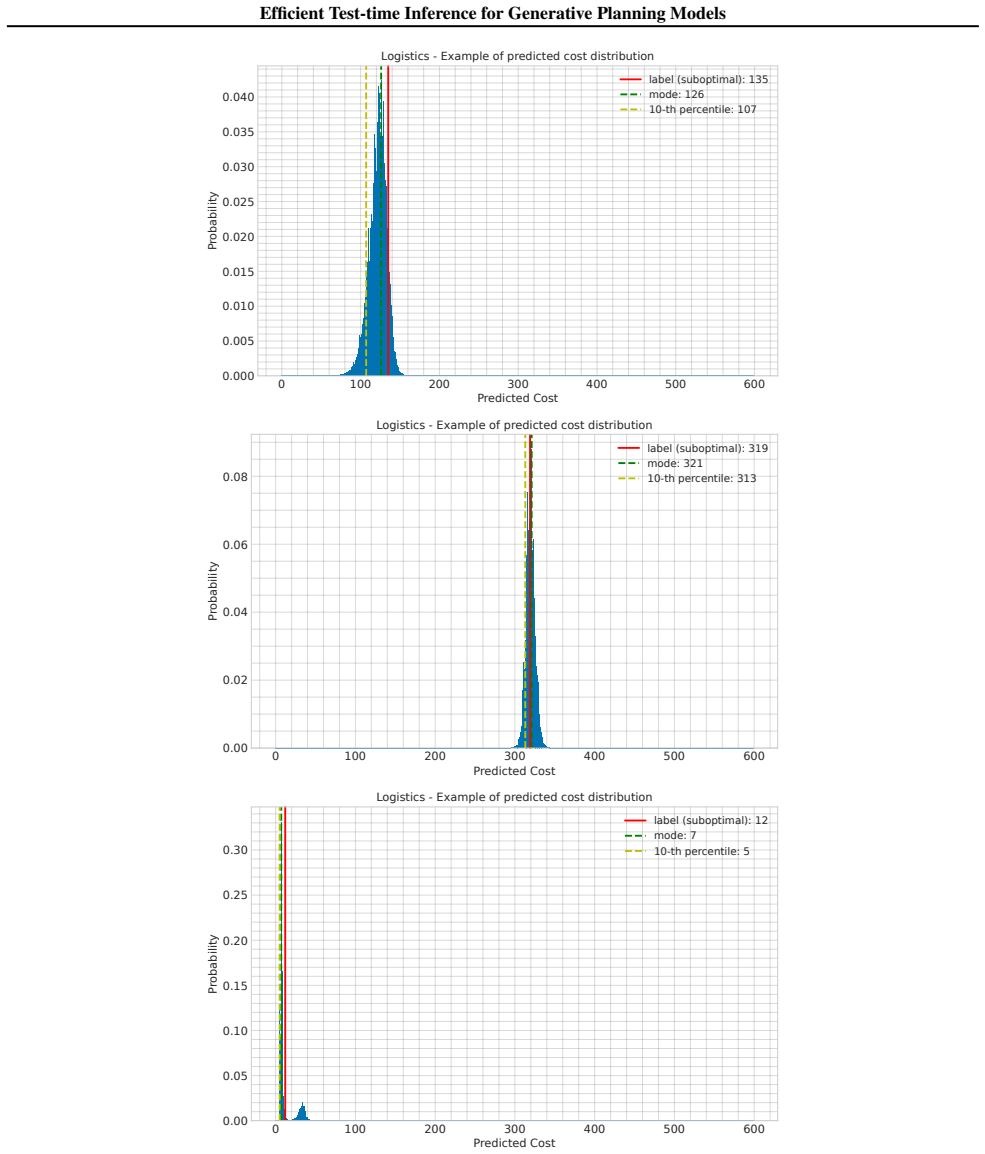
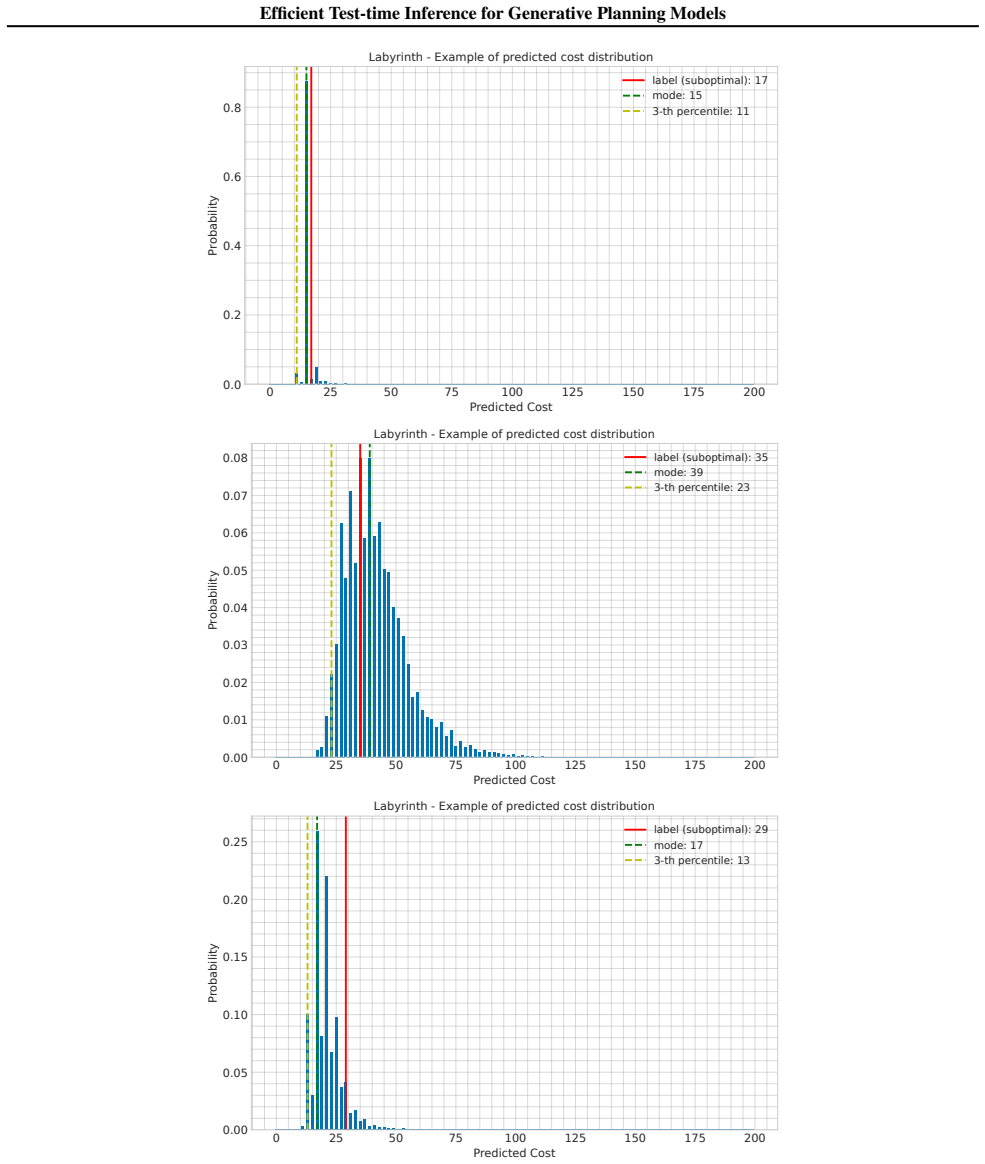

read the original abstract
Generative models have emerged as a powerful paradigm for AI planning, yet their performance remains constrained by the training data distribution. One approach is to improve generated solutions during inference by scaling test-time compute. A more efficient alternative is to optimize the inference process itself. In this paper, we show that a modified version of a classical Open-Closed List (OCL) search provides just such an efficient inference procedure. Our algorithm synergizes two learned components: a generative model that performs fast rollouts from intermediate states and a heuristic model that prioritizes among candidate reasoning paths. Key contributions include novel exploration control mechanisms and integration of learned models within the OCL framework. Across multiple combinatorial planning domains, our approach outperforms both neurosymbolic search baselines and classical solvers in computational efficiency and solution quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a modified version of classical Open-Closed List (OCL) search serves as an efficient test-time inference procedure for generative planning models. It integrates a generative model for fast rollouts from intermediate states with a heuristic model to prioritize reasoning paths, along with novel exploration control mechanisms. The approach is reported to outperform neurosymbolic search baselines and classical solvers in computational efficiency and solution quality across multiple combinatorial planning domains.
Significance. If the empirical claims are substantiated with proper controls and validation, the work would offer a meaningful contribution to test-time optimization in generative planning. It demonstrates how classical search structures can be adapted to synergize with learned generative and heuristic components, providing an alternative to simply scaling inference compute.
major comments (2)
- [Abstract] Abstract: The central claim of outperformance over baselines and classical solvers is presented without any details on experimental setup, error bars, statistical controls, or number of domains/instances, which prevents verification of the reported gains in efficiency and quality.
- [§3 (OCL Integration) or equivalent methods description] The manuscript provides no direct empirical validation that the generative model maintains accurate rollout fidelity when conditioned on intermediate states reached via heuristic-guided exploration rather than complete training trajectories; this assumption is load-bearing for the claimed synergy and efficiency improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to improve clarity and add requested validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of outperformance over baselines and classical solvers is presented without any details on experimental setup, error bars, statistical controls, or number of domains/instances, which prevents verification of the reported gains in efficiency and quality.
Authors: We agree that the abstract lacks sufficient experimental context. In the revised version, we will expand the abstract to report the number of domains and instances evaluated, note the inclusion of error bars, and indicate that statistical controls were applied in the comparisons. Full details remain in the experimental section. revision: yes
-
Referee: [§3 (OCL Integration) or equivalent methods description] The manuscript provides no direct empirical validation that the generative model maintains accurate rollout fidelity when conditioned on intermediate states reached via heuristic-guided exploration rather than complete training trajectories; this assumption is load-bearing for the claimed synergy and efficiency improvements.
Authors: This observation is correct; the manuscript does not include a dedicated empirical check of rollout fidelity specifically on heuristically reached intermediate states. We will add such validation in the revision (e.g., an ablation measuring rollout accuracy or divergence on states generated by the heuristic-guided process versus training trajectories) to directly support the claimed synergy. revision: yes
Circularity Check
No circularity: algorithmic description with no self-referential derivations or fitted predictions
full rationale
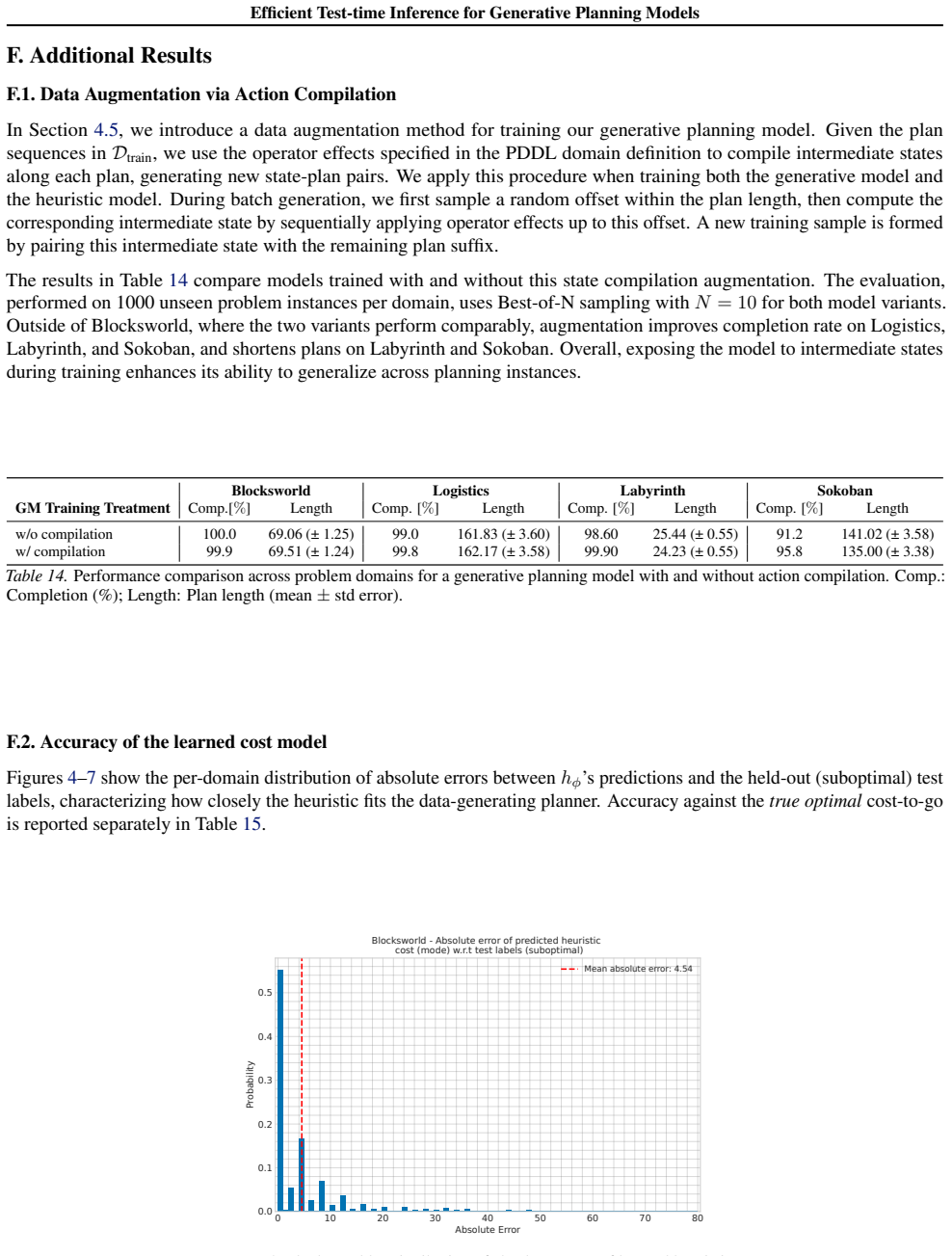
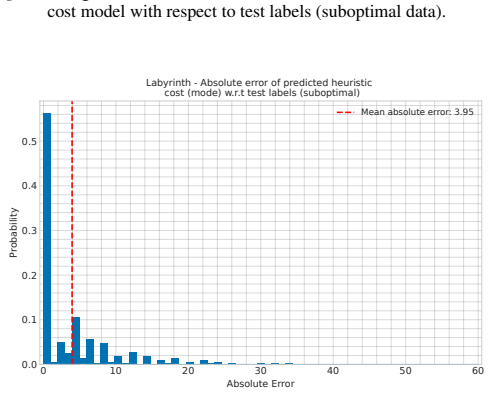
The paper presents a modified OCL search algorithm that integrates a generative model for rollouts and a heuristic model. No equations, derivations, or parameter-fitting steps are described in the provided abstract or claims. The central claim is an empirical performance improvement from the search procedure itself, not a prediction that reduces to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is self-contained as an engineering contribution rather than a mathematical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning general policies for planning through GPT models , author=. Intl. Conf. on Automated Planning and Scheduling , volume=
-
[2]
Complexity results for standard benchmark domains in planning , journal =
Malte Helmert , keywords =. Complexity results for standard benchmark domains in planning , journal =. 2003 , issn =. doi:https://doi.org/10.1016/S0004-3702(02)00364-8 , url =
-
[3]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
AlphaMath Almost Zero: Process Supervision without Process , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[4]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[5]
, author=
Plansformer Tool: Demonstrating Generation of Symbolic Plans Using Transformers. , author=. IJCAI , year=
-
[6]
Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks , author=
-
[7]
Enhancing GPT-based planning policies by model-based plan validation , author=. Intl. Conf. on Neural-Symbolic Learning and Reasoning , year=
-
[8]
Integrating classical planners with gpt-based planning policies , author=. Intl. Conf. of the Italian Association for Artificial Intelligence , pages=. 2024 , organization=
2024
-
[9]
arXiv preprint arXiv:2508.07743 , year=
Symmetry-Aware Transformer Training for Automated Planning , author=. arXiv preprint arXiv:2508.07743 , year=
work page internal anchor Pith review arXiv
-
[10]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Toward self-improvement of llms via imagination, searching, and criticizing , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2402.03610 , year=
Rap: Retrieval-augmented planning with contextual memory for multimodal llm agents , author=. arXiv preprint arXiv:2402.03610 , year=
-
[13]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[14]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking , author=. arXiv preprint arXiv:2501.04519 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The Eleventh International Conference on Learning Representations , year=
Planning with Large Language Models for Code Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency , author=. arXiv preprint arXiv:2304.11477 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning , url =
Guan, Lin and Valmeekam, Karthik and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle =. Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning , url =
-
[18]
PDDL-the planning domain definition language , number=
McDermott, Drew and Ghallab, Malik and Howe, Adele and Knoblock, Craig and Ram, Ashwin and Veloso, Manuela and Weld, Daniel and Wilkins, David , year=. PDDL-the planning domain definition language , number=
-
[19]
Fox, M. and Long, D. , year=. PDDL2.1: An Extension to PDDL for Expressing Temporal Planning Domains , volume=. doi:10.1613/jair.1129 , journal=
-
[20]
Vallati and L
M. Vallati and L. Chrpa and M. Grzes and T. L. McCluskey and M. Roberts and S. Sanner , title =. Artificial Intelligence Magazine (. 2015 , volume=
2015
-
[21]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[22]
, journal =
Sokoban is PSPACE complete. , journal =. 1998 , author =
1998
-
[23]
Blocks World revisited , journal =
John Slaney and Sylvie Thiébaux , keywords =. Blocks World revisited , journal =. 2001 , issn =. doi:https://doi.org/10.1016/S0004-3702(00)00079-5 , url =
-
[24]
The LAMA planner: Guiding cost-based anytime planning with landmarks , journal=
S Richter and M Westphal , volume=. The LAMA planner: Guiding cost-based anytime planning with landmarks , journal=
-
[25]
PDDL Generators
Jendrik Seipp and \'A lvaro Torralba and J \"o rg Hoffmann. PDDL Generators. 2022
2022
-
[26]
Labyrinth PDDL Domain
Rebecca Eifler and Daniel Fišer. Labyrinth PDDL Domain. 2023
2023
-
[27]
The 2023 International Planning Competition , year =
Taitler, Ayal and Alford, Ron and Espasa, Joan and Behnke, Gregor and Fi. The 2023 International Planning Competition , year =. doi:10.1002/aaai.12169 , journal =
-
[28]
Ai Magazine , year=
AIPS 2000 Planning Competition: The Fifth International Conference on Artificial Intelligence Planning and Scheduling Systems , author=. Ai Magazine , year=
2000
-
[29]
Olympiad-level formal mathematical reasoning with reinforcement learning
Olympiad-level formal mathematical reasoning with reinforcement learning , author=. Nature , year=. doi:10.1038/s41586-025-09833-y , url=
-
[30]
The Thirteenth International Conference on Learning Representations , year=
Antonis Antoniades and Albert. The Thirteenth International Conference on Learning Representations , year=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
and Nilsson, Nils J
Hart, Peter E. and Nilsson, Nils J. and Raphael, Bertram , journal=. A Formal Basis for the Heuristic Determination of Minimum Cost Paths , year=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
On the Completeness of Best-First Search Variants That Use Random Exploration , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2016 , month=. doi:10.1609/aaai.v30i1.10081 , abstractNote=
-
[34]
16th IEEE Intl
VAL: Automatic plan validation, continuous effects and mixed initiative planning using PDDL , author=. 16th IEEE Intl. Conf. on Tools with Artificial Intelligence , pages=. 2004 , organization=
2004
-
[35]
Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search
Coulom, R \'e mi. Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. Computers and Games. 2007
2007
-
[36]
Rosin, Christopher D. , title =. Annals of Mathematics and Artificial Intelligence , month = mar, pages =. 2011 , issue_date =. doi:10.1007/s10472-011-9258-6 , abstract =
-
[37]
Samuel, A. L. , journal=. Some Studies in Machine Learning Using the Game of Checkers , year=
-
[38]
Learning heuristic functions for large state spaces , journal =
Shahab. Learning heuristic functions for large state spaces , journal =. 2011 , issn =. doi:https://doi.org/10.1016/j.artint.2011.08.001 , url =
-
[39]
Nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. Nature , volume=. 2016 , publisher=
2016
-
[40]
arXiv preprint arXiv:2402.14083 , year=
Beyond a*: Better planning with transformers via search dynamics bootstrapping , author=. arXiv preprint arXiv:2402.14083 , year=
-
[41]
Advances in neural information processing systems , volume=
Thinking fast and slow with deep learning and tree search , author=. Advances in neural information processing systems , volume=
-
[42]
Learning generalized reactive policies using deep neural networks , author=. Intl. Conf. on Automated Planning and Scheduling , volume=
-
[43]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Mastering chess and shogi by self-play with a general reinforcement learning algorithm , author=. arXiv preprint arXiv:1712.01815 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2406.03816 , year=
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search , author=. arXiv preprint arXiv:2406.03816 , year=
-
[45]
2026 , eprint=
Self-Improvement for Fast, High-Quality Plan Generation , author=. 2026 , eprint=
2026
-
[46]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.