CMAG: Concept-Scaffolded Retrieval for Marketplace Avatar Generation
Pith reviewed 2026-05-20 11:38 UTC · model grok-4.3
The pith
CMAG creates a 3D concept scaffold from text to retrieve and verify compatible avatar parts from a marketplace catalog.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
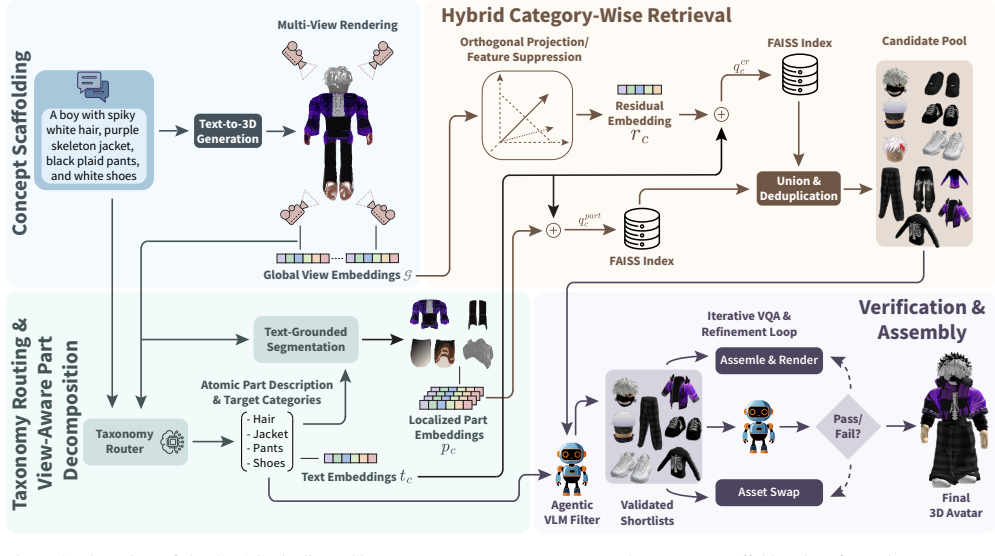
Given a prompt, CMAG first synthesizes an intermediate 3D concept scaffold that disambiguates intent beyond text by providing global spatial and stylistic context. In parallel, a view-aware part discovery module extracts localized visual evidence via prompt decomposition and text-grounded segmentation. A prompt-conditioned taxonomy router enforces category coverage and resolves semantic-to-taxonomic mismatch, after which a hybrid category-wise retriever combines part-based fusion with a concept-residual fallback using feature suppression. Finally, an agentic vision-language model filters and re-ranks candidates across categories and drives an iterative verification loop to assemble prompt-fa
What carries the argument
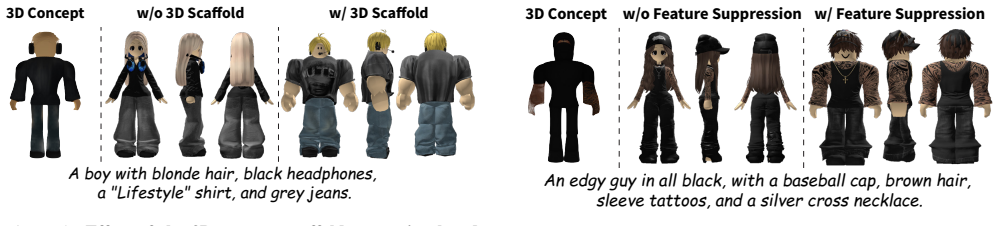
The 3D concept scaffold, an intermediate representation that supplies global spatial and stylistic context to disambiguate text prompts and guide part retrieval and verified composition.
If this is right
- Retrieval robustness increases on diverse compositional prompts compared with text-only baselines.
- Compositional correctness of assembled avatars improves when the concept scaffold supplies context under prompt ambiguity.
- The taxonomy router guarantees category coverage while resolving mismatches between user language and platform labels.
- The iterative verification loop produces topologically consistent results from catalog assets.
Where Pith is reading between the lines
- The scaffolding step could extend to other tasks that require assembling discrete 3D components, such as virtual furniture or scene layout.
- Reducing dependence on the verification model might allow lighter-weight deployment on resource-constrained metaverse platforms.
- The approach suggests that explicit 3D intermediates can serve as a general bridge between ambiguous language and structured asset databases.
Load-bearing premise
An agentic vision-language model can reliably detect and correct topological inconsistencies and stylistic mismatches across independently retrieved parts without introducing new errors or requiring extensive prompt engineering.
What would settle it
Testing CMAG on prompts engineered to produce known topological or stylistic clashes and measuring whether the verification loop yields valid assemblies at a high rate without extra human fixes.
Figures



read the original abstract
Metaverse platforms rely on creator-driven marketplaces where avatars are assembled from discrete, taxonomy-labeled 3D assets (e.g., tops, bottoms, shoes, accessories) under strict category and topology constraints. While users increasingly expect free-form text control, text-only retrieval is brittle: natural language is ambiguous with respect to platform taxonomies, metadata is often noisy or informal, and independently retrieved components can be stylistically inconsistent or geometrically incompatible. We propose \textbf{CMAG}, a concept-scaffolded retrieval and verified composition framework for marketplace avatar generation. Given a prompt, CMAG first synthesizes an intermediate 3D concept scaffold that disambiguates intent beyond text by providing global spatial and stylistic context. In parallel, a view-aware part discovery module extracts localized visual evidence via prompt decomposition and text-grounded segmentation. A prompt-conditioned taxonomy router enforces category coverage and resolves semantic-to-taxonomic mismatch, after which a hybrid category-wise retriever combines part-based fusion with a concept-residual fallback using feature suppression. Finally, an agentic vision--language model filters and re-ranks candidates across categories and drives an iterative verification loop to assemble prompt-faithful, topologically consistent avatars from catalog assets. We evaluate CMAG on diverse compositional prompts and demonstrate improved retrieval robustness and compositional correctness compared to strong baselines, highlighting the importance of 3D concept scaffolding under prompt ambiguity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CMAG, a modular framework for generating 3D avatars from free-form text prompts in metaverse marketplaces. It synthesizes an intermediate 3D concept scaffold for global context, performs view-aware part discovery via prompt decomposition, routes through a prompt-conditioned taxonomy to resolve mismatches, applies a hybrid category-wise retriever with concept-residual fallback, and uses an agentic vision-language model to filter stylistic and topological inconsistencies before iterative assembly of catalog assets. The central claim is improved retrieval robustness and compositional correctness over baselines on diverse compositional prompts.
Significance. If the empirical results hold, the work addresses a practical gap in constrained 3D asset retrieval by combining 3D scaffolding with agentic verification, which could improve real-world avatar composition systems under prompt ambiguity. The modular design highlights the value of explicit concept-level disambiguation for compositional correctness.
major comments (2)
- Abstract: the claim of 'improved retrieval robustness and compositional correctness' is presented without any quantitative metrics, baseline names, dataset statistics, or ablation results, leaving the central evaluation claim without verifiable support from the manuscript text.
- Agentic VLM component (described in the final stage of the framework): the assumption that the vision-language model reliably detects and corrects topological inconsistencies and stylistic mismatches lacks any reported precision, recall, error introduction rate, or ablation isolating its contribution versus the concept scaffold and taxonomy router; this is load-bearing for the end-to-end robustness claim.
minor comments (2)
- Abstract: consider adding one sentence on the scale or diversity of the 'diverse compositional prompts' used in evaluation to help readers gauge the scope.
- Terminology: ensure 'concept scaffold' and '3D concept scaffold' are used consistently when first introduced and in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of how we present our evaluation claims and the role of individual components. We respond to each major comment below and indicate the revisions we intend to make.
read point-by-point responses
-
Referee: Abstract: the claim of 'improved retrieval robustness and compositional correctness' is presented without any quantitative metrics, baseline names, dataset statistics, or ablation results, leaving the central evaluation claim without verifiable support from the manuscript text.
Authors: We agree that the abstract, being a concise summary, does not embed specific numbers or dataset details. The full manuscript reports these elements in the Experiments section, including comparisons to baselines such as text-only retrieval and direct embedding methods, along with dataset statistics and module ablations. To address the concern directly, we will revise the abstract to include brief quantitative highlights and baseline references while respecting length constraints. revision: partial
-
Referee: Agentic VLM component (described in the final stage of the framework): the assumption that the vision-language model reliably detects and corrects topological inconsistencies and stylistic mismatches lacks any reported precision, recall, error introduction rate, or ablation isolating its contribution versus the concept scaffold and taxonomy router; this is load-bearing for the end-to-end robustness claim.
Authors: We acknowledge that the current manuscript presents the agentic VLM primarily through its integration in the end-to-end pipeline and overall performance gains rather than isolated verification metrics or a dedicated ablation. The end-to-end results support the framework's robustness, but we agree that explicit quantification would strengthen the claim. We will add an ablation isolating the VLM stage and report relevant statistics such as detection rates for inconsistencies in the revised manuscript. revision: yes
Circularity Check
No circularity: modular framework with empirical evaluation, no derivations or self-referential reductions
full rationale
The paper presents CMAG as a modular pipeline of independently described components (3D concept scaffold, view-aware part discovery, taxonomy router, hybrid retriever, agentic VLM loop) motivated by platform constraints and prompt ambiguity. No equations, first-principles derivations, or predictions appear that reduce claimed robustness gains to quantities defined by the method's own fitted parameters, self-citations, or ansatzes. Evaluation on diverse compositional prompts supplies external empirical support rather than internal consistency that loops back to inputs. This is a standard applied CV framework paper whose central claims rest on comparative results against baselines, not tautological redefinitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Marketplace avatars must be assembled from discrete taxonomy-labeled 3D assets under strict category and topology constraints.
- domain assumption Text-only retrieval is brittle due to ambiguity, noisy metadata, and stylistic or geometric incompatibility.
Reference graph
Works this paper leans on
-
[1]
Generating CAD code with vision-language models for 3d designs.arXiv preprint arXiv:2410.05340, 2024
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Gen- erating cad code with vision-language models for 3d designs. arXiv preprint arXiv:2410.05340, 2024. 3
-
[2]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Kather- ine Xu, Tsung-Han Wu, Yu Zhou, Lil...
work page 2025
-
[3]
Garikipati, Foad Dabiri, and Chang Xu
Jason Ding, Rohan Gangaraju, Krishna C. Garikipati, Foad Dabiri, and Chang Xu. Avatar-agent: A multi-agent sys- tem for expressive 3d avatar generation. InProceed- ings of the International Workshop on Agentic Engineer- ing (AGENT 2026). Roblox, 2026. DOI:10 . 1145 / 3786167.3788404. 3, 6
-
[4]
Ip-composer: Semantic composition of visual concepts
Sara Dorfman, Dana Cohen-Bar, Rinon Gal, and Daniel Cohen-Or. Ip-composer: Semantic composition of visual concepts. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025. 3, 6
work page 2025
-
[5]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazar´e, Maria Lomeli, Lucas Hosseini, and Herv´e J´egou. The faiss library. IEEE Transactions on Big Data, 2025. 6
work page 2025
-
[6]
Eval3D: Interpretable and Fine-grained Evaluation for 3D Genera- tion
Shivam Duggal, Yushi Hu, Oscar Michel, Aniruddha Kem- bhavi, William T Freeman, Noah A Smith, Ranjay Krishna, Antonio Torralba, Ali Farhadi, and Wei-Chiu Ma. Eval3D: Interpretable and Fine-grained Evaluation for 3D Genera- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2025. 6
work page 2025
-
[7]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6
work page 2022
-
[8]
Byung Hyun Lee, Sungjin Lim, and Se Young Chun. Lo- calized concept erasure for text-to-image diffusion models using training-free gated low-rank adaptation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
work page 2025
-
[9]
Ll3m: Large language 3d modelers.arXiv preprint arXiv:2508.08228, 2025
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtz- man, and Rana Hanocka. Ll3m: Large language 3d model- ers.arXiv preprint arXiv:2508.08228, 2025. 3
-
[10]
Deep geometric moments promote shape consistency in text- to-3d generation
Utkarsh Nath, Rajeev Goel, Eun Som Jeon, Changhoon Kim, Kyle Min, Yezhou Yang, Yingzhen Yang, and Pavan Turaga. Deep geometric moments promote shape consistency in text- to-3d generation. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV),
-
[11]
Utkarsh Nath, Rajeev Goel, Rahul Khurana, Kyle Min, Mark Ollila, Pavan K Turaga, Varun Jampani, and Te- jaswi Gowda. Decompdreamer: A composition-aware cur- riculum for structured 3d asset generation.arXiv preprint arXiv:2503.11981, 2025
-
[12]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion. InThe Eleventh International Conference on Learning Representa- tions, 2023. 2
work page 2023
-
[13]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 6
work page 2021
-
[14]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Tencent. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Learning low-rank feature for thorax disease classification
Yancheng Wang, Rajeev Goel, Utkarsh Nath, Alvin C Silva, Teresa Wu, and Yingzhen Yang. Learning low-rank feature for thorax disease classification. InAdvances in Neural In- formation Processing Systems, 2024. 3
work page 2024
-
[17]
Native and Compact Structured Latents for 3D Generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Trellis: Learning a structured latent representation for 3d generation. arXiv preprint arXiv:2512.14692, 2025. 2, 6
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.