Toward Compiler World Models: Learning Latent Dynamics for Efficient Tensor Program Search
Pith reviewed 2026-06-27 17:31 UTC · model grok-4.3
The pith
A latent dynamics model that simulates scheduling actions in continuous space ranks tensor program candidates more accurately than static cost models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
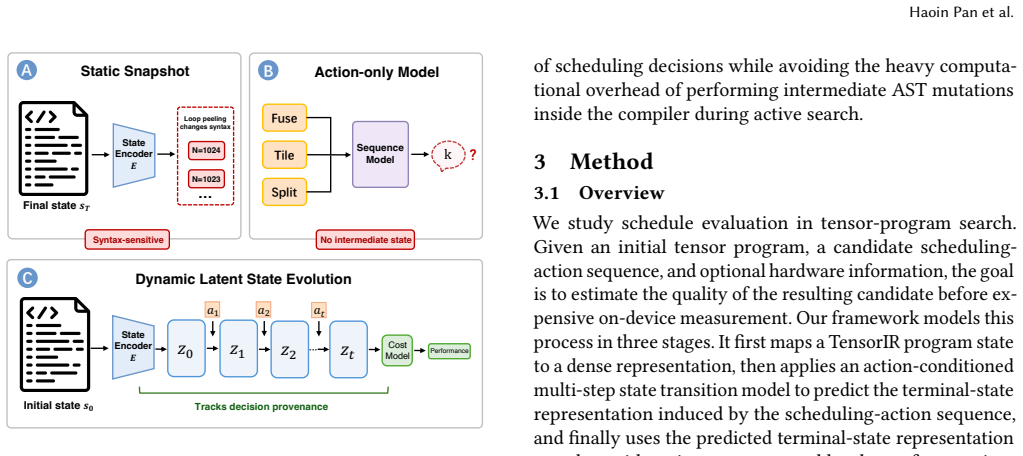
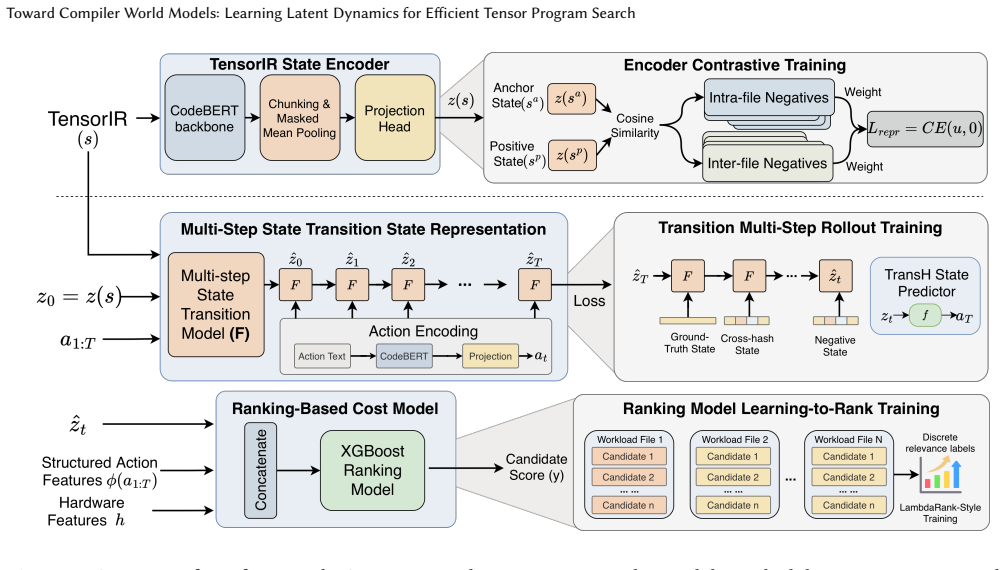
The central claim is that modeling schedule evaluation as action-conditioned latent dynamics over program states, using a lightweight transition model to roll out actions in continuous latent space, produces a final dynamic representation that, when combined with action and hardware features, ranks candidates more effectively than static evaluators.
What carries the argument
Action-conditioned latent dynamics transition model that rolls out scheduling actions from the initial program state in continuous space.
If this is right
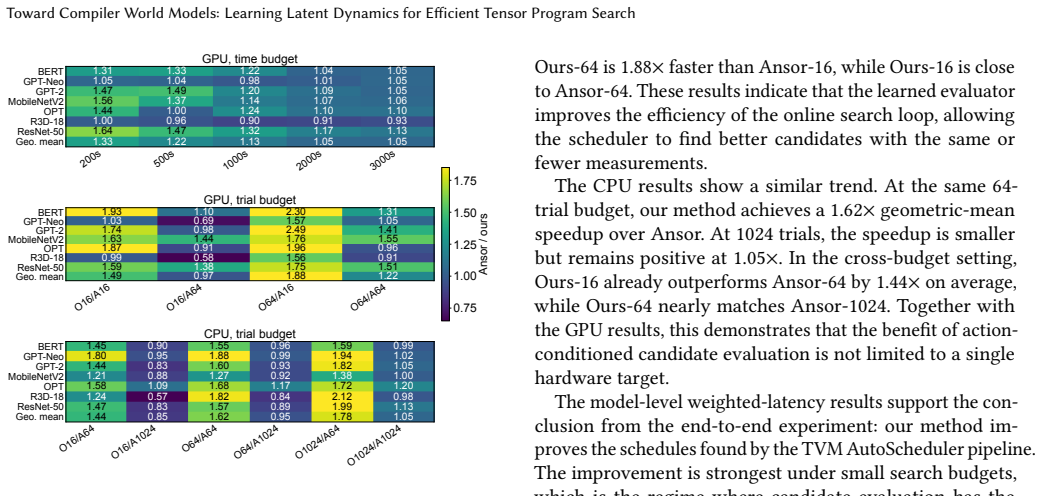
- Under a fixed 64-trial budget the method reduces representative-subgraph latency by 1.37× on GPU and 1.54× on CPU compared with Ansor.
- It reaches performance within 2.2 % geometric mean of an Ansor run that used 10 000 trials while using only one-tenth the measurements.
- Full-model inference speed improves by 4.61× over PyTorch and 3.67× over PyTorch with cuDNN geometric mean.
- The evaluator avoids repeated code generation and measurement for each candidate by simulating trajectories in latent space.
Where Pith is reading between the lines
- The same latent-dynamics pattern could be tried on other compiler passes that also build long action sequences, such as register allocation or loop nest transformations.
- If the transition model proves accurate, it opens the possibility of gradient-based search inside the latent space rather than discrete trial-and-error.
- Hardware-specific features are still concatenated at the end, so the method may still need retraining when the target device changes.
Load-bearing premise
The lightweight transition model operating in continuous latent space can faithfully predict the performance effects of scheduling actions without actual AST changes or repeated executions.
What would settle it
Measure the correlation between the latent model's predicted ranking of 1000 schedules and their actual measured latencies on the target hardware; if the ranking correlation falls below a usable threshold the claim fails.
Figures

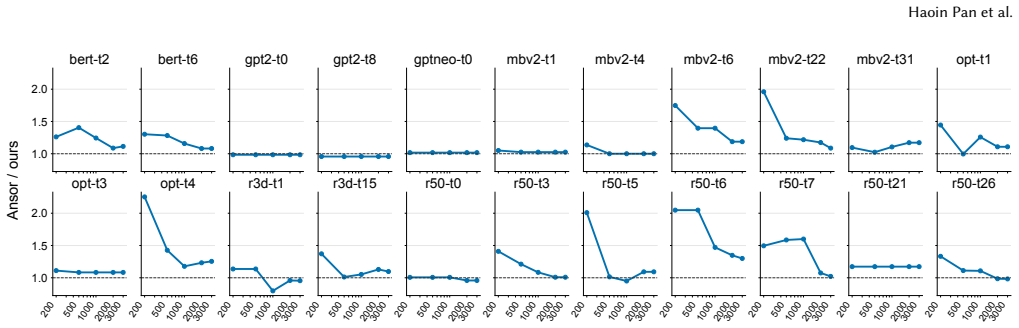
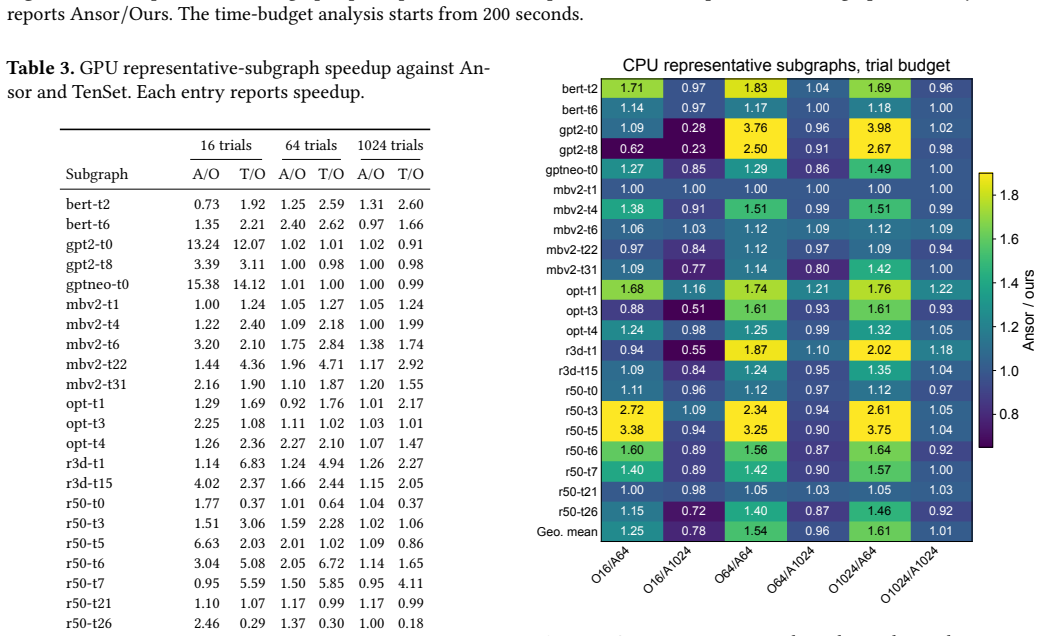

read the original abstract
Tensor program optimization is essential for modern machine learning systems, but its search space is enormous. Existing auto-schedulers reduce measurement cost with learned cost models, yet they usually evaluate each candidate as a static code snapshot, ignoring the schedule trajectory that produced it. This makes them insensitive to action dependencies and vulnerable to superficial code variations. We propose a \emph{world-model-inspired} evaluator that models schedule evaluation as action-conditioned latent dynamics over program states. Starting from the initial program, it rolls out scheduling actions in a continuous latent space with a lightweight transition model, avoiding expensive AST mutation and repeated code encoding. The final dynamic representation is combined with action and hardware features to rank candidates. Implemented in TVM AutoScheduler, our method improves representative-subgraph latency over Ansor by 1.37$\times$ on GPU and 1.54$\times$ on CPU under the same 64-trial budget. It also matches Ansor-10K within 2.2% geometric mean using 10$\times$ fewer measurements, and accelerates full-model inference over PyTorch/PyTorch-opt(cuDNN) by 4.61$\times$/3.67$\times$ geometric mean.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modeling tensor program scheduling evaluation as action-conditioned latent dynamics in a continuous latent space, using a lightweight transition model starting from the initial program, allows efficient candidate ranking without repeated AST mutations or code encodings. Implemented in TVM AutoScheduler, the approach reports 1.37× GPU and 1.54× CPU improvements in representative-subgraph latency over Ansor under a 64-trial budget, matches Ansor-10K performance within 2.2% geometric mean using 10× fewer measurements, and yields 4.61×/3.67× geometric mean speedups over PyTorch/PyTorch-opt(cuDNN) for full-model inference.
Significance. If the results hold, this work could meaningfully advance auto-scheduling by incorporating dynamics modeling to capture action dependencies, potentially reducing measurement costs in tensor program optimization for ML systems. The real-hardware evaluation and comparison to strong baselines like Ansor are strengths.
minor comments (1)
- The abstract supplies no model architecture details, training procedure, validation splits, error bars, or ablation studies; the full manuscript should ensure these are clearly presented in the experimental section to support the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, including recognition of the real-hardware evaluation and strong baseline comparisons. The recommendation for minor revision is noted. As no specific major comments were provided in the report, we have no point-by-point responses to address at this time.
Circularity Check
No significant circularity; empirical results validated externally on hardware
full rationale
The paper's central claims consist of measured latency improvements (1.37×/1.54× over Ansor under fixed trial budget, matching Ansor-10K with 10× fewer measurements) obtained by deploying a learned latent transition model inside TVM AutoScheduler and evaluating the resulting schedules on real GPU/CPU hardware. No equations, derivations, or self-citations are presented that reduce a claimed prediction or uniqueness result to fitted parameters or prior author work by construction. The method is a standard learned surrogate for ranking; its validity is established by direct external measurement rather than internal self-definition. This is the most common honest non-finding for applied ML papers with hardware benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. 2016. {TensorFlow}: a system for {Large-Scale} machine learning. In12th USENIX symposium on operating systems design and implementation (OSDI 16). 265–283
2016
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Andrew Adams, Karima Ma, Luke Anderson, Riyadh Baghdadi, Tzu- Mao Li, Michaël Gharbi, Benoit Steiner, Steven Johnson, Kayvon Fata- halian, Frédo Durand, et al. 2019. Learning to optimize halide with tree search and random programs.ACM Transactions on Graphics (TOG)38, 4 (2019), 1–12
2019
-
[4]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al. 2024. Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. In Proceedings of the 29th ACM international conference on architectural support for programmin...
2024
-
[5]
Anthropic. 2024. The Claude 3 Model Family: Opus, Sonnet, Haiku.https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/ModelCardClaude3. pdfModel card
2024
-
[6]
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. 2026. Motus: A unified latent action world model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 35101–35113
2026
-
[7]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for model- ing multi-relational data.Advances in neural information processing systems26 (2013)
2013
-
[8]
Christopher Burges, Robert Ragno, and Quoc Le. 2006. Learning to rank with nonsmooth cost functions.Advances in neural information processing systems19 (2006)
2006
-
[9]
Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 785–794
2016
-
[10]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hin- ton. 2020. A simple framework for contrastive learning of visual rep- resentations. InInternational conference on machine learning. PmLR, 1597–1607
2020
-
[11]
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. 2015. Mxnet: A flexible and efficient machine learning library for heteroge- neous distributed systems.arXiv preprint arXiv:1512.01274(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX symposium on operating systems design and implementation (OSDI 18). 578–594
2018
-
[13]
Tianqi Chen, Lianmin Zheng, Eddie Yan, Ziheng Jiang, Thierry Moreau, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. Learning to optimize tensor programs.Advances in Neural Information Processing Systems31 (2018)
2018
-
[14]
Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Co- hen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. cudnn: Efficient primitives for deep learning.arXiv preprint arXiv:1410.0759 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural lan- guages. InFindings of the association for computational linguistics: EMNLP 2020. 1536–1547
2020
-
[16]
2026.oneDNN Documentation
Intel. 2026.oneDNN Documentation. Intel.https://www. intel.com/content/www/us/en/developer/tools/oneapi/onednn- documentation.htmlAccessed: 2026-04-12
2026
- [17]
-
[18]
Isu Jeong and Seulki Lee. 2025. Bayesian code diffusion for efficient automatic deep learning program optimization. In19th USENIX Sym- posium on Operating Systems Design and Implementation (OSDI 25). 295–311
2025
-
[19]
Guoliang Ji, Shizhu He, Liheng Xu, Kang Liu, and Jun Zhao. 2015. Knowledge graph embedding via dynamic mapping matrix. InPro- ceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (volume 1: Long papers). 687–696
2015
- [20]
-
[21]
Yann LeCun et al. 2022. A path towards autonomous machine intelli- gence version 0.9. 2, 2022-06-27.Open Review62, 1 (2022), 1–62
2022
-
[22]
Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, and Xuan Zhu. 2015. Learning entity and relation embeddings for knowledge graph com- pletion. InProceedings of the AAAI conference on artificial intelligence, Vol. 29
2015
-
[23]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Yizhi Liu, Yao Wang, Ruofei Yu, Mu Li, Vin Sharma, and Yida Wang
-
[25]
In2019 USENIX Annual Technical Conference (USENIX ATC 19)
Optimizing {CNN} model inference on {CPUs }. In2019 USENIX Annual Technical Conference (USENIX ATC 19). 1025–1040
-
[26]
2026.LLVM Documentation
LLVM Project. 2026.LLVM Documentation. LLVM Project.https: //llvm.org/docs/Accessed: 2026-04-12
2026
-
[27]
Martin Paul Lücke, Oleksandr Zinenko, William S Moses, Michel Steuwer, and Albert Cohen. 2025. The MLIR transform dialect: Your compiler is more powerful than you think. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimiza- tion. 241–254
2025
-
[28]
Zixuan Ma, Haojie Wang, Jingze Xing, Shuhong Huang, Liyan Zheng, Chen Zhang, Huanqi Cao, Kezhao Huang, Mingshu Zhai, Shizhi Tang, et al. 2025. IntelliGen: Instruction-Level Auto-tuning for Tensor Pro- gram with Monotonic Memory Optimization. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Opti- mization. 107–122
2025
-
[29]
2026.CUTLASS: CUDA Templates for Linear Algebra Subrou- tines and Solvers
NVIDIA. 2026.CUTLASS: CUDA Templates for Linear Algebra Subrou- tines and Solvers. NVIDIA.https://docs.nvidia.com/cutlass/Accessed: 2026-04-12
2026
-
[30]
2026.NVIDIA CUDA Compiler Driver NVCC Documentation
NVIDIA. 2026.NVIDIA CUDA Compiler Driver NVCC Documentation. NVIDIA.https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/ index.htmlVersion 13.1, Accessed: 2026-04-12. 13 Haoin Pan et al
2026
-
[31]
2026.NVIDIA TensorRT Documentation
NVIDIA. 2026.NVIDIA TensorRT Documentation. NVIDIA.https: //docs.nvidia.com/deeplearning/tensorrt/latest/Accessed: 2026-04-12
2026
-
[32]
2026.ONNX Documentation
ONNX Community. 2026.ONNX Documentation. ONNX.https: //onnx.ai/onnx/Version 1.22.0, Accessed: 2026-04-12
2026
-
[33]
Liang Qiao, Jun Shi, Xiaoyu Hao, Xi Fang, Sen Zhang, Minfan Zhao, Ziqi Zhu, Junshi Chen, Hong An, Xulong Tang, et al. 2025. Pruner: A draft-then-verify exploration mechanism to accelerate tensor pro- gram tuning. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 949–965
2025
- [34]
-
[35]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Hao- ran Wei, et al . 2024. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115(2024).https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Jared Roesch, Steven Lyubomirsky, Logan Weber, Josh Pollock, Marisa Kirisame, Tianqi Chen, and Zachary Tatlock. 2018. Relay: A new ir for machine learning frameworks. InProceedings of the 2nd ACM SIG- PLAN international workshop on machine learning and programming languages. 58–68
2018
-
[37]
Junru Shao, Xiyou Zhou, Siyuan Feng, Bohan Hou, Ruihang Lai, Hongyi Jin, Wuwei Lin, Masahiro Masuda, Cody Hao Yu, and Tianqi Chen. 2022. Tensor program optimization with probabilistic programs. Advances in Neural Information Processing Systems35 (2022), 35783– 35796
2022
-
[38]
Tadahiro Taniguchi, Ryo Ueda, Tomoaki Nakamura, Masahiro Suzuki, and Akira Taniguchi. 2026. Generative emergent communication: Large language model is a collective world model.Advanced Robotics (2026), 1–26
2026
-
[39]
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. 2019. Triton: an intermediate language and compiler for tiled neural network computa- tions. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. 10–19
2019
-
[40]
Mohammed Tirichine, Nassim Ameur, Nazim Bendib, Iheb Nassim Aouadj, Djad Bouchama, Rafik Bouloudene, and Riyadh Baghdadi
-
[41]
In2026 IEEE/ACM International Symposium on Code Generation and Optimization (CGO)
A Reinforcement Learning Environment for Automatic Code Optimization in the MLIR Compiler. In2026 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 696– 710
-
[42]
Nicolas Vasilache, Oleksandr Zinenko, Theodoros Theodoridis, Priya Goyal, Zachary DeVito, William S Moses, Sven Verdoolaege, Andrew Adams, and Albert Cohen. 2018. Tensor comprehensions: Framework- agnostic high-performance machine learning abstractions.arXiv preprint arXiv:1802.04730(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge graph embedding by translating on hyperplanes. InPro- ceedings of the AAAI conference on artificial intelligence, Vol. 28
2014
-
[44]
Yi Zhai, Sijia Yang, Keyu Pan, Renwei Zhang, Shuo Liu, Chao Liu, Zichun Ye, Jianmin Ji, Jie Zhao, Yu Zhang, et al. 2024. Enabling tensor language model to assist in generating {High-Performance} tensor programs for deep learning. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 289–305
2024
-
[45]
Yi Zhai, Yu Zhang, Shuo Liu, Xiaomeng Chu, Jie Peng, Jianmin Ji, and Yanyong Zhang. 2023. Tlp: A deep learning-based cost model for tensor program tuning. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 833–845
2023
-
[46]
Hongbin Zhang, Mingjie Xing, Yanjun Wu, and Chen Zhao. 2023. Com- piler Technologies in Deep Learning Co-Design: A Survey.Intelligent Computing(2023)
2023
-
[47]
Jie Zhao, Bojie Li, Wang Nie, Zhen Geng, Renwei Zhang, Xiong Gao, Bin Cheng, Chen Wu, Yun Cheng, Zheng Li, et al. 2021. AKG: auto- matic kernel generation for neural processing units using polyhedral transformations. InProceedings of the 42nd ACM SIGPLAN Interna- tional Conference on Programming Language Design and Implementa- tion. 1233–1248
2021
-
[48]
Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu, Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang, Danyang Zhuo, Koushik Sen, et al. 2020. Ansor: Generating {High-Performance} tensor programs for deep learning. In14th USENIX symposium on operating systems design and implementation (OSDI 20). 863–879
2020
-
[49]
Lianmin Zheng, Ruochen Liu, Junru Shao, Tianqi Chen, Joseph E Gonzalez, Ion Stoica, and Ameer Haj Ali. 2021. Tenset: A large-scale program performance dataset for learned tensor compilers. InThirty- fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)
2021
-
[50]
Size Zheng, Yun Liang, Shuo Wang, Renze Chen, and Kaiwen Sheng
-
[51]
InPro- ceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems
Flextensor: An automatic schedule exploration and optimization framework for tensor computation on heterogeneous system. InPro- ceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 859–873. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.