Evaluating Agentic Configuration Repair for Computer Networks
Pith reviewed 2026-06-28 01:08 UTC · model grok-4.3
The pith
Agentic LLM architectures with verification tools outperform base models at repairing network misconfigurations by 12 percent in efficacy and 17 percent in safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
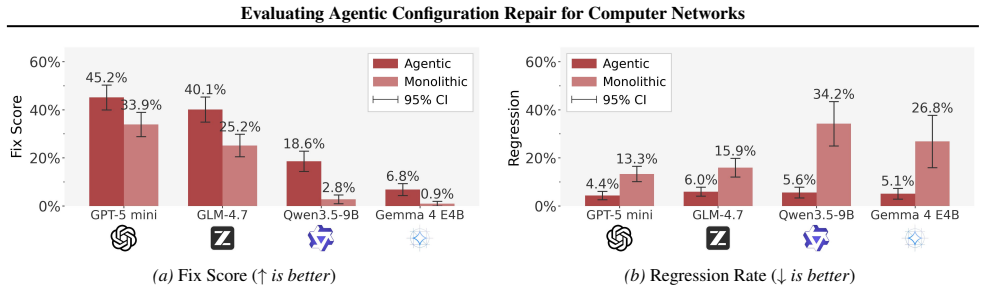
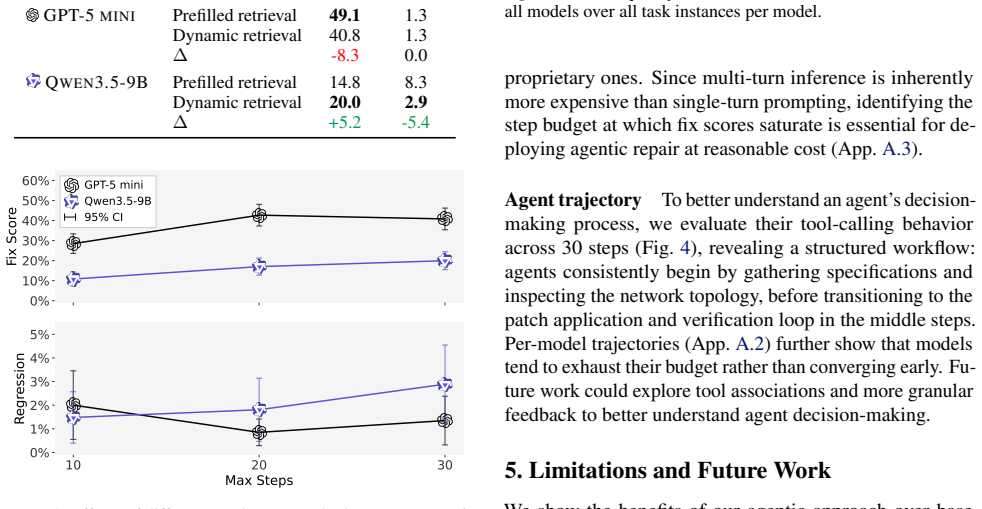
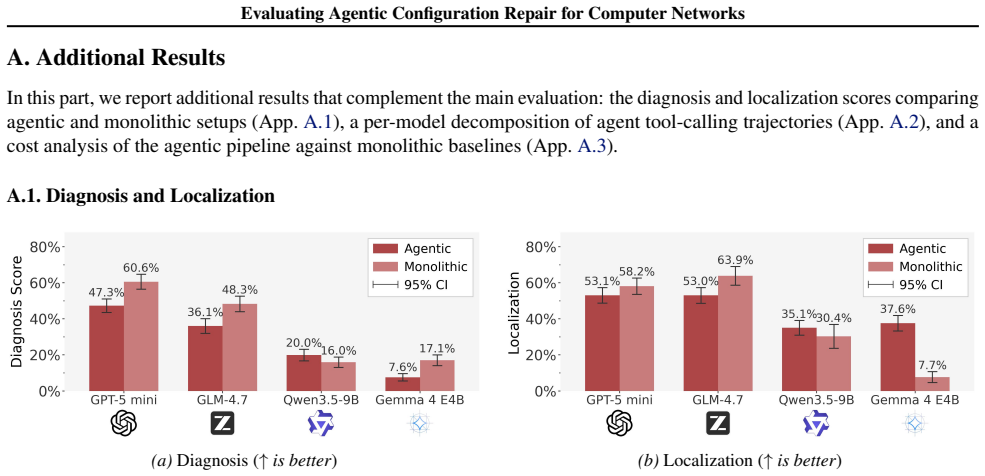
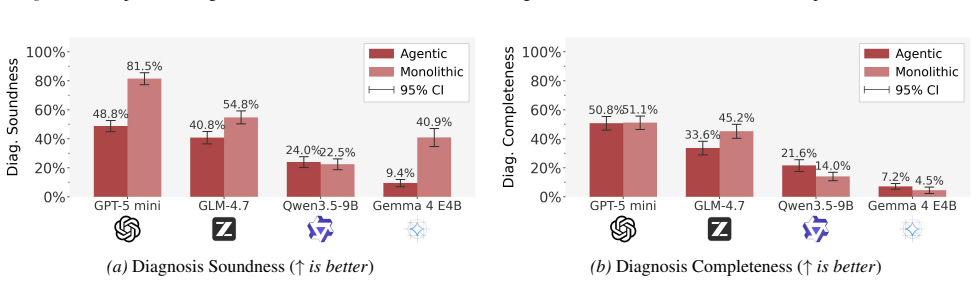
Agentic architectures outperform base LLMs in repair efficacy by 12% on average and safety by 17% on average, enabled by the ability to dynamically manage context and iteratively validate configuration repairs.
What carries the argument
Agentic architectures augmented with formal network verification and context retrieval tools, which enable dynamic context management and iterative validation of repairs.
If this is right
- Agentic systems achieve higher rates of successful configuration repairs in the tested scenarios.
- They introduce fewer new errors during the repair process.
- Dynamic context management allows handling of larger and more complex network setups.
- Iterative validation with formal tools improves the safety of generated repairs.
Where Pith is reading between the lines
- The same tool-augmented approach could reduce the frequency of human intervention needed for routine network fixes.
- Similar agentic patterns may transfer to configuration tasks outside networks, such as software deployment or device setups.
- Real-time integration of these systems into live network controllers would test whether benchmark gains persist under operational constraints.
Load-bearing premise
The evaluation benchmarks and scenarios used accurately represent the large-scale, complex misconfigurations that occur in production networks.
What would settle it
Applying the same agentic and base LLM systems to misconfigurations drawn from an actual large production network and finding that the measured improvements in efficacy and safety disappear.
Figures



read the original abstract
Misconfigurations in computer networks remain a major source of critical Internet outages. Research is turning to Large Language Models (LLMs) to automate the complex, error-prone task of network configuration. However, even state-of-the-art models fail to resolve misconfigurations in large-scale, complex scenarios and often introduce new errors. In this work, we benchmark open- and closed-source LLMs augmented with formal network verification and context retrieval tools. We demonstrate that agentic architectures outperform base LLMs in repair efficacy (by 12% on average) and safety (by 17% on average), enabled by the ability to dynamically manage context and iteratively validate configuration repairs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks open- and closed-source LLMs augmented with formal network verification and context retrieval tools in agentic architectures for repairing network misconfigurations. It claims these agentic setups outperform base LLMs by 12% on average in repair efficacy and 17% on average in safety, attributing the gains to dynamic context management and iterative validation.
Significance. If the empirical results hold under representative benchmarks, the work could advance automated network configuration repair and reduce outage risks from misconfigurations. The direct comparison of agentic vs. base LLMs across model families is a clear strength, as is the focus on both efficacy and safety metrics.
major comments (2)
- [Abstract] Abstract: The central claims of 12% efficacy and 17% safety gains are stated without any description of benchmark construction, dataset size, number of scenarios, statistical tests, error bars, or exclusion criteria. This information is required to evaluate support for the reported deltas.
- [Abstract and §3] Abstract and §3: The assertion that the evaluation covers 'large-scale, complex scenarios' provides no quantitative scale metrics (e.g., number of devices, lines of configuration, protocol diversity, or topology size), which directly bears on whether the 12%/17% improvements can be extrapolated beyond the tested cases.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical on the number of models and scenarios evaluated to give readers an immediate sense of experimental scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation description. The comments highlight opportunities to improve transparency, and we have revised the manuscript to incorporate the requested details on benchmark construction and quantitative scale metrics while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 12% efficacy and 17% safety gains are stated without any description of benchmark construction, dataset size, number of scenarios, statistical tests, error bars, or exclusion criteria. This information is required to evaluate support for the reported deltas.
Authors: We agree the abstract was overly concise. Full details on benchmark construction (synthetic misconfigurations derived from real network traces), dataset size (150 scenarios), number of scenarios, statistical tests (paired t-tests, p < 0.05), error bars (standard deviation across 5 runs), and exclusion criteria (scenarios with >20% syntax errors pre-filtered) appear in Section 3 and Appendix B. We have expanded the abstract to briefly note these elements, including the 150-scenario count and significance testing, to support the reported deltas. revision: yes
-
Referee: [Abstract and §3] Abstract and §3: The assertion that the evaluation covers 'large-scale, complex scenarios' provides no quantitative scale metrics (e.g., number of devices, lines of configuration, protocol diversity, or topology size), which directly bears on whether the 12%/17% improvements can be extrapolated beyond the tested cases.
Authors: We accept that explicit quantitative metrics strengthen the claim. Section 3 already describes the topologies but lacked explicit aggregates; we have added them to both the abstract and §3: average 48 devices per topology (range 12-112), configurations averaging 2,800 lines (range 800-6,200), 6 protocols (BGP, OSPF, IS-IS, MPLS, VLAN, ACL), and topology sizes from 10 to 120 nodes. These additions clarify the evaluated scale and support extrapolation assessment. revision: yes
Circularity Check
No circularity: purely empirical benchmark comparison
full rationale
The paper reports direct empirical measurements of repair efficacy and safety on network configuration tasks, comparing agentic LLM architectures against base LLMs. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or described content. The 12% and 17% deltas are stated as observed averages from benchmarks, not as outputs of any model or theorem that reduces to author-defined inputs. The evaluation assumption about benchmark realism is a validity concern, not a circularity issue in any claimed derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
USENIX Association. ISBN 978-1-939133-13-7. URL https://www.usenix.org/conference/ nsdi20/presentation/birkner. Fogel, A., Fung, S., Pedrosa, L., Walraed-Sullivan, M., Govindan, R., Mahajan, R., and Millstein, T. A general approach to network configuration analysis. In12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15), pp. 469–...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/jsac.2011 2015
-
[2]
URL https: //blog.cloudflare.com/18-november- 2025-outage/
Cloudflare Blog, 2025. URL https: //blog.cloudflare.com/18-november- 2025-outage/. Accessed: 2026-04-29. Protogeros, I., Asadli, R., Hoffman, B., and Vanbever, L. Benchmarking llm-driven network configuration re- pair, 2026. URL https://arxiv.org/abs/2604. 22513. Shamim, F., Aziz, Z., Liu, J., and Martey, A.Troubleshoot- ing IP Routing Protocols. CCIE Pro...
-
[3]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
USENIX Association. ISBN 978-1-939133-39-7. URL https://www.usenix.org/conference/ nsdi24/presentation/wang-haopei. Wang, X., Li, B., Song, Y ., Xu, F. F., Tang, X., Zhuge, M., Pan, J., Song, Y ., Li, B., Singh, J., Tran, H. H., Li, F., Ma, R., Zheng, M., Qian, B., Shao, Y ., Muennighoff, N., Zhang, Y ., Hui, B., Lin, J., Brennan, R., Peng, H., Ji, H., an...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3718958.3750537 2025
-
[4]
router name
approach in which three LLMs (GPT-5.1, CLAUDE4.5 OPUS, and GEMINI2.5 PRO) independently assess the soundness and completeness of each model’s solution trajectory. We follow a multi-judge evaluation mechanism to avoid potential biases. More importantly, each judge receives the ground truth misconfiguration (i.e., the list of injected faults), meaning that ...
2024
-
[5]
Start by examining the violated specifications to understand what is broken
-
[6]
Inspect relevant router configurations to diagnose root causes
-
[7]
Apply targeted patches to fix the identified issues
-
[8]
Run verification to check if specs are restored and no regressions occurred
-
[9]
If issues remain, analyze the verification feedback and iterate
-
[10]
If a patch introduces regressions, rollback and try a different approach
-
[11]
Important Rules 12 Evaluating Agentic Configuration Repair for Computer Networks •Be precise with search blocks: they must match the config EXACTLY (whitespace, indentation, etc.)
Submit when satisfied or when you’ve exhausted reasonable repair attempts. Important Rules 12 Evaluating Agentic Configuration Repair for Computer Networks •Be precise with search blocks: they must match the config EXACTLY (whitespace, indentation, etc.). •Prefer small, targeted patches over large rewrites. •Always verify after applying patches before sub...
-
[12]
Identify which routers must be modified to restore the correct forwarding behavior
-
[13]
Generate the necessary modifications for each router configuration
-
[14]
Expected Output Format: Output must be valid YAML only, with the following top-level keys: routers, then metadata, then replacements
Provide your solution as explicit search-and-replace instructions for each router. Expected Output Format: Output must be valid YAML only, with the following top-level keys: routers, then metadata, then replacements. Specification Semantics: Specifications are formatted as CSV lines with columns: Type, Source Node, Destination Prefix, waypoint node, num r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.