On-Policy Replay for Continual Supervised Fine-Tuning
Pith reviewed 2026-06-29 09:02 UTC · model grok-4.3
The pith
On-Policy Replay reduces forgetting in continual LLM fine-tuning by replaying the model's own generations on historical prompts as standard SFT data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
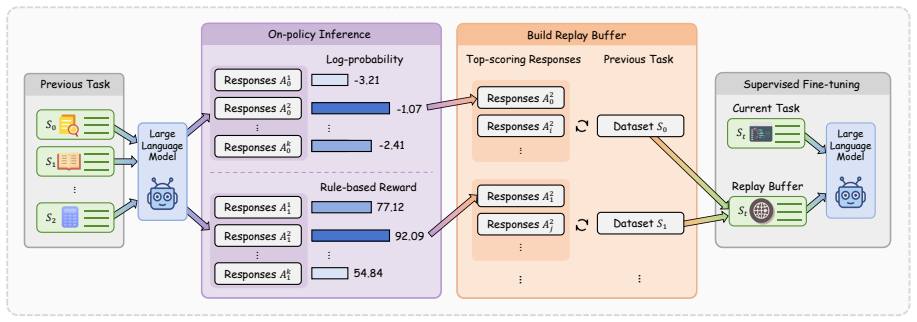
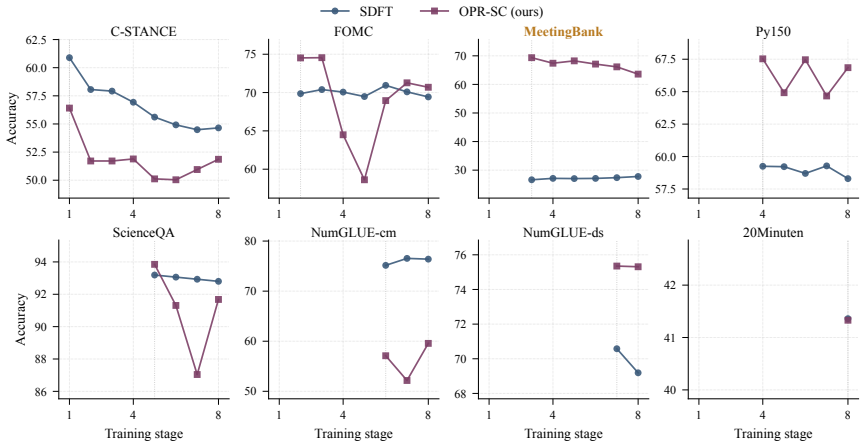
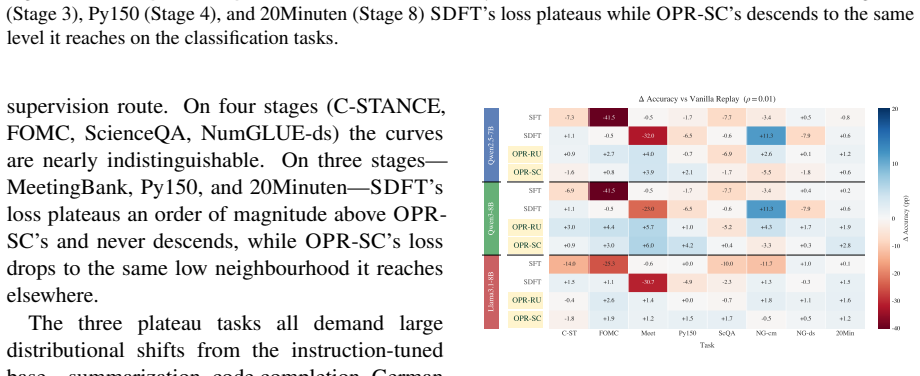
On-Policy Replay (OPR) rolls out the most recent checkpoint on historical prompts, filters the generations by a task reward, and replays the surviving (prompt, model response) pairs as ordinary SFT examples. There is no teacher, no auxiliary loss, and no on-the-fly distillation. Across three 7-8B instruction-tuned backbones on the TRACE continual-learning benchmark, OPR consistently reduces forgetting; on the sharpest stress test (Qwen2.5-7B-Instruct, Sequential SFT BWT -13.93), OPR lifts BWT to -0.65 at a 10% replay budget and to -2.29 at a 1% budget -- a 46% reduction in |BWT| over a tuned Vanilla Replay baseline, with 42-46% reductions observed across all three backbones.
What carries the argument
On-Policy Replay: generating responses from the current model on a budget of historical prompts, filtering them by task reward, and inserting the surviving pairs directly into the standard SFT training set.
If this is right
- OPR improves BWT from -13.93 to -0.65 at 10% replay budget and to -2.29 at 1% budget on Qwen2.5-7B-Instruct under Sequential SFT.
- Reductions of 42-46% in |BWT| hold across Qwen2.5-7B-Instruct, Qwen3-8B, and Llama3.1-8B-Instruct.
- OPR admits a KL-shrinkage interpretation that places it on the same axis as prior on-policy distillation methods.
- Low-score replay is uniformly worse than Vanilla Replay, showing that the on-policy distribution itself, not response quality alone, is the active ingredient.
Where Pith is reading between the lines
- The method may generalize to continual settings where an implicit quality signal can substitute for an explicit task reward.
- Testing OPR inside reinforcement learning loops or multi-agent continual adaptation could reveal whether the on-policy sourcing principle extends beyond supervised fine-tuning.
- Hybrid replay strategies that combine vanilla data with a small on-policy component might offer practical trade-offs when task rewards are expensive to compute.
Load-bearing premise
A reliable task reward function exists that can accurately filter model generations on historical prompts without introducing selection bias or requiring additional labeled data.
What would settle it
Training with unfiltered or randomly filtered model generations on the same historical prompts and observing whether the forgetting reduction relative to vanilla replay disappears.
Figures

read the original abstract
Continual supervised fine-tuning (SFT) is the de facto recipe for adapting large language models (LLMs) to a stream of downstream tasks, but it suffers from catastrophic forgetting of earlier capabilities. Recent work shows that on-policy signals -- training on the model's own outputs -- reduce forgetting more reliably than off-policy supervision. Existing on-policy methods route this signal through a new training objective (e.g., self-distillation losses with a teacher copy), inheriting an extra forward pass, schedule sensitivity, and stylistic drift from the teacher.We instead route the on-policy signal through the training data source. Our method, On-Policy Replay (OPR), rolls out the most recent checkpoint on a small budget of historical prompts, filters the generations by a task reward, and replays the surviving (prompt, model response) pairs as ordinary SFT examples. There is no teacher, no auxiliary loss, and no on-the-fly distillation. Across three 7--8B instruction-tuned backbones (Qwen2.5-7B-Instruct, Qwen3-8B, Llama3.1-8B-Instruct) on the TRACE continual-learning benchmark, OPR consistently reduces forgetting; on the sharpest stress test (Qwen2.5-7B-Instruct, Sequential SFT BWT -13.93), OPR lifts BWT to -0.65 at a 10% replay budget and to -2.29 at a 1% budget -- a 46% reduction in |BWT| over a tuned Vanilla Replay baseline, with 42--46% reductions observed across all three backbones. We give a KL-shrinkage interpretation that places OPR and prior on-policy distillation methods on a single axis, and we present a counterintuitive finding that explains why Vanilla Replay is already a strong baseline: low-score replay is uniformly worse than Vanilla Replay, demonstrating that the active ingredient in OPR is the on-policy distribution, not the response quality alone.Our code is available at https://github.com/Yancey2024/OnPolicyReplay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes On-Policy Replay (OPR) for continual supervised fine-tuning of LLMs. The method rolls out the current checkpoint on a budget of historical prompts, filters generations via a task reward, and replays the surviving (prompt, response) pairs as standard SFT data. No teacher model, auxiliary loss, or on-the-fly distillation is used. On the TRACE benchmark, OPR reduces backward transfer (BWT) across three 7-8B backbones; the headline result is lifting BWT from -13.93 to -0.65 (10% budget) or -2.29 (1% budget) for Qwen2.5-7B-Instruct under Sequential SFT, a 46% |BWT| reduction versus a tuned Vanilla Replay baseline, with 42-46% gains across models. A KL-shrinkage interpretation unifies OPR with prior on-policy methods, and an ablation shows low-score replay underperforms Vanilla Replay.
Significance. If the reported BWT reductions hold under the stated constraints, OPR supplies a lightweight mechanism for injecting on-policy signals into continual SFT without extra objectives or teacher copies. The public code release is a clear strength for reproducibility. The finding that response quality alone does not explain the gains (low-score ablation) is a useful negative result that sharpens the role of the on-policy distribution.
major comments (3)
- [§3] §3 (Method), reward definition: the central claim that OPR requires 'no data beyond what is already available' and introduces no selection bias rests on the task reward being a fair, label-free filter; the manuscript provides no explicit definition, pseudocode, or per-task implementation details for this reward, preventing verification that it does not implicitly leverage ground-truth labels or task-specific heuristics.
- [§4.2] §4.2, Table 2 (or equivalent results table): the 46% |BWT| reduction versus 'tuned Vanilla Replay' is reported without stating the hyperparameter search space, number of tuning runs, or whether the baseline received the same reward-based filtering; this detail is load-bearing for the claim that the improvement stems from the on-policy distribution rather than privileged filtering.
- [§4.3] §4.3 (ablation): the low-score replay experiment demonstrates that filtering matters, yet does not test whether the reward itself is portable or unbiased across tasks; without this, the interpretation that 'the active ingredient in OPR is the on-policy distribution' remains under-supported.
minor comments (2)
- [§5] The KL-shrinkage interpretation in §5 is presented as an after-the-fact lens; a short derivation or reference to the relevant KL term would clarify how OPR and distillation methods lie on the same axis.
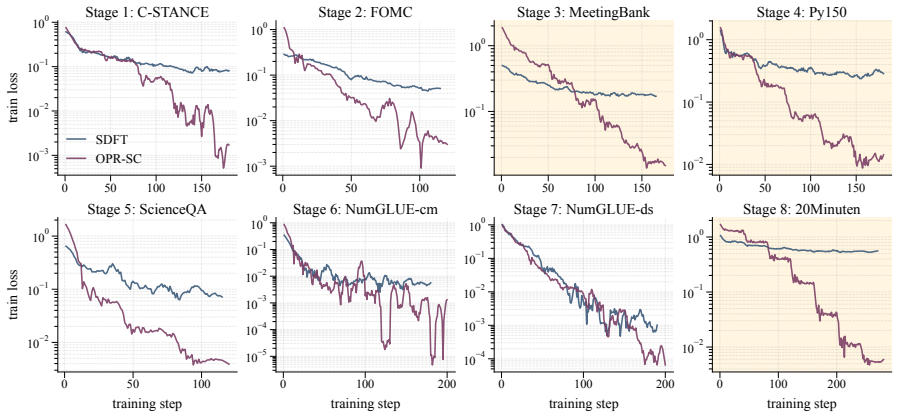
- Figure captions and axis labels in the experimental plots could be expanded to include exact replay budgets and model names for quicker reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights areas where additional clarity will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested details.
read point-by-point responses
-
Referee: [§3] §3 (Method), reward definition: the central claim that OPR requires 'no data beyond what is already available' and introduces no selection bias rests on the task reward being a fair, label-free filter; the manuscript provides no explicit definition, pseudocode, or per-task implementation details for this reward, preventing verification that it does not implicitly leverage ground-truth labels or task-specific heuristics.
Authors: We agree that the reward definition requires explicit documentation. The task reward for each TRACE task is the standard evaluation metric (e.g., exact match for math, accuracy for classification) computed against the ground-truth labels already present in the historical prompt datasets; no new labels or external data are introduced. This is label-using for filtering but does not constitute additional data collection. We will add a clear definition, pseudocode for the rollout-and-filter step, and per-task metric details to the revised §3. revision: yes
-
Referee: [§4.2] §4.2, Table 2 (or equivalent results table): the 46% |BWT| reduction versus 'tuned Vanilla Replay' is reported without stating the hyperparameter search space, number of tuning runs, or whether the baseline received the same reward-based filtering; this detail is load-bearing for the claim that the improvement stems from the on-policy distribution rather than privileged filtering.
Authors: The Vanilla Replay baseline was tuned over the same replay budget grid (1%, 5%, 10%) and learning-rate range as OPR, using three random seeds per setting; it replays randomly sampled historical (prompt, response) pairs with no reward filtering applied. We will expand the experimental details in the revised §4.2 and caption of Table 2 to include the full search space and confirm the absence of reward filtering on the baseline. revision: yes
-
Referee: [§4.3] §4.3 (ablation): the low-score replay experiment demonstrates that filtering matters, yet does not test whether the reward itself is portable or unbiased across tasks; without this, the interpretation that 'the active ingredient in OPR is the on-policy distribution' remains under-supported.
Authors: The reward is intentionally task-specific, matching the evaluation metric of each individual task; cross-task portability is neither claimed nor required for the method. The low-score ablation already isolates the role of the on-policy distribution: even on-policy responses that score poorly under the task reward underperform Vanilla Replay, showing that gains are not explained by response quality in isolation. We will add a clarifying paragraph in the revised §4.3 to make this scope explicit. revision: partial
Circularity Check
No circularity: empirical procedure evaluated on external benchmarks
full rationale
The paper defines OPR as an explicit procedural method (rollout on historical prompts, filter by task reward, replay as SFT data) and reports BWT improvements measured against external TRACE benchmark results and tuned baselines. No equations or derivations are presented that reduce the claimed gains to a fitted parameter or self-citation by construction; the KL-shrinkage view is explicitly labeled an after-the-fact interpretation rather than a load-bearing derivation. The method is self-contained against the stated benchmarks with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- replay budget percentage
axioms (1)
- domain assumption A task-specific reward function is available to score and filter model generations on historical prompts.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2508.04676
Gere: Towards efficient anti-forgetting in con- tinual learning of llm via general samples replay. arXiv preprint arXiv:2508.04676. Chenye Zhao, Yingjie Li, and Cornelia Caragea. 2023. C-STANCE: A large dataset for Chinese zero-shot stance detection. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (ACL). Siyan Z...
-
[2]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. Junhao Zheng, Xidi Cai, Shengjie Qiu, and Qianli Ma
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Bridging SFT and RL: Dynamic Policy Optimization for Robust Reasoning
Spurious forgetting in continual learning of language models. InInternational Conference on Learning Representations (ICLR). Taojie Zhu, Dongyang Xu, Ding Zou, Sen Zhao, Qiaobo Hao, Zhiguo Yang, and Yonghong He. 2026. Bridg- ing sft and rl: Dynamic policy optimization for robust reasoning.arXiv preprint arXiv:2604.08926. A TRACE Tasks, Templates, and Metr...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.