Configuration-Driven Dynamic API Routing for Resilient Service Integrations
Pith reviewed 2026-06-29 16:22 UTC · model grok-4.3
The pith
Configuration-driven dynamic API routing uses factor lists and live telemetry to switch between third-party providers without code changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
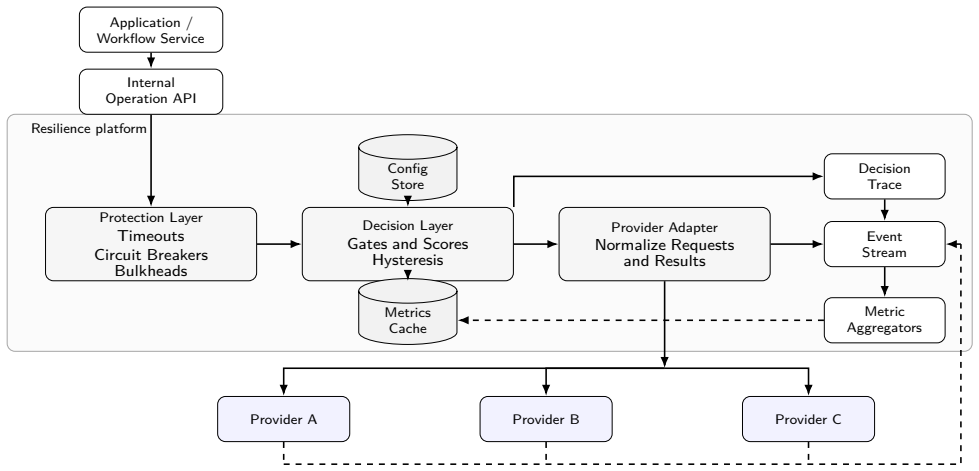
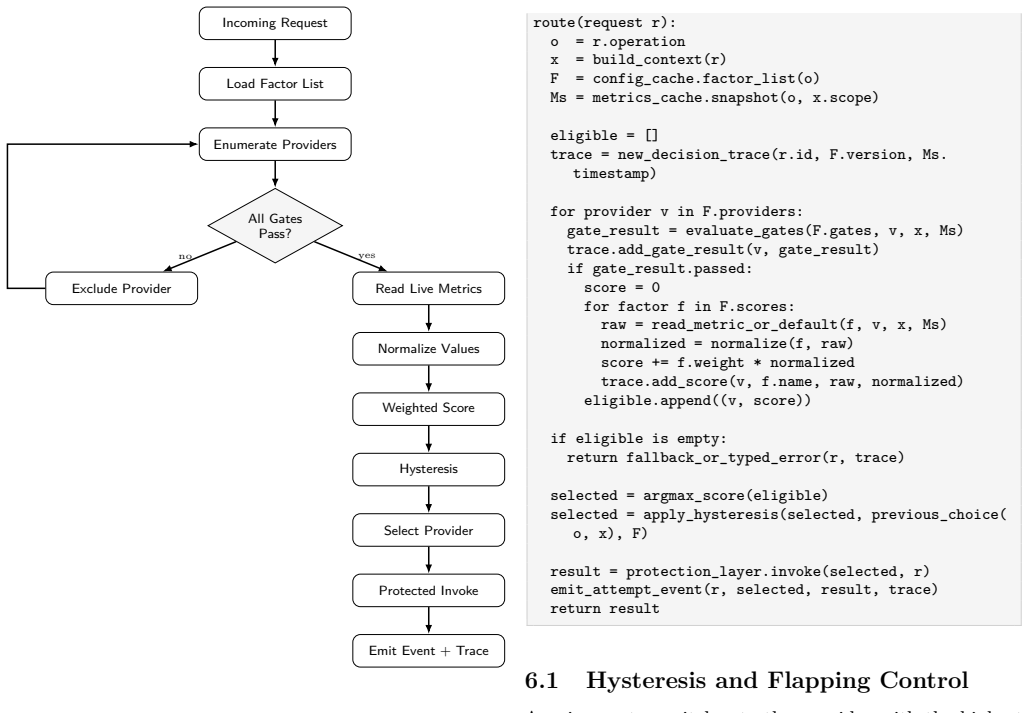
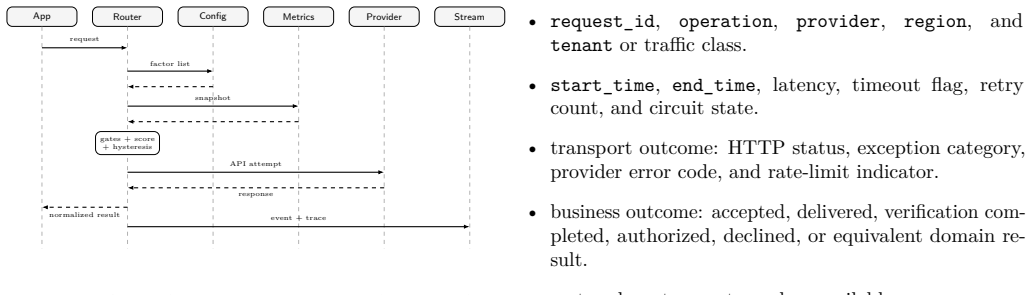
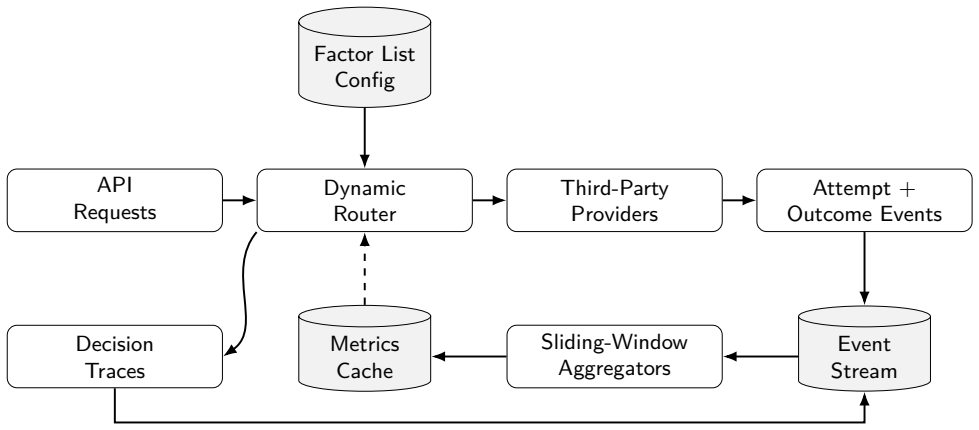
The authors present an architecture for resilient third-party service integration based on pluggable factor lists, real-time telemetry, circuit breakers, bulkhead isolation, and a closed-loop decision engine. A factor list defines operation-specific hard gates and weighted scoring functions that evaluate candidate providers using live metrics, regional policy constraints, quota state, latency, cost, and incident signals. The router separates routing policy from application code, allowing operators to adapt vendor selection at runtime without redeploying applications. They formalize the factor-list model, describe a request-time routing algorithm, present the event pipeline that computes slid
What carries the argument
The factor list, which encodes operation-specific hard gates and weighted scoring functions evaluated against live telemetry to select providers at request time.
If this is right
- Routing policy updates become configuration changes rather than code deployments.
- Manual vendor switching is replaced by automated decisions driven by completion-rate and other telemetry.
- Failover behavior can be analyzed and tuned through the event pipeline for sliding-window metrics.
- Application code remains unchanged while providers are added, removed, or reweighted at runtime.
Where Pith is reading between the lines
- The same factor-list structure could be applied to non-API selections such as database replicas or cloud regions if comparable telemetry exists.
- Adding cost or carbon signals to the scoring functions would let operators optimize for objectives beyond pure resilience.
- Integration with existing monitoring systems would be required for the telemetry pipeline to remain low-latency in large deployments.
Load-bearing premise
Live telemetry and operator-defined factor lists will produce accurate, timely provider health signals that the closed-loop engine can act on without introducing new failure modes or excessive latency.
What would settle it
A production trace showing continued routing to a provider during a documented regional outage because telemetry updates lagged or scoring produced an incorrect ranking.
Figures

read the original abstract
Modern online services rely on third-party APIs for authentication, payments, communication, identity verification, fraud detection, observability, and fulfillment. These dependencies are outside the direct operational control of the application owner and may experience regional outages, throttling, latency spikes, quota exhaustion, or behavior changes that surface as user-visible failures. This paper presents configuration-driven dynamic API routing, an architecture for resilient third-party service integration based on pluggable factor lists, real-time telemetry, circuit breakers, bulkhead isolation, and a closed-loop decision engine. A factor list defines operation-specific hard gates and weighted scoring functions that evaluate candidate providers using live metrics, regional policy constraints, quota state, latency, cost, and incident signals. The router separates routing policy from application code, allowing operators to adapt vendor selection at runtime without redeploying applications. We formalize the factor-list model, describe a request-time routing algorithm, present the event pipeline that computes sliding-window provider health metrics, and analyze failover behavior under degraded-provider scenarios. We also describe an anonymized SMS verification case study in which manual vendor switching was replaced by automated routing driven by completion-rate telemetry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present configuration-driven dynamic API routing, an architecture for resilient third-party service integration. It is based on pluggable factor lists defining operation-specific hard gates and weighted scoring functions evaluated against live metrics (latency, cost, quota, incidents), real-time telemetry, circuit breakers, bulkhead isolation, and a closed-loop decision engine. The router decouples routing policy from application code for runtime adaptation. The manuscript formalizes the factor-list model, describes a request-time routing algorithm, presents an event pipeline for sliding-window provider health metrics, analyzes failover behavior under degraded scenarios, and includes an anonymized SMS verification case study replacing manual vendor switching with automated, telemetry-driven routing.
Significance. If the claims hold, this architecture could offer a practical, operator-configurable approach to improving resilience in API-dependent services by enabling dynamic provider selection without code changes or redeployments. The emphasis on factor lists, telemetry pipelines, and closed-loop control could influence design patterns in distributed systems and microservices, particularly for high-availability applications relying on external providers.
major comments (2)
- [Failover analysis section] Failover analysis section: The analysis of failover behavior under degraded-provider scenarios is described at a high level but supplies no quantitative data, error analysis, formal invariants, model checking, or controlled failure-injection results to quantify decision latency, misrouting rates, or correctness of the closed-loop decision engine. This directly undermines the central claim that the system correctly handles all degraded-provider scenarios without introducing new failure modes.
- [Case study section] Case study section: The SMS verification case study describes the replacement of manual vendor switching by automated routing driven by completion-rate telemetry but reports no before/after metrics, error rates, latency measurements, or validation of the routing decisions, leaving the practical benefits as an unverified assertion rather than a demonstrated property.
minor comments (2)
- The abstract states that the factor-list model is formalized, but the manuscript provides no explicit equations, definitions, or pseudocode for the weighted scoring functions or hard gates, making the formalization difficult to evaluate or reproduce.
- Notation for the sliding-window metrics pipeline and request-time routing algorithm is introduced without clear definitions or examples of how factor weights are combined at runtime.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the failover analysis and case study sections would be strengthened by additional quantitative evidence. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Failover analysis section] Failover analysis section: The analysis of failover behavior under degraded-provider scenarios is described at a high level but supplies no quantitative data, error analysis, formal invariants, model checking, or controlled failure-injection results to quantify decision latency, misrouting rates, or correctness of the closed-loop decision engine. This directly undermines the central claim that the system correctly handles all degraded-provider scenarios without introducing new failure modes.
Authors: We agree that the current failover analysis is qualitative and high-level. This is a genuine limitation in the submitted manuscript. In the revised version we will add results from controlled failure-injection experiments, including measured decision latencies, observed misrouting rates, and validation of the closed-loop engine against the stated invariants. We will also include a short formalization of the key safety properties. revision: yes
-
Referee: [Case study section] Case study section: The SMS verification case study describes the replacement of manual vendor switching by automated routing driven by completion-rate telemetry but reports no before/after metrics, error rates, latency measurements, or validation of the routing decisions, leaving the practical benefits as an unverified assertion rather than a demonstrated property.
Authors: We acknowledge that the case study currently offers only a descriptive account without supporting metrics. Because the study is anonymized under confidentiality constraints, detailed before/after numbers cannot be released. In revision we will (a) clarify that the section is intended as an illustrative deployment example rather than a full empirical evaluation and (b) add any aggregated, non-identifying telemetry summaries that can be safely disclosed. This will be a partial revision. revision: partial
Circularity Check
No circularity; architecture description is self-contained
full rationale
The paper describes a configuration-driven routing architecture, formalizes a factor-list model, presents a request-time algorithm, an event pipeline for metrics, and failover analysis. No equations, fitted parameters, derivations, or self-citations appear in the abstract or visible text that could reduce any claim to its own inputs by construction. The central claims concern design separation of policy from code and automated routing based on telemetry; these are presented as engineering choices rather than mathematical predictions. Per the rules, absence of any quotable reduction to self-definition or fitted-input-as-prediction yields score 0. The skeptic concerns address verification gaps, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. T. Nygard.Release It! Design and Deploy Production-Ready Software. Pragmatic Bookshelf, 2nd edition, 2018
2018
-
[2]
Beyer, C
B. Beyer, C. Jones, J. Petoff, and N. R. Murphy, ed- itors.Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016
2016
-
[3]
Dean and L
J. Dean and L. A. Barroso. The tail at scale.Commu- nications of the ACM, 56(2):74–80, 2013
2013
-
[4]
Kreps, N
J. Kreps, N. Narkhede, and J. Rao. Kafka: A dis- tributed messaging system for log processing. InPro- ceedings of the NetDB Workshop, 2011
2011
-
[5]
D. E. Eisenbud, C. Yi, C. Contavalli, C. Smith, R. Kononov, E. Mann-Hielscher, A. Cilingiroglu, B. Cheyney, W. Shang, and J. D. Hosein. Maglev: A fast and reliable software network load balancer. In13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), pages 523–535, 2016
2016
-
[6]
Karger, E
D. Karger, E. Lehman, T. Leighton, M. Levine, D. Lewin, and R. Panigrahy. Consistent hashing and ran- dom trees: Distributed caching protocols for relieving hot spots on the World Wide Web. InProceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, pages 654–663, 1997
1997
-
[7]
J. O. Kephart and D. M. Chess. The vision of auto- nomic computing.Computer, 36(1):41–50, 2003. 11
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.