Anchored, Not Graded: Vision-Language Models Fail at Slant-from-Texture Perception
Pith reviewed 2026-07-02 22:54 UTC · model grok-4.3
The pith
Vision-language models anchor slant-from-texture predictions to a few discrete angles instead of producing graded outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
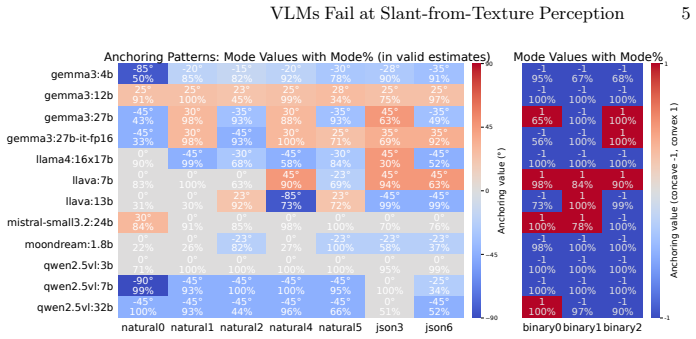
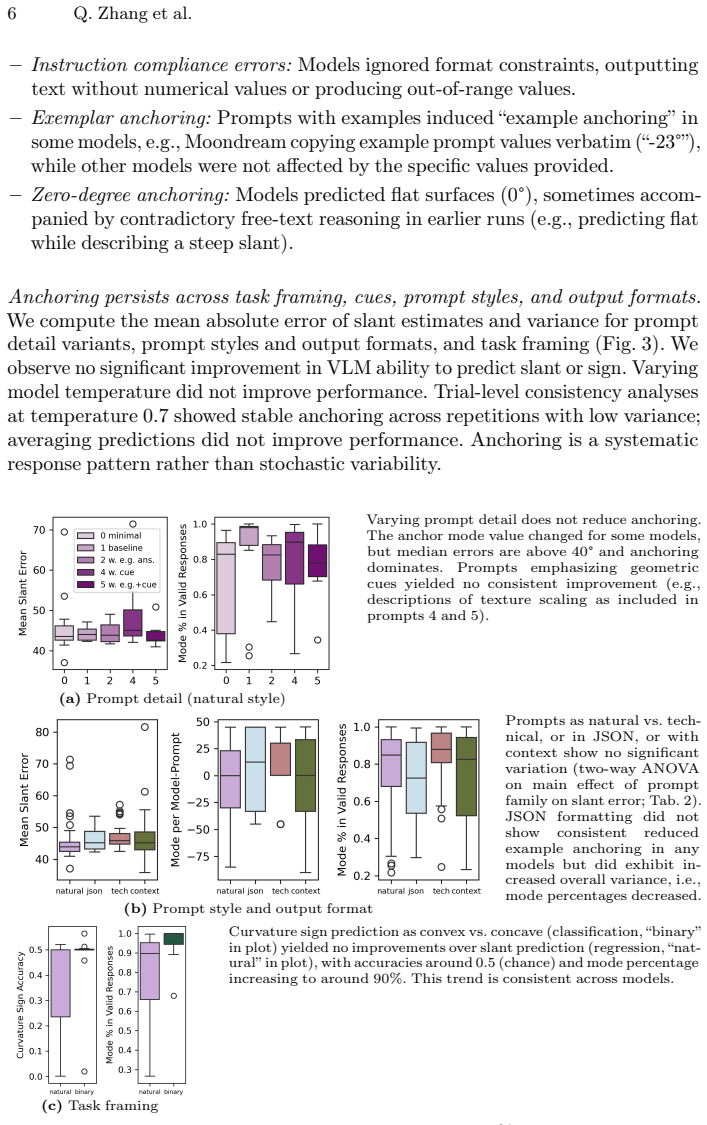
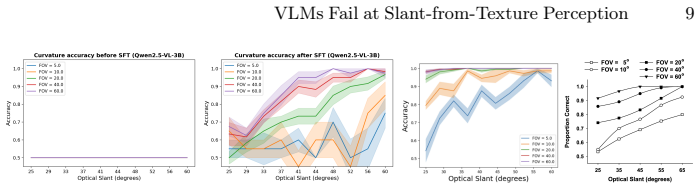
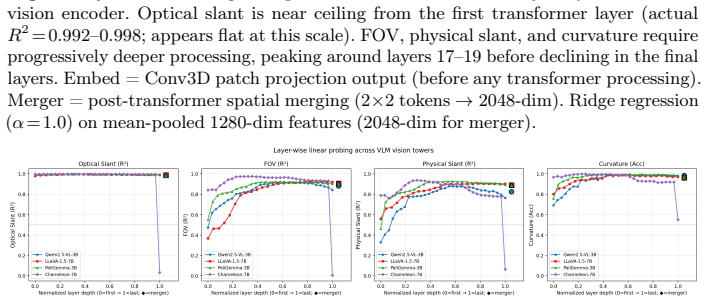
Across VLM families and scales, zero-shot and in-context prompting both produce slant predictions restricted to a small set of anchors (0°, ±25°, ±45°) that show little dependence on stimulus field of view, optical slant, or surface curvature; supervised fine-tuning partially remediates the failure but residual anchoring persists.
What carries the argument
Anchoring effect, in which slant outputs collapse to discrete fixed values independent of continuous changes in the texture stimulus.
If this is right
- High-level vision-language benchmarks can be solved without sensitivity to low-level geometric cues such as slant.
- The observed failure occurs at the representation-to-output language interface rather than from missing geometric encoding.
- Supervised fine-tuning on slant tasks can reduce but does not remove the anchoring pattern.
- This pattern differs from unsupervised CNNs, which reproduce several human-like graded biases on the same stimuli.
Where Pith is reading between the lines
- Training regimes that explicitly penalize discrete output distributions might be needed to elicit graded geometric judgments from VLMs.
- Applications requiring precise surface orientation estimates, such as robotic grasping or augmented reality overlays, may encounter systematic errors traceable to this anchoring.
- Similar anchoring could appear in other continuous perceptual dimensions (e.g., depth or curvature) when VLMs are asked to verbalize them.
Load-bearing premise
The chosen zero-shot and in-context prompting methods are sufficient to reveal the models' underlying perceptual representations rather than merely reflecting output formatting or language interface constraints.
What would settle it
A test in which the same VLM is shown identical slant-from-texture stimuli but asked to output a continuous numeric angle or to adjust a graded visual response, checking whether the output still collapses to the same small set of anchors.
Figures
















read the original abstract
Human perception of surface slant from texture exhibits systematic, graded biases that emerge reliably in psychophysical experiments. Prior work showed that unsupervised CNNs reproduce several human-like biases, while supervised CNNs do not. Do Vision-Language Models (VLMs) exhibit similar competences? Across multiple VLM families and model scales, zero-shot and in-context prompting both produce distinctive failures: slant is predicted at only a small set of anchors (e.g., 0\degree, $\pm$25\degree, $\pm$45\degree) with little dependence on stimulus field of view, optical slant, or surface curvature. Supervised fine-tuning partially remediates the failure, but residual anchoring persists. While success in high-level vision-language benchmarks might not require sensitivity to low-level geometric cues, we interpret anchoring as a failure at the representation-to-output language interface: not necessarily an absence of geometric encoding, but a failure to express it in a graded form.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision-language models (VLMs) across families and scales fail to produce graded slant estimates from texture, instead anchoring predictions to discrete values (0°, ±25°, ±45°) with little sensitivity to field of view, optical slant, or curvature under zero-shot and in-context prompting. Supervised fine-tuning partially reduces but does not eliminate anchoring. The authors interpret this as a representation-to-output interface failure rather than absent geometric encoding.
Significance. If the empirical pattern holds, the work usefully extends prior CNN findings on slant-from-texture to VLMs and underscores that high-level VLM benchmarks may not require low-level geometric competence. Strengths include the multi-model, multi-scale design and explicit discussion of the language-interface alternative. The result could motivate targeted improvements in how VLMs express continuous visual quantities.
major comments (2)
- [Abstract] Abstract and Discussion: the central claim of a 'failure at slant-from-texture perception' rests on the tested prompting regimes being sufficient to surface graded representations. Without experiments using alternative elicitation (direct numerical regression, chain-of-thought, or internal readout), the observed anchors remain compatible with intact internal encoding that standard language output cannot express continuously.
- [Results] Results section: the repeated claim of 'little dependence' on FOV, optical slant, and curvature requires quantitative support (e.g., correlation values or statistical tests) rather than qualitative description; without these, the distinctiveness of the anchoring pattern relative to stimulus variation is difficult to evaluate.
minor comments (2)
- Figure captions should explicitly label the stimulus parameters varied in each panel to allow readers to verify the independence claims.
- The abstract's LaTeX notation (\degree) should be rendered consistently as ° in the published version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate quantitative analyses and additional experiments where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract and Discussion: the central claim of a 'failure at slant-from-texture perception' rests on the tested prompting regimes being sufficient to surface graded representations. Without experiments using alternative elicitation (direct numerical regression, chain-of-thought, or internal readout), the observed anchors remain compatible with intact internal encoding that standard language output cannot express continuously.
Authors: Our manuscript already frames the anchoring as potentially reflecting a representation-to-output interface failure rather than absent geometric encoding. The persistence of discrete anchors across both zero-shot and in-context prompting regimes is consistent with this interpretation. We agree that further elicitation methods would strengthen the evidence and will add chain-of-thought prompting experiments in the revision. Direct numerical regression can also be tested; internal readout is not straightforward for the black-box VLMs studied but will be noted as a limitation. revision: yes
-
Referee: [Results] Results section: the repeated claim of 'little dependence' on FOV, optical slant, and curvature requires quantitative support (e.g., correlation values or statistical tests) rather than qualitative description; without these, the distinctiveness of the anchoring pattern relative to stimulus variation is difficult to evaluate.
Authors: We agree that the claims require quantitative backing. The revised manuscript will include correlation coefficients, regression models, and statistical tests (such as ANOVA) to measure dependence on FOV, optical slant, and curvature, allowing a clearer assessment of how the anchoring pattern stands out from stimulus variation. revision: yes
Circularity Check
No circularity: purely empirical evaluation of model outputs
full rationale
The paper reports direct empirical observations of VLM outputs under zero-shot and in-context prompting on slant-from-texture stimuli. No equations, fitted parameters, or derivations are present that could reduce any claim to its inputs by construction. The central claim rests on measured anchoring patterns across model families, with explicit acknowledgment of alternative interpretations (representation-to-output interface). No self-citation chains or ansatzes are invoked as load-bearing support. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompting methods can elicit perceptual judgments from VLMs in a manner comparable to human psychophysics
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Alain, G., Bengio, Y.: Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Large language model (2026),https://claude.ai/, accessed: 2026-05-11
Anthropic: Claude model (may 2026 version) [large language model]. Large language model (2026),https://claude.ai/, accessed: 2026-05-11
2026
-
[3]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
PaliGemma: A versatile 3B VLM for transfer
Beyer*,L.,Steiner*,A.,Pinto*,A.S.,Kolesnikov*,A.,Wang*,X.,Salz,D.,Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Keysers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Bošnjak, M., Chen, X., Minderer, M., Voigtlaender, P., Bica, I., Balazevic...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: 2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA)
Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., Zhao, B.: Spatialbot: Precise spatial understanding with vision language models. In: 2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA). pp. 9490–9498. IEEE (2025)
2025
-
[6]
Journal of Vision20(7), 14–14 (2020)
Chen, Z., Saunders, J.A.: Multiple texture cues are integrated for perception of 3d slant from texture. Journal of Vision20(7), 14–14 (2020)
2020
-
[7]
Advances in Neural Information Processing Systems37, 135062–135093 (2024)
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems37, 135062–135093 (2024)
2024
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Danier, D., Aygun, M., Li, C., Bilen, H., Mac Aodha, O.: Depthcues: Evaluating monocular depth perception in large vision models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20049–20059 (2025)
2025
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy,A.,Beyer,L.,Kolesnikov,A.,Weissenborn,D.,Zhai,X.,Unterthiner,T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Advances in neural information processing systems27 (2014)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems27 (2014)
2014
-
[11]
arXiv preprint arXiv:2312.11370 (2023)
Gao, J., Pi, R., Zhang, J., Ye, J., Zhong, W., Wang, Y., Hong, L., Han, J., Xu, H., Li, Z., et al.: G-llava: Solving geometric problem with multi-modal large language model. arXiv preprint arXiv:2312.11370 (2023)
-
[12]
In: Proceedings of the IEEE/CVF international conference on computer vision
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3828–3838 (2019)
2019
-
[13]
Vision research9(9), 1079–1094 (1969)
Gogel, W.C.: The sensing of retinal size. Vision research9(9), 1079–1094 (1969)
1969
-
[14]
com/deepmind- media/Model-Cards/Gemini-3-1-Flash- Lite- Model- Card.pdf , accessed: 2026-05-11
Google: Gemini 3.1 flash-lite model card (2026),https://storage.googleapis. com/deepmind- media/Model-Cards/Gemini-3-1-Flash- Lite- Model- Card.pdf , accessed: 2026-05-11
2026
-
[15]
In: Findings of the Association for Computational Linguistics: ACL 2025
Huang, K.H., Qin, C., Qiu, H., Laban, P., Joty, S., Xiong, C., Wu, C.S.: Why vision language models struggle with visual arithmetic? towards enhanced chart and geometry understanding. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 4830–4843 (2025)
2025
-
[16]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) VLMs Fail at Slant-from-Texture Perception 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., et al.: Gemma 3 technical report. arXiv preprint arXiv:2503.197864(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Artificial Intelligence38(1), 1–48 (1989)
Kanatani, K.i., Chou, T.C.: Shape from texture: General principle. Artificial Intelligence38(1), 1–48 (1989)
1989
-
[19]
Kemp, J.T., Vishwanath, D., Domini, F.: Sensory uncertainty does not drive perceptual discriminability in 3d vision (2024)
2024
-
[20]
Vision research38(11), 1655–1682 (1998)
Knill, D.C.: Surface orientation from texture: ideal observers, generic observers and the information content of texture cues. Vision research38(11), 1655–1682 (1998)
1998
-
[21]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Liu, A.H., Khandelwal, K., Subramanian, S., Jouault, V., Rastogi, A., Sadé, A., Jeffares, A., Jiang, A., Cahill, A., Gavaudan, A., et al.: Ministral 3. arXiv preprint arXiv:2601.08584 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Transactions of the Association for Computational Linguistics11, 635–651 (2023)
Liu, F., Emerson, G., Collier, N.: Visual spatial reasoning. Transactions of the Association for Computational Linguistics11, 635–651 (2023)
2023
-
[24]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024)
2024
-
[25]
Journal of Computational Social Science9(1), 11 (2026)
Lou, J., Sun, Y.: Anchoring bias in large language models: An experimental study. Journal of Computational Social Science9(1), 11 (2026)
2026
-
[26]
In: International Conference on Learning Representations (ICLR) (2024)
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[27]
https://github.com/huggingface/peft(2022)
Mangrulkar, S., Gugger, S., Debut, L., Belkada, Y., Paul, S., Bossan, B., Tietz, M.: PEFT: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft(2022)
2022
-
[28]
Meta AI blog post, https : //ai.meta.com/blog/llama-4-multimodal-intelligence/, accessed: 2026-03-04
Meta: Llama 4 multimodal intelligence. Meta AI blog post, https : //ai.meta.com/blog/llama-4-multimodal-intelligence/, accessed: 2026-03-04
2026
-
[29]
GitHub repository, https://github.com/vikhyat/ moondream, accessed: 2026-03-04
Moondream: Moondream. GitHub repository, https://github.com/vikhyat/ moondream, accessed: 2026-03-04
2026
-
[30]
Website,https://docs.ollama
Ollama: Ollama (software and documentation). Website,https://docs.ollama. com/, accessed: 2026-03-04
2026
-
[31]
OpenAI: Chatgpt (march 2026 version) [large language model] (2026), https://chat.openai.com, accessed: 2026-05-11
2026
-
[32]
Vision research43(23), 2451–2468 (2003)
Oruç, I., Maloney, L.T., Landy, M.S.: Weighted linear cue combination with possibly correlated error. Vision research43(23), 2451–2468 (2003)
2003
-
[33]
Qwen Team: Qwen2.5-vl technical report. arXiv (2025).https://doi.org/10. 48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026), https://qwen.ai/blog?id=qwen3.5
2026
-
[35]
Qwen Team: Qwen3.6-35B-A3B: Agentic coding power, now open to all (April 2026), https://qwen.ai/blog?id=qwen3.6-35b-a3b
2026
-
[36]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 18 Q. Zhang et al
2021
-
[37]
In: Proceedings of the Asian Conference on Computer Vision
Rahmanzadehgervi, P., Bolton, L., Taesiri, M.R., Nguyen, A.T.: Vision language models are blind. In: Proceedings of the Asian Conference on Computer Vision. pp. 18–34 (2024)
2024
-
[38]
Vision Research44(13), 1511–1535 (2004)
Rosas, P., Wichmann, F.A., Wagemans, J.: Some observations on the effects of slant and texture type on slant-from-texture. Vision Research44(13), 1511–1535 (2004)
2004
-
[39]
Mechanisms of Prompt-Induced Hallucination in Vision-Language Models
Rudman, W., Golovanevsky, M., Arad, D., Belinkov, Y., Singh, R., Eickhoff, C., Mahowald, K.: Mechanisms of prompt-induced hallucination in vision-language models. arXiv preprint arXiv:2601.05201 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
In: Findings of the Association for Computational Linguistics: ACL 2025
Rudman,W.,Golovanevsky,M.,Bar,A.,Palit,V.,LeCun,Y.,Eickhoff,C.,Singh,R.: Forgotten polygons: Multimodal large language models are shape-blind. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 11983–11998 (2025)
2025
-
[41]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C.: Chameleon: Mixed-modal early-fusion foundation models. arXiv preprint arXiv:2405.09818 (2024).https://doi.org/10.48550/arXiv.2405.09818, https://github.com/facebookresearch/chameleon
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.09818 2024
-
[42]
Journal of vision10(5), 17–17 (2010)
Todd, J.T., Thaler, L.: The perception of 3d shape from texture based on directional width gradients. Journal of vision10(5), 17–17 (2010)
2010
-
[43]
Vision Research45(12), 1501–1517 (2005)
Todd, J.T., Thaler, L., Dijkstra, T.M.: The effects of field of view on the perception of 3d slant from texture. Vision Research45(12), 1501–1517 (2005)
2005
-
[44]
Journal of vision7(12), 9–9 (2007)
Todd, J.T., Thaler, L., Dijkstra, T.M., Koenderink, J.J., Kappers, A.M.: The effects of viewing angle, camera angle, and sign of surface curvature on the perception of three-dimensional shape from texture. Journal of vision7(12), 9–9 (2007)
2007
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578 (2024)
2024
-
[46]
arXiv preprint arXiv:2510.25776 (2025)
Tseng, C.Y., Roy, S., Thasin, M., Zhang, D., Effiong, B.: Streetmath: Study of llms’ approximation behaviors. arXiv preprint arXiv:2510.25776 (2025)
-
[47]
In: ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpatternrecognition
Verbin, D., Zickler, T.: Toward a universal model for shape from texture. In: ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpatternrecognition. pp. 422–430 (2020)
2020
-
[48]
Vision Language Models are Biased
Vo, A., Nguyen, K.N., Taesiri, M.R., Dang, V.T., Nguyen, A.T., Kim, D.: Vision language models are biased. arXiv preprint arXiv:2505.23941 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
ACM Transactions on Applied Perception20(4), 1–18 (2023)
Wang, Y., Zhang, Q., Aubuchon, C., Kemp, J., Domini, F., Tompkin, J.: On human-like biases in convolutional neural networks for the perception of slant from texture. ACM Transactions on Applied Perception20(4), 1–18 (2023)
2023
-
[51]
Artificial intelligence17(1-3), 17–45 (1981)
Witkin, A.P.: Recovering surface shape and orientation from texture. Artificial intelligence17(1-3), 17–45 (1981)
1981
-
[52]
Corpus Linguistics and Linguistic Theory20(1), 123–152 (2024)
Woodin, G., Winter, B., Littlemore, J., Perlman, M., Grieve, J.: Large-scale patterns of number use in spoken and written english. Corpus Linguistics and Linguistic Theory20(1), 123–152 (2024)
2024
-
[53]
Yang,L.,Kang,B.,Huang,Z.,Xu,X.,Feng,J.,Zhao,H.:Depthanything:Unleashing thepoweroflarge-scaleunlabeleddata.In:ProceedingsoftheIEEE/CVFconference on computer vision and pattern recognition. pp. 10371–10381 (2024)
2024
-
[54]
arXiv preprint arXiv:2509.18905 (2025)
Yu,S.,Chen,Y.,Ju,H.,Jia,L.,Zhang,F.,Huang,S.,Wu,Y.,Cui,R.,Ran,B.,Zhang, Z., et al.: How far are vlms from visual spatial intelligence? a benchmark-driven perspective. arXiv preprint arXiv:2509.18905 (2025)
-
[55]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W.,Sun,Y.,etal.:Mmmu:Amassivemulti-disciplinemultimodalunderstandingand VLMs Fail at Slant-from-Texture Perception 19 reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9556–9567 (2024)
2024
-
[56]
2022 ieee
Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., Beyer, L.: Lit: Zero-shot transfer with locked-image text tuning. 2022 ieee. In: CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18102–18112 (2021)
2022
-
[57]
IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024)
Zhang, J., Huang, J., Jin, S., Lu, S.: Vision-language models for vision tasks: A survey. IEEE transactions on pattern analysis and machine intelligence46(8), 5625–5644 (2024)
2024
-
[58]
Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.W., Qiao, Y., et al.: Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? In: European Conference on Computer Vision. pp. 169–186. Springer (2024)
2024
-
[59]
EMNLP 2023 (2023)
Zhang,Y.,Pan,J.,Zhou,Y.,Pan,R.,Chai,J.:Groundingvisualillusionsinlanguage: Do vision-language models perceive illusions like humans? In: Proceedings of Con- ference of Empirical Methods in Natural Language Processing. EMNLP 2023 (2023)
2023
-
[60]
judged slant
Zhang, Y., Unell, A., Wang, X., Ghosh, D., Su, Y., Schmidt, L., Yeung-Levy, S.: Why are visually-grounded language models bad at image classification? Advances in Neural Information Processing Systems37, 51727–51753 (2024) VLMs Fail at Slant-from-Texture Perception 1 1 Recent models We also found anchoring in 12 frontier VLMs, including closed source ones...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.