Beyond NL2Code: A Structured Survey of Multimodal Code Intelligence
Pith reviewed 2026-06-27 03:53 UTC · model grok-4.3
The pith
Multimodal code intelligence connects visual inputs such as screenshots to executable programs whose correctness hinges on layout, semantics, and post-execution behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
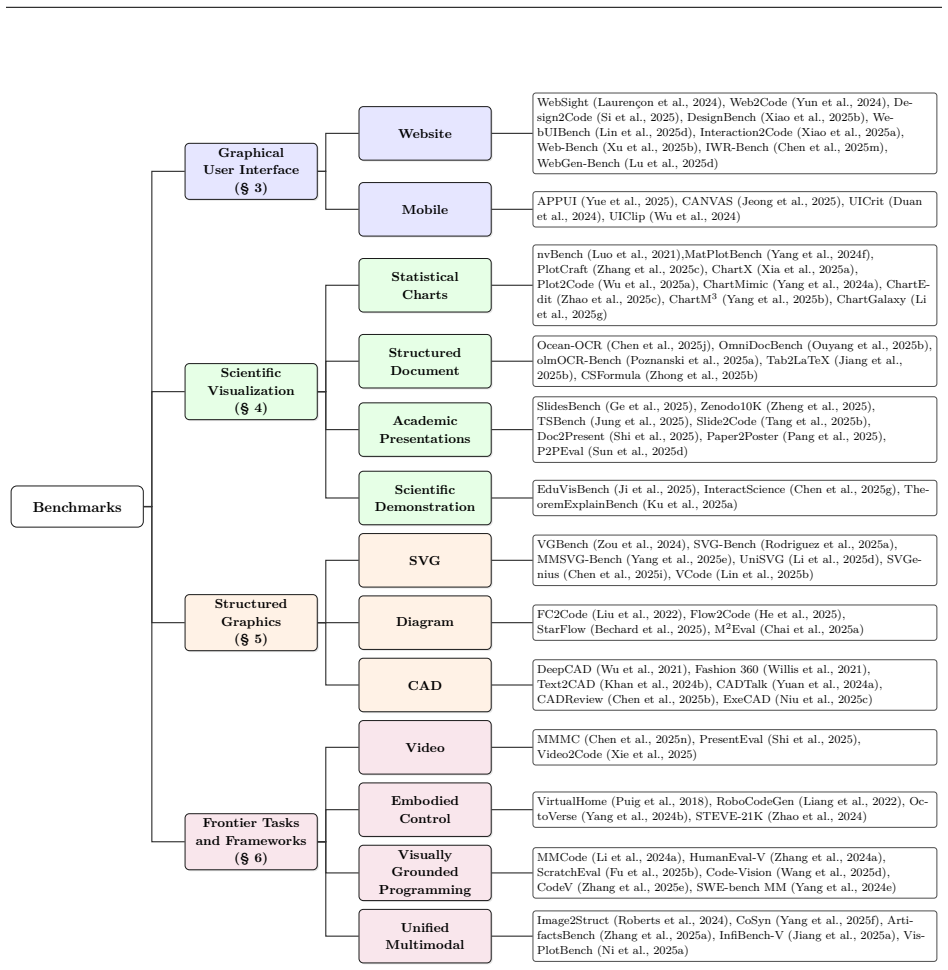
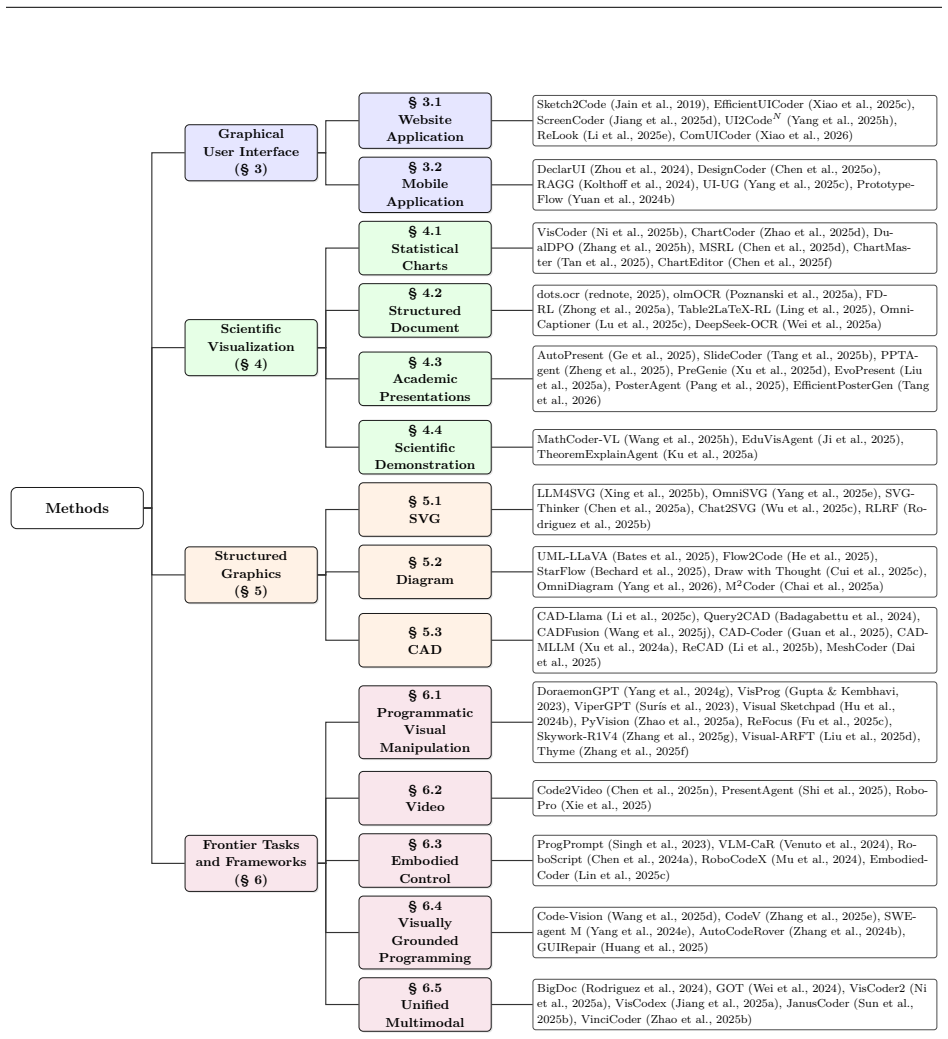
We first formulate the field by the role that code plays in each task, distinguishing code as a rendered artifact, an editable symbolic structure, a scientific representation, an intermediate reasoning trace, or an executable policy or tool interface. We then organize benchmarks and methods into four domains: Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks. This taxonomy connects mature artifact-generation problems to emerging agentic and unified settings and allows us to compare how different tasks treat evidence of correctness. Looking ahead, we argue that future research may benefit from four verification-centered directions: mult
What carries the argument
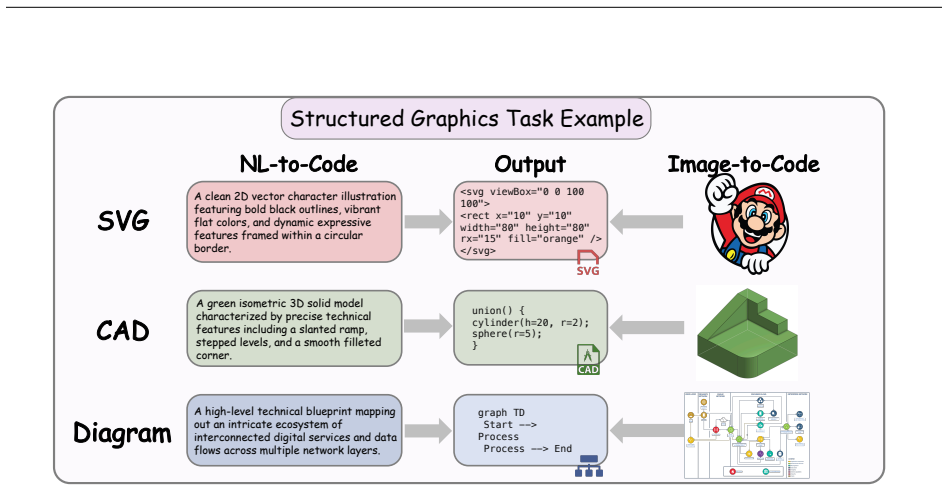
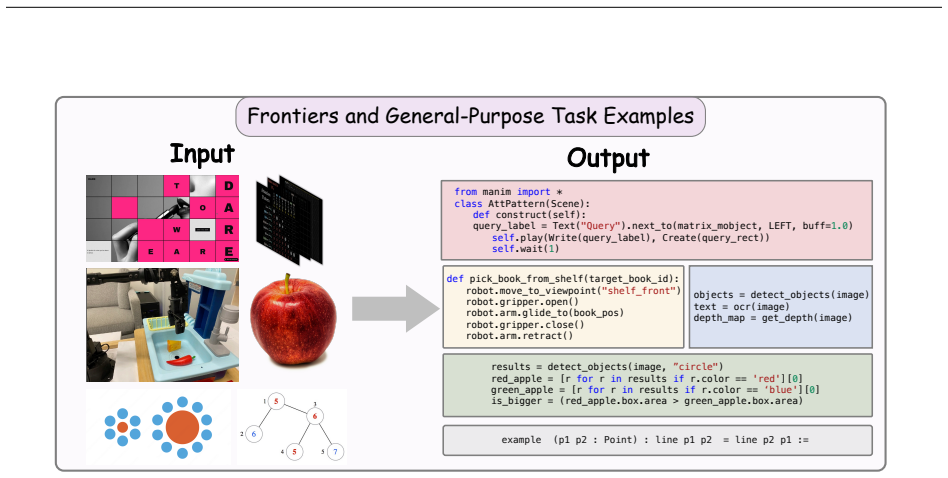
Taxonomy of code roles (rendered artifact, editable symbolic structure, scientific representation, intermediate reasoning trace, executable policy or tool interface) paired with four domains (GUI, Scientific Visualization, Structured Graphics, Frontier Tasks and Frameworks) that structures comparison of correctness evidence across visual-to-code tasks.
If this is right
- Multi-signal validation combines complementary evidence of correctness from different sources.
- Multi-state verification tests program behavior across full execution trajectories rather than single outputs.
- Cross-task transfer testing measures whether visual-code skills learned in one domain transfer to others.
- Verifiable agent traces determine whether an agent's actions remain grounded in the visual evidence provided.
Where Pith is reading between the lines
- The same taxonomy could be used to design shared evaluation protocols that report multiple forms of correctness evidence rather than single metrics.
- Agent frameworks that already produce execution traces could be retrofitted with visual grounding checks without requiring entirely new architectures.
- Transfer testing across the four domains might reveal whether low-level visual parsing skills learned on GUI tasks generalize to scientific visualization problems.
Load-bearing premise
The taxonomy organized by code role and four domains successfully links established artifact-generation problems to newer agentic settings while permitting direct comparison of correctness evidence across tasks.
What would settle it
An empirical study that applies the taxonomy to a broad set of benchmarks and finds that correctness evidence types do not align with the proposed code roles or that the four domains fail to separate key distinctions in agent behavior.
Figures


read the original abstract
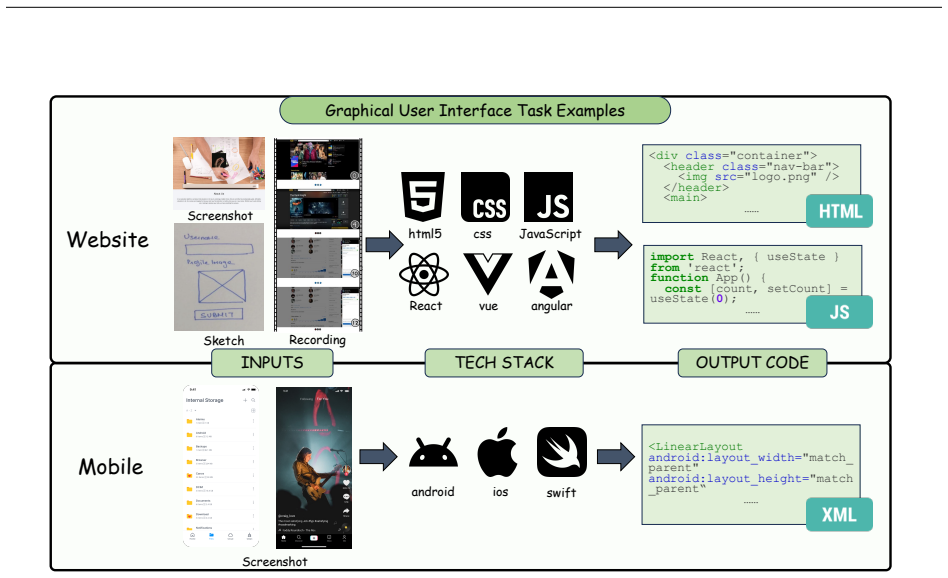
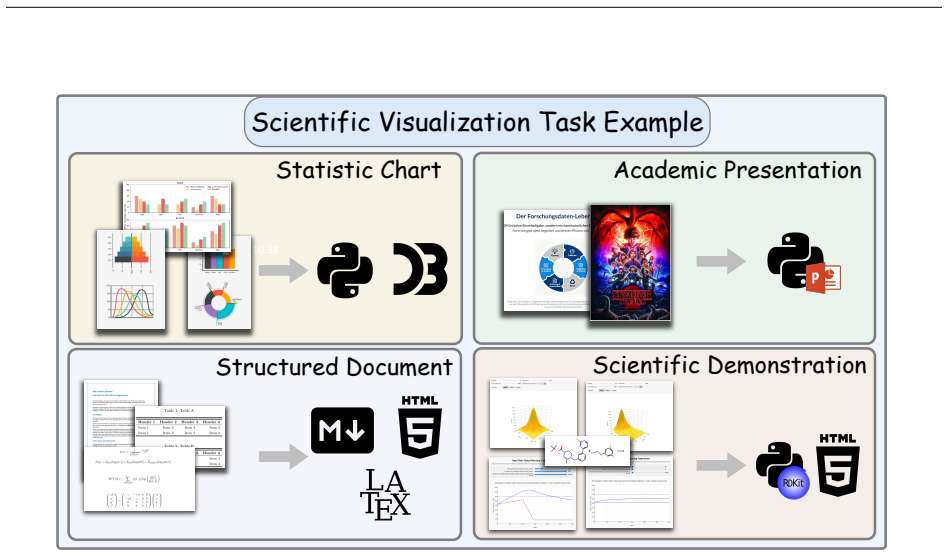
While Large Language Models (LLMs) have substantially advanced text-to-code synthesis, many real programming tasks specify intent through visual artifacts such as screenshots, charts, vector drawings, videos, and interactive states. These tasks require models to connect visual perception to executable programs, because correctness depends not only on syntax but also on layout, data semantics, interaction behavior, and domain-specific constraints that apply after execution. This survey examines Multimodal Code Intelligence, covering systems that generate, edit, refine, or reason with code under visually grounded inputs and outputs. We first formulate the field by the role that code plays in each task, distinguishing code as a rendered artifact, an editable symbolic structure, a scientific representation, an intermediate reasoning trace, or an executable policy or tool interface. We then organize benchmarks and methods into four domains: Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks. This taxonomy connects mature artifact-generation problems to emerging agentic and unified settings and allows us to compare how different tasks treat evidence of correctness. Looking ahead, we argue that future research may benefit from four verification-centered directions. Multi-signal validation can combine complementary evidence of correctness, multi-state verification can test behavior across execution trajectories, cross-task transfer testing can probe reusable visual-code skills, and verifiable agent traces can reveal whether agent actions are grounded in visual evidence. Together, these directions may move this field from single-output imitation toward evidence-grounded executable systems. An ongoing project and resources are available on \href{https://github.com/xjywhu/Awesome-Multimodal-LLM-for-Code}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a structured survey of Multimodal Code Intelligence. It formulates the field according to the role code plays in each task (rendered artifact, editable symbolic structure, scientific representation, intermediate reasoning trace, or executable policy/tool interface) and organizes benchmarks and methods into four domains (Graphical User Interface, Scientific Visualization, Structured Graphics, and Frontier Tasks and Frameworks). The paper concludes by proposing four verification-centered directions for future work: multi-signal validation, multi-state verification, cross-task transfer testing, and verifiable agent traces, with an accompanying GitHub repository of resources.
Significance. If the taxonomy is adopted, the survey supplies a coherent organizational lens that links established artifact-generation problems to emerging agentic and unified multimodal settings while enabling cross-task comparison of correctness evidence. The public GitHub repository constitutes a concrete strength by supporting reproducibility and community extension of the survey.
minor comments (1)
- [Abstract] The abstract states that resources are available on GitHub but the main text does not include a dedicated resources section or explicit selection criteria for the surveyed works, which would aid readers in assessing coverage.
Simulated Author's Rebuttal
We thank the referee for the thorough and positive review. We are pleased that the taxonomy, domain organization, verification-centered directions, and GitHub repository were viewed as strengths, and we appreciate the recommendation to accept.
Circularity Check
No significant circularity
full rationale
This is a survey paper whose contribution is an organizational taxonomy of code roles and four domains plus four suggested verification directions. No equations, fitted parameters, predictions, or derivations appear anywhere in the manuscript. The taxonomy is introduced as a structuring device to connect literature rather than as a result derived from prior claims, and the forward directions are presented as potentially beneficial rather than validated outputs. No self-citation chains or definitional reductions are present; the work is self-contained as descriptive organization of external literature.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-05-30. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
Pith/arXiv arXiv 2026
-
[2]
Query2cad: Generating cad models using natural language queries.arXiv preprint arXiv:2406.00144,
Akshay Badagabettu, Sai Sravan Yarlagadda, and Amir Barati Farimani. Query2cad: Generating cad models using natural language queries.arXiv preprint arXiv:2406.00144,
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
-
[4]
Starflow: Generating structured workflow outputs from sketch images.arXiv preprint arXiv:2503.21889,
Patrice Bechard, Chao Wang, Amirhossein Abaskohi, Juan Rodriguez, Christopher Pal, David Vazquez, Spandana Gella, Sai Rajeswar, and Perouz Taslakian. Starflow: Generating structured workflow outputs from sketch images.arXiv preprint arXiv:2503.21889,
-
[5]
Jonas Belouadi, Anne Lauscher, and Steffen Eger. Automatikz: Text-guided synthesis of scientific vector graphics with tikz.arXiv preprint arXiv:2310.00367,
-
[6]
Alexandre Carlier, Martin Danelljan, Alexandre Alahi, and Radu Timofte
Accessed: 2025-12-10. Alexandre Carlier, Martin Danelljan, Alexandre Alahi, and Radu Timofte. Deepsvg: A hierarchical gen- erative network for vector graphics animation.Advances in Neural Information Processing Systems, 33: 16351–16361,
2025
-
[7]
Linzheng Chai, Jian Yang, Shukai Liu, Wei Zhang, Liran Wang, Ke Jin, Tao Sun, Congnan Liu, Chenchen Zhang, Hualei Zhu, et al. Multilingual multimodal software developer for code generation.arXiv preprint arXiv:2507.08719, 2025a. Mingxu Chai, Ziyu Shen, Chong Zhang, Yue Zhang, Xiao Wang, Shihan Dou, Jihua Kang, Jiazheng Zhang, and Qi Zhang. Docfusion: a un...
arXiv 2025
-
[8]
Svgthinker: Instruction-aligned and reasoning-driven text-to-svg generation
Hanqi Chen, Zhongyin Zhao, Ye Chen, Zhujin Liang, and Bingbing Ni. Svgthinker: Instruction-aligned and reasoning-driven text-to-svg generation. InProceedings of the 33rd ACM International Conference on Multimedia, pp. 11004–11012, 2025a. Jiali Chen, Xusen Hei, HongFei Liu, Yuancheng Wei, Zikun Deng, Jiayuan Xie, Yi Cai, and Li Qing. Cadreview: Automatical...
-
[9]
Nan Chen, Yuge Zhang, Jiahang Xu, Kan Ren, and Yuqing Yang
URL https://arxiv.org/abs/2107.03374. Nan Chen, Yuge Zhang, Jiahang Xu, Kan Ren, and Yuqing Yang. Viseval: A benchmark for data visual- ization in the era of large language models.IEEE Transactions on Visualization and Computer Graphics, 2024b. Qiaosheng Chen, Yang Liu, Lei Li, Kai Chen, Qipeng Guo, Gong Cheng, and Fei Yuan. Interactscience: Programmatic ...
-
[10]
Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery, 202...
-
[11]
Zijian Ding, Qinshi Zhang, Mohan Chi, and Ziyi Wang. Frontend diffusion: Empowering self-representation of junior researchers and designers through agentic workflows.arXiv preprint arXiv:2502.03788,
-
[12]
Peitong Duan, Chin-Yi Cheng, Gang Li, Bjoern Hartmann, and Yang Li
URLhttps://arxiv.org/abs/2510.11718. Peitong Duan, Chin-Yi Cheng, Gang Li, Bjoern Hartmann, and Yang Li. Uicrit: Enhancing automated design evaluation with a ui critique dataset. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, pp. 1–17,
-
[13]
Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
-
[14]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, et al. OCRBench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning.arXiv preprint arXiv:2501.00321, 2025a. Rao Fu, Ziyang Luo, Hongzhan Lin, Zhen Ye, and Jing Ma. Scratcheval: Are gpt-4o...
Pith/arXiv arXiv 2025
-
[15]
Yandong Guan, Xilin Wang, Ximing Xing, Jing Zhang, Dong Xu, and Qian Yu. Cad-coder: Text-to-cad generation with chain-of-thought and geometric reward.arXiv preprint arXiv:2505.19713,
-
[16]
Webcode2m: A real-world dataset for code generation from webpage designs
Yi Gui, Zhen Li, Yao Wan, Yemin Shi, Hongyu Zhang, Bohua Chen, Yi Su, Dongping Chen, Siyuan Wu, Xing Zhou, et al. Webcode2m: A real-world dataset for code generation from webpage designs. InProceedings of the ACM on Web Conference (WWW 2025), pp. 1834–1845,
2025
-
[17]
Iw-bench: Evaluating large multimodal models for converting image-to-web
Hongcheng Guo, Wei Zhang, Junhao Chen, Yaonan Gu, Jian Yang, Junjia Du, Shaosheng Cao, Binyuan Hui, Tianyu Liu, Jianxin Ma, et al. Iw-bench: Evaluating large multimodal models for converting image-to-web. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 6449–6466, 2025a. Lianghong Guo, Wei Tao, Runhan Jiang, Yanlin Wang, Jiachi C...
arXiv 2025
-
[18]
Chartllama: A multimodal llm for chart understanding and generation.arXiv preprint arXiv:2311.16483,
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. Chartllama: A multimodal llm for chart understanding and generation.arXiv preprint arXiv:2311.16483,
-
[19]
Mengliang He, Jiayi Zeng, Yankai Jiang, Wei Zhang, Zeming Liu, Xiaoming Shi, and Aimin Zhou. Flow2code: Evaluating large language models for flowchart-based code generation capability.arXiv preprint arXiv:2506.02073,
-
[20]
Distill visual chart reasoning ability from llms to mllms.arXiv preprint arXiv:2410.18798,
Wei He, Zhiheng Xi, Wanxu Zhao, Xiaoran Fan, Yiwen Ding, Zifei Shan, Tao Gui, Qi Zhang, and Xuanjing Huang. Distill visual chart reasoning ability from llms to mllms.arXiv preprint arXiv:2410.18798,
-
[21]
Ahmed Heakl, Abdullah Sohail, Mukul Ranjan, Rania Hossam, Ghazi Shazan Ahmad, Mohamed El-Geish, Omar Maher, Zhiqiang Shen, Fahad Khan, and Salman Khan. KITAB-bench: A comprehensive multi- domain benchmark for arabic ocr and document understanding.arXiv preprint arXiv:2502.14949,
-
[22]
Xinhai Hou, Shaoyuan Xu, Manan Biyani, Mayan Li, Jia Liu, Todd C Hollon, and Bryan Wang. Codev: Code with images for faithful visual reasoning via tool-aware policy optimization.arXiv preprint arXiv:2511.19661,
-
[23]
Supersvg: Superpixel- based scalable vector graphics synthesis
Teng Hu, Ran Yi, Baihong Qian, Jiangning Zhang, Paul L Rosin, and Yu-Kun Lai. Supersvg: Superpixel- based scalable vector graphics synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24892–24901, 2024a. Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, a...
-
[24]
Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models
Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1911–1920,
1911
-
[25]
Doc2chart: Intent-driven zero-shot chart generation from documents
Akriti Jain, Pritika Ramu, Aparna Garimella, and Apoorv Saxena. Doc2chart: Intent-driven zero-shot chart generation from documents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 34936–34951,
2025
-
[26]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
-
[27]
Vanita Jain, Piyush Agrawal, Subham Banga, Rishabh Kapoor, and Shashwat Gulyani. Sketch2code: trans- formation of sketches to ui in real-time using deep neural network.arXiv preprint arXiv:1910.08930,
arXiv 1910
-
[28]
Daeheon Jeong, Seoyeon Byun, Kihoon Son, Dae Hyun Kim, and Juho Kim. Canvas: A benchmark for vision-language models on tool-based user interface design.arXiv preprint arXiv:2511.20737,
-
[29]
From eduvisbench to eduvisagent: A benchmark and multi-agent framework for reasoning-driven peda- gogical visualization
45 Haonian Ji, Shi Qiu, Siyang Xin, Siwei Han, Zhaorun Chen, Dake Zhang, Hongyi Wang, and Huaxiu Yao. From eduvisbench to eduvisagent: A benchmark and multi-agent framework for reasoning-driven peda- gogical visualization. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025,
2025
-
[30]
Caijun Jia, Nan Xu, Jingxuan Wei, Qingli Wang, Lei Wang, Bihui Yu, and Junnan Zhu. Chartreasoner: Code-driven modality bridging for long-chain reasoning in chart question answering.arXiv preprint arXiv:2506.10116,
-
[31]
Lingjie Jiang, Shaohan Huang, Xun Wu, Yixia Li, Dongdong Zhang, and Furu Wei. Viscodex: Unified multimodal code generation via merging vision and coding models.arXiv preprint arXiv:2508.09945, 2025a. Nan Jiang, Shanchao Liang, Chengxiao Wang, Jiannan Wang, and Lin Tan. Latte: Improving latex recogni- tion for tables and formulae with iterative refinement....
-
[32]
Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, and Jaegul Choo. Talk to your slides: Language-driven agents for efficient slide editing.arXiv preprint arXiv:2505.11604,
-
[33]
Mohammad Sadil Khan, Elona Dupont, Sk Aziz Ali, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4713–4722, 2024a. Mohammad Sadil Khan, Sankalp Sinha, Talha Udd...
-
[34]
46 Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649,
-
[35]
Kristian Kolthoff, Felix Kretzer, Lennart Fiebig, Christian Bartelt, Alexander Maedche, and Simone Paolo Ponzetto. Zero-shotpromptingapproachesforllm-basedgraphicaluserinterfacegeneration.arXiv preprint arXiv:2412.11328,
-
[36]
Theoremexplainagent: Towards video-based multimodal explanations for LLM theorem understanding
MaxKu, CheukHeiChong, JonathanLeung, KrishShah, AlvinYu, andWenhuChen. Theoremexplainagent: Towards video-based multimodal explanations for LLM theorem understanding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, pp. 6663–6684. Association for Computational Linguistics, 2025a. ...
arXiv 2025
-
[37]
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms.arXiv preprint arXiv:2406.18629,
-
[38]
Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029,
-
[39]
Bingxuan Li, Yiwei Wang, Jiuxiang Gu, Kai-Wei Chang, and Nanyun Peng. Metal: A multi-agent framework for chart generation with test-time scaling.arXiv preprint arXiv:2502.17651, 2025a. Jiahao Li, Yusheng Luo, Yunzhong Lou, and Xiangdong Zhou. Recad: Reinforcement learning enhanced parametric cad model generation with vision-language models.arXiv preprint ...
arXiv 1918
-
[40]
47 Tzu-Mao Li, Michal Lukáč, Michaël Gharbi, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning.ACM Transactions on Graphics (TOG), 39(6):1–15, 2020b. Xueyang Li, Yu Song, Yunzhong Lou, and Xiangdong Zhou. Cad translator: An effective drive for text to 3d parametric computer-aided design generative modeling. I...
arXiv 2025
-
[41]
Computer-use agents as judges for generative user interface.arXiv preprint arXiv:2511.15567, 2025a
Kevin Qinghong Lin, Siyuan Hu, Linjie Li, Zhengyuan Yang, Lijuan Wang, Philip Torr, and Mike Zheng Shou. Computer-use agents as judges for generative user interface.arXiv preprint arXiv:2511.15567, 2025a. Kevin Qinghong Lin, Yuhao Zheng, Hangyu Ran, Dantong Zhu, Dongxing Mao, Linjie Li, Philip Torr, and Alex Jinpeng Wang. Vcode: a multimodal coding benchm...
-
[42]
Chengzhi Liu, Yuzhe Yang, Kaiwen Zhou, Zhen Zhang, Yue Fan, Yanan Xie, Peng Qi, and Xin Eric Wang. Presenting a paper is an art: Self-improvement aesthetic agents for academic presentations.arXiv preprint arXiv:2510.05571, 2025a. Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, and Julia...
arXiv 2025
-
[43]
Visual agentic reinforcement fine-tuning.arXiv preprint arXiv:2505.14246, 2025d
Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual agentic reinforcement fine-tuning.arXiv preprint arXiv:2505.14246, 2025d. Jinwei Lu, Yuanfeng Song, Haodi Zhang, Chen Jason Zhang, Kaishun Wu, and Raymond Chi-Wing Wong. Towards robustness of text-to-visualization translation against l...
-
[44]
Tianqi Luo, Chuhan Huang, Leixian Shen, Boyan Li, Shuyu Shen, Wei Zeng, Nan Tang, and Yuyu Luo
URLhttps: //arxiv.org/abs/2410.22370. Tianqi Luo, Chuhan Huang, Leixian Shen, Boyan Li, Shuyu Shen, Wei Zeng, Nan Tang, and Yuyu Luo. nvbench 2.0: Resolving ambiguity in text-to-visualization through stepwise reasoning.arXiv preprint arXiv:2503.12880,
-
[45]
Yuyu Luo, Jiawei Tang, and Guoliang Li. nvbench: A large-scale synthesized dataset for cross-domain natural language to visualization task.arXiv preprint arXiv:2112.12926,
-
[46]
49 Zhao Mandi, Yijia Weng, Dominik Bauer, and Shuran Song
Accessed: 2025-12-12. 49 Zhao Mandi, Yijia Weng, Dominik Bauer, and Shuran Song. Real2code: Reconstruct articulated objects via code generation.arXiv preprint arXiv:2406.08474,
arXiv 2025
-
[47]
Yao Mu, Junting Chen, Qinglong Zhang, Shoufa Chen, Qiaojun Yu, Chongjian Ge, Runjian Chen, Zhixuan Liang, Mengkang Hu, Chaofan Tao, et al. Robocodex: Multimodal code generation for robotic behavior synthesis.arXiv preprint arXiv:2402.16117,
-
[48]
Amace: Automatic multi- agent chart evolution for iteratively tailored chart generation
Hyuk Namgoong, Jeesu Jung, Hyeonseok Kang, Yohan Lee, and Sangkeun Jung. Amace: Automatic multi- agent chart evolution for iteratively tailored chart generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 21483–21498,
2025
-
[49]
Yuansheng Ni, Songcheng Cai, Xiangchao Chen, Jiarong Liang, Zhiheng Lyu, Jiaqi Deng, Kai Zou, Ping Nie, Fei Yuan, Xiang Yue, et al. Viscoder2: Building multi-language visualization coding agents.arXiv preprint arXiv:2510.23642, 2025a. Yuansheng Ni, Ping Nie, Kai Zou, Xiang Yue, and Wenhu Chen. Viscoder: Fine-tuning llms for executable python visualization...
Pith/arXiv arXiv 2025
-
[50]
Accessed: 2025-12-12. Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
Pith/arXiv arXiv 2025
-
[51]
Geliang Ouyang, Jingyao Chen, Zhihe Nie, Yi Gui, Yao Wan, Hongyu Zhang, and Dongping Chen. nvagent: Automated data visualization from natural language via collaborative agent workflow.arXiv preprint arXiv:2502.05036, 2025a. Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, et al. Omni...
-
[52]
Vik Paruchuri
Accessed: 2025-12-10. Vik Paruchuri. Marker: Fast and accurate pdf to markdown converter.https://github.com/datalab-to/ marker,
2025
-
[53]
Accessed: 2025-12-12. ShengYun Peng, Aishwarya Chakravarthy, Seongmin Lee, Xiaojing Wang, Rajarajeswari Balasubramaniyan, and Duen Horng Chau. Unitable: Towards a unified framework for table recognition via self-supervised pretraining.arXiv preprint arXiv:2403.04822,
arXiv 2025
-
[54]
Neuralsvg: An implicit representation for text-to-vector generation.arXiv preprint arXiv:2501.03992,
Sagi Polaczek, Yuval Alaluf, Elad Richardson, Yael Vinker, and Daniel Cohen-Or. Neuralsvg: An implicit representation for text-to-vector generation.arXiv preprint arXiv:2501.03992,
-
[55]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmocr: Unlocking trillions of tokens in pdfs with vision language models.arXiv preprint arXiv:2502.18443, 2025a. Jake Poznanski, Luca Soldaini, and Kyle Lo. olmocr 2: Unit test rewards for document ocr.arXiv preprint ...
-
[56]
URL https://arxiv.org/abs/2402.04236. Zeju Qiu, Weiyang Liu, Haiwen Feng, Zhen Liu, Tim Z Xiao, Katherine M Collins, Joshua B Tenenbaum, Adrian Weller, Michael J Black, and Bernhard Schölkopf. Can large language models understand symbolic graphics programs?arXiv preprint arXiv:2408.08313,
-
[57]
Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text
Mizanur Rahman, Md Tahmid Rahman Laskar, Shafiq Joty, and Enamul Hoque. Text2vis: A challenging and diverse benchmark for generating multimodal visualizations from text. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 31837–31862,
2025
-
[58]
Sina Rismanchian, Yasaman Razeghi, Sameer Singh, and Shayan Doroudi
Accessed: 2025-12-12. Sina Rismanchian, Yasaman Razeghi, Sameer Singh, and Shayan Doroudi. Turtlebench: A visual program- ming benchmark in turtle geometry. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 12170–12188,
2025
-
[59]
Juan Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte, François Savard, Ahmed Masry, Shravan Nayak, et al. Bigdocs: An open dataset for training multimodal models on document and code tasks.arXiv preprint arXiv:2412.04626,
-
[60]
Starvector: Generating scalable vector graphics code from images and text
Juan A Rodriguez, Abhay Puri, Shubham Agarwal, Issam H Laradji, Pau Rodriguez, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Starvector: Generating scalable vector graphics code from images and text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16175–16186, June 2025a. Juan A Rodrigue...
-
[61]
Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
-
[62]
Wonduk Seo, Seungyong Lee, Daye Kang, Hyunjin An, Zonghao Yuan, and Seunghyun Lee. Automated visualization code synthesis via multi-path reasoning and feedback-driven optimization.arXiv preprint arXiv:2502.11140,
-
[63]
Chuyi Shang, Amos You, Sanjay Subramanian, Trevor Darrell, and Roei Herzig. Traveler: A modular multi-lmm agent framework for video question-answering.arXiv preprint arXiv:2404.01476,
-
[64]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[65]
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615,
-
[66]
Presentagent: Multimodal agent for presentation video generation
Jingwei Shi, Zeyu Zhang, Biao Wu, Yanjie Liang, Meng Fang, Ling Chen, and Yang Zhao. Presentagent: Multimodal agent for presentation video generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 760–773,
2025
-
[67]
Design2code: Bench- marking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Bench- marking multimodal code generation for automated front-end engineering. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Hu- man Language Technologies (NAACL), pp. 3956–3974, Albuque...
2025
-
[68]
Shubhankar Singh, Purvi Chaurasia, Yerram Varun, Pranshu Pandya, Vatsal Gupta, Vivek Gupta, and Dan Roth. Flowvqa: Mapping multimodal logic in visual question answering with flowcharts.arXiv preprint arXiv:2406.19237,
-
[69]
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918,
-
[70]
Haoyu Sun, Huichen Will Wang, Jiawei Gu, Linjie Li, and Yu Cheng
Association for Computational Linguistics. Haoyu Sun, Huichen Will Wang, Jiawei Gu, Linjie Li, and Yu Cheng. Fullfront: Benchmarking mllms across the full front-end engineering workflow.arXiv preprint arXiv:2505.17399, 2025a. Qiushi Sun, Zhirui Chen, Fangzhi Xu, Kanzhi Cheng, Chang Ma, Zhangyue Yin, Jianing Wang, Chengcheng Han, Renyu Zhu, Shuai Yuan, et ...
-
[71]
Qiushi Sun, Jingyang Gong, Yang Liu, Qiaosheng Chen, Lei Li, Kai Chen, Qipeng Guo, Ben Kao, and Fei Yuan. Januscoder: Towards a foundational visual-programmatic interface for code intelligence.arXiv preprint arXiv:2510.23538, 2025b. Qiushi Sun, Zhoumianze Liu, Chang Ma, Zichen Ding, Fangzhi Xu, Zhangyue Yin, Haiteng Zhao, Zhenyu Wu, Kanzhi Cheng, Zhaoyang...
-
[72]
URLhttps://proceedings.mlr.press/v80/sun18a.html. Tao Sun, Enhao Pan, Zhengkai Yang, Kaixin Sui, Jiajun Shi, Xianfu Cheng, Tongliang Li, Wenhao Huang, Ge Zhang, Jian Yang, et al. P2p: Automated paper-to-poster generation and fine-grained benchmark. arXiv preprint arXiv:2505.17104, 2025d. DídacSurís, SachitMenon, andCarlVondrick. Vipergpt: Visualinferencev...
-
[73]
Wentao Tan, Qiong Cao, Chao Xue, Yibing Zhan, Changxing Ding, and Xiaodong He
URLhttps://arxiv.org/abs/2303.08128. Wentao Tan, Qiong Cao, Chao Xue, Yibing Zhan, Changxing Ding, and Xiaodong He. Chartmaster: Ad- vancing chart-to-code generation with real-world charts and chart similarity reinforcement learning.arXiv preprint arXiv:2508.17608,
-
[74]
Jiahao Tang, Henry Hengyuan Zhao, Lijian Wu, Yifei Tao, Dongxing Mao, Yang Wan, Jingru Tan, Min Zeng, Min Li, and Alex Jinpeng Wang. From charts to code: A hierarchical benchmark for multimodal models.arXiv preprint arXiv:2510.17932, 2025a. Wenxin Tang, Jingyu Xiao, Wenxuan Jiang, Xi Xiao, Yuhang Wang, Xuxin Tang, Qing Li, Yuehe Ma, Junliang Liu, Shisong ...
-
[75]
53 Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
-
[76]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
Accessed: 2026-05-30. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30,
2026
-
[77]
Code as reward: Empowering reinforcement learning with vlms.arXiv preprint arXiv:2402.04764,
David Venuto, Sami Nur Islam, Martin Klissarov, Doina Precup, Sherry Yang, and Ankit Anand. Code as reward: Empowering reinforcement learning with vlms.arXiv preprint arXiv:2402.04764,
-
[78]
Yuxuan Wan, Yi Dong, Jingyu Xiao, Yintong Huo, Wenxuan Wang, and Michael R Lyu. Mrweb: An explo- ration of generating multi-page resource-aware web code from ui designs.arXiv preprint arXiv:2412.15310,
-
[79]
Yuxuan Wan, Tingshuo Liang, Jiakai Xu, Jingyu Xiao, Yintong Huo, and Michael R Lyu. Automatically generating web applications from requirements via multi-agent test-driven development.arXiv preprint arXiv:2509.25297,
-
[80]
Baode Wang, Biao Wu, Weizhen Li, Meng Fang, Yanjie Liang, Zuming Huang, Haozhe Wang, Jun Huang, Ling Chen, Wei Chu, et al. Infinity parser: Layout aware reinforcement learning for scanned document parsing.arXiv preprint arXiv:2506.03197, 2025a. Bin Wang, Zhuangcheng Gu, Guang Liang, Chao Xu, Bo Zhang, Botian Shi, and Conghui He. Unimernet: A universal net...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.