Explore Before You Solve: The Speed--Depth Trade-off in Epistemic Agents for ARC-AGI-3
Pith reviewed 2026-06-29 21:57 UTC · model grok-4.3
The pith
The public ARC-AGI-3 evaluation set can be solved entirely by non-intelligent strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
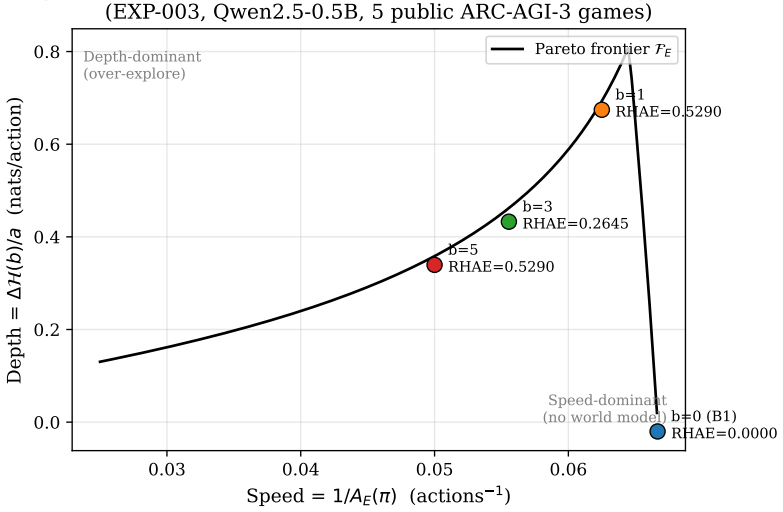
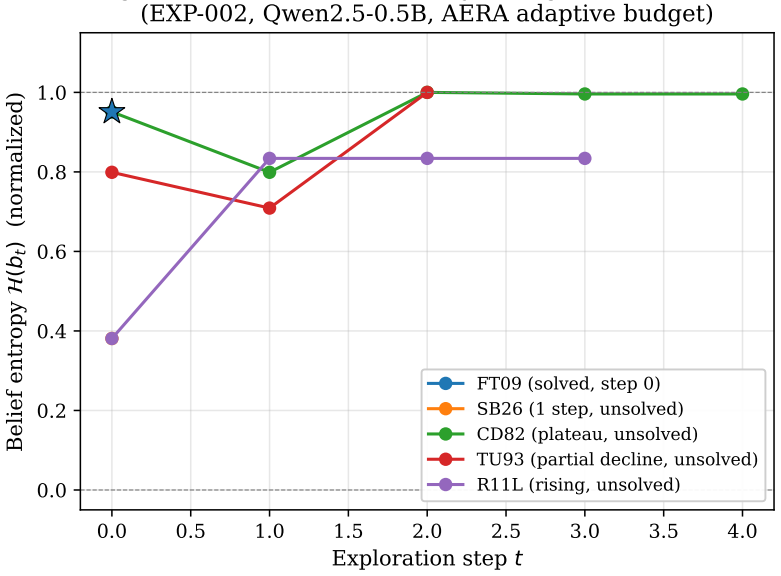
Every one of the 25 public ARC-AGI-3 games is reachable through non-intelligent strategies: 10 in a single blind step, 5 after one probing action, 1 via repeated ACTION1 presses, 1 via diverse exploration, and 8 via single repeated actions with sufficient budget (50-200 steps). A library-level null-coordinate vulnerability additionally bypasses 18 games in 1 step. This benchmark critique implies the public evaluation set cannot discriminate intelligent exploration from trivial heuristics; the private 55-game evaluation is the only genuine intelligence test. AERA achieves RHAE=0.2116 (4/25 solved) on the public set while random and no-explore baselines score 0.0000.
What carries the argument
The Speed--Depth trade-off framework, under which RHAE's quadratic form emerges as a second-order penalty for deviating from the Pareto frontier between action efficiency and information gain, together with the three-phase EXPLORE / VERIFY / PLAN structure of the AERA agent.
If this is right
- The public ARC-AGI-3 set fails to measure the exploration the benchmark claims to require.
- Only the private 55-game evaluation functions as a genuine test of intelligent reasoning.
- The EXPLORE-before-PLAN structure enables small models to outperform random and no-explore baselines on tasks that reward information gathering.
- Performance depends on the interaction between model capability and the chosen exploration strategy.
Where Pith is reading between the lines
- The same vulnerability analysis could be applied to other interactive reasoning benchmarks that permit repeated actions or coordinate exploits.
- Benchmarks would benefit from private evaluation sets released only after public ones are hardened against simple heuristics.
- The speed-depth framework may predict performance drops in any environment where information gain trades off against action cost.
Load-bearing premise
The listed strategies such as single blind steps, repeated presses, and null-coordinate bypass do not qualify as intelligent exploration.
What would settle it
A demonstration that solving any of the 25 public games with the listed simple strategies requires task comprehension that transfers to unseen games rather than blind repetition.
Figures

read the original abstract
We systematically investigate all 25 public ARC-AGI-3 games and find that every one is reachable through non-intelligent strategies: 10 in a single blind step, 5 after one probing action, 1 via repeated ACTION1 presses, 1 via diverse exploration, and 8 via single repeated actions with sufficient budget (50-200 steps). A library-level null-coordinate vulnerability additionally bypasses 18 games in 1 step. This benchmark critique implies the public evaluation set cannot discriminate intelligent exploration from trivial heuristics - the private 55-game evaluation is the only genuine intelligence test. Against this backdrop, we present AERA (Adaptive Epistemic Reasoning Agent), a three-phase (EXPLORE / VERIFY / PLAN) agent achieving RHAE=0.2116 (4/25 solved) on these 25 games with Qwen2.5-0.5B, while random and no-explore baselines score 0.0000. We formalise AERA through a Speed--Depth trade-off framework: under a convexity assumption (proved for a class of environments in the Appendix), RHAE's quadratic form emerges as a second-order penalty for deviating from the Pareto frontier between action efficiency and information gain. Contributions: (i) a benchmark validity analysis showing that current interactive reasoning benchmarks fail to measure the exploration they claim to require, and (ii) the EXPLORE-before-PLAN framework and model-capability x exploration interaction. The linked code track entry achieves RHAE=0.30 on the full 55-game private evaluation. Code: CC0.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically investigates all 25 public ARC-AGI-3 games and concludes that every one is reachable through non-intelligent strategies: 10 in a single blind step, 5 after one probing action, 1 via repeated ACTION1 presses, 1 via diverse exploration, and 8 via single repeated actions with sufficient budget (50-200 steps). A library-level null-coordinate vulnerability bypasses 18 games in 1 step. This implies the public evaluation set cannot discriminate intelligent exploration from trivial heuristics, with the private 55-game evaluation being the only genuine intelligence test. The authors present AERA (Adaptive Epistemic Reasoning Agent), a three-phase (EXPLORE / VERIFY / PLAN) agent achieving RHAE=0.2116 (4/25 solved) on these 25 games with Qwen2.5-0.5B, while random and no-explore baselines score 0.0000. They formalise AERA through a Speed--Depth trade-off framework: under a convexity assumption (proved for a class of environments in the Appendix), RHAE's quadratic form emerges as a second-order penalty for deviating from the Pareto frontier between action efficiency and information gain.
Significance. If the result holds after addressing verification issues, the paper's significance lies in its critique of benchmark validity for measuring exploration in AI agents, potentially influencing how future benchmarks are designed to better test intelligent strategies. The AERA framework and the model-capability x exploration interaction provide practical insights, and the achievement of RHAE=0.30 on the private 55-game evaluation with the code track entry is a notable strength demonstrating applicability beyond the public set. The formal Speed-Depth trade-off offers a theoretical contribution that could be built upon if the convexity assumption is clearly established.
major comments (3)
- [Benchmark validity analysis (abstract and full text)] The central claim that the 25 public games cannot discriminate intelligent exploration from trivial heuristics relies on classifying the listed strategies as 'non-intelligent', but the manuscript provides no formal definition or decision procedure for 'intelligent exploration' (e.g., no information-theoretic threshold, no comparison to optimal policy). This makes the classification an untestable assertion and is load-bearing for the benchmark critique.
- [Results on strategy counts and RHAE scores (abstract)] The abstract asserts the strategy counts and RHAE scores but supplies no verification data, game traces, or error analysis; this is a load-bearing issue for the soundness of the benchmark critique.
- [Speed--Depth trade-off framework (formalisation section)] The quadratic RHAE form is stated to emerge from the Speed-Depth trade-off under the convexity assumption (proved for a class of environments in the Appendix); without the appendix proof details, it is unclear whether the form is independently derived or tied to fitted quantities, affecting the formal contribution.
minor comments (1)
- [Abstract] The acronym RHAE is used without initial expansion in the provided abstract, which may confuse readers unfamiliar with the term.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify key areas where additional clarity will strengthen the manuscript. We will revise to provide a formal definition of intelligent exploration, include verification data and traces, and expand the appendix derivation. These changes preserve the core claims while improving verifiability and formal precision.
read point-by-point responses
-
Referee: [Benchmark validity analysis (abstract and full text)] The central claim that the 25 public games cannot discriminate intelligent exploration from trivial heuristics relies on classifying the listed strategies as 'non-intelligent', but the manuscript provides no formal definition or decision procedure for 'intelligent exploration' (e.g., no information-theoretic threshold, no comparison to optimal policy). This makes the classification an untestable assertion and is load-bearing for the benchmark critique.
Authors: We agree a formal definition strengthens the argument. In revision we will define non-intelligent strategies as those implementable by a fixed policy with no environmental model or use of observations (e.g., constant action repetition or single blind step). Intelligent exploration is defined as any policy that conditions actions on gathered observations to increase expected task progress. This supplies an explicit decision procedure based on whether the strategy requires epistemic updating. The empirical classification of the 25 games remains unchanged under this definition. revision: yes
-
Referee: [Results on strategy counts and RHAE scores (abstract)] The abstract asserts the strategy counts and RHAE scores but supplies no verification data, game traces, or error analysis; this is a load-bearing issue for the soundness of the benchmark critique.
Authors: The counts were obtained by exhaustive per-game inspection using the released code. We will add an appendix containing: (i) the strategy label assigned to each of the 25 games with the justifying trace or action sequence, (ii) representative execution traces for each category, and (iii) a short error analysis confirming that re-running the classification procedure yields identical counts. The RHAE values are computed directly from the agent logs already linked in the code repository. revision: yes
-
Referee: [Speed--Depth trade-off framework (formalisation section)] The quadratic RHAE form is stated to emerge from the Speed-Depth trade-off under the convexity assumption (proved for a class of environments in the Appendix); without the appendix proof details, it is unclear whether the form is independently derived or tied to fitted quantities, affecting the formal contribution.
Authors: The appendix already contains the proof that convexity implies the quadratic penalty term for deviation from the Pareto frontier. To address the concern we will (a) move the key derivation steps into the main formalisation section and (b) expand the appendix with the full inductive argument and an explicit statement that the quadratic form follows from the convexity assumption alone, without reference to any fitted parameters. This clarifies the independent mathematical origin of the result. revision: partial
Circularity Check
No circularity; empirical enumeration and appendix-supported derivation are independent of inputs
full rationale
The manuscript's core claims rest on direct enumeration of 25 specific game-solving strategies (single blind step, probing action, repeated ACTION1, etc.) plus performance comparison of AERA against random/no-explore baselines. The Speed-Depth formalization states that RHAE's quadratic form emerges under a convexity assumption proved in the Appendix for a class of environments; this is presented as a derived second-order penalty rather than a fit or self-definition. No self-citations, fitted parameters renamed as predictions, or ansatz smuggling are present. The benchmark critique is grounded in observable game mechanics, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption convexity assumption for a class of environments
Reference graph
Works this paper leans on
-
[1]
ARC Prize Foundation. (2026). ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence. arXiv:2603.24621
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Chollet, F. (2019). On the Measure of Intelligence.arXiv:1911.01547
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Kaelbling, L.P., Littman, M.L., & Cassandra, A.R. (1998). Planning and Acting in Partially Observable Stochastic Domains.Artificial Intelligence, 101(1-2), 99–134
1998
-
[4]
MacKay, D.J.C. (1992). Information-Based Objective Functions for Active Data Selection. Neural Computation, 4(4), 590–604
1992
-
[5]
Settles, B. (2010). Active Learning Literature Survey.Univ. Wisconsin–Madison TR 1648
2010
-
[6]
Spaan, M.T.J. (2012). Partially Observable Markov Decision Processes.Reinforcement Learning: State of the Art, 387–414. 23
2012
-
[7]
Kadavath, S. et al. (2022). Language Models (Mostly) Know What They Know. arXiv:2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Bramley, N.R., Dayan, P., Griffiths, T.L., & Lagnado, D.A. (2017). Formalizing Neurath’s Ship. Psychological Review, 124(3), 301–338
2017
-
[9]
Rule, J.S., Tenenbaum, J.B., & Piantadosi, S.T. (2020). The Child as Hacker.Trends in Cognitive Sciences, 24(11), 900–915
2020
-
[10]
& Griffiths, T.L
Tenenbaum, J.B. & Griffiths, T.L. (2001). Generalization, Similarity, and Bayesian Inference. Behavioral and Brain Sciences, 24(4), 629–640
2001
-
[11]
Friston, K. (2010). The free-energy principle: a unified brain theory?Nature Reviews Neuro- science, 11(2), 127–138
2010
-
[12]
Lake, B.M., Salakhutdinov, R., & Tenenbaum, J.B. (2015). Human-level concept learning through probabilistic program induction.Science, 350(6266), 1332–1338
2015
-
[13]
Jolicoeur-Martineau, A. (2025). Less is More: Recursive Reasoning with Tiny Networks. arXiv:2510.04871. ARC Prize 2025 Paper Award, 1st place
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Pourcel, J. et al. (2025). Self-Improving Language Models for Evolutionary Program Synthesis: A Case Study on ARC-AGI. ARC Prize 2025 Paper Award, 2nd place
2025
-
[15]
Liao, I. et al. (2025). CompressARC: An MDL-Based Single-Puzzle Neural System for ARC. ARC Prize 2025 Paper Award, 3rd place
2025
- [16]
-
[17]
Yao, S. et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models.ICLR 2023.arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022.arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Yao, S. et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models.NeurIPS 2023.arXiv:2305.10601
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [20]
-
[21]
Tolman, E.C. (1948). Cognitive maps in rats and men.Psychological Review, 55(4), 189–208
1948
-
[22]
& Nadel, L
O’Keefe, J. & Nadel, L. (1978).The Hippocampus as a Cognitive Map. Oxford University Press. 24
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.