Beyond Monotonic Progress: Retry-Supervised Value Learning for Robot Imitation
Pith reviewed 2026-06-25 23:37 UTC · model grok-4.3
The pith
Retry events in demonstrations supply sparse supervision for value functions that detect local mistakes and improve imitation from imperfect robot data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
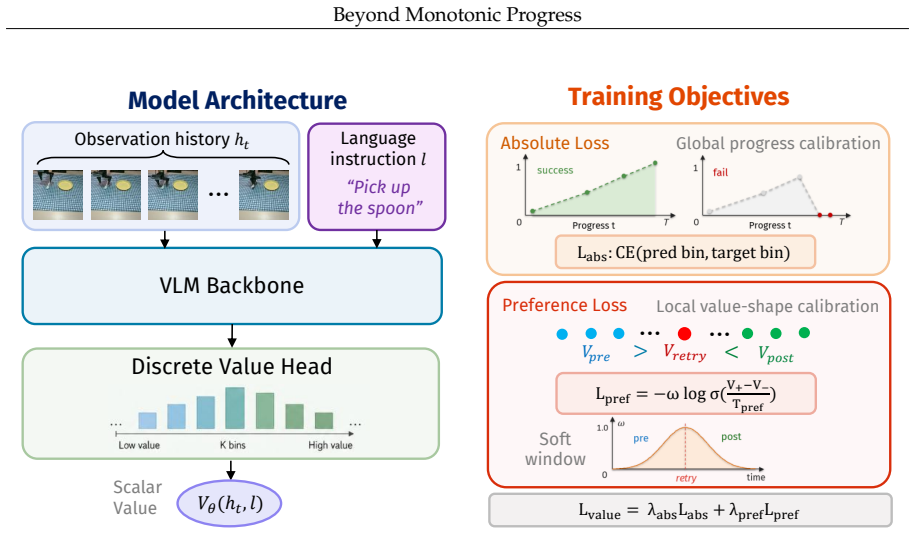
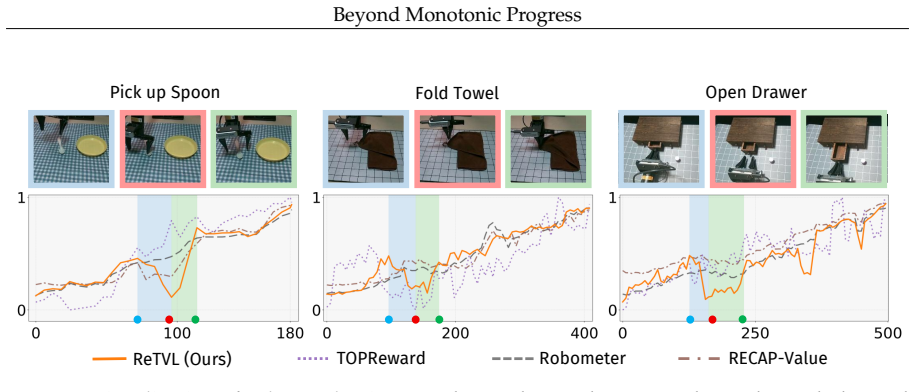
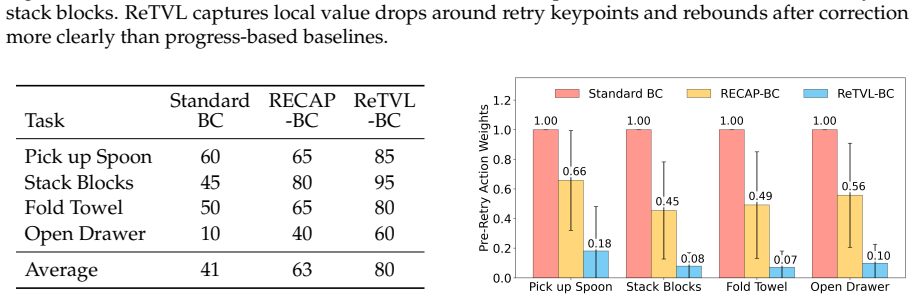
ReTVL learns mistake-sensitive value functions by combining global progress calibration with local pairwise preference learning induced by sparsely annotated retry keypoints, then applies the values to reweight demonstration chunks for behavior cloning so that execution errors are down-weighted while corrective behaviors are preserved.
What carries the argument
Retry-supervised value learning that uses retry keypoints to induce local pairwise preferences for modeling degradation-and-recovery structure around mistakes.
If this is right
- Value estimates become more fine-grained than those produced by monotonic progress baselines.
- Imitation learning from imperfect demonstrations improves on real-robot manipulation tasks.
- Harmful execution errors receive reduced weight while useful corrective segments are retained during behavior cloning.
- The approach operates directly on mixed-quality demonstration data without requiring additional dense rewards or perfect trajectories.
Where Pith is reading between the lines
- The same retry-signal idea could be tested in other sequential domains where correction events occur naturally, such as language-model fine-tuning from human edits.
- It offers a route to extract preference pairs from existing demonstration logs without new human annotation.
- The framework might combine with online data collection to continually refine values from observed retries during deployment.
Load-bearing premise
Retry events in the demonstrations reliably mark unbiased local degradation-and-recovery points that can serve as supervision without task-specific bias or annotation artifacts.
What would settle it
A controlled comparison on the same real-robot manipulation tasks in which behavior cloning reweighted by ReTVL values shows no improvement or worse performance than reweighting by progress-based value estimates.
Figures


read the original abstract
Human demonstrations for robot imitation learning often contain mistakes and corrective behaviors, such as imprecise grasps, object misalignment, unstable contact, and repeated attempts. While these segments are commonly treated as noisy or suboptimal data, they provide valuable evidence about when execution deviates from a desirable path and how task feasibility can be restored. However, existing reward and value models often rely on monotonic progress assumptions, which capture coarse task advancement but may overlook local execution errors and corrective behaviors in imperfect demonstrations. In this work, we propose ReTVL (ReTry-Supervised Value Learning), a framework for learning mistake-sensitive value functions from mixed-quality robot demonstrations by leveraging retry events as sparse supervision. ReTVL captures the local degradation-and-recovery structure around mistakes by combining global progress calibration with local pairwise preference learning induced by sparsely annotated retry keypoints. The learned value model is then used to reweight demonstration chunks for downstream behavior cloning, reducing the influence of harmful execution errors while preserving useful corrective behaviors. Experiments on real-robot manipulation tasks show that ReTVL produces more fine-grained value estimates than progress-based baselines and improves imitation learning from imperfect demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReTVL (ReTry-Supervised Value Learning), a framework that learns mistake-sensitive value functions from mixed-quality robot demonstrations by treating sparsely annotated retry events as markers of local degradation-and-recovery. It combines global progress calibration with local pairwise preference learning from these keypoints, then reweights demonstration chunks using the learned value model for downstream behavior cloning. The central claim is that this produces more fine-grained value estimates than monotonic progress baselines and improves imitation learning performance on real-robot manipulation tasks with imperfect demonstrations.
Significance. If the central construction holds without bias, the work offers a practical advance in imitation learning by extracting supervisory signal from corrective behaviors that are typically discarded as noise. It directly targets a common real-world data issue (mistakes and recoveries) without requiring dense rewards or perfect demonstrations, and the reweighting step for behavior cloning is a clear downstream application. The approach is grounded in observable retry events rather than invented dense labels.
major comments (2)
- [Abstract and method section] The assumption that retry keypoints provide unbiased sparse supervision for pairwise preferences is load-bearing for both the fine-grained value claim and the reweighting benefit. The manuscript provides no annotation protocol, inter-annotator reliability metrics, or controls demonstrating that retry locations are independent of task geometry, object properties, or demonstrator idiosyncrasies (Abstract; method description). If retry events correlate with these factors, the learned value function may rediscover task-specific heuristics rather than general mistake sensitivity.
- [Abstract and experiments section] The abstract asserts that experiments show ReTVL produces more fine-grained value estimates and improves imitation learning, yet supplies no quantitative results, baseline comparisons, error bars, or statistical tests. This prevents assessment of whether the data support the central claims about value granularity and downstream BC improvement (Abstract; experiments section).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and method section] The assumption that retry keypoints provide unbiased sparse supervision for pairwise preferences is load-bearing for both the fine-grained value claim and the reweighting benefit. The manuscript provides no annotation protocol, inter-annotator reliability metrics, or controls demonstrating that retry locations are independent of task geometry, object properties, or demonstrator idiosyncrasies (Abstract; method description). If retry events correlate with these factors, the learned value function may rediscover task-specific heuristics rather than general mistake sensitivity.
Authors: We agree that an explicit annotation protocol would improve clarity. Retry events are identified directly from trajectory data as repeated attempts following observable failures (e.g., grasp slips or misalignments), which are task-agnostic markers of local degradation. The local pairwise preference learning is restricted to short windows around these keypoints to focus on recovery dynamics rather than global task structure. We will add a dedicated subsection describing the annotation procedure and acknowledge the absence of inter-annotator metrics and explicit independence controls as a limitation. New experiments to demonstrate full independence are outside the scope of the current study. revision: partial
-
Referee: [Abstract and experiments section] The abstract asserts that experiments show ReTVL produces more fine-grained value estimates and improves imitation learning, yet supplies no quantitative results, baseline comparisons, error bars, or statistical tests. This prevents assessment of whether the data support the central claims about value granularity and downstream BC improvement (Abstract; experiments section).
Authors: The experiments section reports baseline comparisons on real-robot tasks and states that ReTVL yields finer value estimates and better BC performance. However, we acknowledge that the abstract contains no numerical values and that error bars plus statistical tests are not presented. We will revise the abstract to include key quantitative metrics and augment the experiments section with error bars and significance tests. revision: yes
- Providing inter-annotator reliability metrics or new controls proving retry locations are independent of task geometry, object properties, and demonstrator idiosyncrasies, as these were not collected in the original study.
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description contain no equations, fitting procedures, or derivation steps that reduce any prediction or result to its own inputs by construction. No self-citations, ansatzes, or uniqueness claims are referenced. The method is described at a high level using retry events for supervision, but without visible load-bearing reductions or self-referential definitions, the central claims remain independent of the inputs in the given text. This is the expected outcome for papers without explicit mathematical derivations shown.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
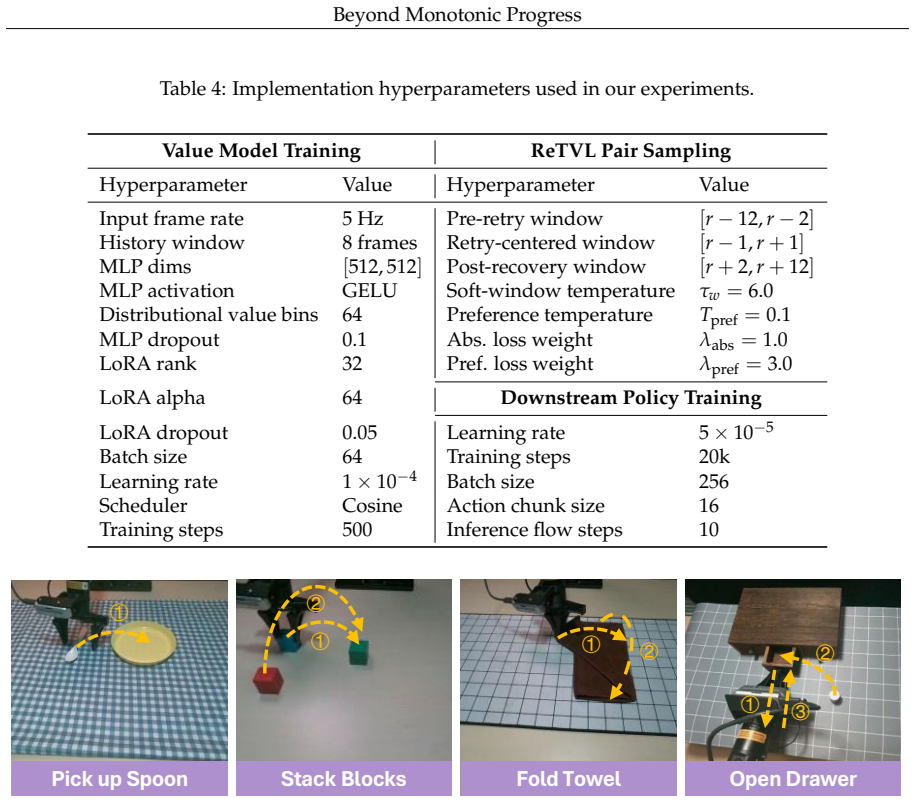
and Ng, A
Abbeel, P . and Ng, A. Y. Apprenticeship learning via inverse reinforcement learning. InProceedings of the twenty-first international conference on Machine learning, pp. 1, 2004
2004
-
[2]
Alakuijala, M., McLean, R., Woungang, I., Farsad, N., Kaski, S., Marttinen, P ., and Yuan, K. Video- language critic: Transferable reward functions for language-conditioned robotics.arXiv preprint arXiv:2405.19988, 2024
arXiv 2024
-
[3]
Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., Driess, D., Equi, M., Esmail, A., Fang, Y., Finn, C., Glossop, C., Godden, T., Goryachev, I., Groom, L., Hancock, H., Hausman, K., Hussein, G., Ichter, B., Jakubczak, S., Jen, R., Jones, T., Katz, B., Ke, L., Kuchi, C., Lamb, M., LeBlanc, ...
Pith/arXiv arXiv 2025
-
[4]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[5]
X., Tanner, J., Vuong, Q., Walling, A., Wang, H., and Zhilinsky, U
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L. X., Tanner, J., Vuong, Q., Walling, A., Wang, H., and Zhilinsky, U. π0: A vision-language- action flow model for general robot control, 202...
Pith/arXiv arXiv 2026
-
[6]
Bradley, R. A. and Terry, M. E. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[7]
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P ., Fu, C., Arenas, M. G., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.-W. E., Levine, S., Lu, Y., Michale...
Pith/arXiv arXiv 2023
-
[8]
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., Ibarz, J., Ichter, B., Irpan, A., Jackson, T., Jesmonth, S., Joshi, N. J., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, K.-H., Levine, S., Lu, Y., Malla, U., Manjunath, D., Mordatch, I., Nachum, O., Parada, C., Peralta, J...
Pith/arXiv arXiv 2023
-
[9]
S., Goo, W., Nagarajan, P ., and Niekum, S
Brown, D. S., Goo, W., Nagarajan, P ., and Niekum, S. Extrapolating beyond suboptimal demonstra- tions via inverse reinforcement learning from observations. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pp. 783–792. PMLR, 2019. 9 Beyond Monotonic Progress
2019
-
[10]
S., Goo, W., and Niekum, S
Brown, D. S., Goo, W., and Niekum, S. Better-than-demonstrator imitation learning via automatically-ranked demonstrations. InProceedings of the Conference on Robot Learning, volume 100 ofProceedings of Machine Learning Research, pp. 330–359. PMLR, 2020
2020
-
[11]
Bu, Q., Cai, J., Chen, L., Cui, X., Ding, Y., Feng, S., Gao, S., He, X., Hu, X., Huang, X., et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[12]
in-the-wild
Chen, A. S., Nair, S., and Finn, C. Learning generalizable robotic reward functions from “in-the-wild” human videos. InProceedings of Robotics: Science and Systems (RSS), 2021
2021
-
[13]
Chen, Q., Yu, J., Schwager, M., Abbeel, P ., Shentu, F., and Wu, P . Sarm: Stage-aware reward modeling for long horizon robot manipulation.arXiv preprint arXiv:2509.25358, 2025
Pith/arXiv arXiv 2025
-
[14]
Chen, S., Harrison, C., Lee, Y.-C., Yang, A. J., Ren, Z., Ratliff, L. J., Duan, J., Fox, D., and Kr- ishna, R. Topreward: Token probabilities as hidden zero-shot rewards for robotics.arXiv preprint arXiv:2602.19313, 2026
arXiv 2026
-
[15]
villa-x: Enhancing latent action modeling in vision-language-action models,
Chen, X., Wei, H., Zhang, P ., Zhang, C., Wang, K., Guo, Y., Yang, R., Wang, Y., Xiao, X., Zhao, L., Chen, J., and Bian, J. villa-x: Enhancing latent action modeling in vision-language-action models,
-
[16]
URLhttps://arxiv.org/abs/2507.23682
-
[17]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P . F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[18]
F., Leike, J., Brown, T
Christiano, P . F., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[19]
Guided cost learning: Deep inverse optimal control via policy optimization
Finn, C., Levine, S., and Abbeel, P . Guided cost learning: Deep inverse optimal control via policy optimization. InInternational conference on machine learning, pp. 49–58. PMLR, 2016
2016
-
[20]
Awr: Adaptive weighting regression for 3d hand pose estimation
Huang, W., Ren, P ., Wang, J., Qi, Q., and Sun, H. Awr: Adaptive weighting regression for 3d hand pose estimation. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 11061–11068, 2020
2020
-
[21]
Intelligence, P ., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M. Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A. Z., Shi, L. X., Smith, L., Springenberg, J. T., St...
Pith/arXiv arXiv 2025
-
[22]
Vima: General robot manipulation with multimodal prompts, 2023
Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., Fei-Fei, L., Anandkumar, A., Zhu, Y., and Fan, L. Vima: General robot manipulation with multimodal prompts, 2023. URL https: //arxiv.org/abs/2210.03094
arXiv 2023
-
[23]
Kelly, M., Sidrane, C., Driggs-Campbell, K., and Kochenderfer, M. J. HG-DAgger: Interactive imitation learning with human experts. InProceedings of the IEEE International Conference on Robotics and Automation, pp. 8077–8083, 2019. doi: 10.1109/ICRA.2019.8793698
-
[24]
Demodice: Offline imitation learning with supplementary imperfect demonstrations
Kim, G.-H., Seo, S., Lee, J., Jeon, W., Hwang, H., Yang, H., and Kim, K.-E. Demodice: Offline imitation learning with supplementary imperfect demonstrations. InInternational Conference on Learning Representations, 2022
2022
-
[25]
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P ., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P ., and Finn, C. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[26]
Dart: Noise injection for robust imitation learning, 2017
Laskey, M., Lee, J., Fox, R., Dragan, A., and Goldberg, K. Dart: Noise injection for robust imitation learning, 2017. URLhttps://arxiv.org/abs/1703.09327
Pith/arXiv arXiv 2017
-
[27]
Lee, T., Wagenmaker, A., Pertsch, K., Liang, P ., Levine, S., and Finn, C. Roboreward: General- purpose vision-language reward models for robotics.arXiv preprint arXiv:2601.00675, 2026. 10 Beyond Monotonic Progress
arXiv 2026
-
[28]
Li, P ., Chen, Y., Wu, H., Ma, X., Wu, X., Huang, Y., Wang, L., Kong, T., and Tan, T. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models, 2025. URLhttps://arxiv.org/abs/2506.07961
arXiv 2025
-
[29]
Li, Y., Ma, X., Xu, J., Cui, Y., Cui, Z., Han, Z., Huang, L., Kong, T., Liu, Y., Niu, H., et al. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation.arXiv preprint arXiv:2512.01801, 2025
arXiv 2025
-
[30]
Liang, A., Korkmaz, Y., Zhang, J., Hwang, M., Anwar, A., Kaushik, S., Shah, A., Huang, A. S., Zettlemoyer, L., Fox, D., Xiang, Y., Li, A., Bobu, A., Gupta, A., Tu, S., Biyik, E., and Zhang, J. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
Pith/arXiv arXiv 2026
-
[31]
Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., and Zhu, J. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[32]
J., Sodhani, S., Jayaraman, D., Bastani, O., Kumar, V ., and Zhang, A
Ma, Y. J., Sodhani, S., Jayaraman, D., Bastani, O., Kumar, V ., and Zhang, A. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
Pith/arXiv arXiv 2022
-
[33]
J., Liang, W., Som, V ., Kumar, V ., Zhang, A., Bastani, O., and Jayaraman, D
Ma, Y. J., Liang, W., Som, V ., Kumar, V ., Zhang, A., Bastani, O., and Jayaraman, D. Liv: Language- image representations and rewards for robotic control. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[34]
Arm: Advantage reward modeling for long-horizon manipulation.arXiv preprint arXiv:2604.03037, 2026
Mao, Y., Yu, Z., Mao, W., Li, Y., Hu, Q., Lan, Z., Zhu, M., and Chen, H. Arm: Advantage reward modeling for long-horizon manipulation.arXiv preprint arXiv:2604.03037, 2026
Pith/arXiv arXiv 2026
-
[35]
Awac: Accelerating online reinforcement learning with offline datasets, 2021
Nair, A., Gupta, A., Dalal, M., and Levine, S. Awac: Accelerating online reinforcement learning with offline datasets, 2021. URLhttps://arxiv.org/abs/2006.09359
Pith/arXiv arXiv 2021
-
[36]
Ng, A. Y. and Russell, S. J. Algorithms for inverse reinforcement learning. InProceedings of the Seventeenth International Conference on Machine Learning, ICML ’00, pp. 663–670, San Francisco, CA, USA, 2000. Morgan Kaufmann Publishers Inc. ISBN 1558607072
2000
-
[37]
C., Shevchuk, G., and Sadigh, D
Palan, M., Landolfi, N. C., Shevchuk, G., and Sadigh, D. Learning reward functions by integrating human demonstrations and preferences. InProceedings of Robotics: Science and Systems, 2019
2019
-
[38]
B., Kumar, A., Zhang, G., and Levine, S
Peng, X. B., Kumar, A., Zhang, G., and Levine, S. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning, 2019. URLhttps://arxiv.org/abs/1910.00177
Pith/arXiv arXiv 2019
-
[39]
Sadigh, D., Dragan, A. D., Sastry, S. S., and Seshia, S. A. Active preference-based learning of reward functions. InProceedings of Robotics: Science and Systems, 2017. doi: 10.15607/RSS.2017.XIII.053
-
[40]
Smolvla: A vision-language-action model for affordable and efficient robotics, 2025
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P ., Palma, S., Zouitine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., Alibert, S., Cord, M., Wolf, T., and Cadene, R. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025. URL https://arxiv.org/ abs/2506.01844
Pith/arXiv arXiv 2025
-
[41]
Tan, H., Chen, S., Xu, Y., Wang, Z., Ji, Y., Chi, C., Lyu, Y., Zhao, Z., Chen, X., Co, P ., et al. Robo- dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[42]
Team, O. M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., Luo, J., Tan, Y. L., Chen, L. Y., Sanketi, P ., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., and Levine, S. Octo: An open-source generalist robot policy, 2024. URL https://arxiv.org/abs/2405.12213
Pith/arXiv arXiv 2024
-
[43]
Wen, J., Zhu, Y., Li, J., Tang, Z., Shen, C., and Feng, F. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
Pith/arXiv arXiv 2025
-
[44]
Imitation learning from imperfect demonstration, 2019
Wu, Y.-H., Charoenphakdee, N., Bao, H., Tangkaratt, V ., and Sugiyama, M. Imitation learning from imperfect demonstration, 2019. URLhttps://arxiv.org/abs/1901.09387
Pith/arXiv arXiv 2019
-
[45]
Imitation learning from imperfect demonstration
Wu, Y.-H., Charoenphakdee, N., Bao, H., Tangkaratt, V ., and Sugiyama, M. Imitation learning from imperfect demonstration. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pp. 6818–6827. PMLR, 2019. 11 Beyond Monotonic Progress
2019
-
[46]
Discriminator-weighted offline imitation learning from suboptimal demonstrations
Xu, H., Zhan, X., Yin, H., and Qin, H. Discriminator-weighted offline imitation learning from suboptimal demonstrations. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pp. 24725–24742. PMLR, 2022
2022
-
[47]
Compliant residual dagger: Improving real-world contact- rich manipulation with human corrections.Advances in Neural Information Processing Systems, 38: 139559–139581, 2026
Xu, X., Hou, Y., Liu, Z., and Song, S. Compliant residual dagger: Improving real-world contact- rich manipulation with human corrections.Advances in Neural Information Processing Systems, 38: 139559–139581, 2026
2026
-
[48]
Yang, J., Lin, K., Li, J., Zhang, W., Lin, T., Wu, L., Su, Z., Zhao, H., Zhang, Y.-Q., Chen, L., et al. Rise: Self-improving robot policy with compositional world model.arXiv preprint arXiv:2602.11075, 2026
Pith/arXiv arXiv 2026
-
[49]
Yang, R., Wang, H., Liu, C., Yan, X., Wang, Y., Du, X., Yue, S., Liu, Y., Zhang, C., Qi, L., et al. Aloe: Action-level off-policy evaluation for vision-language-action model post-training.arXiv preprint arXiv:2602.12691, 2026
Pith/arXiv arXiv 2026
-
[50]
Confidence-aware imitation learning from demonstrations with varying optimality
Zhang, S., Cao, Z., Sadigh, D., and Sui, Y. Confidence-aware imitation learning from demonstrations with varying optimality. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[51]
Vlas: Vision-language- action model with speech instructions for customized robot manipulation, 2025
Zhao, W., Ding, P ., Zhang, M., Gong, Z., Bai, S., Zhao, H., and Wang, D. Vlas: Vision-language- action model with speech instructions for customized robot manipulation, 2025. URL https: //arxiv.org/abs/2502.13508
arXiv 2025
-
[52]
Ziebart, B. D., Maas, A. L., Bagnell, J. A., Dey, A. K., et al. Maximum entropy inverse reinforcement learning. InAaai, volume 8, pp. 1433–1438. Chicago, IL, USA, 2008. 12 Beyond Monotonic Progress A Implementation Details A.1 Value Model Training Data preprocessing.All value models are trained and evaluated using the same local 5 Hz data protocol. The ra...
arXiv 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.