CDPM-Align: Multi-Scale Guidance-Aligned Diffusion Pretraining for Robust Few-Shot Anatomical Landmark Detection
Pith reviewed 2026-06-28 06:39 UTC · model grok-4.3
The pith
Generative pre-training via multi-scale conditional diffusion learns robust representations that improve accuracy and uncertainty in few-shot anatomical landmark detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that generative pre-training with multi-scale guidance-aligned conditional diffusion on three heterogeneous small-scale benchmark datasets produces transferable representations. These representations improve both accuracy and uncertainty on the downstream landmark detection tasks when only 10 or 25 images are annotated, advancing towards safe and efficient clinical deployment.
What carries the argument
CDPM-Align, the multi-scale guidance-aligned conditional diffusion pre-training method that aligns generative guidance across scales to build robust representations from limited medical images.
If this is right
- Models initialized from this pre-training achieve higher localization accuracy than those trained from scratch when labeled data is restricted to 10 or 25 images.
- Uncertainty estimates become more reliable, reducing the risk of overconfident errors in clinical settings.
- The benefit holds across heterogeneous small-scale benchmarks, indicating the pre-training generalizes beyond any single dataset.
- Generative pre-training reduces the annotation effort needed to reach usable performance levels for anatomical landmark detection.
Where Pith is reading between the lines
- The same pre-training strategy could be tested on other medical imaging tasks that suffer from annotation scarcity, such as organ segmentation.
- Extending the pre-training corpus to include more imaging modalities might further strengthen transfer performance.
- If the uncertainty improvements hold, the method could support active learning loops that prioritize the most uncertain cases for additional labeling.
Load-bearing premise
Pretraining via the proposed multi-scale guidance-aligned conditional diffusion on three heterogeneous small-scale benchmark datasets will produce transferable representations that improve landmark detection performance and uncertainty in the specific low-annotation regimes of 10 and 25 images.
What would settle it
If the pre-trained models show no measurable gains over non-pretrained baselines in either mean localization error or uncertainty calibration metrics on the 10-image and 25-image downstream tasks across the three datasets, the claim would be falsified.
Figures
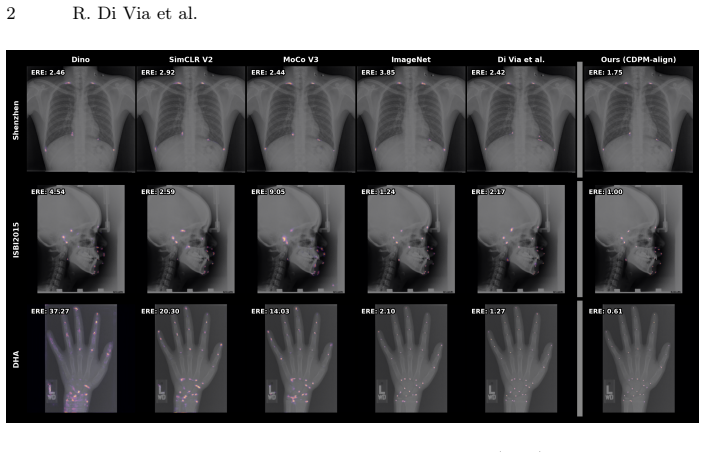
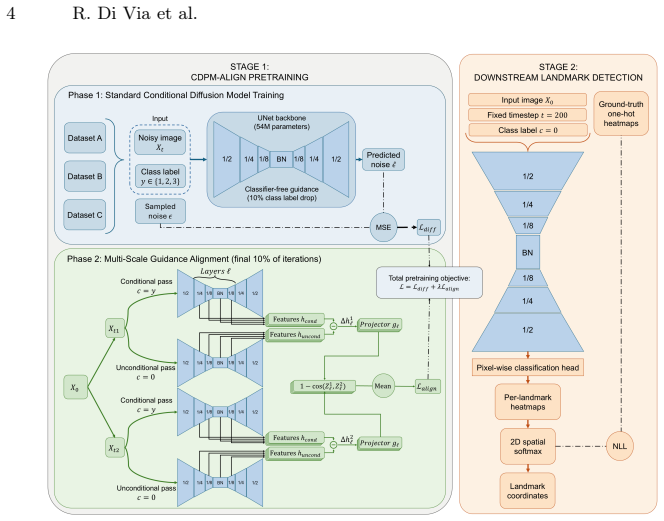
read the original abstract
Anatomical landmark detection is a fundamental task in medical image analysis supporting a wide range of diagnostic and interventional workflows. Although recent methods have achieved sub-millimetric localisation, accuracy alone is not sufficient for clinical deployment, requiring reliability and robustness in prediction. Despite its clinical relevance, the impact of representation learning in this context is still underexplored. In this work, we introduce CDPM-align, a multi-scale guidance-aligned conditional diffusion pre-training for anatomical landmark detection. Our experimental setup focuses on a few images and a few annotation regimes. Specifically, we employ three popular heterogeneous small-scale benchmark datasets for representation learning via conditional generative pre-training. Furthermore, we consider low-annotation scenarios for the downstream task of landmark detection, with 10 and 25 annotated images, reflecting realistic trade-offs between clinical effort and resource constraints for annotations. Our results confirm that generative pre-training enables the model to learn a robust representation. This improves both accuracy and uncertainty on the downstream tasks, advancing towards safe and efficient clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CDPM-Align, a multi-scale guidance-aligned conditional diffusion pre-training method for anatomical landmark detection. It performs generative pre-training on three heterogeneous small-scale benchmark datasets and evaluates the resulting representations in low-annotation downstream regimes (10 and 25 annotated images), claiming that this yields improved accuracy and uncertainty estimates relative to non-pretrained baselines.
Significance. If the empirical claims are substantiated with quantitative results, the work would address an underexplored aspect of representation learning for reliable landmark detection under realistic annotation constraints, with potential relevance to clinical workflows that require both precision and uncertainty awareness.
major comments (1)
- [Abstract] Abstract: The abstract states that experiments confirm generative pre-training improves accuracy and uncertainty but supplies no quantitative numbers, baselines, error bars, or ablation details; the central claim cannot be verified from the provided text.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comment. We address the concern about the abstract below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that experiments confirm generative pre-training improves accuracy and uncertainty but supplies no quantitative numbers, baselines, error bars, or ablation details; the central claim cannot be verified from the provided text.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The current abstract summarizes the experimental setup and high-level findings without specific metrics. In the revised version we will add concise quantitative statements (e.g., mean error reductions and uncertainty calibration improvements on the 10- and 25-shot regimes relative to the strongest non-pretrained baselines, with standard deviations), while remaining within the word limit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical study introducing CDPM-Align for multi-scale guidance-aligned conditional diffusion pre-training on three heterogeneous small-scale datasets, followed by downstream evaluation in 10- and 25-image annotation regimes for landmark detection. All load-bearing claims rest on experimental outcomes measuring accuracy and uncertainty improvements rather than any derivation chain, equations, fitted parameters renamed as predictions, or self-citation that reduces the result to its inputs by construction. No self-definitional steps, ansatz smuggling, or uniqueness theorems appear in the abstract or framing; the work is self-contained against external benchmarks with no visible reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional generative pretraining on heterogeneous small medical datasets produces representations that transfer to downstream landmark detection under low annotation.
Reference graph
Works this paper leans on
-
[1]
In: Proc
Baranchuk, D., Voynov, A., Rubachev, I., Khrulkov, V., Babenko, A.: Label- efficient semantic segmentation with diffusion models. In: Proc. ICLR (2022)
2022
-
[2]
arXiv preprint arXiv:2104.14294 (2021)
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294 (2021)
Pith/arXiv arXiv 2021
-
[3]
In: Advances in Neural Information Processing Systems
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.: Big self-supervised models are strong semi-supervised learners. In: Advances in Neural Information Processing Systems. vol. 33, pp. 21296–21309 (2020)
2020
-
[4]
In: Proc
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised vision transformers. In: Proc. ICCV. pp. 9640–9649 (2021)
2021
-
[5]
Electronics15(3), 589 (2025)
Choi, S.B., Ham, G.S., Oh, K.: Learning structural relations for robust chest x- ray landmark detection. Electronics15(3), 589 (2025). https://doi.org/10.3390/ electronics15030589
2025
-
[6]
In: Proc
Clement, A., Willoughby, J., Voiculescu, I.: Confidence in Angle Predictions for Clinical Decision Support. In: Proc. MICCAI. pp. 116–124 (2025)
2025
-
[7]
In: Proc
Di Via, R., Ciranni, M., Marinelli, D., Clement, A., Patel, N., Wyatt, J., Odone, F., Santacesaria, M., Voiculescu, I., Pastore, V.P.: Are x-ray landmark detection models fair? a preliminary assessment and mitigation strategy. In: Proc. ICCVW. pp. 272–278 (2025)
2025
-
[8]
In: Proc
Di Via, R., Odone, F., Pastore, V.P.: Self-supervised pre-training with diffusion model for few-shot landmark detection in x-ray images. In: Proc. WACV. pp. 3886–3894 (2025)
2025
-
[9]
arXiv preprint arXiv:2601.18555 (2026)
Di Via, R., Pastore, V.P., Odone, F., Glyn-Jones, S., Voiculescu, I.: Automated landmark detection for assessing hip conditions: A cross-modality validation of MRI versus x-ray. arXiv preprint arXiv:2601.18555 (2026)
arXiv 2026
-
[10]
Di Via, R., Santacesaria, M., Odone, F., Pastore, V.P.: Is in-domain data beneficial in transfer learning for landmarks detection in x-ray images? In: Proc. ISBI. pp. 1–5 (2024). https://doi.org/10.1109/ISBI56570.2024.10635861
-
[11]
arXiv preprint arXiv:2511.04255 (2025)
Elbatel, M., Wang, A., Liu, K., Mouheb, K., Almar-Munoz, E., et al.: MedSapi- ens: Taking a pose to rethink medical imaging landmark detection. arXiv preprint arXiv:2511.04255 (2025). https://doi.org/10.48550/arXiv.2511.04255
-
[12]
Gertych, A., Zhang, A., Sayre, J., Pospiech-Kurkowska, S., Huang, H.K.: Bone age assessment of children using a digital hand atlas. Comput. Med. Imaging Graph. 31(4–5), 322–331 (2007). https://doi.org/10.1016/j.compmedimag.2007.02.012
-
[13]
https://github.com/giakou4/pyssl (2023)
Giakoumoglou, N., Giakoumoglou, P.: PySSL: A PyTorch implementation of self- supervised learning methods. https://github.com/giakou4/pyssl (2023)
2023
-
[14]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6840–6851 (2020) 10 R. Di Via et al
2020
-
[15]
arXiv preprint arXiv:2207.12598 (2022)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
Pith/arXiv arXiv 2022
-
[16]
arXiv preprint arXiv:2502.14221 (2025)
Huang, Z., Tang, T., Xu, R., Wei, Y., Yang, W., et al.: H3DE-Net: Efficient and ac- curate 3D landmark detection in medical imaging. arXiv preprint arXiv:2502.14221 (2025)
arXiv 2025
-
[17]
Jaeger, S., Candemir, S., Antani, S., Wáng, Y.X.J., Lu, P.X., Thoma, G.: Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quant. Imaging Med. Surg.4(6), 475–477 (2014). https://doi.org/10.3978/j.issn. 2223-4292.2014.11.20
-
[18]
Frontiers in Artificial Intelligence6, 1142895 (2023)
Li, Z., Chen, W., Ju, Y., Chen, Y., Hou, Z., Li, X., Jiang, Y.: Bone age assessment based on deep neural networks with annotation-free cascaded critical bone region extraction. Frontiers in Artificial Intelligence6, 1142895 (2023). https://doi.org/ 10.3389/frai.2023.1142895
-
[19]
In: Proc
McCouat, J., Voiculescu, I.: Contour-hugging heatmaps for landmark detection. In: Proc. CVPR. pp. 20597–20605 (2022)
2022
-
[20]
In: Proc
Patel, N., Clement, A., Wyatt, J., Di Via, R., Marinelli, D., Ciranni, M., Pastore, V.P., Voiculescu, I.: A handful of data: Evaluating few-shot incremental land- mark detection. In: Proc. ICIAP. pp. 127–139 (2025). https://doi.org/10.1007/ 978-3-032-10192-1_11
2025
-
[21]
Medical Image Analysis 54, 207–219 (2019)
Payer,C.,Štern,D.,Bischof,H.,Urschler,M.:Integratingspatialconfigurationinto heatmap regression based cnns for landmark localization. Medical Image Analysis 54, 207–219 (2019). https://doi.org/10.1016/j.media.2019.03.012
-
[22]
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: FiLM: Visual reasoning with a general conditioning layer. In: Proc. AAAI. vol. 32, pp. 8101– 8108 (2018). https://doi.org/10.1609/aaai.v32i1.11671
-
[23]
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: Proc. MICCAI. pp. 234–241 (2015). https://doi.org/ 10.1007/978-3-319-24574-4_28
-
[24]
Journal of Advance and Future Research3(12), 692–702 (2025), https://rjwave.org/jaafr/papers/JAAFR2512414.pdf
Sanjas, A.M., Ida, A.M., Santhiya, S.G., Mercy, P.A.S., Nithya, S.A.: Deep learning–based automatic estimation of cardiometric coefficients from chest x- ray images. Journal of Advance and Future Research3(12), 692–702 (2025), https://rjwave.org/jaafr/papers/JAAFR2512414.pdf
2025
-
[25]
arXiv preprint arXiv:2507.11551 (2025)
Stansfield, E., Mitterer, J.A., Altahhan, A.: Landmark detection for medical im- ages using a general-purpose segmentation model. arXiv preprint arXiv:2507.11551 (2025)
arXiv 2025
-
[26]
Truong, T., Mohammadi, S., Lenga, M.: How transferable are self-supervised fea- tures in medical image classification tasks? In: Proc. ML4H. vol. 158, pp. 54–74 (2021)
2021
-
[27]
Medical Image Analysis 31, 63–76 (2016)
Wang, C.W., Huang, C.T., Lee, J.H., Li, C.H., Chang, S.W., et al.: A benchmark for comparison of dental radiography analysis algorithms. Medical Image Analysis 31, 63–76 (2016). https://doi.org/10.1016/j.media.2016.02.004
-
[28]
In: Proc
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.: ChestX-Ray14: Hospital-scale chest x-ray database and benchmarks. In: Proc. CVPR. pp. 2097– 2106 (2017)
2097
-
[29]
arXiv preprint arXiv:2410.04445 (2024)
Wyatt, J., Voiculescu, I.: Optimising for the unknown: Domain alignment for cephalometric landmark detection. arXiv preprint arXiv:2410.04445 (2024)
arXiv 2024
-
[30]
Yan, K., Cai, J., Jin, D., Miao, S., Guo, D., Harrison, A.P., Tang, Y., Xiao, J., Lu, J., Lu, L.: SAM: Self-supervised learning of pixel-wise anatomical embeddings in radiological images. IEEE Trans. Med. Imaging41(10), 2658–2669 (2022). https: //doi.org/10.1109/TMI.2022.3169003 CDPM-Align for Robust Landmark Detection 11
-
[31]
arXiv preprint arXiv:2412.06499 (2024)
Zhou, X., Huang, Z., Zhu, H., Yao, Q., Zhou, S.K.: Hybrid attention net- work: An efficient approach for anatomy-free landmark detection. arXiv preprint arXiv:2412.06499 (2024). https://doi.org/10.48550/arXiv.2412.06499
-
[32]
In: Proc
Zhu, H., Yao, Q., Mao, E., Zhou, S.K.: You only learn once: Universal anatomical landmark detection. In: Proc. MICCAI. pp. 84–94 (2021). https://doi.org/10.1007/ 978-3-030-87240-3_9
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.