Diverse Evidence, Better Forecasts: Multi-Agent Deliberation Under Information Asymmetry
Pith reviewed 2026-07-03 14:38 UTC · model grok-4.3
The pith
Partitioning evidence into public and private subsets for agents reduces inter-agent error correlation and improves multi-agent forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
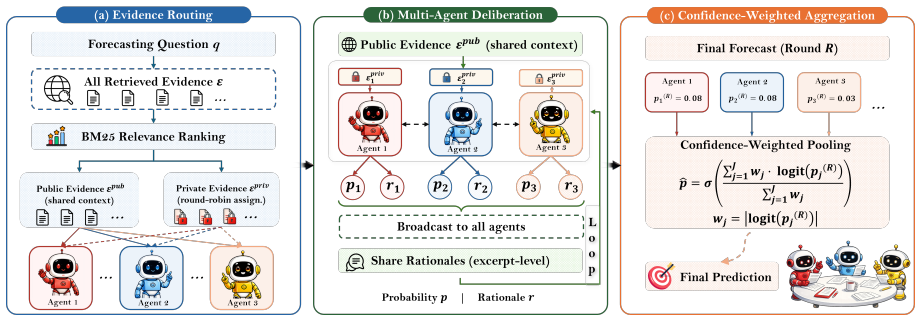
By partitioning evidence into shared public and disjoint private subsets, each agent holds exclusive knowledge that can only reach others through deliberation. This decomposition reduces inter-agent error correlation and improves forecasting performance when instantiated in the InfoDelphi framework on the PolyGym benchmark.
What carries the argument
Designed information asymmetry via partitioning evidence into shared public and disjoint private subsets, combined with relevance-aware routing, rationale-based iterative deliberation, and confidence-weighted aggregation.
If this is right
- Multi-agent forecasting systems should incorporate input diversity rather than uniform evidence to realize deliberation gains.
- Removing information asymmetry eliminates most of the performance improvements from multi-agent discussion.
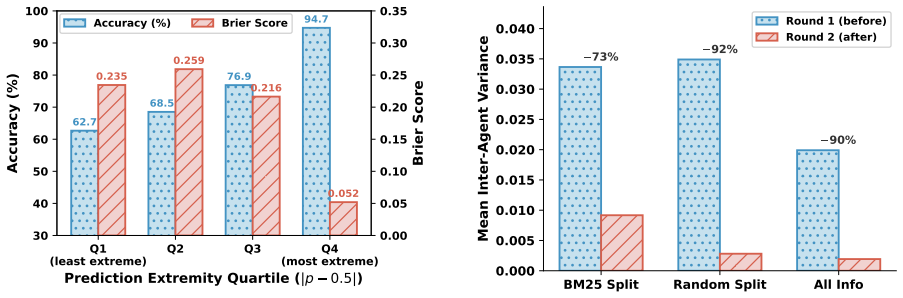
- InfoDelphi achieves 12-18% better Brier scores and 4-8 percentage point accuracy gains over strongest baselines on real prediction-market questions.
- Diversity of input, not merely the number of agents or deliberation rounds, is the key driver of effective multi-agent reasoning.
Where Pith is reading between the lines
- The same partitioning principle could be tested in non-forecasting multi-agent tasks such as collaborative problem solving.
- Human prediction teams might achieve similar gains by deliberately withholding some private data until discussion occurs.
- Automated methods for deciding the public-private split size could further optimize the approach without manual tuning.
Load-bearing premise
Evidence can be partitioned into meaningful public and private subsets such that the private portions are both non-redundant and correctly routed without introducing new biases or information loss.
What would settle it
An experiment in which agents receive partitioned evidence yet exhibit the same level of error correlation and forecast accuracy as agents given identical evidence to all.
Figures


read the original abstract
Multi-agent systems are increasingly used for forecasting future events, as deliberation among multiple LLMs is believed to improve reasoning and calibration. Yet existing approaches overlook a critical design choice: what information each agent receives. When all agents are given identical evidence, deliberation collapses into herding rather than genuine belief revision, leaving multi-agent systems little better than a single agent. We identify this as a fundamental gap and propose designed information asymmetry to close it: by partitioning evidence into shared public and disjoint private subsets, each agent holds exclusive knowledge that can only reach others through deliberation. We theoretically show that this decomposition reduces inter-agent error correlation, and instantiate it in InfoDelphi, a framework combining relevance-aware evidence routing, rationale-based iterative deliberation, and confidence-weighted aggregation. On PolyGym, a benchmark of 375 binary forecasting questions derived from real-world prediction markets, InfoDelphi outperforms the strongest single-agent and multi-agent baselines by 12--18% in Brier score and 4--8 percentage points in accuracy. More detailed experiments confirm that removing information asymmetry eliminates most deliberation gains, establishing diversity of input as the key enabler of effective multi-agent reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard multi-agent LLM deliberation fails when all agents receive identical evidence because it leads to herding rather than genuine belief revision. It proposes designed information asymmetry via partitioning evidence into shared public and disjoint private subsets, theoretically showing this reduces inter-agent error correlation. The authors instantiate the idea in InfoDelphi, which uses relevance-aware evidence routing, rationale-based iterative deliberation, and confidence-weighted aggregation. On the PolyGym benchmark of 375 binary forecasting questions from real prediction markets, InfoDelphi outperforms single-agent and multi-agent baselines by 12-18% in Brier score and 4-8 percentage points in accuracy; ablations indicate that removing asymmetry largely eliminates the gains.
Significance. If the central claim holds, the work would be significant for the design of multi-agent LLM systems in forecasting and reasoning. It identifies input diversity as a load-bearing factor that existing deliberation methods overlook, supplies a concrete framework combining routing and iterative exchange, and reports sizable gains on a benchmark derived from real-world markets. The explicit link between the theoretical correlation-reduction argument and the empirical ablations is a strength.
major comments (3)
- [§3] §3 (Theoretical Analysis): The argument that partitioning into public/private subsets reduces error correlation models the private subsets as independent and non-overlapping. It is not shown that the relevance-aware routing procedure (detailed in §4.2) preserves this independence; if the router assigns correlated signals to multiple agents or filters non-redundant private information, the claimed reduction does not follow from the decomposition alone.
- [§5.3] §5.3 (Ablation studies): The result that gains disappear when asymmetry is removed is consistent with the hypothesis, yet the experiments do not compare against alternative partitioning schemes or routing heuristics that would still create asymmetry. Without such controls it remains unclear whether the observed improvement is attributable to the public/private decomposition or to the specific routing implementation.
- [Table 4] Table 4 (PolyGym results): The reported 12-18% Brier-score improvement is load-bearing for the central claim, but the baseline implementations are not described in sufficient detail (e.g., whether they use the same evidence pool or identical routing logic). This makes it difficult to isolate the contribution of information asymmetry from other implementation choices.
minor comments (2)
- [Figure 1] Figure 1: The diagram of public/private evidence flow would benefit from explicit labels indicating which arrows represent routed private evidence versus shared public evidence.
- [§4.1] §4.1: The definition of the relevance scoring function is introduced without stating whether it is learned or hand-crafted; a short clarification would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments identify important areas for clarification and strengthening, particularly around the link between theory and implementation, the specificity of ablations, and baseline descriptions. We address each major comment below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Analysis): The argument that partitioning into public/private subsets reduces error correlation models the private subsets as independent and non-overlapping. It is not shown that the relevance-aware routing procedure (detailed in §4.2) preserves this independence; if the router assigns correlated signals to multiple agents or filters non-redundant private information, the claimed reduction does not follow from the decomposition alone.
Authors: The theoretical decomposition in §3 shows that error correlation is reduced when private subsets are independent and non-overlapping by construction. The relevance-aware router in §4.2 assigns private evidence from disjoint pools using per-agent relevance scores, which by design prevents overlap. We agree, however, that a formal argument that the router's selections preserve statistical independence (as opposed to mere disjointness) is not supplied. In revision we will add a clarifying paragraph to §3 stating the maintained assumptions and noting that the router's relevance-based selection from disjoint pools is intended to satisfy the conditions of the theorem; we will also reference the ablation results as empirical support. revision: partial
-
Referee: [§5.3] §5.3 (Ablation studies): The result that gains disappear when asymmetry is removed is consistent with the hypothesis, yet the experiments do not compare against alternative partitioning schemes or routing heuristics that would still create asymmetry. Without such controls it remains unclear whether the observed improvement is attributable to the public/private decomposition or to the specific routing implementation.
Authors: The §5.3 ablation isolates the necessity of asymmetry by showing that its removal largely eliminates gains. We acknowledge that additional controls comparing our routing to other asymmetry-inducing schemes (e.g., random partitioning) would further isolate the contribution of the specific public/private design. In the revised manuscript we will add a random-partitioning ablation to §5.3; this will help demonstrate that the structured relevance-aware decomposition, rather than asymmetry alone, drives the observed improvements. revision: yes
-
Referee: [Table 4] Table 4 (PolyGym results): The reported 12-18% Brier-score improvement is load-bearing for the central claim, but the baseline implementations are not described in sufficient detail (e.g., whether they use the same evidence pool or identical routing logic). This makes it difficult to isolate the contribution of information asymmetry from other implementation choices.
Authors: We agree that insufficient detail on baselines hinders attribution. All methods operate over the identical evidence pool; standard multi-agent baselines receive the full pool without partitioning or relevance routing, while single-agent baselines also receive the full pool. In revision we will expand §5.1 and the Table 4 caption to explicitly document these implementation choices, the absence of routing in baselines, and the exact prompting and aggregation procedures used, thereby clarifying that the performance gap is attributable to the introduction of designed asymmetry. revision: yes
Circularity Check
No significant circularity; theoretical reduction and empirical gains are independently derived and validated.
full rationale
The paper's core derivation states that partitioning evidence into public and disjoint private subsets reduces inter-agent error correlation, presented as a theoretical result from the decomposition itself rather than a fitted parameter or self-referential definition. Empirical performance on the PolyGym benchmark (derived from external prediction markets) and the ablation removing asymmetry are separate validations that do not reduce to the input partitioning by construction. No load-bearing self-citations, ansatz smuggling, or renaming of known results appear in the described chain; the relevance-aware routing is an instantiation step whose independence from benchmark construction is not contradicted by the given text. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[2]
International conference on machine learning , pages=
Retrieval augmented language model pre-training , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[3]
Advances in Neural Information Processing Systems , volume=
Approaching human-level forecasting with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Izacard, Gautier and Grave, Edouard. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021
2021
-
[5]
Paleka, D., Goel, S., Geiping, J., and Tram`er, F
Forecastbench: A dynamic benchmark of ai forecasting capabilities , author=. arXiv preprint arXiv:2409.19839 , year=
-
[6]
arXiv preprint arXiv:2511.03628 , year=
Livetradebench: Seeking real-world alpha with large language models , author=. arXiv preprint arXiv:2511.03628 , year=
-
[7]
DeGroot , journal =
Morris H. DeGroot , journal =. Reaching a Consensus , urldate =
-
[8]
Stone , journal =
M. Stone , journal =. The Opinion Pool , urldate =
-
[9]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Ranjan, Roopesh and Gneiting, Tilmann , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2010 , month =. doi:10.1111/j.1467-9868.2009.00726.x , url =
-
[10]
Combining multiple probability predictions using a simple logit model , journal =. 2014 , issn =. doi:https://doi.org/10.1016/j.ijforecast.2013.09.009 , url =
-
[11]
Proceedings of the fifteenth ACM conference on Economics and computation , pages=
Information aggregation in exponential family markets , author=. Proceedings of the fifteenth ACM conference on Economics and computation , pages=
-
[12]
Zidek , title =
Christian Genest and James V. Zidek , title =. Statistical Science , number =. 1986 , doi =
1986
-
[13]
Advances in Neural Information Processing Systems , volume=
Forecasting future world events with neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2310.13014 , year=
Large language model prediction capabilities: Evidence from a real-world forecasting tournament , author=. arXiv preprint arXiv:2310.13014 , year=
-
[15]
The Twelfth International Conference on Learning Representations , year=
AutoCast++: Enhancing World Event Prediction with Zero-shot Ranking-based Context Retrieval , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
It's High Time: A Survey of Temporal Question Answering
It's High Time: A Survey of Temporal Question Answering , author=. arXiv preprint arXiv:2505.20243 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Workshop on Scaling Environments for Agents , year=
Scaling Open-Ended Reasoning to Predict the Future , author=. Workshop on Scaling Environments for Agents , year=
-
[18]
arXiv preprint arXiv:2502.05253 , year=
Llms can teach themselves to better predict the future , author=. arXiv preprint arXiv:2502.05253 , year=
-
[19]
Science Advances , volume=
Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy , author=. Science Advances , volume=. 2024 , publisher=
2024
-
[20]
The Eleventh International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[21]
The Thirteenth International Conference on Learning Representations , year=
Mixture-of-Agents Enhances Large Language Model Capabilities , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
arXiv preprint arXiv:2508.11987 , year=
Futurex: An advanced live benchmark for llm agents in future prediction , author=. arXiv preprint arXiv:2508.11987 , year=
-
[23]
arXiv preprint arXiv:2506.00723 , year=
Pitfalls in evaluating language model forecasters , author=. arXiv preprint arXiv:2506.00723 , year=
-
[24]
Teaching Models to Express Their Uncertainty in Words
Teaching models to express their uncertainty in words , author=. arXiv preprint arXiv:2205.14334 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[26]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reconcile: Round-table conference improves reasoning via consensus among diverse llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
An experimental study of group opinion: The Delphi method , journal =. 1969 , issn =. doi:https://doi.org/10.1016/S0016-3287(69)80025-X , url =
-
[28]
Ravi Lonkani and Chuleeporn Changchit and Thanu Prasertsoontorn and Alicha Treerotchananon , keywords =. Psychological influences on forecast bias: The impact of mood, depression, and trading performance on investor expectations , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.actpsy.2025.106120 , url =
-
[29]
Proceedings of the National Academy of Sciences , year=
How social influence can undermine the wisdom of crowd effect , author=. Proceedings of the National Academy of Sciences , year=
-
[30]
Journal of political Economy , volume=
A theory of fads, fashion, custom, and cultural change as informational cascades , author=. Journal of political Economy , volume=. 1992 , publisher=
1992
-
[31]
2005 , publisher=
Expert Political Judgment: How Good Is It? How Can We Know? , author=. 2005 , publisher=
2005
-
[32]
Forty-second International Conference on Machine Learning , year=
Correlated Errors in Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Debate or vote: Which yields better decisions in multi-agent large language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2602.08003 , year=
Don't Always Pick the Highest-Performing Model: An Information Theoretic View of LLM Ensemble Selection , author=. arXiv preprint arXiv:2602.08003 , year=
-
[35]
Journal of machine learning research , volume=
A unified theory of diversity in ensemble learning , author=. Journal of machine learning research , volume=
-
[36]
The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning
The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning , author=. arXiv preprint arXiv:2605.01704 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[38]
2004 , isbn =
Surowiecki, James , title =. 2004 , isbn =
2004
-
[39]
Lu Hong and Scott E. Page , title =. Proceedings of the National Academy of Sciences , volume =. 2004 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.0403723101 , abstract =
-
[40]
Proceedings of EMNLP 2021 , year=
FinQA: A Dataset of Numerical Reasoning over Financial Data , author=. Proceedings of EMNLP 2021 , year=
2021
-
[41]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[42]
2025 , howpublished=
Polymarket Prediction Markets Dataset , author=. 2025 , howpublished=
2025
-
[43]
arXiv preprint arXiv:2511.07678 , year=
AIA Forecaster: Technical Report , author=. arXiv preprint arXiv:2511.07678 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Language models can improve event prediction by few-shot abductive reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[47]
2026 , eprint=
PolyBench: Benchmarking LLM Forecasting and Trading Capabilities on Live Prediction Market Data , author=. 2026 , eprint=
2026
-
[48]
International Conference on Machine Learning , year=
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle , author=. International Conference on Machine Learning , year=
-
[49]
2026 , eprint=
Prediction Arena: Benchmarking AI Models on Real-World Prediction Markets , author=. 2026 , eprint=
2026
-
[50]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes , author=. arXiv preprint arXiv:2601.11659 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.