Spatial Speech Perception Systems: A Survey of Sound Source Localization, Directional Enhancement, and Speech Recognition
Pith reviewed 2026-07-03 04:50 UTC · model grok-4.3
The pith
Spatial speech perception systems integrate sound source localization, directional enhancement, and speech recognition to handle real-world noise and reverberation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that microphone-array information enables robust speech understanding in complex acoustic scenes by combining SSL for locating sources, DSE for enhancing target speech while suppressing interference, and ASR for interpretation, with both standalone and end-to-end pipeline approaches reviewed across classical and data-driven techniques.
What carries the argument
The integrated processing pipeline of sound source localization (SSL), directional speech enhancement (DSE), and automatic speech recognition (ASR) that exploits microphone-array data.
Load-bearing premise
The papers and methods chosen for review represent the current field without major omissions or biases in coverage of classical and learning-based approaches.
What would settle it
A search that identifies multiple significant recent papers or standard methods on SSL, DSE, or integrated ASR pipelines absent from the survey would indicate the review is incomplete.
Figures

read the original abstract
Robust speech understanding in real-world acoustic environments remains a fundamental challenge for intelligent auditory systems such as robot audition, hearing aids, teleconferencing systems, smart speakers, and voice-controlled assistants. These systems must operate under background noise, reverberation, competing speakers, and dynamic acoustic conditions. Spatial speech perception addresses this challenge by exploiting microphone-array information to localize, enhance, and interpret target speech in complex acoustic scenes. This paper surveys spatial speech perception systems with emphasis on the roles of sound source localization (SSL), directional speech enhancement (DSE), and automatic speech recognition (ASR), both individually and within integrated processing pipelines. We review classical signal-processing approaches and recent learning-based methods for microphone-array localization, beamforming, neural enhancement, speech separation, and modern recognition architectures. Beyond component-level analysis, we discuss robustness to noise and reverberation, multi-speaker operation, real-time constraints, and computational efficiency. We also examine representative applications in robot audition, hearing assistance, smart speakers, and teleconferencing, and identify open challenges and future directions toward robust, low-latency, and perception-aware speech systems for complex acoustic environments.
Editorial analysis
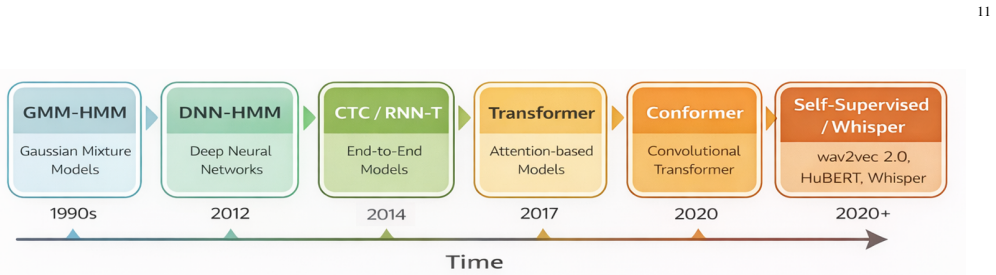
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys spatial speech perception systems, emphasizing the roles of sound source localization (SSL), directional speech enhancement (DSE), and automatic speech recognition (ASR) both as individual components and within integrated pipelines. It reviews classical signal-processing approaches alongside recent learning-based methods for microphone-array localization, beamforming, neural enhancement, speech separation, and modern recognition architectures, while addressing robustness to noise and reverberation, multi-speaker scenarios, real-time constraints, computational efficiency, representative applications (robot audition, hearing aids, smart speakers, teleconferencing), and open challenges for robust low-latency systems.
Significance. If the reviewed literature is representative, the survey would provide a useful consolidation of work on spatial audio processing pipelines, helping to map connections between SSL, DSE, and ASR and to highlight directions toward perception-aware systems; its value lies in the descriptive synthesis rather than new derivations or empirical results.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the manuscript and for recommending acceptance. Their summary correctly reflects the paper's focus on integrating SSL, DSE, and ASR within spatial speech perception pipelines.
Circularity Check
No significant circularity: survey of external literature
full rationale
This paper is a survey reviewing SSL, DSE, and ASR methods from external sources. It contains no derivations, equations, predictions, fitted parameters, or theorems whose validity depends on internal assumptions or self-citations. The central claim is descriptive (review of literature and pipelines), with no load-bearing steps that reduce to the paper's own inputs by construction. All content is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Some experiments on the recognition of speech, with one and with two ears,
E. C. Cherry, “Some experiments on the recognition of speech, with one and with two ears,”The Journal of the Acoustical Society of America, vol. 25, no. 5, pp. 975–979, 1953
1953
-
[2]
A. S. Bregman,Auditory Scene Analysis: The Perceptual Organization of Sound. The MIT Press, 05 1990. [Online]. Available: https: //doi.org/10.7551/mitpress/1486.001.0001
-
[3]
The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions,
A. W. Bronkhorst, “The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions,”ACUS- TICA united with acta acustica, vol. 86, no. 1, pp. 117–128, 2000
2000
-
[4]
Far-field automatic speech recognition,
R. Haeb-Umbach, J. Heymann, L. Drude, S. Watanabe, M. Delcroix, and T. Nakatani, “Far-field automatic speech recognition,”Proceedings of the IEEE, vol. 109, no. 2, pp. 124–148, 2021
2021
-
[5]
The fifth 'CHiME' Speech Separation and Recognition Challenge: Dataset, task and baselines
J. Barker, S. Watanabe, E. Vincent, and J. Trmal, “The fifth ’chime’ speech separation and recognition challenge: Dataset, task and baselines,” 2018. [Online]. Available: https://arxiv.org/abs/1803.10609
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Chime-6 challenge:tackling multispeaker speech recognition for unsegmented recordings,
S. Watanabe, M. Mandel, J. Barker, E. Vincent, A. Arora, X. Chang, S. Khudanpur, V . Manohar, D. Povey, D. Raj, D. Snyder, A. S. Subramanian, J. Trmal, B. B. Yair, C. Boeddeker, Z. Ni, Y . Fujita, S. Horiguchi, N. Kanda, T. Yoshioka, and N. Ryant, “Chime-6 challenge:tackling multispeaker speech recognition for unsegmented recordings,” 2020. [Online]. Avai...
-
[7]
Brandstein and H
M. Brandstein and H. Silverman,Microphone Arrays: Signal Process- ing Techniques and Applications. Springer, 2001
2001
-
[8]
Acoustic beamform- ing for hearing aid applications,
S. Doclo, S. Gannot, M. Moonen, and A. Spriet, “Acoustic beamform- ing for hearing aid applications,” inHandbook on Array Processing and Sensor Networks, S. Haykin and K. J. R. Liu, Eds. Wiley, 2010, pp. 269–302
2010
-
[9]
Robot audition and computational auditory scene analysis,
K. Nakadai and H. G. Okuno, “Robot audition and computational auditory scene analysis,”Advanced Intelligent Systems, vol. 2, no. 9, p. 2000050, 2020. [Online]. Available: https://advanced.onlinelibrary. wiley.com/doi/abs/10.1002/aisy.202000050
-
[10]
A survey of sound source localization with deep learning methods,
P.-A. Grumiauxet al., “A survey of sound source localization with deep learning methods,”The Journal of the Acoustical Society of America, vol. 152, no. 1, pp. 107–136, 2022. [Online]. Available: https://pubs.aip.org/asa/jasa/article/152/1/107/ 2838290/A-survey-of-sound-source-localization-with-deep
2022
-
[11]
A survey of sound source localization and detection methods and their applications,
G. Jekatery ´nczuket al., “A survey of sound source localization and detection methods and their applications,”Sensors, 2023. [Online]. Available: https://pmc.ncbi.nlm.nih.gov/articles/PMC10781166/
2023
-
[12]
Deep clustering: Discriminative embeddings for segmentation and separation
J. R. Hershey, Z. Chen, J. L. Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” 2015. [Online]. Available: https://arxiv.org/abs/1508.04306
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Deep attractor network for single-microphone speaker separation,
Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Mar. 2017, p. 246–250. [Online]. Available: http://dx.doi.org/ 10.1109/ICASSP.2017.7952155
-
[14]
All neural low-latency directional speech extraction,
A. Pandey, S. Lee, J. Azcarreta, D. Wong, and B. Xu, “All neural low-latency directional speech extraction,” 2024. [Online]. Available: https://arxiv.org/abs/2407.04879
-
[15]
Neural directed speech enhancement with dual microphone array in high noise scenario,
W. Wen, Q. Zhou, Y . Xi, H. Li, Z. Gong, and K. Yu, “Neural directed speech enhancement with dual microphone array in high noise scenario,” 2024. [Online]. Available: https://arxiv.org/abs/2412.18141
-
[16]
End-to-end doa-guided speech extraction in noisy multi-talker scenarios,
K. Jing, W. Zhang, and Y . Gao, “End-to-end doa-guided speech extraction in noisy multi-talker scenarios,” 2025. [Online]. Available: https://arxiv.org/abs/2507.20926
-
[17]
Automatic speech recognition: A survey of deep learning techniques and approaches,
H. Ahlawat, N. Aggarwal, and D. Gupta, “Automatic speech recognition: A survey of deep learning techniques and approaches,” International Journal of Cognitive Computing in Engineering, vol. 6, pp. 201–237, 2025. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S2666307424000573
2025
-
[18]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–2...
2023
-
[19]
Fastemit: Low- latency streaming asr with sequence-level emission regularization,
J. Yu, C.-C. Chiu, B. Li, S. yiin Chang, T. N. Sainath, Y . He, A. Narayanan, W. Han, A. Gulati, Y . Wu, and R. Pang, “Fastemit: Low- latency streaming asr with sequence-level emission regularization,”
-
[20]
Available: https://arxiv.org/abs/2010.11148
[Online]. Available: https://arxiv.org/abs/2010.11148
-
[21]
Performance and efficiency evaluation of asr inference on the edge,
S. Gondi and V . Pratap, “Performance and efficiency evaluation of asr inference on the edge,”Sustainability, vol. 13, no. 22, 2021. [Online]. Available: https://www.mdpi.com/2071-1050/13/22/12392
2021
-
[22]
The generalized correlation method for estimation of time delay,
C. Knapp and G. C. Carter, “The generalized correlation method for estimation of time delay,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 24, no. 4, pp. 320–327, 1976
1976
-
[23]
Multiple emitter location and signal parameter estima- tion,
R. O. Schmidt, “Multiple emitter location and signal parameter estima- tion,”IEEE Transactions on Antennas and Propagation, vol. 34, no. 3, pp. 276–280, 1986
1986
-
[24]
High-resolution frequency-wavenumber spectrum analysis,
J. Capon, “High-resolution frequency-wavenumber spectrum analysis,” Proceedings of the IEEE, vol. 57, no. 8, pp. 1408–1418, 1969
1969
-
[25]
An alternative approach to linearly constrained adaptive beamforming,
L. Griffiths and C. Jim, “An alternative approach to linearly constrained adaptive beamforming,”IEEE Transactions on Antennas and Propaga- tion, vol. 30, no. 1, pp. 27–34, 1982
1982
-
[26]
Fasnet: Low- latency adaptive beamforming for multi-microphone audio processing,
Y . Luo, E. Ceolini, C. Han, S.-C. Liu, and N. Mesgarani, “Fasnet: Low- latency adaptive beamforming for multi-microphone audio processing,”
-
[27]
Available: https://arxiv.org/abs/1909.13387
[Online]. Available: https://arxiv.org/abs/1909.13387
-
[28]
A tutorial on hidden markov models and selected applica- tions in speech recognition,
L. Rabiner, “A tutorial on hidden markov models and selected applica- tions in speech recognition,”Proceedings of the IEEE, vol. 77, no. 2, pp. 257–286, 1989
1989
-
[29]
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V . Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,”IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82–97, 2012
2012
-
[30]
Connection- ist temporal classification: labelling unsegmented sequence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Connection- ist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” inProceedings of the 23rd international conference on Machine learning, 2006, pp. 369–376
2006
-
[31]
Sequence transduction with recurrent neural networks,
A. Graves, “Sequence transduction with recurrent neural networks,”
-
[32]
Sequence Transduction with Recurrent Neural Networks
[Online]. Available: https://arxiv.org/abs/1211.3711
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017. [Online]. Available: https://pr...
2017
-
[34]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented transformer for speech recognition,” 2020. [Online]. Available: https://arxiv.org/abs/2005.08100
-
[35]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevskiet al., “wav2vec 2.0: A framework for self-supervised learning of speech representations,” inNeurIPS, 2020. [Online]. Available: https://arxiv.org/abs/2006.11477
-
[36]
Development of microphone-array-embedded uav for search and rescue task,
K. Nakadai, M. Kumon, H. G. Okuno, K. Hoshiba, M. Wakabayashi, K. Washizaki, T. Ishiki, D. Gabriel, Y . Bando, T. Morito, R. Kojima, and O. Sugiyama, “Development of microphone-array-embedded uav for search and rescue task,” in2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 5985–5990
2017
-
[37]
Odas: Open embedded audition system,
F. Grondin, D. L ´etourneau, C. Godin, J.-S. Lauzon, J. Vincent, S. Michaud, S. Faucher, and F. Michaud, “Odas: Open embedded audition system,” 2022. [Online]. Available: https://arxiv.org/abs/2103. 03954
2022
-
[38]
High-accuracy tdoa-based localization without time synchronization,
B. Xu, G. Sun, R. Yu, and Z. Yang, “High-accuracy tdoa-based localization without time synchronization,”Parallel and Distributed Systems, IEEE Transactions on, vol. 24, pp. 1567–1576, 08 2013
2013
-
[39]
Time delay estimation in the presence of cor- related noise and reverberation,
Y . Rui and D. Florencio, “Time delay estimation in the presence of cor- related noise and reverberation,” inProceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2004
2004
-
[40]
A robust method for speech signal time-delay estimation in the presence of reverberation and noise,
H. F. Silverman, Y . Yu, J. Sachar, and W. Patterson, “A robust method for speech signal time-delay estimation in the presence of reverberation and noise,” inProceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 1997
1997
-
[41]
H. L. Van Trees,Optimum Array Processing: Part IV of Detection, Estimation, and Modulation Theory. New York: Wiley, 2002
2002
-
[42]
P.-O. Lagac ´e, F. Ferland, and F. Grondin, “Ego-noise reduction of a mobile robot using noise spatial covariance matrix learning and minimum variance distortionless response,” 2023. [Online]. Available: https://arxiv.org/abs/2303.00829
-
[43]
Sound source localization for human-robot interaction in outdoor environments,
V . Liu, T. Du, J. Sehn, J. Collier, and F. Grondin, “Sound source localization for human-robot interaction in outdoor environments,”
-
[44]
Available: https://arxiv.org/abs/2507.21431
[Online]. Available: https://arxiv.org/abs/2507.21431
-
[45]
Fast and robust 3-d sound source localiza- tion with dsvd-phat,
F. Grondin and J. Glass, “Fast and robust 3-d sound source localiza- tion with dsvd-phat,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 5352–5357
2019
-
[46]
Development of a high- precision multi-source localization system based on duet-srp-phat,
Y . Jiang, R. Hang, B. Liu, S. Yang, and Y . Xu, “Development of a high- precision multi-source localization system based on duet-srp-phat,” in 2024 20th International Conference on Natural Computation, Fuzzy 26 Systems and Knowledge Discovery (ICNC-FSKD), 2024. [Online]. Available: https://doi.org/10.1109/icnc-fskd64080.2024.10702295
-
[47]
Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide- band sources,
H. Wang and M. Kaveh, “Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide- band sources,”IEEE Transactions on Acoustics, Speech, and Signal Processing, 1985
1985
-
[48]
Intelligent sound source localization for dynamic environments,
K. Nakamura, K. Nakadai, F. Asano, Y . Hasegawa, and H. Tsujino, “Intelligent sound source localization for dynamic environments,” in 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2009, pp. 664–669
2009
-
[49]
Real-time super-resolution sound source localization for robots,
K. Nakamura, K. Nakadai, and G. Ince, “Real-time super-resolution sound source localization for robots,” in2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012, pp. 694–699
2012
-
[50]
Improvement in outdoor sound source detection using a quadrotor- embedded microphone array,
T. Ohata, K. Nakamura, T. Mizumoto, T. Taiki, and K. Nakadai, “Improvement in outdoor sound source detection using a quadrotor- embedded microphone array,” in2014 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems, 2014, pp. 1902–1907
2014
-
[51]
Broadband doa estimation using convolutional neural networks trained with noise signals,
S. Chakrabarty and E. A. P. Habets, “Broadband doa estimation using convolutional neural networks trained with noise signals,” in 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, Oct. 2017, p. 136–140. [Online]. Available: http://dx.doi.org/10.1109/W ASPAA.2017.8170010
work page doi:10.1109/w 2017
-
[52]
Deep neural networks for multiple speaker detection and localization,
W. He, P. Motlicek, and J.-M. Odobez, “Deep neural networks for multiple speaker detection and localization,” in2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, May 2018, p. 74–79. [Online]. Available: http://dx.doi.org/10.1109/ ICRA.2018.8461267
-
[53]
Sound source localization for auditory perception of a humanoid robot using deep neural networks,
G. Boztas, “Sound source localization for auditory perception of a humanoid robot using deep neural networks,”Neural Computing and Applications, vol. 35, pp. 6801–6811, 2023, published 29 November 2022, Issue date March 2023. [Online]. Available: https://doi.org/10.1007/s00521-022-08047-x
-
[54]
Gcc-phat with speech- oriented attention for robotic sound source localization,
J. Wang, X. Qian, Z. Pan, M. Zhang, and H. Li, “Gcc-phat with speech- oriented attention for robotic sound source localization,” in2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 5876–5883
2021
-
[56]
[Online]. Available: http://arxiv.org/abs/1807.00129
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Sound event localization and detection using imbalanced real and synthetic data via multi-generator,
Y . C. Shin and C. Chun, “Sound event localization and detection using imbalanced real and synthetic data via multi-generator,” Sensors (Basel, Switzerland), vol. 23, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257745516
2023
-
[58]
The nerc-slip system for sound event localization and detection of dcase2022 challenge,
Q. Wang, L. Chai, H. Wu, Z. Nian, S. Niu, S. Zheng, Y . Wang, L. Sun, Y . Fang, J. Pan, J. Du, and C.-H. Lee, “The nerc-slip system for sound event localization and detection of dcase2022 challenge,” DCASE2022 Challenge, Tech. Rep., June 2022, technical Report. [Online]. Available: https://dcase.community/documents/ challenge2022/technical reports/DCASE20...
2022
-
[59]
Microphone pair training for robust sound source localization with diverse array configurations,
I. An, G. An, T. Kim, and S.-e. Yoon, “Microphone pair training for robust sound source localization with diverse array configurations,” IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 319–326, 2024
2024
-
[60]
Multiple sound sources localization using sub-band spatial features and attention mechanism,
D. Zhang, J. Chen, J. Baiet al., “Multiple sound sources localization using sub-band spatial features and attention mechanism,”Circuits, Systems, and Signal Processing, vol. 44, pp. 2592–2620, 2025, published 13 December 2024, Issue date April 2025. [Online]. Available: https://doi.org/10.1007/s00034-024-02925-6
-
[61]
A hybrid CNN-LSTM model for environmental sound classification: Leveraging feature engineering and transfer learning,
R. Akter, M. R. Islam, S. K. Debnath, P. K. Sarker, and M. K. Uddin, “A hybrid CNN-LSTM model for environmental sound classification: Leveraging feature engineering and transfer learning,”Digital Signal Processing, vol. 163, p. 105234, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1051200425002568
2025
-
[62]
Single- microphone-based sound source localization for mobile robots in reverberant environments,
J. Wang, R. Shi, B. Yen, H. Kong, and K. Nakadai, “Single- microphone-based sound source localization for mobile robots in reverberant environments,” 2025. [Online]. Available: https: //arxiv.org/abs/2506.16173
-
[63]
Ipdnet2: an efficient and improved inter-channel phase difference estimation network for sound source localization,
Y . Wang, B. Yang, and X. Li, “Ipdnet2: an efficient and improved inter-channel phase difference estimation network for sound source localization,” 2025. [Online]. Available: https://arxiv.org/abs/2509. 21900
2025
-
[64]
Multi-Speaker DOA Estimation in Binaural Hearing Aids using Deep Learning and Speaker Count Fusion
F. Jazaeri, H. Kamkar-Parsi, F. Grondin, and M. Bouchard, “Multi-speaker doa estimation in binaural hearing aids using deep learning and speaker count fusion,” 2025. [Online]. Available: https://arxiv.org/abs/2509.21382
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Auralnet: Hierarchical attention-based 3d binaural localization of overlapping speakers,
L. Fu, Y . Liu, Z. Liu, Z. Yang, Z.-Q. Wang, Y . Li, and H. Kong, “Auralnet: Hierarchical attention-based 3d binaural localization of overlapping speakers,” 2025. [Online]. Available: https://arxiv.org/abs/ 2506.02773
-
[66]
Insights into deep non-linear filters for improved multi-channel speech enhancement,
K. Tesch and T. Gerkmann, “Insights into deep non-linear filters for improved multi-channel speech enhancement,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, p. 563–575, 2023. [Online]. Available: http://dx.doi.org/10.1109/TASLP. 2022.3221046
-
[67]
Turning whisper into real-time transcription system,
D. Mach ´aˇcek, R. Dabre, and O. Bojar, “Turning whisper into real-time transcription system,” inProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics: System Demonstrations, S. Saha and H. Sujaini, Eds. Bali, Indonesia: Asso...
2023
-
[68]
Simultaneous translation with offline speech and LLM models in CUNI submission to IWSLT 2025,
D. Mach ´aˇcek and P. Pol ´ak, “Simultaneous translation with offline speech and LLM models in CUNI submission to IWSLT 2025,” inProceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), E. Salesky, M. Federico, and A. Anastasopoulos, Eds. Vienna, Austria (in-person and online): Association for Computational Linguistics...
2025
-
[69]
data2vec: A general framework for self-supervised learning in speech, vision and language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A general framework for self-supervised learning in speech, vision and language,” inProceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, Eds., vol. 16...
2022
-
[70]
Long short-term memory re- current neural network architectures for large scale acoustic modeling
H. Sak, A. W. Senior, F. Beaufayset al., “Long short-term memory re- current neural network architectures for large scale acoustic modeling.” inInterspeech, vol. 2014, 2014, pp. 338–342
2014
-
[71]
Deep Speech: Scaling up end-to-end speech recognition
A. Hannun, C. Case, J. Casper, B. Catanzaro, G. Diamos, E. Elsen, R. Prenger, S. Satheesh, S. Sengupta, A. Coates, and A. Y . Ng, “Deep speech: Scaling up end-to-end speech recognition,” 2014. [Online]. Available: https://arxiv.org/abs/1412.5567
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[72]
Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer,
K. Rao, H. Sak, and R. Prabhavalkar, “Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer,” in2017 IEEE Automatic Speech Recognition and Understanding Work- shop (ASRU), 2017, pp. 193–199
2017
-
[73]
Deep speech 2 : End-to-end speech recognition in english and mandarin,
D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen, J. Chen, J. Chen, Z. Chen, M. Chrzanowski, A. Coates, G. Diamos, K. Ding, N. Du, E. Elsen, J. Engel, W. Fang, L. Fan, C. Fougner, L. Gao, C. Gong, A. Hannun, T. Han, L. Johannes, B. Jiang, C. Ju, B. Jun, P. LeGresley, L. Lin, J. Liu, Y ....
2016
-
[74]
Framewise phoneme classification with bidirectional lstm and other neural network architectures,
A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional lstm and other neural network architectures,”Neural networks, vol. 18, no. 5-6, pp. 602–610, 2005
2005
-
[75]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,
W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 4960–4964
2016
-
[76]
Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition,
L. Dong, S. Xu, and B. Xu, “Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition,” in2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5884–5888
2018
-
[77]
Msdet: Multitask speaker separation and direction-of-arrival estimation training,
R. Hartanto, S. Sakti, and K. Shinoda, “Msdet: Multitask speaker separation and direction-of-arrival estimation training,” 09 2024, pp. 2170–2174
2024
-
[78]
Dbnet: Doa-driven beamforming network for end-to-end reverberant sound source separation,
A. Aroudi and S. Braun, “Dbnet: Doa-driven beamforming network for end-to-end reverberant sound source separation,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 211–215. 27
2021
-
[79]
Jointnet: Joint learning for simultaneous doa estimation and speech enhancement in noisy and reverberant environments,
W. Xiong, M. Jia, J. Zhou, J. Zhang, and Q. Shen, “Jointnet: Joint learning for simultaneous doa estimation and speech enhancement in noisy and reverberant environments,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 596–611, 2026
2026
-
[80]
Directional asr: A new paradigm for e2e multi- speaker speech recognition with source localization,
A. S. Subramanian, C. Weng, S. Watanabe, M. Yu, Y . Xu, S.-X. Zhang, and D. Yu, “Directional asr: A new paradigm for e2e multi- speaker speech recognition with source localization,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 8433–8437
2021
-
[81]
Development of a low-latency and real-time automatic speech recognition system,
C. S. Leow, T. Hayakawa, H. Nishizaki, and N. Kitaoka, “Development of a low-latency and real-time automatic speech recognition system,” in 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), 2020, pp. 925–928
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.