Attention, May I Have Your Decision? Localizing Generative Choices in Diffusion Models
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
Self-attention layers localize the implicit decisions that resolve ambiguous prompts in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
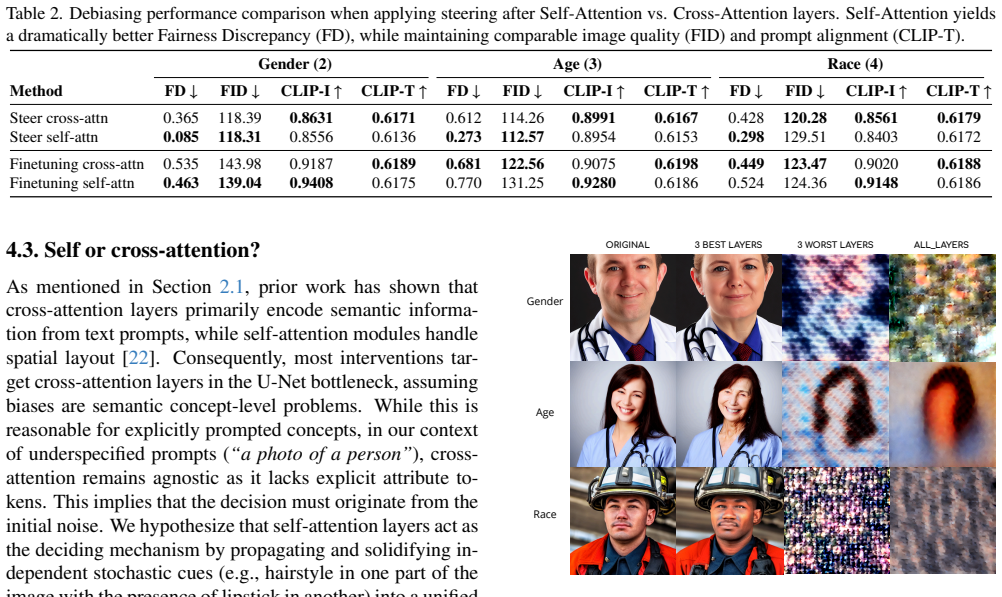
Text-to-image diffusion models make implicit generative decisions for ambiguous prompts principally inside their self-attention layers. A probing-based localization method ranks layers by attribute separability and identifies self-attention blocks as the highest-ranking sites. Targeted edits applied only to this small subset of layers yield stronger debiasing performance and fewer unintended artifacts than existing state-of-the-art steering approaches.
What carries the argument
Probing-based localization that ranks layers according to their attribute separability for concepts, isolating self-attention layers as the dominant sites for resolving implicit generative choices.
If this is right
- Interventions can be restricted to a small number of self-attention layers while still altering implicit choices.
- ICM outperforms prior steering methods on debiasing tasks with reduced visual artifacts.
- Explicit conditioning from the prompt can be kept separate from the implicit decision process during editing.
- Fewer layers need modification, lowering the computational cost of precise generative control.
Where Pith is reading between the lines
- The same localization approach could be applied to other generative architectures to find their implicit decision points.
- Targeted layer edits might support fine-grained image editing tasks that current global methods cannot achieve cleanly.
- Auditing self-attention layers could reveal where models systematically inject biases for particular ambiguous attributes.
Load-bearing premise
The probing method correctly isolates layers that handle implicit decisions separately from explicit prompt conditioning, and edits to those layers causally change the generated content without large side effects.
What would settle it
If applying the same magnitude of intervention to the identified self-attention layers produces no measurable shift in how ambiguous concepts are resolved, or yields the same level of artifacts as intervening on randomly chosen layers, the localization claim is falsified.
Figures














read the original abstract
Text-to-image diffusion models exhibit remarkable generative capabilities, yet their internal operations remain opaque, particularly when handling prompts that are not fully descriptive. In such scenarios, models must make implicit decisions to generate details not explicitly specified in the text. This work investigates the hypothesis that this decision-making process is not diffuse but is computationally localized within the model's architecture. While existing localization techniques focus on prompt-related interventions, we notice that such explicit conditioning may differ from implicit decisions. Therefore, we introduce a probing-based localization technique to identify the layers with the highest attribute separability for concepts. Our findings indicate that the resolution of ambiguous concepts is governed principally by self-attention layers, identifying them as the most effective point for intervention. Based on this discovery, we propose ICM (Implicit Choice-Modification) - a precise steering method that applies targeted interventions to a small subset of layers. Extensive experiments confirm that intervening on these specific self-attention layers yields superior debiasing performance compared to existing state-of-the-art methods, minimizing artifacts common to less precise approaches. The code is available at https://github.com/kzaleskaa/icm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that implicit generative decisions in text-to-image diffusion models for ambiguous prompts are localized primarily in self-attention layers, identified via a probing technique that ranks layers by attribute separability. It introduces the ICM intervention method targeting a small subset of these layers and reports superior debiasing performance over existing methods with fewer artifacts.
Significance. If the localization holds, the work would offer a more precise mechanism for steering implicit choices in diffusion models, improving control over debiasing and reducing side effects from broad interventions. The public code release supports reproducibility and allows direct verification of the reported gains.
major comments (2)
- [Abstract] The abstract asserts superior debiasing performance but supplies no quantitative metrics, baseline comparisons, or experimental controls; this absence prevents assessment of whether the central claim is supported by data.
- [Method (probing technique)] The probing-based localization ranks self-attention layers highest for attribute separability on ambiguous concepts, yet the method does not include controls that would isolate this from the layers' known generic role in cross-token feature aggregation (e.g., separability scores on fully-specified versus underspecified prompts, or on non-ambiguous attributes). Without such controls the inference that these layers are the privileged site for implicit decisions remains under-supported.
minor comments (1)
- [Method] Notation for the separability metric and the precise definition of 'attribute separability' should be formalized with an equation to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the presentation of our results and the rigor of our localization analysis. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts superior debiasing performance but supplies no quantitative metrics, baseline comparisons, or experimental controls; this absence prevents assessment of whether the central claim is supported by data.
Authors: We agree that the abstract's brevity limits immediate assessment of the quantitative claims. In the revised manuscript we will expand the abstract to include the primary performance metrics (e.g., the reported improvement in debiasing scores relative to baselines), a brief statement of the experimental controls used, and the key comparison against prior state-of-the-art methods. These additions will be drawn directly from the results already presented in the experimental section. revision: yes
-
Referee: [Method (probing technique)] The probing-based localization ranks self-attention layers highest for attribute separability on ambiguous concepts, yet the method does not include controls that would isolate this from the layers' known generic role in cross-token feature aggregation (e.g., separability scores on fully-specified versus underspecified prompts, or on non-ambiguous attributes). Without such controls the inference that these layers are the privileged site for implicit decisions remains under-supported.
Authors: The referee correctly identifies that additional controls would more convincingly isolate the role of self-attention layers in implicit generative choices from their general cross-token aggregation function. While our current probing focuses on attribute separability for ambiguous prompts, we acknowledge the value of the suggested comparisons. In the revised manuscript we will add new experiments reporting separability scores on fully-specified prompts and on non-ambiguous attributes, thereby providing the requested controls and strengthening the localization argument. revision: yes
Circularity Check
No circularity: empirical probing and intervention results are independent of inputs
full rationale
The paper introduces a probing technique that ranks layers by attribute separability on ambiguous concepts, reports that self-attention layers score highest, and validates the finding by showing superior debiasing when intervening on those layers. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on experimental measurements rather than reducing by construction to the probing inputs or prior self-references. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a probing-based localization technique to identify the layers with the highest attribute separability for concepts... self-attention layers... ICM (Implicit Choice-Modification)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.