Difference of Convex Programming in the Wasserstein Space with Applications to MMD Optimization
Pith reviewed 2026-06-29 05:00 UTC · model grok-4.3
The pith
A lifted convex-concave procedure finds almost-stationary points for difference-of-convex objectives over the Wasserstein space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
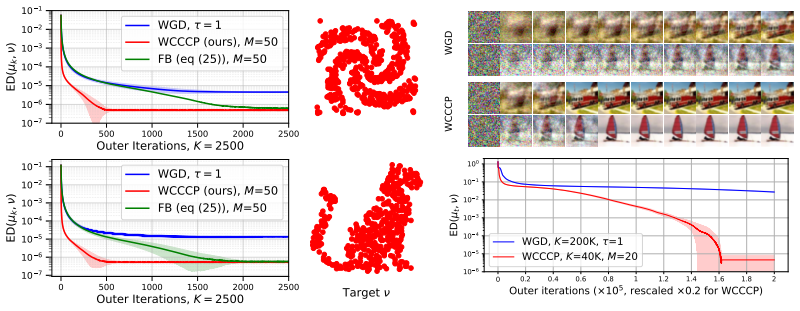
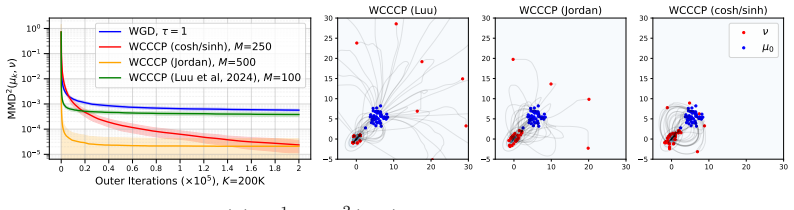
Objectives over the Wasserstein space that admit a difference-of-convex decomposition can be minimized by a lifted CCCP algorithm whose iterates are almost stationary when the convex components are smooth and strongly convex. Explicit Wasserstein DC decompositions are supplied for the MMD and energy-distance functionals, and the scheme is shown to converge locally under mild assumptions. Well-chosen decompositions produce faster and more stable convergence than plain Wasserstein gradient descent on these objectives.
What carries the argument
The lifted convex-concave procedure (CCCP) applied to a DC decomposition of a functional on the Wasserstein space, which generates a sequence of convex subproblems solved along Wasserstein geodesics.
If this is right
- Iterates of the lifted CCCP are almost stationary for smooth strongly convex DC components.
- Explicit DC decompositions exist for both MMD and energy distance.
- Local convergence holds under mild assumptions on those decompositions.
- Well-chosen DC decompositions converge faster and more stably than Wasserstein gradient descent on MMD objectives.
Where Pith is reading between the lines
- The approach may extend to other optimal-transport discrepancies once suitable DC decompositions are found.
- It could be combined with existing Wasserstein gradient flows to handle mixed convex-nonconvex objectives in generative modeling.
- Finding systematic ways to obtain DC decompositions for arbitrary functionals on measures remains a separate algorithmic question.
Load-bearing premise
The convex parts of the DC decomposition must be smooth and strongly convex.
What would settle it
Run the lifted CCCP on an MMD objective whose DC decomposition has a convex part that is not strongly convex and check whether the iterates remain far from stationarity.
Figures
read the original abstract
Optimizing functionals over the space of probability measures is now ubiquitous in machine learning. A widely used approach is to perform the optimization directly over the Wasserstein space, but many objective functionals of practical interest are non-convex along Wasserstein geodesics, making the analysis of standard first-order methods challenging. In this work, we study a class of objectives over the Wasserstein space that admit a difference-of-convex (DC) decomposition and we lift the classical convex-concave procedure (CCCP) to this setting. Under smoothness and strong convexity assumptions on the convex components of the decomposition, we prove almost stationarity along the iterates of the resulting algorithm. Our main focus is on the Maximum Mean Discrepancy (MMD) and the Energy Distance (ED) functionals, for which we develop explicit Wasserstein DC decompositions, and establish local convergence of the scheme under mild assumptions. Empirically, we show that well-chosen DC decompositions yield faster and more stable convergence than Wasserstein gradient descent on these MMD objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes lifting the classical convex-concave procedure (CCCP) to the Wasserstein space for optimizing functionals that admit a difference-of-convex (DC) decomposition. Under smoothness and strong-convexity assumptions on the convex summands, it claims to prove that the resulting algorithm produces almost-stationary iterates. Explicit DC decompositions are developed for the Maximum Mean Discrepancy (MMD) and Energy Distance (ED) functionals, for which local convergence is established under mild assumptions. Empirical comparisons indicate that suitably chosen DC decompositions yield faster and more stable convergence than Wasserstein gradient descent on MMD objectives.
Significance. If the smoothness and strong-convexity assumptions hold for the explicit DC splittings of MMD and ED with respect to the Wasserstein metric, the work supplies a new first-order scheme for a practically relevant class of non-convex problems on probability measures together with concrete constructions and local-convergence guarantees. The provision of explicit DC decompositions for MMD and ED constitutes a concrete, reusable contribution.
major comments (1)
- [Abstract] Abstract: the almost-stationarity and local-convergence statements are conditioned on the convex components of the DC decomposition being smooth and strongly convex in the Wasserstein geometry. The manuscript supplies explicit DC decompositions for MMD and ED yet provides no verification, constant bounds, or counter-example checks confirming that these particular summands satisfy strong convexity (or even finite smoothness constants) with respect to the Wasserstein metric; this verification is load-bearing for the applicability of the theoretical guarantees to the functionals highlighted in the title and abstract.
minor comments (1)
- [Abstract] The abstract refers to 'well-chosen DC decompositions' without stating the selection criterion or the precise mild assumptions used for local convergence of MMD/ED.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the constructive comment on the abstract. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the almost-stationarity and local-convergence statements are conditioned on the convex components of the DC decomposition being smooth and strongly convex in the Wasserstein geometry. The manuscript supplies explicit DC decompositions for MMD and ED yet provides no verification, constant bounds, or counter-example checks confirming that these particular summands satisfy strong convexity (or even finite smoothness constants) with respect to the Wasserstein metric; this verification is load-bearing for the applicability of the theoretical guarantees to the functionals highlighted in the title and abstract.
Authors: We agree that the general almost-stationarity result relies on smoothness and strong-convexity of the convex summands with respect to the Wasserstein metric, and that the manuscript does not supply explicit verification, bounds, or checks for the specific DC components of MMD and ED. The local-convergence claim for MMD/ED is stated under separate mild assumptions, but the referee is correct that the abstract does not clearly separate the general theorem from the application. In the revision we will add a dedicated paragraph (or short appendix) that either derives the relevant constants for the chosen decompositions or states the precise additional conditions needed for the MMD/ED cases. This addresses the load-bearing gap without altering the main theorems. revision: yes
Circularity Check
No circularity: convergence claims rest on independent assumptions and explicit decompositions without reduction to self-defined inputs.
full rationale
The abstract states that almost-stationarity is proved under smoothness and strong-convexity assumptions on the DC components, with explicit decompositions supplied for MMD and ED and local convergence shown under mild assumptions. No quoted equations or steps reduce any prediction or theorem to a fitted parameter, self-citation chain, or definitional equivalence. The derivation chain is presented as conditional on external assumptions that are not shown to be tautological with the result itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective functional admits a DC decomposition whose convex parts are smooth and strongly convex along Wasserstein geodesics.
Reference graph
Works this paper leans on
-
[1]
On the rate of convergence of the difference-of-convex algorithm (DCA).Journal of Optimization Theory and Applications, 202(1):475–496, 2024
Hadi Abbaszadehpeivasti, Etienne de Klerk, and Moslem Zamani. On the rate of convergence of the difference-of-convex algorithm (DCA).Journal of Optimization Theory and Applications, 202(1):475–496, 2024. (Cited on p. 4, 5, 17)
2024
-
[2]
DC Decomposition of Nonconvex Polynomials with Algebraic Techniques.Mathematical Programming, 169(1):69–94, 2018
Amir Ali Ahmadi and Georgina Hall. DC Decomposition of Nonconvex Polynomials with Algebraic Techniques.Mathematical Programming, 169(1):69–94, 2018. (Cited on p. 9, 17)
2018
-
[3]
Neural Wasserstein Gradient Flows for Discrepancies with Riesz Kernels
Fabian Altekrüger, Johannes Hertrich, and Gabriele Steidl. Neural Wasserstein Gradient Flows for Discrepancies with Riesz Kernels. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learn...
2023
-
[4]
Springer, 2008
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré.Gradient Flows: in Metric Spaces and in the Space of Probability Measures. Springer, 2008. (Cited on p. 1, 2, 3, 6, 17, 19, 33)
2008
-
[5]
Refining Deep Generative Models via Discriminator Gradient Flow
Abdul Fatir Ansari, Ming Liang Ang, and Harold Soh. Refining Deep Generative Models via Discriminator Gradient Flow. InInternational Conference on Learning Representations, 2021. (Cited on p. 1)
2021
-
[6]
Maximum Mean Discrepancy Gradient Flow.Advances in Neural Information Processing Systems, 32, 2019
Michael Arbel, Anna Korba, Adil Salim, and Arthur Gretton. Maximum Mean Discrepancy Gradient Flow.Advances in Neural Information Processing Systems, 32, 2019. (Cited on p. 1, 2, 3, 7, 9, 28)
2019
-
[7]
A DC- Programming Algorithm for Kernel Selection
Andreas Argyriou, Raphael Hauser, Charles A Micchelli, and Massimiliano Pontil. A DC- Programming Algorithm for Kernel Selection. InProceedings of the 23rd international confer- ence on Machine learning, pages 41–48, 2006. (Cited on p. 2)
2006
-
[8]
Convex- Concave Programming: An Effective Alternative for Optimizing Shallow Neural Networks
Mohammad Askarizadeh, Alireza Morsali, Sadegh Tofigh, and Kim Khoa Nguyen. Convex- Concave Programming: An Effective Alternative for Optimizing Shallow Neural Networks. IEEE Transactions on Emerging Topics in Computational Intelligence, 9(4):2894–2907, 2024. (Cited on p. 2)
2024
-
[9]
DC-programming for neural network optimizations.Journal of Global Optimization, pages 1–17, 2024
Pranjal Awasthi, Anqi Mao, Mehryar Mohri, and Yutao Zhong. DC-programming for neural network optimizations.Journal of Global Optimization, pages 1–17, 2024. (Cited on p. 2)
2024
-
[10]
A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications.Mathematics of Operations Research, 42(2):330–348, 2017
Heinz H Bauschke, Jérôme Bolte, and Marc Teboulle. A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications.Mathematics of Operations Research, 42(2):330–348, 2017. (Cited on p. 17)
2017
-
[11]
Mirror Descent and Nonlinear Projected Subgradient Methods for Convex Optimization.Operations Research Letters, 31(3):167–175, 2003
Amir Beck and Marc Teboulle. Mirror Descent and Nonlinear Projected Subgradient Methods for Convex Optimization.Operations Research Letters, 31(3):167–175, 2003. (Cited on p. 3)
2003
-
[12]
Weighted Quantization Using MMD: From Mean Field to Mean Shift via Gradient Flows
Ayoub Belhadji, Daniel Sharp, and Youssef Marzouk. Weighted Quantization Using MMD: From Mean Field to Mean Shift via Gradient Flows. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. (Cited on p. 2)
2026
-
[13]
The Difference of Convex Algorithm on Hadamard Manifolds.Journal of Optimization Theory and Applications, 201(1):221–251, 2024
Ronny Bergmann, Orizon P Ferreira, Elianderson M Santos, and João Carlos O Souza. The Difference of Convex Algorithm on Hadamard Manifolds.Journal of Optimization Theory and Applications, 201(1):221–251, 2024. (Cited on p. 2)
2024
-
[14]
A family of functional inequalities: Łojasiewicz inequalities and displacement convex functions.Journal of Functional Analysis, 275(7):1650–1673, 2018
Adrien Blanchet and Jérôme Bolte. A family of functional inequalities: Łojasiewicz inequalities and displacement convex functions.Journal of Functional Analysis, 275(7):1650–1673, 2018. (Cited on p. 1, 17)
2018
-
[15]
Variational Inference: A Review for Statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational Inference: A Review for Statisticians.Journal of the American statistical Association, 112(518):859–877, 2017. (Cited on p. 1) 10
2017
-
[16]
Bomze and Marco Locatelli
Immanuel M. Bomze and Marco Locatelli. Undominated d.c. Decompositions of Quadratic Functions and Applications to Branch-and-Bound Approaches.Computational Optimization and Applications, 28(2):227–245, 2004. (Cited on p. 17)
2004
-
[17]
Mirror and Preconditioned Gradient Descent in Wasserstein Space
Clément Bonet, Théo Uscidda, Adam David, Pierre-Cyril Aubin-Frankowski, and Anna Korba. Mirror and Preconditioned Gradient Descent in Wasserstein Space. InThirty-eight Conference on Neural Information Processing Systems, 2024. (Cited on p. 1, 3, 5, 6, 17, 18, 34)
2024
-
[18]
Sliced-Wasserstein Distances and Flows on Cartan-Hadamard Manifolds.Journal of Machine Learning Research, 26(32):1–76, 2025
Clément Bonet, Lucas Drumetz, and Nicolas Courty. Sliced-Wasserstein Distances and Flows on Cartan-Hadamard Manifolds.Journal of Machine Learning Research, 26(32):1–76, 2025. (Cited on p. 1)
2025
-
[19]
A Pontryagin Maximum Principle in Wasserstein Spaces for Constrained Optimal Control Problems.ESAIM: Control, Optimisation and Calculus of Variations, 25:52,
Benoît Bonnet. A Pontryagin Maximum Principle in Wasserstein Spaces for Constrained Optimal Control Problems.ESAIM: Control, Optimisation and Calculus of Variations, 25:52,
-
[20]
PhD thesis, Université Paris Sud-Paris XI; Scuola normale superiore (Pise, Italie), 2013
Nicolas Bonnotte.Unidimensional and Evolution Methods for Optimal Transportation. PhD thesis, Université Paris Sud-Paris XI; Scuola normale superiore (Pise, Italie), 2013. (Cited on p. 1)
2013
-
[21]
On the global convergence of Wasserstein gradient flow of the Coulomb discrepancy.SIAM Journal on Mathematical Analysis, 57(4): 4556–4587, 2025
Siwan Boufadène and François-Xavier Vialard. On the global convergence of Wasserstein gradient flow of the Coulomb discrepancy.SIAM Journal on Mathematical Analysis, 57(4): 4556–4587, 2025. (Cited on p. 2)
2025
-
[22]
Polar Factorization and Monotone Rearrangement of Vector-Valued Functions
Yann Brenier. Polar Factorization and Monotone Rearrangement of Vector-Valued Functions. Communications on pure and applied mathematics, 44(4):375–417, 1991. (Cited on p. 4)
1991
-
[23]
Proximal Opti- mal Transport Modeling of Population Dynamics
Charlotte Bunne, Laetitia Papaxanthos, Andreas Krause, and Marco Cuturi. Proximal Opti- mal Transport Modeling of Population Dynamics. InInternational Conference on Artificial Intelligence and Statistics, pages 6511–6528. PMLR, 2022. (Cited on p. 1)
2022
-
[24]
Jiarui Cao, Zixuan Wei, and Yuxin Liu. Gradient Flow Drifting: Generative Model- ing via Wasserstein Gradient Flows of KDE-Approximated Divergences.arXiv preprint arXiv:2603.10592, 2026. (Cited on p. 1)
-
[25]
A Lagrangian approach to totally dissipative evolutions in Wasserstein spaces
Giulia Cavagnari, Giuseppe Savaré, and Giacomo Enrico Sodini. A Lagrangian approach to totally dissipative evolutions in Wasserstein spaces.arXiv preprint arXiv:2305.05211, 2023. (Cited on p. 3, 17)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Stochastic Difference-of-Convex Optimization with Mo- mentum.arXiv preprint arXiv:2510.17503, 2025
El Mahdi Chayti and Martin Jaggi. Stochastic Difference-of-Convex Optimization with Mo- mentum.arXiv preprint arXiv:2510.17503, 2025. (Cited on p. 6)
-
[27]
On the Global Convergence of Gradient Descent for Over- Parameterized Models using Optimal Transport.Advances in neural information processing systems, 31, 2018
Lenaic Chizat and Francis Bach. On the Global Convergence of Gradient Descent for Over- Parameterized Models using Optimal Transport.Advances in neural information processing systems, 31, 2018. (Cited on p. 1)
2018
-
[28]
Lénaïc Chizat, Maria Colombo, Roberto Colombo, and Xavier Fernández-Real. Quantitative Convergence of Wasserstein Gradient Flows of Kernel Mean Discrepancies.arXiv preprint arXiv:2603.01977, 2026. (Cited on p. 8)
-
[29]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative Modeling via Drifting.arXiv preprint arXiv:2602.04770, 2026. (Cited on p. 1)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Nonparametric Generative Modeling with Conditional Sliced-Wasserstein Flows
Chao Du, Tianbo Li, Tianyu Pang, Shuicheng Yan, and Min Lin. Nonparametric Generative Modeling with Conditional Sliced-Wasserstein Flows. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machin...
2023
-
[31]
Learning Monge maps with constrained drifting models
Théo Dumont, Théo Lacombe, and François-Xavier Vialard. Learning Monge maps by lifting and constraining Wasserstein gradient flows.arXiv preprint arXiv:2603.25182, 2026. (Cited on p. 3)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
A Bregman Divergence View on the Difference-of-Convex Algorithm
Oisin Faust, Hamza Fawzi, and James Saunderson. A Bregman Divergence View on the Difference-of-Convex Algorithm. InInternational Conference on Artificial Intelligence and Statistics, pages 3427–3439. PMLR, 2023. (Cited on p. 4, 5, 17, 18, 19)
2023
-
[33]
OP Ferreira, DS Gonçalves, MS Louzeiro, SZ Németh, and J Zhu. A subdifferential characteri- zation via Busemann functions and applications to DC optimization on Hadamard manifolds. arXiv preprint arXiv:2602.20931, 2026. (Cited on p. 2) 11
-
[34]
Functional Bregman Divergence
Bela A Frigyik, Santosh Srivastava, and Maya R Gupta. Functional Bregman Divergence. In 2008 IEEE International Symposium on Information Theory, pages 1681–1685. IEEE, 2008. (Cited on p. 3)
2008
-
[35]
Deep Generative Learning via Variational Gradient Flow
Yuan Gao, Yuling Jiao, Yang Wang, Yao Wang, Can Yang, and Shunkang Zhang. Deep Generative Learning via Variational Gradient Flow. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 2093–2101. PMLR, 09–15 Jun 2019. (Cited on p. 1)
2093
-
[36]
DDEQs: Distribu- tional Deep Equilibrium Models through Wasserstein Gradient Flows
Jonathan Geuter, Clément Bonet, Anna Korba, and David Alvarez-Melis. DDEQs: Distribu- tional Deep Equilibrium Models through Wasserstein Gradient Flows. InThe 28th International Conference on Artificial Intelligence and Statistics, 2025. (Cited on p. 8)
2025
-
[37]
Interaction-Force Transport Gradient Flows.Advances in Neural Information Processing Systems, 37:14484– 14508, 2024
Egor Gladin, Pavel Dvurechensky, Alexander Mielke, and Jia-Jie Zhu. Interaction-Force Transport Gradient Flows.Advances in Neural Information Processing Systems, 37:14484– 14508, 2024. (Cited on p. 2, 28)
2024
-
[38]
A Kernel Two-sample Test.The journal of machine learning research, 13(1):723–773,
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A Kernel Two-sample Test.The journal of machine learning research, 13(1):723–773,
-
[39]
Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel
Paul Hagemann, Johannes Hertrich, Fabian Altekrüger, Robert Beinert, Jannis Chemseddine, and Gabriele Steidl. Posterior Sampling Based on Gradient Flows of the MMD with Negative Distance Kernel. InThe Twelfth International Conference on Learning Representations, 2024. (Cited on p. 8)
2024
-
[40]
Wasserstein Steepest Descent Flows of Discrepancies with Riesz Kernels.Journal of Mathematical Analysis and Applications, 531(1):127829, 2024
Johannes Hertrich, Manuel Gräf, Robert Beinert, and Gabriele Steidl. Wasserstein Steepest Descent Flows of Discrepancies with Riesz Kernels.Journal of Mathematical Analysis and Applications, 531(1):127829, 2024. (Cited on p. 1, 8)
2024
-
[41]
Generative Sliced MMD Flows with Riesz Kernels
Johannes Hertrich, Christian Wald, Fabian Altekrüger, and Paul Hagemann. Generative Sliced MMD Flows with Riesz Kernels. InThe Twelfth International Conference on Learning Repre- sentations, 2024. (Cited on p. 1, 7, 8, 25, 28)
2024
-
[42]
Generalized Differentiability, Duality and Optimization for Prob- lems Dealing with Differences of Convex Functions
Jean-Baptiste Hiriart-Urruty. Generalized Differentiability, Duality and Optimization for Prob- lems Dealing with Differences of Convex Functions. In J. Ponstein, editor,Convexity and Duality in Optimization, volume 256 ofLecture Notes in Economics and Mathematical Systems, pages 37–70. Springer, Berlin, 1985. (Cited on p. 2, 3)
1985
-
[43]
The variational formulation of the Fokker– Planck equation.SIAM journal on mathematical analysis, 29(1):1–17, 1998
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the Fokker– Planck equation.SIAM journal on mathematical analysis, 29(1):1–17, 1998. (Cited on p. 1)
1998
-
[44]
Kernel Stein Discrepancy Descent
Anna Korba, Pierre-Cyril Aubin-Frankowski, Szymon Majewski, and Pierre Ablin. Kernel Stein Discrepancy Descent. InInternational Conference on Machine Learning, pages 5719–5730. PMLR, 2021. (Cited on p. 7)
2021
-
[45]
Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning Multiple Layers of Features from Tiny Images. 2009. (Cited on p. 8)
2009
-
[46]
Variational Inference via Wasserstein Gradient Flows.Advances in Neural Information Processing Systems, 35:14434–14447, 2022
Marc Lambert, Sinho Chewi, Francis Bach, Silvère Bonnabel, and Philippe Rigollet. Variational Inference via Wasserstein Gradient Flows.Advances in Neural Information Processing Systems, 35:14434–14447, 2022. (Cited on p. 1)
2022
-
[47]
On the Convergence of the Concave-Convex Procedure.Advances in neural information processing systems, 22, 2009
Gert Lanckriet and Bharath K Sriperumbudur. On the Convergence of the Concave-Convex Procedure.Advances in neural information processing systems, 22, 2009. (Cited on p. 4)
2009
-
[48]
First-Order Conditions for Optimiza- tion in the Wasserstein Space.SIAM Journal on Mathematics of Data Science, 7(1):274–300,
Nicolas Lanzetti, Saverio Bolognani, and Florian Dörfler. First-Order Conditions for Optimiza- tion in the Wasserstein Space.SIAM Journal on Mathematics of Data Science, 7(1):274–300,
-
[49]
DC programming and DCA: thirty years of developments
Hoai An Le Thi and Tao Pham Dinh. DC programming and DCA: thirty years of developments. Mathematical Programming, 169(1):5–68, 2018. (Cited on p. 2, 4)
2018
-
[50]
Polyak–Łojasiewicz inequality on the space of measures and convergence of mean-field birth-death processes.Applied Mathematics & Optimization, 87(3):48, 2023
Linshan Liu, Mateusz B Majka, and Łukasz Szpruch. Polyak–Łojasiewicz inequality on the space of measures and convergence of mean-field birth-death processes.Applied Mathematics & Optimization, 87(3):48, 2023. (Cited on p. 1, 17) 12
2023
-
[51]
Minimizing f- Divergences by Interpolating Velocity Fields
Song Liu, Jiahao Yu, Jack Simons, Mingxuan Yi, and Mark Beaumont. Minimizing f- Divergences by Interpolating Velocity Fields. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings ...
2024
-
[52]
Sliced-Wasserstein Flows: Nonparametric Generative Modeling via Optimal Transport and Diffusions
Antoine Liutkus, Umut Simsekli, Szymon Majewski, Alain Durmus, and Fabian-Robert Stöter. Sliced-Wasserstein Flows: Nonparametric Generative Modeling via Optimal Transport and Diffusions. InInternational Conference on machine learning, pages 4104–4113. PMLR, 2019. (Cited on p. 1)
2019
-
[53]
Freund, and Yurii Nesterov
Haihao Lu, Robert M. Freund, and Yurii Nesterov. Relatively Smooth Convex Optimization by First-Order Methods, and Applications.SIAM Journal on Optimization, 28(1):333–354, 2018. (Cited on p. 3, 17)
2018
-
[54]
DC-LA: Difference-of-Convex Langevin Algorithm
Hoang Phuc Hau Luu and Zhongjian Wang. DC-LA: Difference-of-Convex Langevin Algorithm. arXiv preprint arXiv:2601.22932, 2026. (Cited on p. 2)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Non-geodesically-convex optimization in the Wasserstein space
Hoang Phuc Hau Luu, Hanlin Yu, Bernardo Williams, Petrus Mikkola, Marcelo Hartmann, Kai Puolamäki, and Arto Klami. Non-geodesically-convex optimization in the Wasserstein space. Advances in Neural Information Processing Systems, 37:16772–16809, 2024. (Cited on p. 1, 2, 4, 6, 7, 8, 9, 19, 20, 25, 29)
2024
-
[56]
A Mean Field View of the Landscape of Two-Layer Neural Networks.Proceedings of the National Academy of Sciences, 115(33): E7665–E7671, 2018
Song Mei, Andrea Montanari, and Phan-Minh Nguyen. A Mean Field View of the Landscape of Two-Layer Neural Networks.Proceedings of the National Academy of Sciences, 115(33): E7665–E7671, 2018. (Cited on p. 1)
2018
-
[57]
Kernel Mean Embedding of Distributions: A Review and Beyond.Foundations and Trends® in Machine Learning, 10(1-2):1–141, 2017
Krikamol Muandet, Kenji Fukumizu, Bharath Sriperumbudur, and Bernhard Schölkopf. Kernel Mean Embedding of Distributions: A Review and Beyond.Foundations and Trends® in Machine Learning, 10(1-2):1–141, 2017. (Cited on p. 7)
2017
-
[58]
Stochastic Difference of Convex Algorithm and its Appli- cation to Training Deep Boltzmann Machines
Atsushi Nitanda and Taiji Suzuki. Stochastic Difference of Convex Algorithm and its Appli- cation to Training Deep Boltzmann Machines. InArtificial intelligence and statistics, pages 470–478. PMLR, 2017. (Cited on p. 6)
2017
-
[59]
Continuous-Time Dynamics of the Difference-of-Convex Algorithm
Yi-Shuai Niu. Continuous-Time Dynamics of the Difference-of-Convex Algorithm.arXiv preprint arXiv:2604.06926, 2026. (Cited on p. 4, 17)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
On Difference-of-SOS and Difference- of-Convex-SOS Decompositions for Polynomials.SIAM Journal on Optimization, 34(2): 1852–1878, 2024
Yi-Shuai Niu, Hoai An Le Thi, and Dinh Tao Pham. On Difference-of-SOS and Difference- of-Convex-SOS Decompositions for Polynomials.SIAM Journal on Optimization, 34(2): 1852–1878, 2024. (Cited on p. 17)
2024
-
[61]
Konstantinos Oikonomidis, Emanuel Laude, and Panagiotis Patrinos. Forward-backward splitting under the light of generalized convexity.arXiv preprint arXiv:2503.18098, 2025. (Cited on p. 4, 17, 18, 19)
-
[62]
Some convexity criteria for differentiable functions on the 2-Wasserstein space
Guy Parker. Some convexity criteria for differentiable functions on the 2-Wasserstein space. Bulletin of the London Mathematical Society, 56(5):1839–1858, 2024. (Cited on p. 3, 17)
2024
-
[63]
Learning of Population Dynamics: Inverse Optimization Meets JKO Scheme
Mikhail Persiianov, Jiawei Chen, Petr Mokrov, Alexander Tyurin, Evgeny Burnaev, and Alexan- der Korotin. Learning of Population Dynamics: Inverse Optimization Meets JKO Scheme. In The Fourteenth International Conference on Learning Representations, 2026. (Cited on p. 1)
2026
-
[64]
Variational Inference with Mix- tures of Isotropic Gaussians
Marguerite Petit-Talamon, Marc Lambert, and Anna Korba. Variational Inference with Mix- tures of Isotropic Gaussians. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. (Cited on p. 1)
2025
-
[65]
Wasserstein Policy Optimization
David Pfau, Ian Davies, Diana L Borsa, João Guilherme Madeira Araújo, Brendan Daniel Tracey, and Hado van Hasselt. Wasserstein Policy Optimization. InForty-second International Conference on Machine Learning, 2025. (Cited on p. 1)
2025
-
[66]
Recent advances in DC programming and DCA.Transac- tions on computational intelligence XIII, pages 1–37, 2014
Tao Pham Dinh and Hoai An Le Thi. Recent advances in DC programming and DCA.Transac- tions on computational intelligence XIII, pages 1–37, 2014. (Cited on p. 2, 4)
2014
-
[67]
Teodor Rotaru, Panagiotis Patrinos, and François Glineur. Tight Analysis of Difference-of- Convex Algorithm (DCA) Improves Convergence Rates for Proximal Gradient Descent.arXiv preprint arXiv:2503.04486, 2025. (Cited on p. 4)
-
[68]
Smoothed distance kernels for MMDs and applications in Wasserstein gradient flows.Advances in Computational Mathematics, 52 (2):24, 2026
Nicolaj Rux, Michael Quellmalz, and Gabriele Steidl. Smoothed distance kernels for MMDs and applications in Wasserstein gradient flows.Advances in Computational Mathematics, 52 (2):24, 2026. (Cited on p. 25) 13
2026
-
[69]
The Wasserstein Proximal Gradient Algorithm
Adil Salim, Anna Korba, and Giulia Luise. The Wasserstein Proximal Gradient Algorithm. Advances in Neural Information Processing Systems, 33:12356–12366, 2020. (Cited on p. 1, 2, 6)
2020
-
[70]
Springer,
Filippo Santambrogio.Optimal Transport for Applied Mathematicians, volume 55. Springer,
-
[71]
Equivalence of distance-based and RKHS-based statistics in hypothesis testing.The annals of statistics, pages 2263–2291, 2013
Dino Sejdinovic, Bharath Sriperumbudur, Arthur Gretton, and Kenji Fukumizu. Equivalence of distance-based and RKHS-based statistics in hypothesis testing.The annals of statistics, pages 2263–2291, 2013. (Cited on p. 8, 24)
2013
-
[72]
Learning Rate Free Sampling in Constrained Domains.Advances in Neural Information Processing Systems, 36:65380–65415,
Louis Sharrock, Lester Mackey, and Christopher Nemeth. Learning Rate Free Sampling in Constrained Domains.Advances in Neural Information Processing Systems, 36:65380–65415,
-
[73]
A proximal point algorithm for DC fuctions on Hadamard manifolds.Journal of Global Optimization, 63(4):797–810, 2015
JC d O Souza and Paulo Roberto Oliveira. A proximal point algorithm for DC fuctions on Hadamard manifolds.Journal of Global Optimization, 63(4):797–810, 2015. (Cited on p. 2)
2015
-
[74]
Universality, Characteristic Kernels and RKHS Embedding of Measures.Journal of Machine Learning Research, 12(7),
Bharath K Sriperumbudur, Kenji Fukumizu, and Gert RG Lanckriet. Universality, Characteristic Kernels and RKHS Embedding of Measures.Journal of Machine Learning Research, 12(7),
-
[75]
Proximal point algorithm for minimization of DC function.Journal of computational Mathematics, pages 451–462, 2003
Wen-yu Sun, Raimundo JB Sampaio, and MAB Candido. Proximal point algorithm for minimization of DC function.Journal of computational Mathematics, pages 451–462, 2003. (Cited on p. 6)
2003
-
[76]
Ken’ichiro Tanaka. Accelerated gradient descent method for functionals of probability measures by new convexity and smoothness based on transport maps.arXiv preprint arXiv:2305.05127,
-
[77]
Convex analysis approach to DC programming: theory, algorithms and applications.Acta mathematica vietnamica, 22(1):289–355, 1997
Pham Dinh Tao and Hoai An Le Thi. Convex analysis approach to DC programming: theory, algorithms and applications.Acta mathematica vietnamica, 22(1):289–355, 1997. (Cited on p. 4)
1997
-
[78]
New and efficient DCA based algorithms for minimum sum-of-squares clustering.Pattern Recognition, 47(1):388–401, 2014
Pham Dinh Tao et al. New and efficient DCA based algorithms for minimum sum-of-squares clustering.Pattern Recognition, 47(1):388–401, 2014. (Cited on p. 2)
2014
-
[79]
Learning diffusion at lightspeed
Antonio Terpin, Nicolas Lanzetti, Martín Gadea, and Florian Dorfler. Learning diffusion at lightspeed. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[80]
Gauthier Thurin, Claire Boyer, and Kimia Nadjahi. Convergence Rates for Distribution Match- ing with Sliced Optimal Transport.arXiv preprint arXiv:2602.10691, 2026. (Cited on p. 2)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.