PRIME: Evaluating Prompt Resolution Under Incompatible Instructions in LLMs
Pith reviewed 2026-06-26 11:00 UTC · model grok-4.3
The pith
Conflict type affects LLM behavior more than model scale under incompatible instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
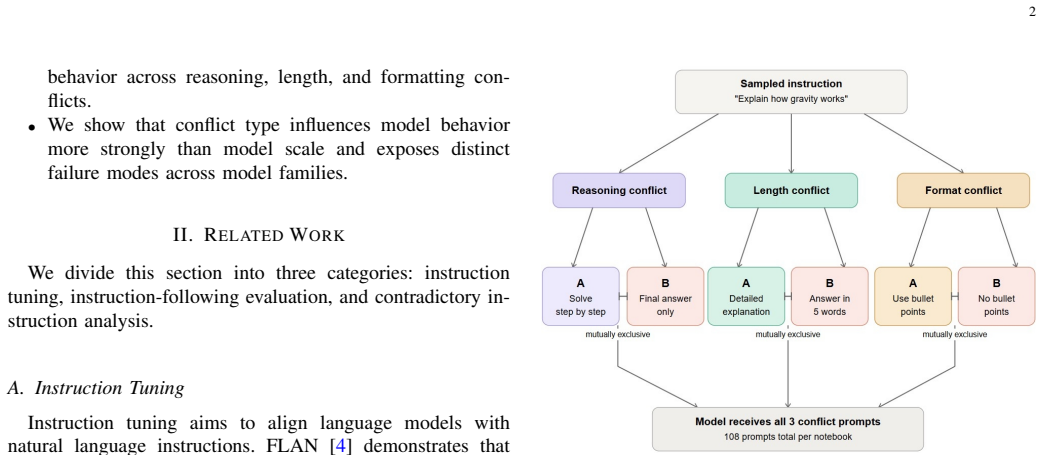
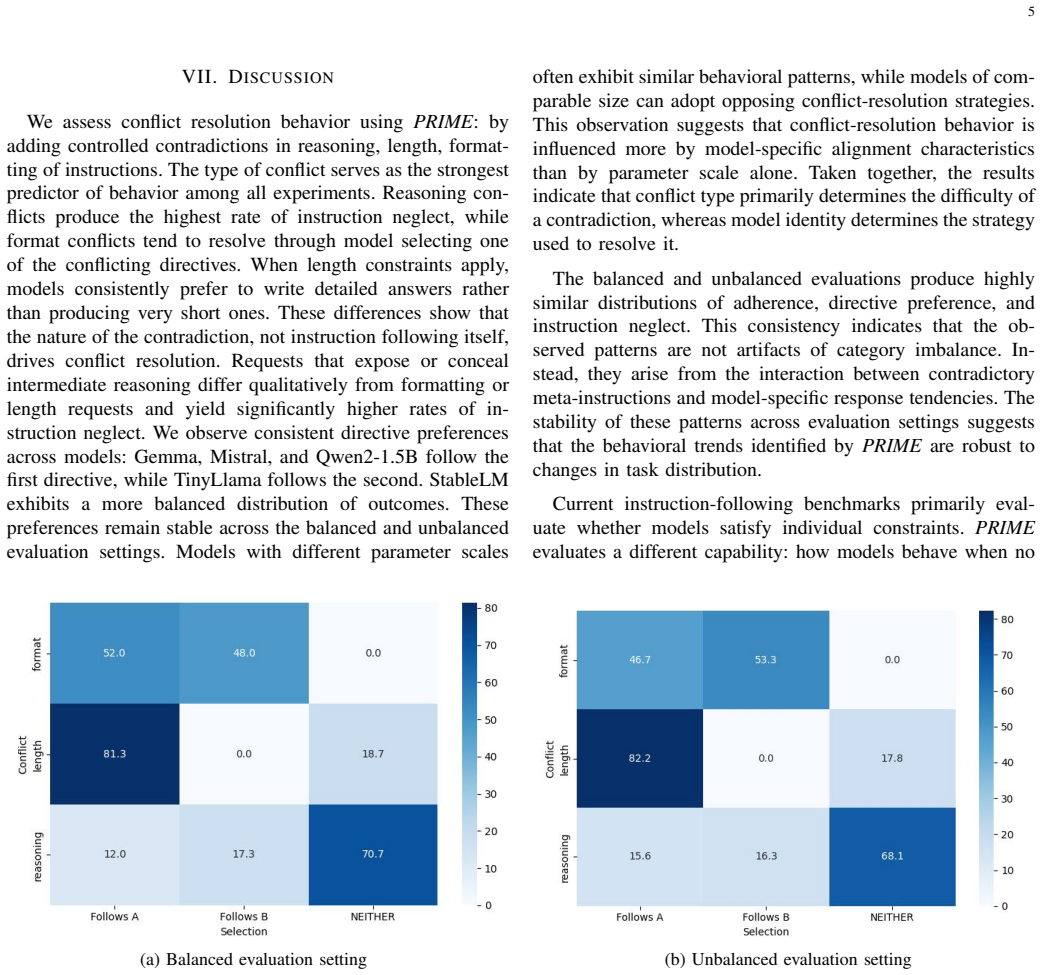
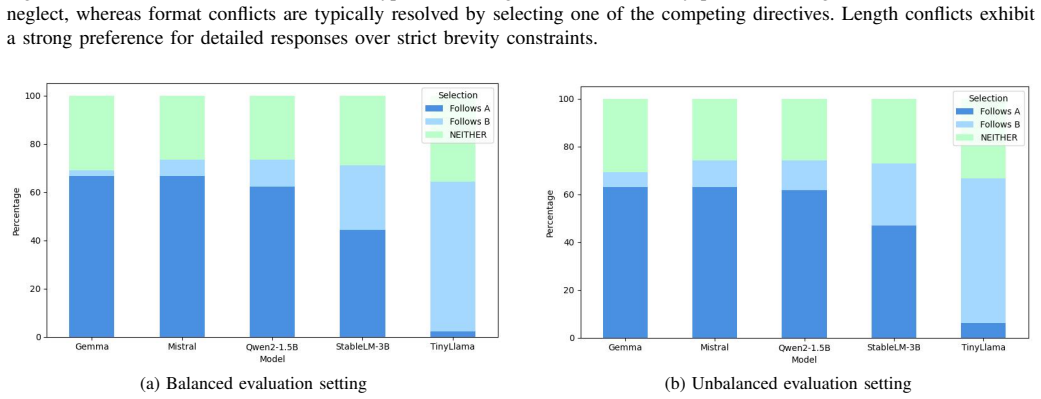
PRIME produces calibrated conflicts across response length, output format, and reasoning and classifies model responses with a deterministic behavioral taxonomy. Evaluation of five instruction-tuned open-weight LLMs reveals that conflict type affects behavior more significantly than model scale, with various failure modes in different conflict categories.
What carries the argument
The PRIME framework, which generates calibrated conflicts in meta-instructions and applies a deterministic behavioral taxonomy to classify responses.
Load-bearing premise
The deterministic behavioral taxonomy and the method of producing calibrated conflicts across response length, output format, and reasoning accurately and objectively classify model responses without introducing evaluation bias or missing relevant behaviors.
What would settle it
Finding that model scale predicts behavior more consistently than conflict type when testing a broader set of models and conflict types would falsify the main conclusion.
Figures


read the original abstract
Large language models (LLMs) often encounter conflicting prompts, although current instruction following benchmarks assess those meta-instructions in isolation, limiting the insights about how models process conflicting instructions. We introduce a framework \textit{PRIME}(\textit{Prompt Resolution under Incompatible Meta-Instructions Evaluation}) to analyze behavior of LLMs when provided with conflicting instructions. \textit{PRIME} purposefully produces calibrated conflicts across response length, output format, and reasoning; classifying model responses with a deterministic behavioral taxonomy. We are evaluating five instruction tuned open weight LLMs in two distinct settings, balanced and naturally distributed. The conclusion we reach upon analysis is that conflict type is more significant in affecting behavior than model scale, and various failure modes across different categories of conflict. Our findings emphasize the value of developing conflict awareness and suggest ability of LLM to follow instructions cannot be assessed through isolated constraints alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PRIME framework to evaluate how LLMs resolve incompatible meta-instructions, specifically calibrated conflicts in response length, output format, and reasoning. It applies a deterministic behavioral taxonomy to classify responses from five instruction-tuned open-weight LLMs across balanced and naturally distributed settings, concluding that conflict type influences behavior more than model scale and identifying various failure modes.
Significance. If the taxonomy and calibration hold, the work would demonstrate that isolated instruction-following benchmarks are insufficient and that conflict type dominates scale in driving LLM behavior under incompatibility. This provides an empirical basis for developing conflict-aware evaluation and training methods.
major comments (3)
- [Abstract and taxonomy section] Abstract and framework description: The central claim that 'conflict type is more significant in affecting behavior than model scale' is derived from response distributions under the deterministic behavioral taxonomy. No validation of the taxonomy (e.g., inter-rater agreement, human alignment checks, or ablation on taxonomy variants) is reported, which is load-bearing because ambiguous or incomplete categories could artifactually produce the observed dominance of conflict type over scale.
- [Framework and experimental setup] Conflict calibration method: The paper states that PRIME 'purposefully produces calibrated conflicts across response length, output format, and reasoning,' but provides no quantitative metrics (e.g., measured incompatibility strength, controls for prompt length or lexical overlap) to confirm equalized difficulty across conflict categories. Without this, the comparison of conflict types versus model scale is potentially confounded.
- [Experiments and results] Model evaluation scope: Conclusions on the relative unimportance of model scale rest on only five open-weight models. This sample is too narrow to support the general claim, as scale effects could emerge with a wider range of parameter counts, architectures, or closed models.
minor comments (2)
- The terms 'balanced and naturally distributed' settings are mentioned in the abstract but lack explicit definitions or examples in the provided description, hindering reproducibility.
- No mention of statistical significance testing or error bars on the reported behavioral distributions, which would strengthen the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the manuscript. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and taxonomy section] Abstract and framework description: The central claim that 'conflict type is more significant in affecting behavior than model scale' is derived from response distributions under the deterministic behavioral taxonomy. No validation of the taxonomy (e.g., inter-rater agreement, human alignment checks, or ablation on taxonomy variants) is reported, which is load-bearing because ambiguous or incomplete categories could artifactually produce the observed dominance of conflict type over scale.
Authors: The taxonomy is explicitly rule-based and deterministic, with classification decisions driven by verifiable criteria (e.g., exact length compliance, format token presence, presence/absence of reasoning steps) rather than subjective judgment, which removes the applicability of inter-rater agreement. That said, we agree that external validation would increase confidence in the taxonomy. In the revision we will add a dedicated subsection reporting a human alignment study on a stratified sample of 200 responses, including agreement rates and any taxonomy refinements. revision: yes
-
Referee: [Framework and experimental setup] Conflict calibration method: The paper states that PRIME 'purposefully produces calibrated conflicts across response length, output format, and reasoning,' but provides no quantitative metrics (e.g., measured incompatibility strength, controls for prompt length or lexical overlap) to confirm equalized difficulty across conflict categories. Without this, the comparison of conflict types versus model scale is potentially confounded.
Authors: We acknowledge the absence of explicit quantitative calibration metrics in the current manuscript. Prompts were constructed via iterative manual balancing to achieve comparable conflict intensity, but this process was not documented with measurements. The revised version will include a new calibration appendix reporting prompt-length statistics, lexical-overlap scores (via embedding cosine similarity), and results from a small pilot study that equalized observed conflict strength across the three categories. revision: yes
-
Referee: [Experiments and results] Model evaluation scope: Conclusions on the relative unimportance of model scale rest on only five open-weight models. This sample is too narrow to support the general claim, as scale effects could emerge with a wider range of parameter counts, architectures, or closed models.
Authors: The experiments were deliberately limited to five publicly available instruction-tuned open-weight models to ensure full reproducibility. We accept that the current sample is insufficient to support an unqualified claim about scale in general. The revision will (a) add two additional open-weight models spanning a wider parameter range, (b) include a limitations paragraph explicitly restricting the scale-related conclusion to the tested open-weight models, and (c) discuss why closed models were excluded. revision: partial
Circularity Check
Empirical evaluation framework with no derivations or self-referential predictions
full rationale
The paper introduces PRIME as an evaluation framework that generates calibrated conflicts and applies a deterministic taxonomy to classify LLM responses across five models. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claim (conflict type more significant than scale) follows from direct observation of response distributions rather than any reduction to the taxonomy or calibration by construction. This is a standard empirical study whose burden is low and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Instruction-following evaluation for large language models,
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,”arXiv preprint arXiv:2311.07911, 2023. [Online]. Available: https://arxiv.org/abs/2311.07911
Pith/arXiv arXiv 2023
-
[2]
Followbench: A multi-level fine- grained constraints following benchmark for large language models,
Y . Jiang, Y . Wang, X. Zeng, W. Zhong, L. Li, F. Mi, L. Shang, X. Jiang, Q. Liu, and W. Wang, “Followbench: A multi-level fine- grained constraints following benchmark for large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand, 2024, pp. 4667–
2024
-
[3]
Available: https://aclanthology.org/2024.acl-long.257
[Online]. Available: https://aclanthology.org/2024.acl-long.257
2024
-
[4]
Coninstruct: Evaluating large language models on conflict detection and resolution in instructions,
X. He, Q. Zhang, P. Chen, G. Chen, L. Yu, Y . Yuan, and S.-M. Yiu, “Coninstruct: Evaluating large language models on conflict detection and resolution in instructions,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI-26), 2026. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/40356
2026
-
[5]
Finetuned language models are zero-shot learners,
J. Wei, M. Bosma, V . Y . Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V . Le, “Finetuned language models are zero-shot learners,” inInternational Conference on Learning Representations (ICLR), 2022. [Online]. Available: https://arxiv.org/abs/2109.01652
Pith/arXiv arXiv 2022
-
[6]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin et al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022. [Online]. Available: https://arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[7]
Scaling instruction-finetuned language models,
H. W. Chung, L. Hou, S. Longpre, J. Dean, A. Roberts, Q. V . Le, and J. Wei, “Scaling instruction-finetuned language models,” arXiv preprint arXiv:2210.11416, 2022. [Online]. Available: https: //arxiv.org/abs/2210.11416
Pith/arXiv arXiv 2022
-
[8]
Instruction tuning for large language models: A survey,
S. Zhang, L. Dong, X. Liet al., “Instruction tuning for large language models: A survey,”arXiv preprint arXiv:2308.10792, 2023. [Online]. Available: https://arxiv.org/abs/2308.10792
arXiv 2023
-
[9]
Calibrate before use: Improving few-shot performance of language models,
T. Z. Zhao, E. Wallace, S. Feng, D. Klein, and S. Singh, “Calibrate before use: Improving few-shot performance of language models,” in International Conference on Machine Learning (ICML), 2021. [Online]. Available: https://arxiv.org/abs/2102.09690
arXiv 2021
-
[10]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024. [Online]. Available: https://aclanthology.org/2024.tacl-1.9
2024
-
[11]
Large language models are not robust multiple choice selectors,
C. Zheng, H. Zhou, F. Meng, J. Zhou, and M. Huang, “Large language models are not robust multiple choice selectors,” inInternational Conference on Learning Representations (ICLR), 2024. [Online]. Available: https://arxiv.org/abs/2309.03882
arXiv 2024
-
[12]
Tinyllama: An open- source small language model,
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open- source small language model,”arXiv preprint arXiv:2401.02385, 2024. [Online]. Available: https://arxiv.org/abs/2401.02385
Pith/arXiv arXiv 2024
-
[13]
A. Yang, B. Yang, B. Huiet al., “Qwen2 technical report,” arXiv preprint arXiv:2407.10671, 2024. [Online]. Available: https: //arxiv.org/abs/2407.10671
Pith/arXiv arXiv 2024
-
[15]
Available: https://arxiv.org/abs/2403.08295
[Online]. Available: https://arxiv.org/abs/2403.08295
-
[16]
Stablelm-3b- 4e1t,
J. Tow, M. Bellagente, D. Mahan, and C. Riquelme, “Stablelm-3b- 4e1t,” Stability AI, 2023. [Online]. Available: https://huggingface.co/ stabilityai/stablelm-3b-4e1t
2023
-
[17]
A. Q. Jiang, A. Sablayrolles, A. Menschet al., “Mistral 7b,” arXiv preprint arXiv:2310.06825, 2023. [Online]. Available: https: //arxiv.org/abs/2310.06825
Pith/arXiv arXiv 2023
-
[18]
F. Wang, M. Lin, Y . Ma, H. Liu, Q. He, X. Tang, J. Tang, J. Pei, and S. Wang, “A survey on small language models in the era of large language models: Architecture, capabilities, and trustworthiness,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, vol. 2, 2025, pp. 6173–6183. [Online]. Available: https://doi.org/10...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.