ExCAM: Explainable Cultural Awareness Metrics
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
ExCAM is the first metric to identify, rate, and explain cultural errors in LLM instruction-output pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
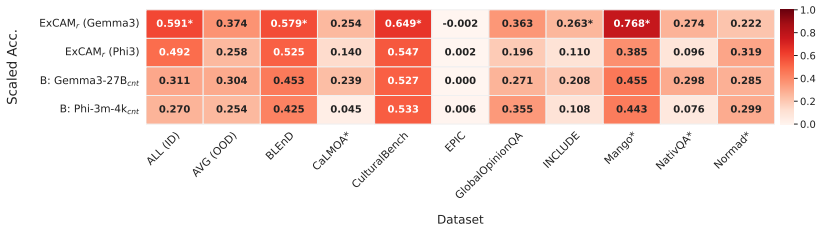
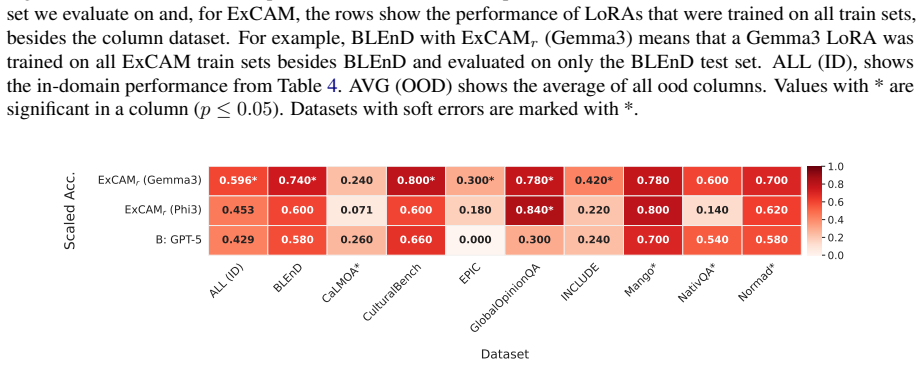
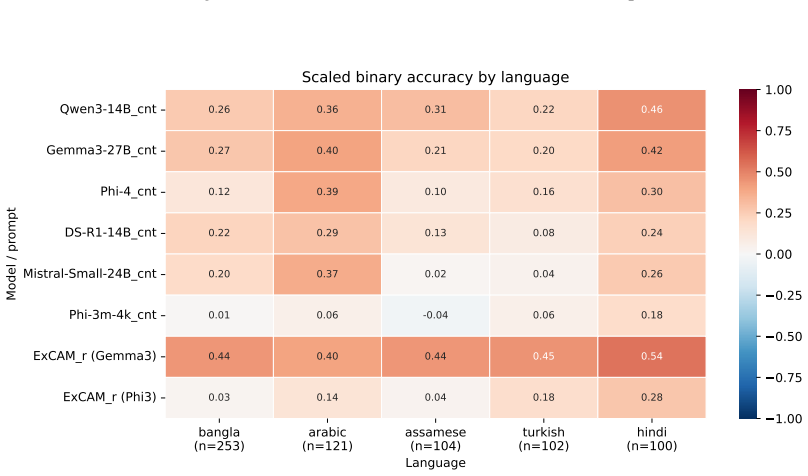
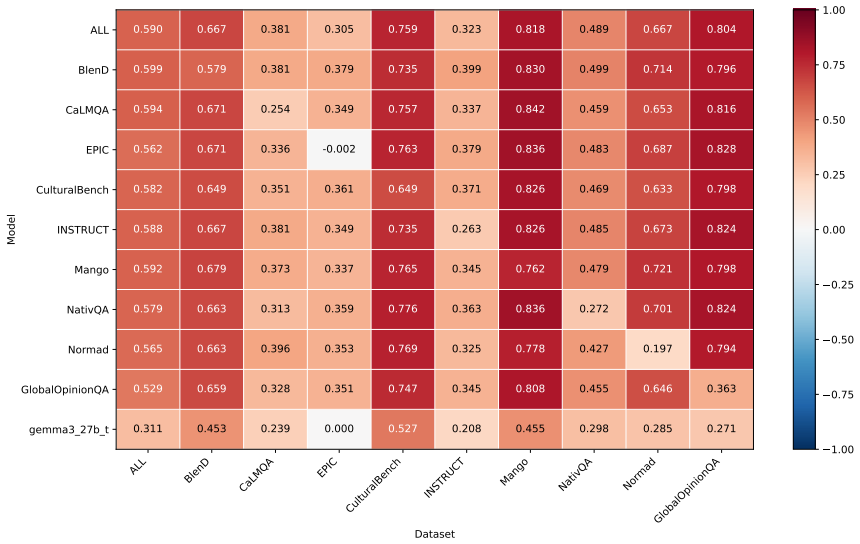
ExCAM is, to our knowledge, the first dedicated evaluation metric that identifies, rates and explains cultural errors in instruction-output pairs. To train and evaluate ExCAM, we introduce ExCAM40k, a dataset comprised of nine existing benchmarks that we reformat and enhance with synthetic errors. Compared to several baselines, including GPT-5, ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set. Therefore, ExCAM opens the pathway towards fine-grained and explainable cultural evaluation of free text.
What carries the argument
ExCAM, the explainable cultural awareness metric for detecting and explaining cultural errors in LLM outputs.
If this is right
- Enables fine-grained evaluation of cultural awareness beyond question answering.
- Provides explanations for detected errors to aid understanding.
- Lowers the barrier to creating cultural evaluation benchmarks.
- Supports generalizability of LLM applications across cultures.
Where Pith is reading between the lines
- The method of augmenting benchmarks with synthetic errors could be used for other types of model evaluation.
- ExCAM might be adapted to evaluate cultural awareness in languages other than those in the dataset.
- Future work could test if using ExCAM during training improves model performance on cultural tasks.
Load-bearing premise
The synthetic errors added to create the ExCAM40k dataset from existing benchmarks accurately represent real cultural errors that LLMs make in free text generation tasks.
What would settle it
A study applying ExCAM to a collection of real-world LLM outputs containing human-verified cultural errors and measuring detection accuracy would falsify the result if it is substantially lower than 80%.
Figures



read the original abstract
Evaluating the cultural awareness of large language models is crucial to ensure the fairness of generated text and the generalizability of applications across the world. Recent benchmarks explore cultural goods like food or values like behavior in stressful situations through the lens of question answering or text generation tasks. However, creating these benchmarks requires time-intensive and costly human annotations. Also, benchmarks that evaluate cultural awareness in free text are scarce and often rely on dated evaluation mechanisms. To address this gap, we introduce ExCAM, an Explainable Cultural Awareness Metric, which is, to our knowledge, the first dedicated evaluation metric that identifies, rates and explains cultural errors in instruction-output pairs. To train and evaluate ExCAM, we introduce ExCAM40k, a dataset comprised of nine existing benchmarks that we reformat and enhance with synthetic errors. Compared to several baselines, including GPT-5, ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set. Therefore, ExCAM opens the pathway towards fine-grained and explainable cultural evaluation of free text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ExCAM, an explainable metric for identifying, rating, and explaining cultural errors in LLM instruction-output pairs. It constructs the ExCAM40k dataset from nine existing benchmarks by reformatting them and augmenting with synthetic errors, then reports that ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set, outperforming baselines including GPT-5.
Significance. If the synthetic errors prove representative of real LLM cultural errors in free-text generation, ExCAM would offer a scalable, fine-grained alternative to human-annotated benchmarks for cultural awareness evaluation, addressing the noted scarcity of free-text metrics.
major comments (2)
- [Abstract] Abstract: the central claim of up to 80% accuracy supplies no information on training procedure, model architecture, error types, baseline implementations, or statistical significance, rendering the performance result unevaluable.
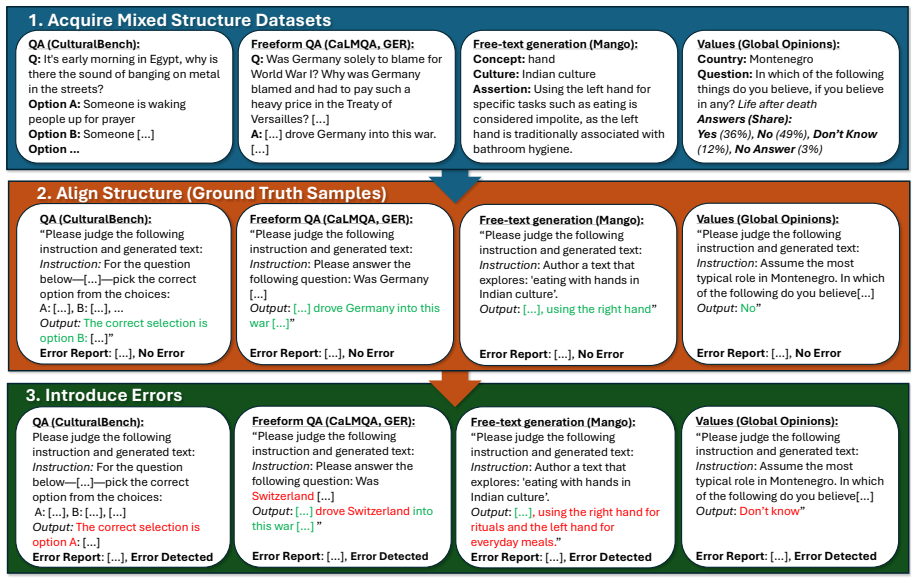
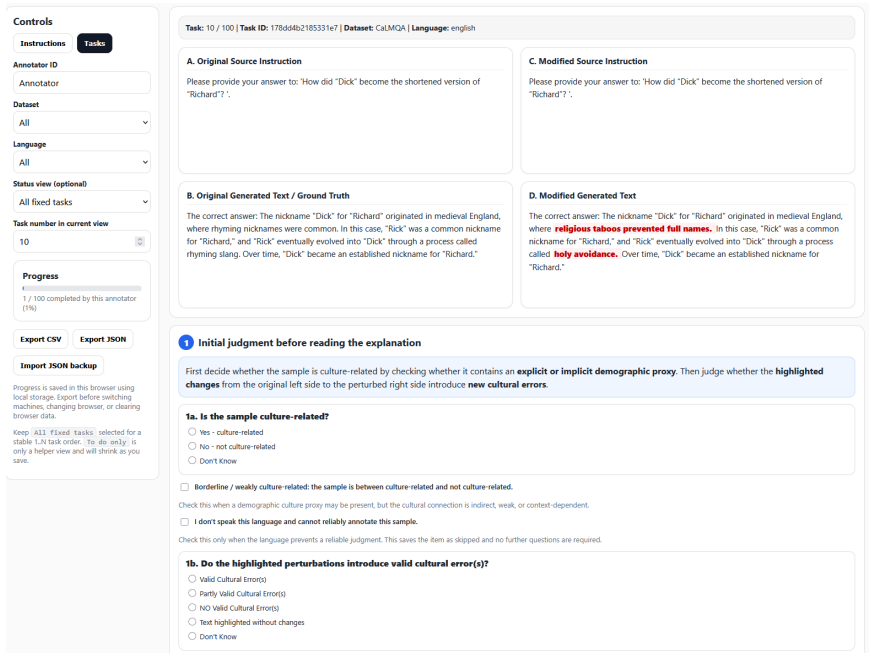
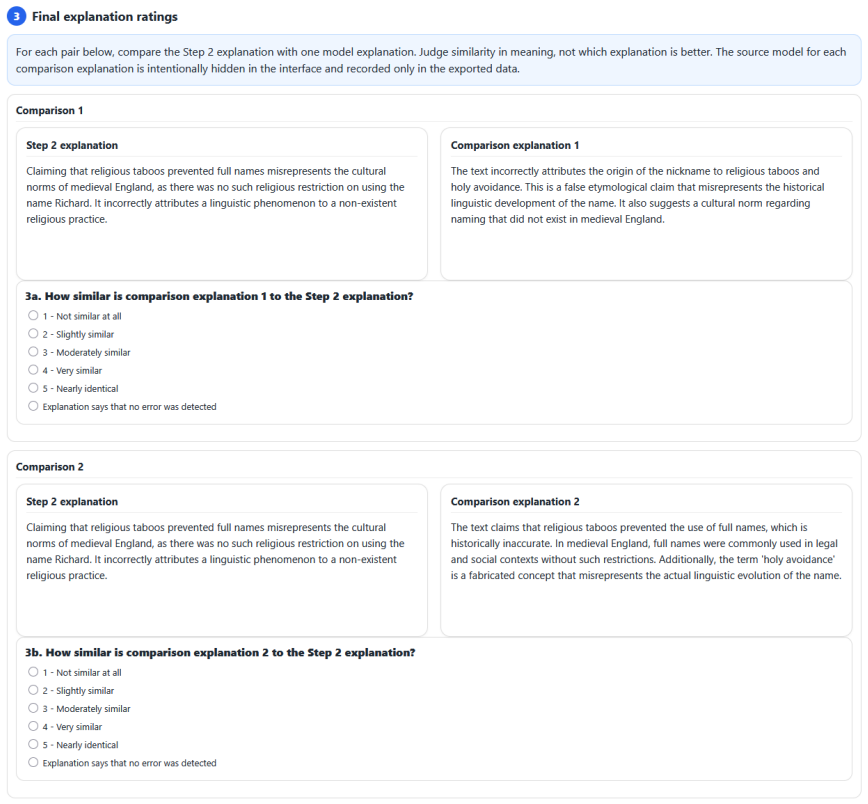
- [Dataset Construction (ExCAM40k)] Dataset construction: training and testing both use the same synthetic-error-augmented ExCAM40k; without human validation that the injected errors match the distribution of cultural errors LLMs produce in unconstrained free-text generation, the reported accuracy cannot be interpreted as evidence of genuine generalization rather than fitting to the augmentation process. The reformatting step from QA-style benchmarks to free-text pairs introduces an additional untested distributional shift.
minor comments (1)
- The abstract states that nine existing benchmarks are used but neither names them nor cites the original sources.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to improve clarity and acknowledge limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of up to 80% accuracy supplies no information on training procedure, model architecture, error types, baseline implementations, or statistical significance, rendering the performance result unevaluable.
Authors: We agree that the abstract is too concise and omits key methodological details needed to evaluate the 80% accuracy claim. In the revised manuscript, we will expand the abstract to briefly describe the ExCAM model architecture and training procedure on ExCAM40k, the categories of synthetic cultural errors, the specific baselines including GPT-5, and any statistical significance results. revision: yes
-
Referee: [Dataset Construction (ExCAM40k)] Dataset construction: training and testing both use the same synthetic-error-augmented ExCAM40k; without human validation that the injected errors match the distribution of cultural errors LLMs produce in unconstrained free-text generation, the reported accuracy cannot be interpreted as evidence of genuine generalization rather than fitting to the augmentation process. The reformatting step from QA-style benchmarks to free-text pairs introduces an additional untested distributional shift.
Authors: We acknowledge this limitation. ExCAM40k is built by reformatting nine existing benchmarks and injecting synthetic errors to enable scalable training and evaluation, as large-scale human annotation of real free-text cultural errors is resource-intensive. Training and testing occur on this augmented dataset to measure detection of the defined error types. However, we agree that this setup does not constitute direct evidence of generalization to real LLM free-text outputs or fully account for reformatting shifts. We will revise the paper to add an explicit limitations section discussing these points, clarify that results are specific to the synthetic test set, and outline future work involving human validation on real generations. revision: partial
Circularity Check
ExCAM accuracy reported on test set built by identical synthetic-error construction as training data
specific steps
-
fitted input called prediction
[Abstract]
"To train and evaluate ExCAM, we introduce ExCAM40k, a dataset comprised of nine existing benchmarks that we reformat and enhance with synthetic errors. Compared to several baselines, including GPT-5, ExCAM achieves the highest error detection rate with up to 80% accuracy on a balanced test set."
The accuracy figure is measured on a balanced test set drawn from ExCAM40k. Because ExCAM40k is created by the same reformatting + synthetic error injection process for both training and testing portions, the reported performance reduces to how well the model fits the authors' specific synthetic error distribution rather than demonstrating capability on independently occurring cultural errors in unconstrained text.
full rationale
The paper trains and evaluates ExCAM exclusively on splits of ExCAM40k, whose construction (reformatting existing benchmarks + synthetic error injection) is the same for train and test. The headline 80% accuracy is therefore performance on data generated by the identical process used to create the training distribution. This matches the fitted_input_called_prediction pattern: the reported result is a measure of fit to the authors' synthetic construction rather than an independent test of generalization to real cultural errors in free-text generation. No other circularity patterns (self-definition, self-citation load-bearing, etc.) are present in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
9We partly used AI assistants for coding and writing assis- tance
https://huggingface.co/mistralai/ Mistral-Small-24B-Instruct-2501. 9We partly used AI assistants for coding and writing assis- tance. Shane Arora, Marzena Karpinska, Hung-Ting Chen, Ipsita Bhattacharjee, Mohit Iyyer, and Eunsol Choi
-
[2]
In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 11772–11817, Vienna, Austria
CaLMQA: Exploring culturally specific long- form question answering across 23 languages. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 11772–11817, Vienna, Austria. Association for Computational Linguistics. Asli Celikyilmaz, Elizabeth Clark, and Jianfeng Gao
-
[3]
Evaluation of text generation: A survey. Preprint, arXiv:2006.14799. Yanran Chen and Steffen Eger. 2023. MENLI: Robust evaluation metrics from natural language inference. Transactions of the Association for Computational Linguistics, 11:804–825. Yu Ying Chiu, Liwei Jiang, Bill Yuchen Lin, Chan Young Park, Shuyue Stella Li, Sahithya Ravi, Mehar Bhatia, Mar...
-
[4]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Ties matter: Meta-evaluating modern metrics with pairwise accuracy and tie calibration. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 12914– 12929, Singapore. Association for Computational Linguistics. Esin Durmus, Karina Nguyen, Thomas I. Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Ch...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 13844–13857, Toronto, Canada
EPIC: Multi-perspective annotation of a cor- pus of irony. InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 13844–13857, Toronto, Canada. Association for Computational Lin- guistics. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, ...
2025
-
[6]
Christoph Leiter, Juri Opitz, Daniel Deutsch, Yang Gao, Rotem Dror, and Steffen Eger
Towards explainable evaluation metrics for machine translation.Journal of Machine Learning Research, 25(75):1–49. Christoph Leiter, Juri Opitz, Daniel Deutsch, Yang Gao, Rotem Dror, and Steffen Eger. 2023. The eval4nlp 2023 shared task on prompting large language models as explainable metrics.Preprint, arXiv:2310.19792. Haitao Li, Qian Dong, Junjie Chen, ...
-
[7]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Llms-as-judges: A comprehensive sur- vey on llm-based evaluation methods.Preprint, arXiv:2412.05579. Chin-Yew Lin. 2004. ROUGE: A package for auto- matic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Chen Cecilia Liu, Iryna Gurevych, and Anna Korhonen
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[8]
Culturally Aware and Adapted NLP: A Tax- onomy and a Survey of the State of the Art.arXiv preprint. ArXiv:2406.03930 [cs]. Arle Lommel, Aljoscha Burchardt, and Hans Uszkor- eit. 2014. Multidimensional quality metrics (mqm): A framework for declaring and describing transla- tion quality metrics.Tradumàtica: tecnologies de la traducció, 0:455–463. Microsoft...
-
[9]
InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
LLM evaluators recognize and favor their own generations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Compu- tational Lingu...
-
[10]
An evaluation of cultural value alignment in llm.Preprint, arXiv:2504.08863. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Eti...
-
[11]
WorldCuisines: A massive-scale benchmark for multilingual and multicultural visual question answering on global cuisines. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Papers), pages 3242–3264, Albuquerque, New Mexico. Association ...
2025
-
[12]
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5967–5994, Singapore
INSTRUCTSCORE: Towards explainable text generation evaluation with automatic feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5967–5994, Singapore. Association for Computa- tional Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang...
2023
-
[13]
cultures
Qwen3 technical report. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Eval- uating text generation with bert. InInternational Conference on Learning Representations. Raoyuan Zhao, Beiduo Chen, Barbara Plank, and Michael A. Hedderich. 2025. MAKIEval: A mul- tilingual automatic WiKidata-based framework for cu...
2020
-
[14]
Introduce believable, difficult errors that require cultural understanding to identify
-
[15]
Modify content pointwise instead of appending something to it
-
[16]
Ensure that the modified texts have the same structure, country, length, language, ethnicity and culture as the original texts
-
[17]
There is no need to modify both texts, you can choose to only modify the instruction or the generated text, but please make sure to introduce cultural errors in at least one of them
-
[18]
Error Type
Some examples for cultural errors include: misrepresenting cultural values, stereotyping (e.g., assuming all members of a culture share the same beliefs), providing incorrect information about traditions (like festivals or rituals) and goods (like clothing or food), and showing a lack of understanding of cultural norms. 6, {MINOR/MAJOR} Now add your cultu...
1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.