An Efficient Machine Learning-based Framework for Detection and Prevention of Frauds in Telecom Networks
Pith reviewed 2026-05-19 23:22 UTC · model grok-4.3
pith:66GCTIJ3 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{66GCTIJ3}
Prints a linked pith:66GCTIJ3 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Random Forest detects telecom fraud at 99.9% accuracy after data balancing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
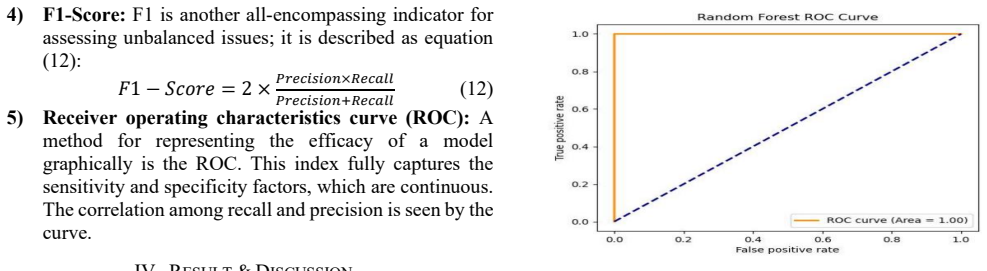
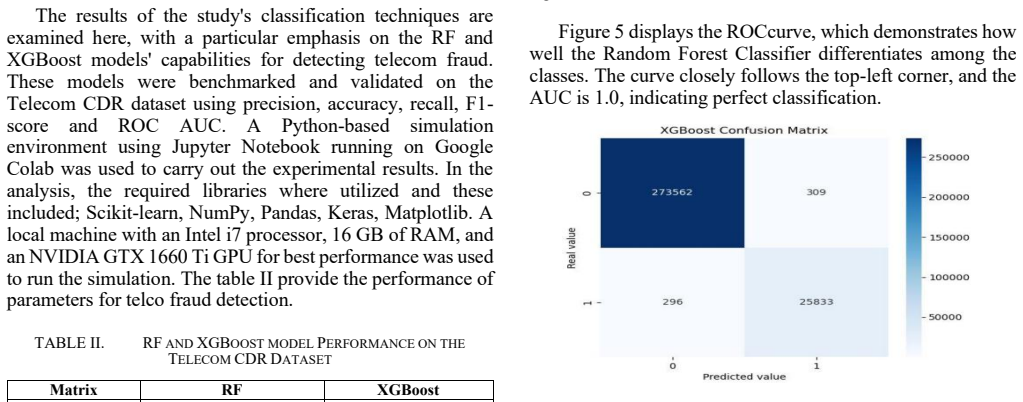
Using a Telecom CDR dataset with 101,174 records and 17 attributes including 8,830 fraud cases, the framework preprocesses data with missing value handling, Min-Max scaling, and SMOTE balancing, then applies Random Forest to achieve 99.9% accuracy, precision, recall, and F1-score while XGBoost reaches 99.7%, demonstrating superior fraud detection with minimal misclassifications compared to models like DBSCAN, RoBERTa, and K-means.
What carries the argument
The Random Forest model trained on scaled and SMOTE-balanced Call Detail Record features acts as the primary classifier to distinguish fraudulent activities based on the dataset attributes.
If this is right
- Random Forest outperforms XGBoost and other models including GNN and BERT in all performance metrics.
- The approach results in robust fraud detection with few errors on the evaluated dataset.
- Machine learning provides an efficient method for fraud prevention in telecommunication systems.
Where Pith is reading between the lines
- Deploying this model in real-time monitoring could allow immediate blocking of suspicious calls.
- Extending the preprocessing pipeline to other industries with imbalanced fraud data might yield similar high accuracy.
- Validating on datasets from varied telecom operators would test the model's adaptability to different fraud types.
Load-bearing premise
The high performance scores obtained after SMOTE balancing on the training data will hold for new fraud patterns encountered in live telecom network operations.
What would settle it
Evaluating the trained Random Forest model on a completely separate and later-collected CDR dataset to measure if accuracy, precision, recall, and F1-score stay near 99.9 percent or decline substantially.
Figures



read the original abstract
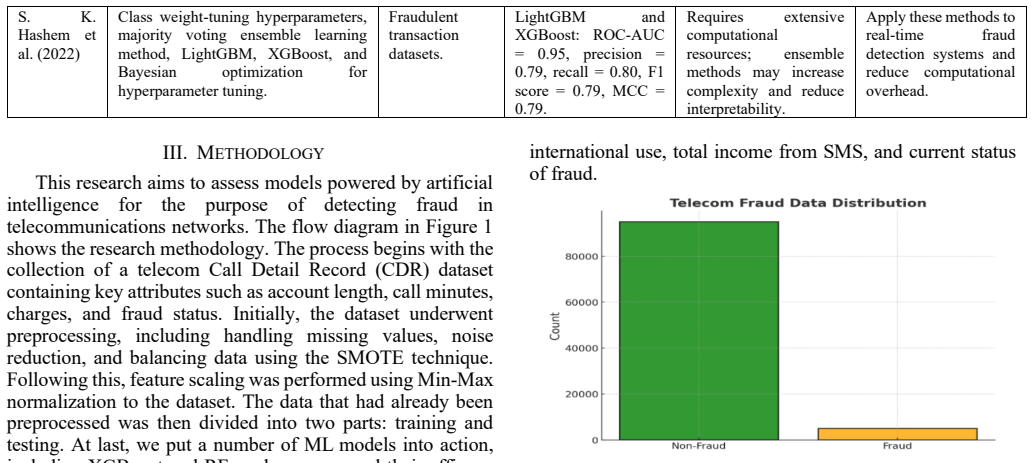
Telecommunication fraud is an acute problem that leads to substantial material losses and compromises the reliability of telecom systems worldwide. Only effective and efficient detection mechanisms can help to deal with these threats, though there are certain shifts in the approaches to fraud detection. This paper evaluates the performance of AI-driven models for fraud detection in telecommunication networks using Call Detail Record (CDR) datasets. This study focuses on fraud detection in telecom networks using the Telecom CDR dataset, which contains 101,174 customer records with 17 attributes, including 8,830 fraud cases. In feature preprocessing, missing values were dealt with, followed by data scaling using Min-Max scaling and data balancing using the SMOTE technique. The dataset was trained for predictive analysis using Random Forest (RF) and XGBoost models. F1-score, ROC AUC, recall, accuracy, time, and precision were used as indicators with which to compare performance of the two models. RF recorded a high level of accuracy at 99.9% while XGBoost at 99.7%. Findings show that the suggested framework successfully detects fraud with few misclassifications. Several machine learning models were evaluated and contrasted, such as RF, XGBoost, DBSCAN, RoBERTa, and K-means. Among all the models, RF was seen to give the highest performance with an accuracy of 99.9% and precision of 99.9%, recall of 99.9% and F1-score of 99.9%, XGBoost, GNN and BERT. The findings emphasize RF as the most effective model for detecting fraudulent activities in telecom networks, ensuring robust and reliable prevention of fraud.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an ML-based framework for fraud detection in telecom networks using a CDR dataset of 101,174 records (8,830 fraud cases). After handling missing values, applying Min-Max scaling, and balancing via SMOTE, it trains Random Forest and XGBoost models and reports that Random Forest achieves 99.9% accuracy, precision, recall, and F1-score, outperforming XGBoost and other baselines such as DBSCAN, RoBERTa, and K-means. The central claim is that this framework provides effective and reliable fraud detection with few misclassifications.
Significance. If the evaluation protocol were shown to use a proper train-test split with SMOTE applied only after splitting and no leakage, the reported near-perfect metrics on a real-world-scale CDR dataset would constitute a practically significant result for operational telecom fraud prevention. The work would then offer a concrete, deployable baseline that could be compared against production systems. As written, however, the performance numbers cannot be interpreted as evidence of generalization.
major comments (2)
- [Abstract and Results] Abstract and results section: the reported 99.9% accuracy/precision/recall/F1 for Random Forest (and 99.7% for XGBoost) are presented without any description of the train-test split ratio, whether the split occurred before or after SMOTE, or any cross-validation procedure. In an 8.7% fraud-rate setting, applying SMOTE to the full dataset before splitting is a well-known source of leakage that produces inflated metrics; this omission directly undermines the central claim that the framework “successfully detects fraud with few misclassifications.”
- [Methodology] Methodology section: the paper states that “the dataset was trained for predictive analysis” after SMOTE but supplies no hold-out set statistics, no mention of an independent test set untouched during hyper-parameter tuning or balancing, and no external validation on live network traffic. Without these details the headline performance figures rest on an unverifiable assumption of generalization.
minor comments (2)
- [Abstract] The abstract lists “time” among the evaluation indicators but no training or inference latency numbers appear in the reported results; clarify whether runtime was measured and, if so, on what hardware.
- [Abstract] The manuscript mentions evaluation of “GNN and BERT” in the abstract but provides no implementation details, hyper-parameters, or performance numbers for these models; either remove the reference or add the missing results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about the evaluation protocol and data leakage, providing the missing details on the train-test split and hold-out set while clarifying the scope of the study.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and results section: the reported 99.9% accuracy/precision/recall/F1 for Random Forest (and 99.7% for XGBoost) are presented without any description of the train-test split ratio, whether the split occurred before or after SMOTE, or any cross-validation procedure. In an 8.7% fraud-rate setting, applying SMOTE to the full dataset before splitting is a well-known source of leakage that produces inflated metrics; this omission directly undermines the central claim that the framework “successfully detects fraud with few misclassifications.”
Authors: We agree that the original manuscript lacked a clear description of the train-test split and the timing of SMOTE application, which is essential for interpreting the results. We have revised the Abstract, Methodology, and Results sections to specify that a stratified 80/20 train-test split was performed prior to any preprocessing or balancing steps, with SMOTE and Min-Max scaling applied exclusively to the training portion to prevent leakage. We have also added details on 5-fold cross-validation conducted solely within the training set for hyperparameter tuning. These revisions directly address the potential for inflated metrics and strengthen the evidence for the framework's effectiveness. revision: yes
-
Referee: [Methodology] Methodology section: the paper states that “the dataset was trained for predictive analysis” after SMOTE but supplies no hold-out set statistics, no mention of an independent test set untouched during hyper-parameter tuning or balancing, and no external validation on live network traffic. Without these details the headline performance figures rest on an unverifiable assumption of generalization.
Authors: We acknowledge the insufficient detail in the original Methodology section. The revised version now includes hold-out set statistics (test set size of approximately 20,235 records) and explicitly states that the test set remained completely untouched during scaling, SMOTE balancing, and hyperparameter tuning. Performance metrics on the independent test set are now reported separately. Regarding external validation on live network traffic, this was outside the scope of the current study, which evaluates the framework on the provided static CDR dataset; we have added a limitations and future work subsection discussing plans for operational deployment and real-time validation. revision: partial
- External validation results on live network traffic cannot be provided, as the study was limited to the available CDR dataset and did not include access to operational telecom systems.
Circularity Check
Reported 99.9% RF metrics reduce to in-sample fit after SMOTE on full dataset without verified out-of-sample split
specific steps
-
fitted input called prediction
[Abstract]
"In feature preprocessing, missing values were dealt with, followed by data scaling using Min-Max scaling and data balancing using the SMOTE technique. The dataset was trained for predictive analysis using Random Forest (RF) and XGBoost models. ... RF recorded a high level of accuracy at 99.9% while XGBoost at 99.7%. ... RF was seen to give the highest performance with an accuracy of 99.9% and precision of 99.9%, recall of 99.9% and F1-score of 99.9%"
Preprocessing and balancing steps are described as applied to the full dataset before training; the subsequent 'predictive analysis' metrics are then presented as evidence of successful detection. Because SMOTE generates synthetic samples from the minority class across the entire data, any evaluation performed after this step (absent a documented split-first protocol) is statistically forced by the fitting process itself rather than constituting an independent prediction on unseen fraud instances.
full rationale
The paper's central claim of an effective fraud detection framework rests on performance metrics (accuracy, precision, recall, F1) obtained after applying Min-Max scaling and SMOTE balancing to the 101k-record dataset, followed by training RF and XGBoost. No explicit description of train-test split timing, cross-validation, or hold-out statistics is provided before balancing. In this setup the quoted metrics largely restate the outcome of fitting the model to the processed (including synthetically balanced) data rather than measuring generalization to unseen patterns, satisfying the fitted-input-called-prediction pattern.
Axiom & Free-Parameter Ledger
free parameters (2)
- SMOTE oversampling ratio
- Random Forest and XGBoost hyperparameters
axioms (1)
- domain assumption The 101,174-record CDR dataset with 8,830 fraud cases is representative of real-world telecom fraud distributions.
Reference graph
Works this paper leans on
-
[1]
An examination of machine learning -based credit card fraud detection systems,
H. Sinha, “An examination of machine learning -based credit card fraud detection systems,” Int. J. Sci. Res. Arch., vol. 12, no. 01, pp. 2282–2294, 2024, doi: https://doi.org/10.30574/ijsra.2024.12.2.1456
-
[2]
A Machine and Deep Learning Framework for Robust Health Insurance Fraud Detection and Prevention,
Suhag Pandya, “A Machine and Deep Learning Framework for Robust Health Insurance Fraud Detection and Prevention,” Int. J. Adv. Res. Sci. Commun. Technol. , pp. 1332–1342, Jul. 2023, doi: 10.48175/IJARSCT-14000U
-
[3]
ConvNets for fraud detection analysis,
A. Chouiekh and E. H. I. El Haj, “ConvNets for fraud detection analysis,” Procedia Comput. Sci. , vol. 127, pp. 133 –138, 2018, doi: 10.1016/j.procs.2018.01.107
-
[4]
The Assessments Of Financial Risk Based On Renewable Energy Industry,
M. R. S. and P. K. Vishwakarma, “The Assessments Of Financial Risk Based On Renewable Energy Industry,” Int. Res. J. Mod. Eng. Technol. Sci., vol. 06, no. 09, pp. 758–770, 2024
work page 2024
-
[5]
The Machine Learning Based Regression Models Analysis For House Price Prediction,
R. Tandon, “The Machine Learning Based Regression Models Analysis For House Price Prediction,” Int. J. Res. Anal. Rev., vol. 11, no. 3, pp. 296–305, 2024
work page 2024
-
[6]
Data Mining Techniques in Telecommunication Company,
N. Ahmadzai, H. Mohammadi, and N. Mangal, “Data Mining Techniques in Telecommunication Company,” J. Res. Appl. Sci. Biotechnol., 2023, doi: 10.55544/jrasb.2.1.12
-
[7]
Olajide Soji Osundare, Chidiebere Somadina Ike, Ololade Gilbert Fakeyede, and Adebimpe Bolatito Ige, “x,” Comput. Sci. IT Res. J., vol. 4, no. 3, pp. 458–477, 2023, doi: 10.51594/csitrj.v4i3.1499
-
[8]
Prediction of Stock Market Trends Based on Large Language Models,
R. Tandon, “Prediction of Stock Market Trends Based on Large Language Models,” J. Emerg. Technol. Innov. Res., vol. 11, no. 9, pp. a615–a622, 2024
work page 2024
-
[9]
Big Data Analysis with No Digital Footprints Available: Evidence from Cyber -Telecom Fraud,
L. X. Liu, Y. Liu, X. Ruan, and Y. Zhang, “Big Data Analysis with No Digital Footprints Available: Evidence from Cyber -Telecom Fraud,” SSRN Electron. J., 2021, doi: 10.2139/ssrn.3991369
-
[10]
F. E. Onuodu and S. B. Nnaa, “An Enhanced Fraud Detection Model using Neural Networks for Telecommunications and Smart Cards in Nigeria,” London J. Res. …, vol. 20, no. 2, 2020
work page 2020
-
[11]
M. Bajpai, “Available online www.jsaer.com Fraud Detection and Prevention in Telecommunication Data and Voice Networks,” vol. 7, no. 6, pp. 302–305, 2020
work page 2020
-
[12]
V. Kolluri, “Revolutionizing Healthcare Delivery: The Role of AI and Machine Learning in Personalized Medicine and Predictive Analytics,” Well Test. J., vol. 33, no. 02, 2024
work page 2024
-
[13]
A Novel Method for Detecting Telecom Fraud User,
R. Li, Y. Zhang, Y. Tuo, and P. Chang, “A Novel Method for Detecting Telecom Fraud User,” in Proceedings - 2018 3rd International Conference on Information Systems Engineering, ICISE 2018, 2018. doi: 10.1109/ICISE.2018.00016
-
[14]
Telecom fraud detection with big data analytics,
D. S. Terzi, Ş. Sağıroğlu, and H. Kılınç, “Telecom fraud detection with big data analytics,” Int. J. Data Sci., vol. 6, no. 3, p. 191, 2021, doi: 10.1504/ijds.2021.121090
-
[15]
The Future of Database Administration: AI Integration and Innovation,
B. Boddu, “The Future of Database Administration: AI Integration and Innovation,” J. Sci. Eng. Res. , vol. 11, no. 1, pp. 312 –316, 2024
work page 2024
-
[16]
A. J. Rahul Dattangire, Ruchika Vaidya, Divya Biradar, “Exploring the Tangible Impact of Artificial Intelligence and Machine Learning: Bridging the Gap between Hype and Reality,” 2024 1st Int. Conf. Adv. Comput. Emerg. Technol., pp. 1–6, 2024
work page 2024
-
[17]
Telecommunications Fraud Machine Learning-based Detection,
B. A. Yehya and N. Salhab, “Telecommunications Fraud Machine Learning-based Detection,” 2023 4th Int. Conf. Data Anal. Bus. Ind. ICDABI 2023 , no. August, pp. 656 –661, 2023, doi: 10.1109/ICDABI60145.2023.10629612
-
[18]
AI-Enhanced Demand Forecasting Dashboard Device Having Interface for Optimal Inventory Management
J. Thomas, H. Volikatla, J. Vummadi, and R. Shah, “AI-Enhanced Demand Forecasting Dashboard Device Having Interface for Optimal Inventory Management.” 2024
work page 2024
-
[19]
E. M. D. Djomadji, K. I. Basile, T. T. Christian, F. V. K. Djoko, and M. E. Sone, “Machine Learning -Based Approach for Identification of SIM Box Bypass Fraud in a Telecom Network Based on CDR Analysis: Case of a Fixed and Mobile Operator in Cameroon,” J. Comput. Commun. , 2023, doi: 10.4236/jcc.2023.112010
-
[20]
Optimisation of Deep Learning based Model for Identification of Credit Card Frauds,
H. Palivela et al., “Optimisation of Deep Learning based Model for Identification of Credit Card Frauds,” IEEE Access, vol. 12, no. September, pp. 125629 –125642, 2024, doi: 10.1109/ACCESS.2024.3440637
-
[21]
J. Li, C. Zhang, and L. Jiang, “Innovative Telecom Fraud Detection: A New Dataset and an Advanced Model with RoBERTa and Dual Loss Functions,” Appl. Sci., vol. 14, no. 24, p. 11628, Dec. 2024, doi: 10.3390/app142411628
-
[22]
Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning,
V. Chang, B. Ali, L. Golightly, M. A. Ganatra, and M. Mohamed, “Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning,” Information, vol. 15, no. 8, p. 478, Aug. 2024, doi: 10.3390/info15080478
-
[23]
R. Li, H. Chen, S. Liu, K. Wang, B. Wang, and X. Hu, “TFD-IIS- CRMCB: Telecom Fraud Detection for Incomplete Information Systems Based on Correlated Relation and Maximal Consistent Block,” Entropy, 2023, doi: 10.3390/e25010112
-
[24]
Fraud Detection in Banking Data by Machine Learning Techniques,
S. K. Hashemi, S. L. Mirtaheri, and S. Greco, “Fraud Detection in Banking Data by Machine Learning Techniques,” IEEE Access , 2023, doi: 10.1109/ACCESS.2022.3232287
-
[25]
Research on Data Preprocessing and Categorization Technique for Smartphone Review Analysis,
V. Agarwal, “Research on Data Preprocessing and Categorization Technique for Smartphone Review Analysis,” Int. J. Comput. Appl., 2015, doi: 10.5120/ijca2015907309
-
[26]
Quality Assurance In The Age Of Data Analytics: Innovations And Challenges,
K. Patel, “Quality Assurance In The Age Of Data Analytics: Innovations And Challenges,” Int. J. Creat. Res. Thoughts, vol. 9, no. 12, pp. f573–f578, 2021
work page 2021
-
[27]
L. Guanyu, “Leveraging Machine Learning for Telecom Banking Card Fraud Detection : A Comparative Analysis of Logistic Regression , Random Forest , and XGBoost Models,” vol. 1, no. 1, pp. 13–27, 2024
work page 2024
-
[28]
N. Abid, “Empowering Cybersecurity : Optimized Network Intrusion Detection Using Data Balancing and Advanced Machine Learning Models,” TIJER, vol. 11, no. 12, 2024
work page 2024
-
[29]
Analysis of anomaly and novelty detection in time series data using machine learning techniques,
H. Sinha, “Analysis of anomaly and novelty detection in time series data using machine learning techniques,” Multidiscip. Sci. J., vol. 7, no. 06, 2024, doi: https://doi.org/10.31893/multiscience.2025299
-
[30]
A. Cutler, D. R. Cutler, and J. R. Stevens, “Ensemble Machine Learning,” Ensemble Mach. Learn. , no. January, 2012, doi: 10.1007/978-1-4419-9326-7
-
[31]
M. Gopalsamy, “Evaluating the Effectiveness of Machine Learning (ML) Models in Detecting Malware Threats for Cybersecurity,” Int. J. Curr. Eng. Technol. , vol. 13, no. 06, 2023, doi: : https://doi.org/10.14741/ijcet/v.13.6.4
-
[32]
M. Gopalsamy, “Identification and Classification of Phishing Emails Based on Machine Learning Techniques to Improvise Cybersecurity,” Int. J. Sci. Adv. Res. Technol., vol. 10, no. 10, pp. 47–57, 2024
work page 2024
-
[33]
Extreme gradient boosting (Xgboost) model to predict the groundwater levels in Selangor Malaysia,
A. Ibrahem Ahmed Osman, A. Najah Ahmed, M. F. Chow, Y. Feng Huang, and A. El -Shafie, “Extreme gradient boosting (Xgboost) model to predict the groundwater levels in Selangor Malaysia,” Ain Shams Eng. J., vol. 12, no. 2, pp. 1545–1556, 2021, doi: https://doi.org/10.1016/j.asej.2020.11.011
-
[34]
Mining Mobile Network Fraudsters with Augmented Graph Neural Networks,
X. Hu, H. Chen, H. Chen, X. Li, J. Zhang, and S. Liu, “Mining Mobile Network Fraudsters with Augmented Graph Neural Networks,” Entropy, vol. 25, no. 1, pp. 1 –16, 2023, doi: 10.3390/e25010150
-
[35]
Fraud Detection Call Detail Record Using Machine Learning in Telecommunications Company,
M. A. Jabbar and S. Suharjito, “Fraud Detection Call Detail Record Using Machine Learning in Telecommunications Company,” Adv. Sci. Technol. Eng. Syst. J. , vol. 5, no. 4, pp. 63 – 69, Jul. 2020, doi: 10.25046/aj050409
-
[36]
Z. Aziz and R. Bestak, “Insight into Anomaly Detection and Prediction and Mobile Network Security Enhancement Leveraging K-Means Clustering on Call Detail Records,” Sensors, vol. 24, no. 6, p. 1716, Mar. 2024, doi: 10.3390/s24061716
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.