StickyInvoc: Rethinking Task Models for High-throughput Workflows in the LLM Era
Pith reviewed 2026-06-26 11:14 UTC · model grok-4.3
The pith
StickyInvoc decouples state creation from computation so invocation tasks inherit persistent LLM models without repeated loading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
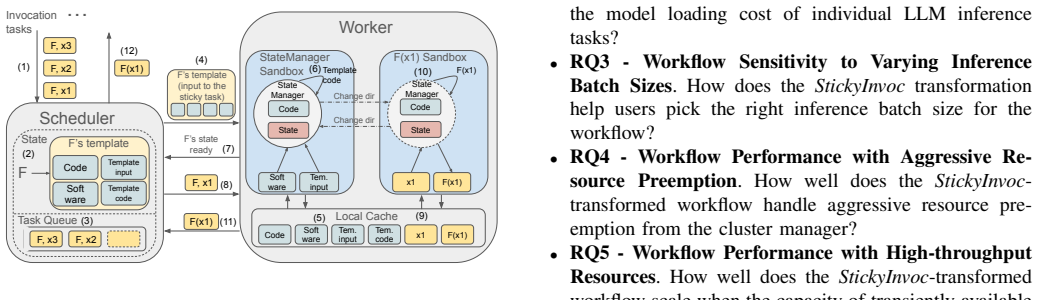
StickyInvoc establishes a symbiotic relationship between two new task models: a sticky task creates a persistent computational state on a compute node from a user-provided template without performing goodput computation, while subsequent invocation tasks inherit that state to execute the actual computation without incurring creation or destruction overhead. The model therefore decouples the creation and destruction of computational states, allowing the state of LLM models to be created once per sticky task and amortized over many invocation tasks.
What carries the argument
The StickyInvoc paradigm of sticky tasks that create persistent state and invocation tasks that inherit it without recreation or destruction.
If this is right
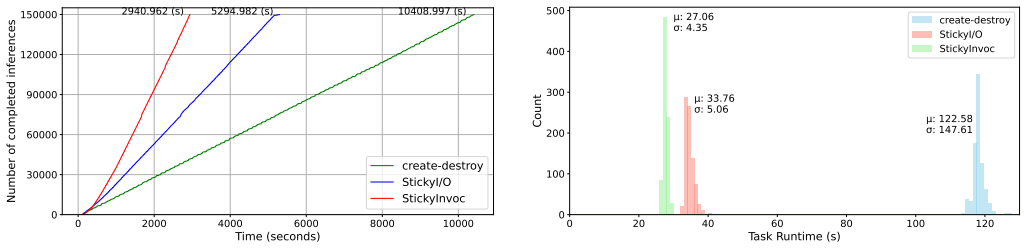
- A claim verification workflow of 150k inferences achieves a 3.6x speedup on a 20-GPU testbed.
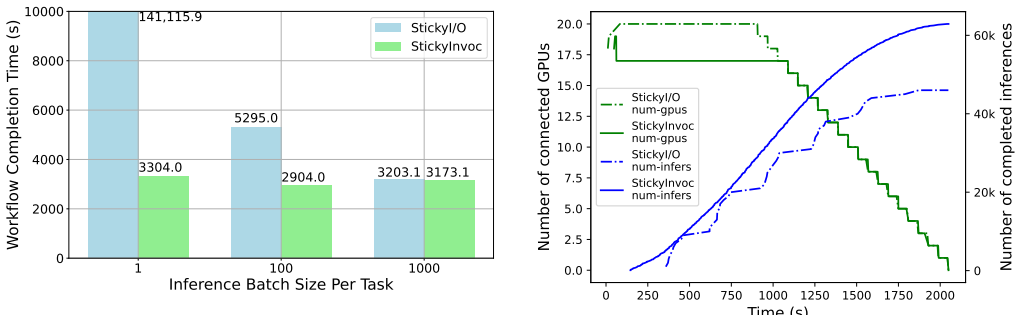
- The same workflow completes in 784 seconds when incrementally scaled to 186 otherwise idle GPUs.
- Model loading costs are incurred only once per sticky task instead of once per inference task.
- High-throughput workflows can utilize heterogeneous and preemptible resources more effectively by leaving model state resident.
Where Pith is reading between the lines
- The model could apply to other state-heavy scientific codes that currently repeat large data loads, such as molecular dynamics or climate simulations.
- Incremental scaling to idle GPUs implies the approach may improve overall cluster utilization when combined with existing schedulers.
- Repeated state transfers avoided by this method could lower total energy use for LLM inference campaigns.
- Explicit tests of inheritance under high preemption rates would be needed to confirm robustness beyond the reported stable testbed.
Load-bearing premise
Invocation tasks can reliably inherit and use the persistent state created by a sticky task without additional overhead or failure under the heterogeneous and preemptible conditions typical of high-throughput resources.
What would settle it
Observing that state inheritance on preemptible nodes either fails or adds measurable overhead that erases the reported 3.6x speedup on the 150k-inference workflow would disprove the central performance claim.
Figures





read the original abstract
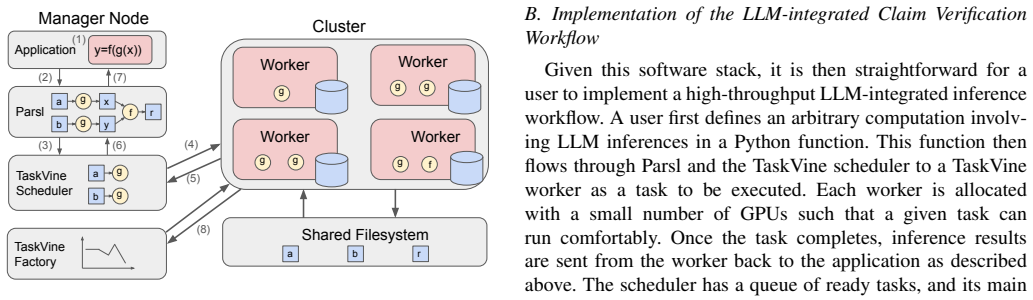
The integration of LLMs into high-throughput workflows is creating a new class of workloads on HPC clusters that promises to accelerate advances in scientific discovery with unprecedented generative capabilities. However, the traditional task model imposes a prohibitive overhead in this new domain: each task must create its computational state from scratch and destroy it upon completion. For each LLM inference task, this "create-destroy" model forces the repeated and costly transfer of multi-gigabyte model parameters from a long-term, reliable storage to a compute node's local disk, its CPU memory, and finally its GPU memory. This overhead, compounded by the inherently high startup cost of LLM inference, the typical scale of thousands of tasks in high-throughput workflows, and the heterogeneous and preemptible nature of high-throughput resources, presents a significant performance barrier. To overcome this barrier, this paper presents StickyInvoc: a symbiotic relationship between two new task models for high-throughput workflows. Specifically, a "sticky" task creates a persistent state on a compute node from a user-provided template, but doesn't execute any goodput computation by itself. Instead, this state is then inherited by subsequent "invocation" tasks, which perform the actual computation without incurring the state creation overhead or destroying the state upon exit. StickyInvoc thus allows the decoupling of the creation and destruction of computational states, allowing the computational state of LLM models to be created once per sticky task and its cost amortized over many subsequent invocation tasks. Our evaluation shows that when rewritten in the StickyInvoc paradigm, a claim verification workflow consisting of 150k inferences achieves a 3.6x speedup on a stable testbed with 20 GPUs, and completes in just 784 seconds by incrementally scaling out to 186 otherwise idle GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StickyInvoc, a new task model pairing 'sticky' tasks (which create persistent computational state such as loaded LLM models from a user template without performing goodput work) with 'invocation' tasks (which inherit that state to execute inferences). It claims that rewriting a claim-verification workflow of 150k inferences under this model yields a 3.6x speedup on a stable 20-GPU testbed and finishes in 784 seconds when scaling out to 186 otherwise-idle GPUs.
Significance. If the inheritance mechanism proves reliable, the approach would amortize multi-gigabyte model-loading costs across many tasks and could materially improve throughput for LLM-driven scientific workflows on HPC clusters; the empirical scaling result on otherwise-idle GPUs is a concrete, falsifiable data point that strengthens the practical case.
major comments (1)
- [Abstract / Evaluation description] The abstract states that heterogeneous and preemptible resources are a core source of create-destroy overhead that StickyInvoc must overcome, yet the reported 3.6x speedup and 784-second completion are measured exclusively on a stable testbed with 20 GPUs plus otherwise-idle GPUs. No results are given for state inheritance, recovery from preemption, or cross-node heterogeneity, leaving the load-bearing assumption that invocation tasks can reliably use sticky state without added overhead or failure under the stated conditions untested.
minor comments (1)
- [Abstract] The abstract reports a 3.6x speedup without error bars, workload parameter details, or a description of how the baseline task model was implemented, making it difficult to judge whether post-hoc selection or unaccounted overheads affect the result.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of significance and for the detailed comment. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract / Evaluation description] The abstract states that heterogeneous and preemptible resources are a core source of create-destroy overhead that StickyInvoc must overcome, yet the reported 3.6x speedup and 784-second completion are measured exclusively on a stable testbed with 20 GPUs plus otherwise-idle GPUs. No results are given for state inheritance, recovery from preemption, or cross-node heterogeneity, leaving the load-bearing assumption that invocation tasks can reliably use sticky state without added overhead or failure under the stated conditions untested.
Authors: The referee correctly notes that the reported 3.6x speedup and 784-second scaling result were obtained on a stable 20-GPU testbed plus otherwise-idle GPUs, without dedicated experiments measuring recovery from preemption or behavior under cross-node heterogeneity. State inheritance itself is directly exercised and measured by the 150k-inference claim-verification workflow that produces the 3.6x improvement. The scaling experiment further shows that invocation tasks can attach to sticky state across a larger set of idle GPUs. We agree, however, that the abstract's emphasis on heterogeneous and preemptible resources as a primary motivation is not matched by results that explicitly test those conditions. We will therefore revise the abstract and evaluation description to more precisely delineate the tested scenarios and add an explicit limitations paragraph on preemption and heterogeneity. This is a partial revision; new experiments on preemptible resources are outside the scope of the current testbed. revision: partial
Circularity Check
No circularity: speedup is empirical measurement, not derived quantity
full rationale
The paper introduces StickyInvoc as a new task model that decouples state creation (sticky tasks) from computation (invocation tasks) to amortize LLM model loading costs. Its central performance claim is an empirical observation: a claim verification workflow with 150k inferences achieves 3.6x speedup on a 20-GPU stable testbed and completes in 784s when scaling to 186 GPUs. This is presented as a direct experimental result rather than a prediction or first-principles derivation from equations or fitted parameters. No self-citations, uniqueness theorems, or ansatzes are used to support the result; the evaluation stands as an independent measurement of the implemented system. The derivation chain consists of model description followed by benchmark data, with no step reducing a claimed output to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
sticky task
no independent evidence
-
invocation task
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
The Claude 3 Model Family: Opus, Sonnet, Haiku,
Anthropic, “The Claude 3 Model Family: Opus, Sonnet, Haiku,” 2024, available at https://www- cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model Card Claude 3.pdf
2024
-
[4]
Minifold: Simple, fast, and accurate protein structure prediction,
J. Wohlwend, M. Reveiz, M. McPartlon, A. Feldmann, W. Jin, and R. Barzilay, “Minifold: Simple, fast, and accurate protein structure prediction,”Transactions on Machine Learning Research, 2025
2025
-
[5]
A. Shah and S. Jayaratnam, “Energy efficient protein language models: Leveraging small language models with lora for controllable protein generation,”arXiv preprint arXiv:2411.05966, 2024
-
[6]
Scaling down for effi- ciency: Medium-sized transformer models for protein sequence transfer learning,
L. C. Vieira, M. L. Handojo, and C. O. Wilke, “Scaling down for effi- ciency: Medium-sized transformer models for protein sequence transfer learning,”bioRxiv, pp. 2024–11, 2024
2024
-
[7]
Col- mena: Scalable machine-learning-based steering of ensemble simula- tions for high performance computing,
L. Ward, G. Sivaraman, J. G. Pauloski, Y . Babuji, R. Chard, N. Dandu, P. C. Redfern, R. S. Assary, K. Chard, L. A. Curtisset al., “Col- mena: Scalable machine-learning-based steering of ensemble simula- tions for high performance computing,” in2021 IEEE/ACM Workshop on Machine Learning in High Performance Computing Environments (MLHPC). IEEE, 2021, pp. 9–20
2021
-
[8]
Workflowllm: Enhancing workflow orchestration capability of large language models,
S. Fan, X. Cong, Y . Fu, Z. Zhang, S. Zhang, Y . Liu, Y . Wu, Y . Lin, Z. Liu, and M. Sun, “Workflowllm: Enhancing workflow orchestration capability of large language models,”arXiv preprint arXiv:2411.05451, 2024
-
[9]
A strategic coordination framework of small llms matches large llms in data synthesis,
X. Gao, Q. Pei, Z. Tang, Y . Li, H. Lin, J. Wu, L. Wu, and C. He, “A strategic coordination framework of small llms matches large llms in data synthesis,”arXiv preprint arXiv:2504.12322, 2025
-
[10]
Pegasus, a work- flow management system for science automation,
E. Deelman, K. Vahi, G. Juve, M. Rynge, S. Callaghan, P. J. Maechling, R. Mayani, W. Chen, R. F. Da Silva, M. Livnyet al., “Pegasus, a work- flow management system for science automation,”Future Generation Computer Systems, vol. 46, pp. 17–35, 2015
2015
-
[12]
Nextflow enables reproducible computational work- flows,
P. Di Tommaso, M. Chatzou, E. W. Floden, P. P. Barja, E. Palumbo, and C. Notredame, “Nextflow enables reproducible computational work- flows,”Nature biotechnology, vol. 35, no. 4, pp. 316–319, 2017
2017
-
[13]
Work queue+ python: A framework for scalable scientific ensemble appli- cations,
P. Bui, D. Rajan, B. Abdul-Wahid, J. Izaguirre, and D. Thain, “Work queue+ python: A framework for scalable scientific ensemble appli- cations,” inWorkshop on python for high performance and scientific computing at sc11, 2011
2011
-
[14]
Reproducible, scalable, and share- able analysis pipelines with bioinformatics workflow managers,
L. Wratten, A. Wilm, and J. G ¨oke, “Reproducible, scalable, and share- able analysis pipelines with bioinformatics workflow managers,”Nature methods, vol. 18, no. 10, pp. 1161–1168, 2021
2021
-
[15]
The nf-core framework for community-curated bioinformatics pipelines,
P. A. Ewels, A. Peltzer, S. Fillinger, H. Patel, J. Alneberg, A. Wilm, M. U. Garcia, P. Di Tommaso, and S. Nahnsen, “The nf-core framework for community-curated bioinformatics pipelines,”Nature biotechnology, vol. 38, no. 3, pp. 276–278, 2020
2020
-
[16]
A scalable scenic workflow for single-cell gene regulatory network analysis,
B. Van de Sande, C. Flerin, K. Davie, M. De Waegeneer, G. Hulselmans, S. Aibar, R. Seurinck, W. Saelens, R. Cannoodt, Q. Rouchonet al., “A scalable scenic workflow for single-cell gene regulatory network analysis,”Nature protocols, vol. 15, no. 7, pp. 2247–2276, 2020
2020
-
[17]
Reshaping high en- ergy physics applications for near-interactive execution using taskvine,
B. Sly-Delgado, B. Tovar, J. Zhou, and D. Thain, “Reshaping high en- ergy physics applications for near-interactive execution using taskvine,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–13
2024
-
[18]
Dynamic task shaping for high throughput data analysis applications in high energy physics,
B. Tovar, B. Lyons, K. Mohrman, B. Sly-Delgado, K. Lannon, and D. Thain, “Dynamic task shaping for high throughput data analysis applications in high energy physics,” in2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2022, pp. 346– 356
2022
-
[19]
Pegasus workflow management system: helping applications from earth and space,
G. Mehta, E. Deelman, K. Vahi, and F. Silva, “Pegasus workflow management system: helping applications from earth and space,” inAGU Fall Meeting Abstracts, vol. 2010, 2010, pp. IN41B–1362
2010
-
[20]
Gemma 2b,
Google, “Gemma 2b,” Hugging Face, 2025, accessed: 2025-10-01. [Online]. Available: https://huggingface.co/google/gemma-2-2b
2025
-
[21]
Smollm2-1.7b-instruct,
H. Face, “Smollm2-1.7b-instruct,” Hugging Face, 2025, accessed: 2025-10-01. [Online]. Available: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct
2025
-
[22]
Stablelm-2-1.6b,
S. AI, “Stablelm-2-1.6b,” Hugging Face, 2025, accessed: 2025-10-01. [Online]. Available: https://huggingface.co/stabilityai/stablelm-2-1 6b
2025
-
[23]
Qwen2.5-1.5b,
U. AI, “Qwen2.5-1.5b,” Hugging Face, 2025, accessed: 2025-10-01. [Online]. Available: https://huggingface.co/unsloth/Qwen2.5-1.5B
2025
-
[24]
Deepseek-r1-distill-qwen-1.5b,
DeepSeek-AI, “Deepseek-r1-distill-qwen-1.5b,” Hugging Face, 2025, accessed: 2025-10-01. [Online]. Available: https://huggingface.co/deepseek- ai/DeepSeek-R1-Distill-Qwen-1.5B
2025
-
[25]
Ohio Supercomputer Center
(2025) Monitoring and managing your job. Ohio Supercomputer Center. Accessed: 2025-10-01. [Online]. Available: https://www.osc.edu/ supercomputing/batch-processing-at-osc/monitoring-and-managing- your-job
2025
-
[26]
Princeton Research Computing
(2025) Job priority. Princeton Research Computing. Accessed: 2025- 10-01. [Online]. Available: https://researchcomputing.princeton.edu/ support/knowledge-base/job-priority
2025
-
[27]
Argonne Leadership Computing Facility (ALCF)
(2025) Queue scheduling. Argonne Leadership Computing Facility (ALCF). Accessed: 2025-10-01. [Online]. Available: https://docs.alcf.anl.gov/policies/queue-scheduling/
2025
-
[28]
2025 global semiconductor industry outlook,
Deloitte Insights, “2025 global semiconductor industry outlook,” February 2025. [Online]. Available: https://www.deloitte.com/us/en/insights/industry/technology/technology- media-telecom-outlooks/semiconductor-industry-outlook.html
2025
-
[29]
K. F. Pilz, J. Sanders, R. Rahman, and L. Heim, “Trends in ai supercomputers,”arXiv preprint arXiv:2504.16026, 2025
-
[30]
A survey on hardware accelerators for large language models,
C. Kachris, “A survey on hardware accelerators for large language models,”Applied Sciences, vol. 15, no. 2, p. 586, 2025
2025
-
[31]
Scheduling deep learning jobs in multi-tenant gpu clusters via wise resource sharing,
Y . Luo, Q. Wang, S. Shi, J. Lai, S. Qi, J. Zhang, and X. Wang, “Scheduling deep learning jobs in multi-tenant gpu clusters via wise resource sharing,” in2024 IEEE/ACM 32nd International Symposium on Quality of Service (IWQoS). IEEE, 2024, pp. 1–10
2024
-
[32]
Resource allocation and workload scheduling for large-scale distributed deep learning: A survey,
F. Liang, Z. Zhang, H. Lu, C. Li, V . Leung, Y . Guo, and X. Hu, “Resource allocation and workload scheduling for large-scale distributed deep learning: A survey,”arXiv preprint arXiv:2406.08115, 2024
-
[33]
Mirage: Towards low-interruption services on batch gpu clusters with reinforce- ment learning,
Q. Ding, P. Zheng, S. Kudari, S. Venkataraman, and Z. Zhang, “Mirage: Towards low-interruption services on batch gpu clusters with reinforce- ment learning,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023, pp. 1–13
2023
-
[34]
Multi-tenant gpu clusters for deep learning workloads: Anal- ysis and implications,
M. Jeon, S. Venkataraman, J. Qian, A. Phanishayee, W. Xiao, and F. Yang, “Multi-tenant gpu clusters for deep learning workloads: Anal- ysis and implications,”Technical report, Microsoft Research, 2018
2018
-
[35]
{AntMan}: Dynamic scaling on{GPU}clusters for deep learning,
W. Xiao, S. Ren, Y . Li, Y . Zhang, P. Hou, Z. Li, Y . Feng, W. Lin, and Y . Jia, “{AntMan}: Dynamic scaling on{GPU}clusters for deep learning,” in14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), 2020, pp. 533–548
2020
-
[36]
Analysis of{Large-Scale}{Multi-Tenant}{GPU}clusters for{DNN}training workloads,
M. Jeon, S. Venkataraman, A. Phanishayee, J. Qian, W. Xiao, and F. Yang, “Analysis of{Large-Scale}{Multi-Tenant}{GPU}clusters for{DNN}training workloads,” in2019 USENIX Annual Technical Conference (USENIX ATC 19), 2019, pp. 947–960
2019
-
[37]
(2025) Queues and charges. NERSC. Accessed: 2025-10-02. [Online]. Available: https://docs.nersc.gov/jobs/policy/#qos-cost-factor- charge-multipliers-and-discounts
2025
-
[38]
NCAR HPC
(2025) Job premption with pbs. NCAR HPC. Ac- cessed: 2025-10-02. [Online]. Available: https://ncar-hpc- docs.readthedocs.io/en/latest/pbs/preemption/#charging-and-allocations
2025
-
[39]
University of Maryland High- Performance Computing Center
(2025) Available hpc partitions. University of Maryland High- Performance Computing Center. Accessed: 2025-10-02. [Online]. Available: https://hpcc.umd.edu/kb/queues/#scavenger-partition
2025
-
[40]
Center for High Performance Computing at the University of Utah
(2025) Atomatic restarting of preemptable jobs. Center for High Performance Computing at the University of Utah. Accessed: 2025-10-02. [Online]. Available: https://www.chpc.utah.edu/documentation/software/slurm-job- preemption.php#Automatic%20Restarting%20of%20Preemptable%20Jobs
2025
-
[41]
Fermilab
(2025) Slurm job scheduler. Fermilab. Accessed: 2025-10-02. [Online]. Available: https://computing.fnal.gov/wilsoncluster/slurm-job-scheduler/
2025
-
[42]
Center for Computational Research at the University at Buffalo
(2025) Slurm directives, partitions & qos. Center for Computational Research at the University at Buffalo. Accessed: 2025-10-02. [On- line]. Available: https://docs.ccr.buffalo.edu/en/latest/hpc/jobs/#slurm- directives-partitions-qos
2025
-
[43]
{AW ARE}: Automate workload autoscaling with reinforcement learning in production cloud systems,
H. Qiu, W. Mao, C. Wang, H. Franke, A. Youssef, Z. T. Kalbarczyk, T. Bas ¸ar, and R. K. Iyer, “{AW ARE}: Automate workload autoscaling with reinforcement learning in production cloud systems,” in2023 USENIX Annual Technical Conference (USENIX ATC 23), 2023, pp. 387–402
2023
-
[44]
Optscaler: A collaborative framework for robust autoscaling in the cloud,
D. Zou, W. Lu, Z. Zhu, X. Lu, J. Zhou, X. Wang, K. Liu, K. Wang, R. Sun, and H. Wang, “Optscaler: A collaborative framework for robust autoscaling in the cloud,”Proceedings of the VLDB Endowment, vol. 17, no. 12, pp. 4090–4103, 2024
2024
-
[45]
Tuning a kubernetes horizontal pod autoscaler for meeting performance and load demands in cloud deployments,
D. R. Augustyn, Ł. Wyci ´slik, and M. Sojka, “Tuning a kubernetes horizontal pod autoscaler for meeting performance and load demands in cloud deployments,”Applied Sciences, vol. 14, no. 2, p. 646, 2024
2024
-
[46]
A survey on auto-scaling: how to exploit cloud elasticity,
M. Catillo, U. Villano, and M. Rak, “A survey on auto-scaling: how to exploit cloud elasticity,”International Journal of Grid and Utility Computing, vol. 14, no. 1, pp. 37–50, 2023
2023
-
[47]
Checkpointing techniques in distributed systems: A synopsis of diverse strategies over the last decades,
H. Goulart, A. Franco, and O. Mendizabal, “Checkpointing techniques in distributed systems: A synopsis of diverse strategies over the last decades,” inWorkshop de Testes e Toler ˆancia a Falhas (WTF). SBC, 2023, pp. 15–28
2023
-
[48]
Mcrengine: A scalable checkpointing system using data-aware aggregation and compression,
T. Z. Islam, K. Mohror, S. Bagchi, A. Moody, B. R. De Supinski, and R. Eigenmann, “Mcrengine: A scalable checkpointing system using data-aware aggregation and compression,” inSC’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE, 2012, pp. 1–11
2012
-
[49]
Checkmate: Evaluating checkpointing protocols for streaming dataflows,
G. Siachamis, K. Psarakis, M. Fragkoulis, A. Van Deursen, P. Carbone, and A. Katsifodimos, “Checkmate: Evaluating checkpointing protocols for streaming dataflows,” in2024 IEEE 40th international conference on data engineering (ICDE). IEEE, 2024, pp. 4030–4043
2024
-
[50]
Parsl: Per- vasive parallel programming in python,
Y . Babuji, A. Woodard, Z. Li, D. S. Katz, B. Clifford, R. Kumar, L. Lacinski, R. Chard, J. M. Wozniak, I. Fosteret al., “Parsl: Per- vasive parallel programming in python,” inProceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing, 2019, pp. 25–36
2019
-
[51]
Taskvine: Managing in-cluster storage for high- throughput data intensive workflows,
B. Sly-Delgado, T. S. Phung, C. Thomas, D. Simonetti, A. Hennessee, B. Tovar, and D. Thain, “Taskvine: Managing in-cluster storage for high- throughput data intensive workflows,” inProceedings of the SC’23 Work- shops of the International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 1978–1988
2023
-
[52]
Maximizing data utility for hpc python workflow execution,
T. S. Phung, B. Clifford, K. Chard, and D. Thain, “Maximizing data utility for hpc python workflow execution,” inProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 637–640
2023
-
[53]
Accelerating function-centric applications by discovering, distributing, and retaining reusable context in workflow systems,
T. S. Phung, C. Thomas, L. Ward, K. Chard, and D. Thain, “Accelerating function-centric applications by discovering, distributing, and retaining reusable context in workflow systems,” inProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, 2024, pp. 122–134
2024
-
[54]
Adaptive task-oriented resource allocation for large dynamic workflows on opportunistic resources,
T. S. Phung and D. Thain, “Adaptive task-oriented resource allocation for large dynamic workflows on opportunistic resources,” in2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2024, pp. 300–311
2024
-
[55]
X. Zhang and W. Gao, “Towards llm-based fact verification on news claims with a hierarchical step-by-step prompting method,”arXiv preprint arXiv:2310.00305, 2023
-
[56]
Molecular facts: Desiderata for decontex- tualization in llm fact verification,
A. Gunjal and G. Durrett, “Molecular facts: Desiderata for decontex- tualization in llm fact verification,”arXiv preprint arXiv:2406.20079, 2024
-
[57]
FEVER: a large-scale dataset for fact extraction and VERification,
J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “FEVER: a large-scale dataset for fact extraction and VERification,” inNAACL- HLT, 2018
2018
-
[58]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Bl ´azquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydl ´ıˇcek, A. P. Lajar ´ın, V . Srivastav et al., “Smollm2: When smol goes big–data-centric training of a small language model,”arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Distributed computing in practice: the condor experience,
D. Thain, T. Tannenbaum, and M. Livny, “Distributed computing in practice: the condor experience,”Concurrency and computation: prac- tice and experience, vol. 17, no. 2-4, pp. 323–356, 2005
2005
-
[60]
Taming metadata storms in parallel filesystems with metafs,
T. Shaffer and D. Thain, “Taming metadata storms in parallel filesystems with metafs,” inProceedings of the 2nd Joint International Workshop on Parallel Data Storage & Data Intensive Scalable Computing Systems, 2017, pp. 25–30
2017
-
[61]
Scalable performance of the panasas parallel file system
B. Welch, M. Unangst, Z. Abbasi, G. A. Gibson, B. Mueller, J. Small, J. Zelenka, and B. Zhou, “Scalable performance of the panasas parallel file system.” inFAST, vol. 8, 2008, pp. 1–17
2008
-
[62]
Anaconda software distribution,
A. Inc., “Anaconda software distribution,” https://docs.anaconda.com/, 2020
2020
-
[63]
Google Cloud
(2025) Spot vms. Google Cloud. [Online]. Available: https://cloud.google.com/solutions/spot-vms
2025
-
[64]
Amazon Web Services (AWS)
(2025) Amazon ec2 spot instances. Amazon Web Services (AWS). [Online]. Available: https://aws.amazon.com/ec2/spot/
2025
-
[65]
Microsoft Azure
(2025) Spot virtual machines. Microsoft Azure. [Online]. Available: https://azure.microsoft.com/en-us/products/virtual-machines/spot
2025
-
[66]
Skyserve: Serving ai models across regions and clouds with spot instances,
Z. Mao, T. Xia, Z. Wu, W.-L. Chiang, T. Griggs, R. Bhardwaj, Z. Yang, S. Shenker, and I. Stoica, “Skyserve: Serving ai models across regions and clouds with spot instances,” inProceedings of the Twentieth European Conference on Computer Systems, 2025, pp. 159–175
2025
-
[67]
Spotserve: Serving generative large language models on preemptible instances,
X. Miao, C. Shi, J. Duan, X. Xi, D. Lin, B. Cui, and Z. Jia, “Spotserve: Serving generative large language models on preemptible instances,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 1112–1127
2024
-
[68]
Ama- zon Web Services (AWS)
(2025) Spot instance interruption notices. Ama- zon Web Services (AWS). [Online]. Avail- able: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot- instance-termination-notices.html
2025
-
[69]
Google Cloud
(2025) Spot vms. Google Cloud. [Online]. Available: https://cloud.google.com/compute/docs/instances/spot
2025
-
[70]
Microsoft Azure
(2025) Spot virtual machines. Microsoft Azure. [Online]. Available: https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms
2025
-
[71]
Fast inference from transform- ers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transform- ers via speculative decoding,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 19 274–19 286
2023
-
[72]
Accelerating llm inference with staged specula- tive decoding,
B. Spector and C. Re, “Accelerating llm inference with staged specula- tive decoding,”arXiv preprint arXiv:2308.04623, 2023
-
[73]
Cascade speculative drafting for even faster llm inference,
Z. Chen, X. Yang, J. Lin, C. Sun, K. Chang, and J. Huang, “Cascade speculative drafting for even faster llm inference,”Advances in Neural Information Processing Systems, vol. 37, pp. 86 226–86 242, 2024
2024
-
[74]
Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices,
R. Svirschevski, A. May, Z. Chen, B. Chen, Z. Jia, and M. Ryabinin, “Specexec: Massively parallel speculative decoding for interactive llm inference on consumer devices,”Advances in Neural Information Pro- cessing Systems, vol. 37, pp. 16 342–16 368, 2024
2024
-
[75]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 611–626
2023
-
[76]
B. Lin, C. Zhang, T. Peng, H. Zhao, W. Xiao, M. Sun, A. Liu, Z. Zhang, L. Li, X. Qiuet al., “Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,”arXiv preprint arXiv:2401.02669, 2024
-
[77]
{ServerlessLLM}:{Low-Latency}serverless inference for large language models,
Y . Fu, L. Xue, Y . Huang, A.-O. Brabete, D. Ustiugov, Y . Patel, and L. Mai, “{ServerlessLLM}:{Low-Latency}serverless inference for large language models,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 135–153
2024
-
[78]
Middleware building blocks for workflow systems,
M. Turilli, V . Balasubramanian, A. Merzky, I. Paraskevakos, and S. Jha, “Middleware building blocks for workflow systems,”Computing in Science & Engineering, vol. 21, no. 4, pp. 62–75, 2019
2019
-
[79]
Deploying high throughput scientific workflows on container schedulers with makeflow and mesos,
C. Zheng, B. Tovar, and D. Thain, “Deploying high throughput scientific workflows on container schedulers with makeflow and mesos,” in2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). IEEE, 2017, pp. 130–139
2017
-
[80]
Not all tasks are created equal: Adaptive resource allocation for heterogeneous tasks in dynamic workflows,
T. S. Phung, L. Ward, K. Chard, and D. Thain, “Not all tasks are created equal: Adaptive resource allocation for heterogeneous tasks in dynamic workflows,” in2021 IEEE Workshop on Workflows in Support of Large- Scale Science (WORKS). IEEE, 2021, pp. 17–24
2021
-
[81]
Dask: Parallel computation with blocked algorithms and task scheduling
M. Rocklinet al., “Dask: Parallel computation with blocked algorithms and task scheduling.” inSciPy, 2015, pp. 126–132
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.