Variational Learning for Insertion-based Generation
Pith reviewed 2026-06-28 15:21 UTC · model grok-4.3
The pith
A bijective mapping from insertion trajectories to permutations lets a new stochastic model learn where, what, and when to insert while supporting variable lengths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
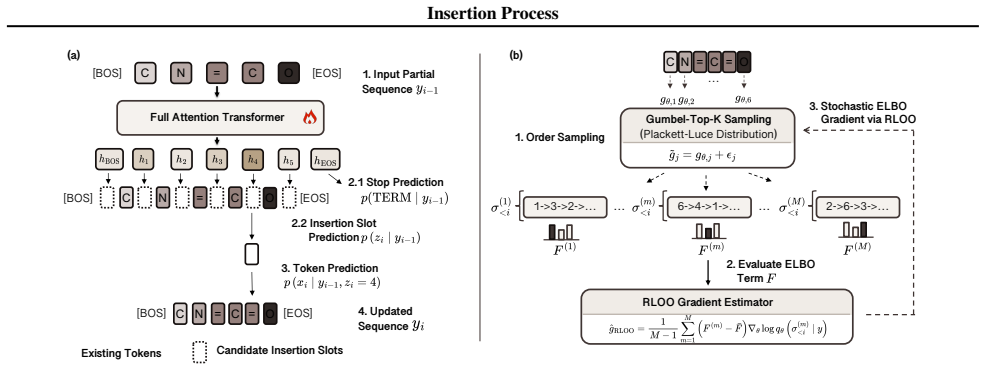
We formalize a bijective correspondence between insertion trajectories and permutations, which enables an exact reparameterization of the data likelihood as a sum over permutations. Building on this result, we propose the Insertion Process (IP), a stochastic generative model that jointly learns where to insert, what to insert, and when to terminate, trained via permutation-based variational inference.
What carries the argument
The bijective correspondence between insertion trajectories and permutations, which reparameterizes the data likelihood exactly as a sum over permutations for variational training.
If this is right
- The model generates sequences of arbitrary length without a fixed canvas or pre-specified termination.
- Insertion order becomes a learned distribution rather than a fixed or random schedule.
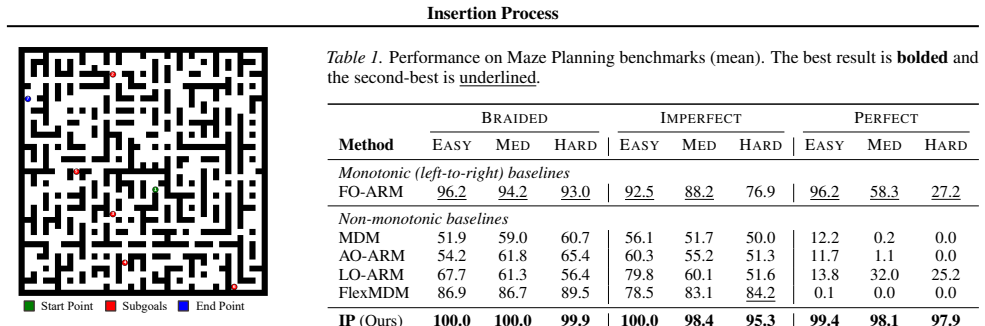
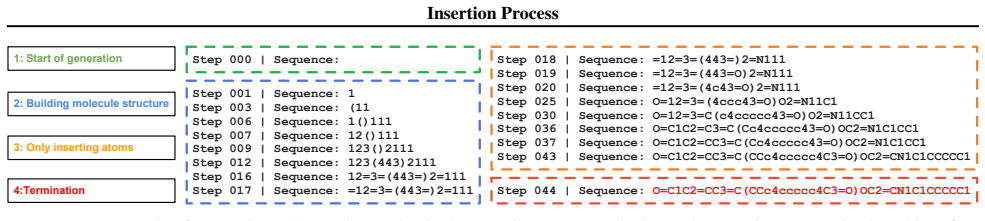
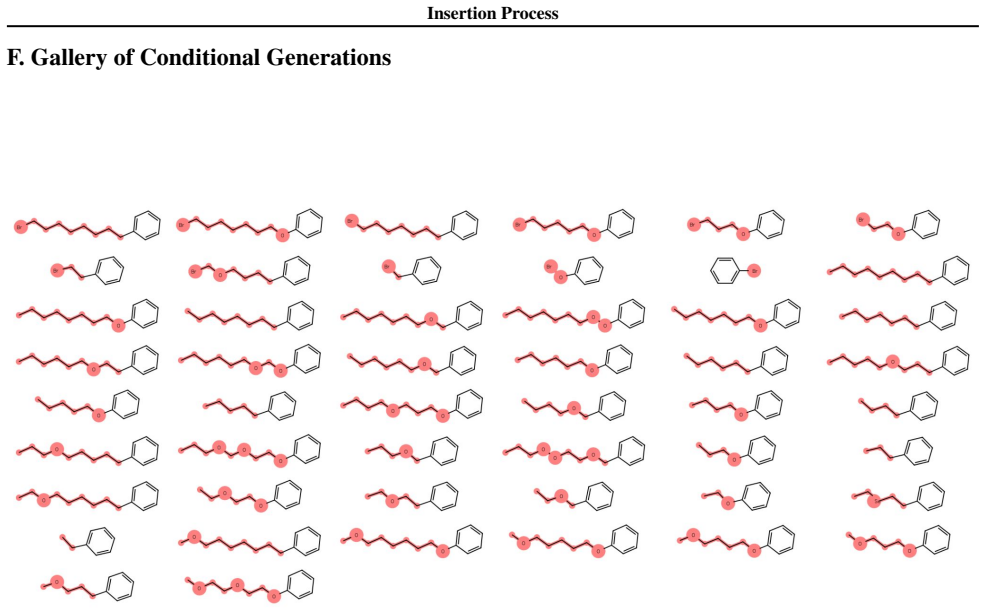
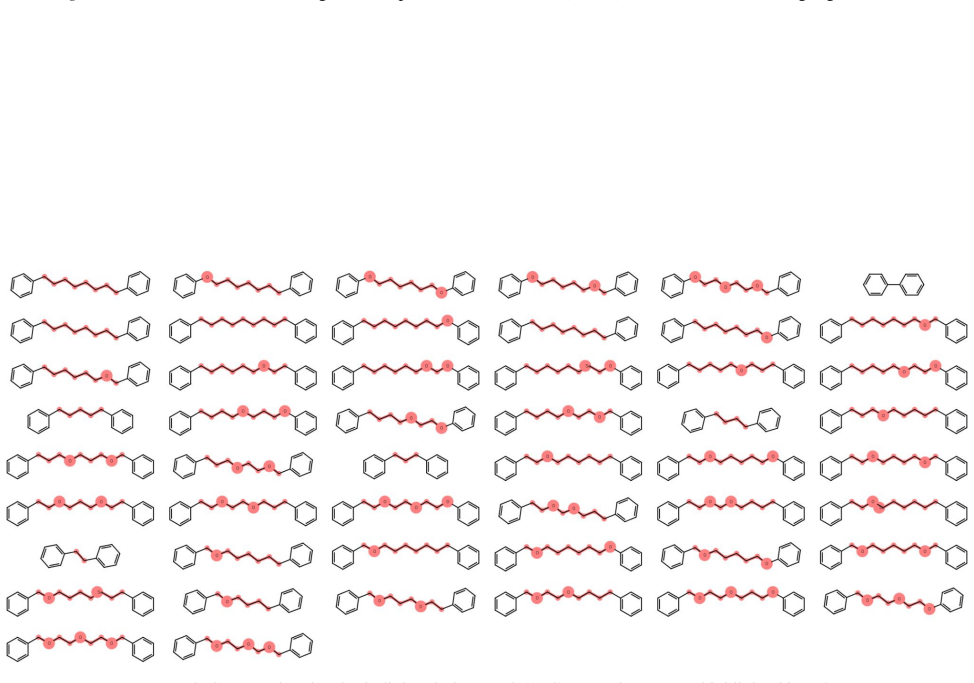
- Performance gains appear on tasks without canonical left-to-right order, such as goal-conditioned planning and molecular strings.
- Training remains tractable through permutation-based variational inference instead of enumerating all trajectories.
Where Pith is reading between the lines
- The same permutation reparameterization could be tested on other insertion-style tasks such as program synthesis or protein design where order is not obvious.
- If the learned insertion preferences prove stable across datasets, they might reveal domain-specific structural priors that autoregressive models cannot capture.
- Extending the framework to continuous or graph-structured data would require checking whether the permutation bijection still holds after relaxing the discrete token assumption.
Load-bearing premise
Every possible insertion trajectory maps bijectively to a unique permutation so that the likelihood can be rewritten without approximation or loss.
What would settle it
If summing the likelihood over the permutation representation produces a different value than direct enumeration of insertion paths on small fixed-length sequences, the claimed exact reparameterization is false.
Figures




read the original abstract
Non-monotonic sequence generation methods, such as masked diffusion models, provide a flexible alternative to left-to-right autoregressive modeling by allowing tokens to be generated in non-fixed and prescribed orders. Despite their practical advantages, most existing non-monotonic models are order-agnostic and rely on a fixed-length grid, limiting their ability to support variable-length generation and adaptive insertion order. In this work, we introduce a probabilistic framework for learning insertion order in variable-length insertion models. We formalize a bijective correspondence between insertion trajectories and permutations, which enables an exact reparameterization of the data likelihood as a sum over permutations. Building on this result, we propose the Insertion Process (IP), a stochastic generative model that jointly learns where to insert, what to insert, and when to terminate, trained via permutation-based variational inference. Unlike prior fixed-canvas approaches, IP natively supports variable-length generation and learns data-driven preferences over insertion orders. Experiments on goal-conditioned planning and molecular string generation demonstrate that learning insertion order improves both modeling quality and generalization in domains without a canonical left-to-right structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Insertion Process (IP), a stochastic generative model for non-monotonic, variable-length sequence generation. It formalizes a bijective correspondence between insertion trajectories and permutations that enables an exact reparameterization of the data likelihood as a sum over permutations. The model jointly learns insertion positions, token values, and termination, and is trained via permutation-based variational inference. Experiments on goal-conditioned planning and molecular string generation are used to demonstrate improvements over fixed-canvas baselines in domains without canonical left-to-right order.
Significance. If the bijective correspondence is rigorously shown to yield an exact reparameterization without hidden parameters or circularity, the framework would offer a principled advance over order-agnostic non-autoregressive models by supporting data-driven insertion orders and native variable-length generation. The permutation-based variational training is a direct application of standard techniques to this new correspondence, and the empirical results on planning and molecules suggest practical utility where ordering is not fixed a priori.
minor comments (3)
- [Abstract / §3] The abstract states the bijective correspondence and exact reparameterization but supplies no equations or proof sketch; the full manuscript should include an explicit statement of the mapping (e.g., in §3) and a short verification that the sum over permutations recovers the original likelihood.
- [§4] The description of the variational objective and the form of the permutation-based variational distribution is only sketched; adding the explicit ELBO expression and the parameterization of q(·) would improve reproducibility.
- [Experiments] Figure captions and experimental tables should report the number of permutations sampled during training and inference, as this directly affects the quality of the variational approximation.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation of minor revision. We are pleased that the bijective correspondence, exact reparameterization, and permutation-based variational inference are viewed as a principled advance.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The central derivation rests on formalizing a bijective correspondence between insertion trajectories and permutations, which is presented as a mathematical result that enables exact reparameterization of the likelihood as a sum over permutations. This step is independent of model parameters or fitted values and does not reduce to any self-definition, ansatz smuggled via citation, or prediction that is statistically forced by construction. The Insertion Process and its permutation-based variational inference are then constructed on top of this reparameterization using standard techniques. No load-bearing equations or claims in the abstract or described framework collapse to their own inputs. The result is self-contained against external benchmarks with no self-citation chains or renaming of known results as new derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption bijective correspondence between insertion trajectories and permutations
invented entities (1)
-
Insertion Process (IP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas , url =
Wu, Zirui and Zheng, Lin and Xie, Zhihui and Ye, Jiacheng and Gao, Jiahui and Feng, Yansong and Li, Zhenguo and W., Victoria and Zhou, Guorui and Kong, Lingpeng , year =. DreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas , url =
-
[2]
arXiv preprint arXiv:2406.03736 , year=
Your absorbing discrete diffusion secretly models the conditional distributions of clean data , author=. arXiv preprint arXiv:2406.03736 , year=
-
[3]
International Conference on Machine Learning , year=
Learning-Order Autoregressive Models with Application to Molecular Graph Generation , author=. International Conference on Machine Learning , year=
-
[4]
2025 , eprint=
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions , author=. 2025 , eprint=
2025
-
[5]
L ist O ps: A Diagnostic Dataset for Latent Tree Learning
Nangia, Nikita and Bowman, Samuel. L ist O ps: A Diagnostic Dataset for Latent Tree Learning. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Student Research Workshop. 2018
2018
-
[6]
2025 , eprint=
REOrdering Patches Improves Vision Models , author=. 2025 , eprint=
2025
-
[7]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Graph Diffusion that can Insert and Delete , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[8]
International Conference on Machine Learning , pages =
Insertion Transformer: Flexible Sequence Generation via Insertion Operations , author =. International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[9]
Insertion-based Decoding with Automatically Inferred Generation Order
Gu, Jiatao and Liu, Qi and Cho, Kyunghyun. Insertion-based Decoding with Automatically Inferred Generation Order. Transactions of the Association for Computational Linguistics. 2019
2019
-
[10]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:1409.0473 , year=
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Sequence modeling with unconstrained generation order , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Simplified and generalized masked diffusion for discrete data , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
2025 , eprint=
Any-Order Flexible Length Masked Diffusion , author=. 2025 , eprint=
2025
-
[17]
2021 , eprint=
Discovering Non-monotonic Autoregressive Orderings with Variational Inference , author=. 2021 , eprint=
2021
-
[18]
2019 , eprint=
KERMIT: Generative Insertion-Based Modeling for Sequences , author=. 2019 , eprint=
2019
-
[19]
2019 , eprint=
Levenshtein Transformer , author=. 2019 , eprint=
2019
-
[20]
2025 , eprint=
Edit Flows: Flow Matching with Edit Operations , author=. 2025 , eprint=
2025
-
[21]
2020 , eprint=
Blank Language Models , author=. 2020 , eprint=
2020
-
[22]
Frontiers in Pharmacology , VOLUME=
Polykovskiy, Daniil and Zhebrak, Alexander and Sanchez-Lengeling, Benjamin and Golovanov, Sergey and Tatanov, Oktai and Belyaev, Stanislav and Kurbanov, Rauf and Artamonov, Aleksey and Aladinskiy, Vladimir and Veselov, Mark and Kadurin, Artur and Johansson, Simon and Chen, Hongming and Nikolenko, Sergey and Aspuru-Guzik, Alán and Zhavoronkov, Alex , TITLE...
2020
-
[23]
and Vaucher, Alain C
Brown, Nathan and Fiscato, Marco and Segler, Marwin H.S. and Vaucher, Alain C. , title =. Journal of Chemical Information and Modeling , volume =. 2019 , doi =
2019
-
[24]
Buy 4 reinforce samples, get a baseline for free! , author=
-
[25]
International conference on machine learning , pages=
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[26]
Screening of multi deep learning-based de novo molecular generation models and their application for specific target molecular generation
Wang, Yishu and Guo, Mengyao and Chen, Xiaomin and Ai, Dongmei. Screening of multi deep learning-based de novo molecular generation models and their application for specific target molecular generation. Sci. Rep
-
[27]
The Electronic Journal of Combinatorics , volume=
The insertion encoding of permutations , author=. The Electronic Journal of Combinatorics , volume=. 2005 , publisher=
2005
-
[28]
Fréchet ChemNet Distance: A Metric for Generative Models for Molecules in Drug Discovery , journal =
Preuer, Kristina and Renz, Philipp and Unterthiner, Thomas and Hochreiter, Sepp and Klambauer, G. Fréchet ChemNet Distance: A Metric for Generative Models for Molecules in Drug Discovery , journal =
-
[29]
arXiv preprint arXiv:2211.15089 , year=
Continuous diffusion for categorical data , author=. arXiv preprint arXiv:2211.15089 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Discrete flow matching , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2310.16834 , year=
Discrete diffusion modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
-
[32]
2023 , eprint=
RoFormer: Enhanced Transformer with Rotary Position Embedding , author=. 2023 , eprint=
2023
-
[33]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2601.15165 , year=
The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models , author=. arXiv preprint arXiv:2601.15165 , year=
-
[35]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[36]
arXiv preprint arXiv:2011.13456 , year=
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
Pith/arXiv arXiv 2011
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Argmax flows and multinomial diffusion: Learning categorical distributions , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
arXiv preprint arXiv:2209.14734 , year=
Digress: Discrete denoising diffusion for graph generation , author=. arXiv preprint arXiv:2209.14734 , year=
-
[40]
arXiv preprint arXiv:2406.06449 , year=
Cometh: A continuous-time discrete-state graph diffusion model , author=. arXiv preprint arXiv:2406.06449 , year=
-
[41]
arXiv preprint arXiv:2410.04263 , year=
Defog: Discrete flow matching for graph generation , author=. arXiv preprint arXiv:2410.04263 , year=
-
[42]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[43]
arXiv preprint arXiv:2208.04202 , year=
Analog bits: Generating discrete data using diffusion models with self-conditioning , author=. arXiv preprint arXiv:2208.04202 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
Likelihood-based diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
International Conference on Machine Learning , pages=
A deep and tractable density estimator , author=. International Conference on Machine Learning , pages=. 2014 , organization=
2014
-
[47]
Advances in Neural Information Processing Systems , volume=
Training and inference on any-order autoregressive models the right way , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2502.09767 , year=
Non-markovian discrete diffusion with causal language models , author=. arXiv preprint arXiv:2502.09767 , year=
-
[49]
International Conference on Machine Learning , pages=
Dirichlet diffusion score model for biological sequence generation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[50]
Advances in Neural Information Processing Systems , volume=
A continuous time framework for discrete denoising models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2211.16750 , year=
Score-based continuous-time discrete diffusion models , author=. arXiv preprint arXiv:2211.16750 , year=
-
[52]
Advances in Neural Information Processing Systems , volume=
Discrete flows: Invertible generative models of discrete data , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
International Conference on Machine Learning , pages=
Blackout diffusion: generative diffusion models in discrete-state spaces , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[54]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[55]
2020 , eprint=
GLU Variants Improve Transformer , author=. 2020 , eprint=
2020
-
[56]
arXiv preprint arXiv:2005.13211 , year=
Insertion-based modeling for end-to-end automatic speech recognition , author=. arXiv preprint arXiv:2005.13211 , year=
arXiv 2005
-
[57]
Advances in Neural Information Processing Systems , volume=
Fisher flow matching for generative modeling over discrete data , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Insnet: An efficient, flexible, and performant insertion-based text generation model , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[60]
International Conference on Machine Learning , pages=
Bayesian inference for Plackett-Luce ranking models , author=. International Conference on Machine Learning , pages=
-
[61]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules , author=. Journal of Chemical Information and Computer Sciences , volume=. 1988 , publisher=
1988
-
[64]
arXiv preprint arXiv:2501.06158 , year=
Genmol: A drug discovery generalist with discrete diffusion , author=. arXiv preprint arXiv:2501.06158 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.