PerceptUI: LLM Agents as Human-Aligned Synthetic Users for UI/UX Evaluation
Pith reviewed 2026-06-28 01:31 UTC · model grok-4.3
The pith
PerceptUI trains LLM agents to answer UI questions as specific human personas would.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
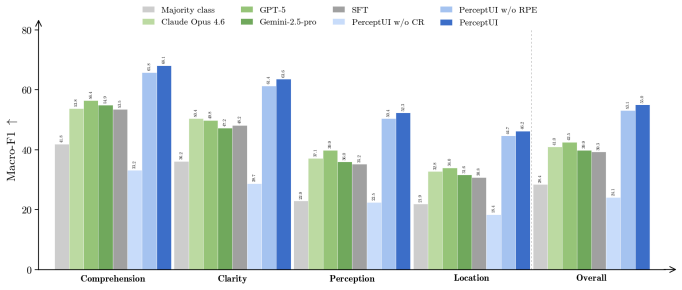
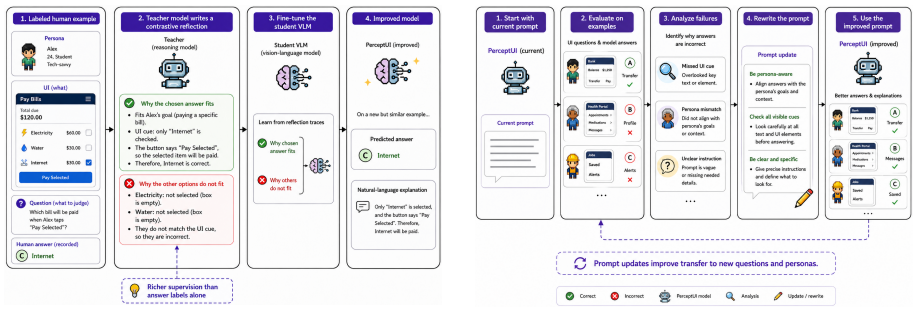
PerceptUI is a framework for persona-conditioned UI/UX evaluation that predicts how a specific user would answer interface-related questions and produces natural-language rationales. It is trained in two stages: contrastive reflection fine-tuning distills teacher-generated rationales by extracting lessons from human decisions, and a reflective prompt-evolution step uses the model's own failure traces. Across multiple domains and datasets, PerceptUI achieves human-level realism, generalizes to unseen questions and personas, and yields population-level response distributions.
What carries the argument
The two-stage training process of contrastive reflection fine-tuning on teacher-generated rationales combined with reflective prompt-evolution from failure traces.
If this is right
- Reduces the need to recruit human participants for early UI/UX iteration.
- Produces both predictions and natural-language rationales tied to specific personas.
- Generalizes to questions and personas not encountered in training.
- Generates response distributions that match those observed in human populations.
Where Pith is reading between the lines
- Could let designers test accessibility features across simulated user groups with different abilities or backgrounds.
- Might support rapid A/B testing of many interface variants before any live users see them.
- Opens the possibility of simulating how new features would land with hard-to-recruit demographics.
- Could extend beyond interfaces to evaluate other user-facing systems such as instructions or service flows.
Load-bearing premise
The fine-tuning and prompt evolution produce responses that reflect genuine user behavior rather than the model's own biases or surface patterns.
What would settle it
Compare PerceptUI response distributions and rationales for a new unseen interface against fresh human participants with the same personas, checking for statistical match on both individual answers and population aggregates.
Figures

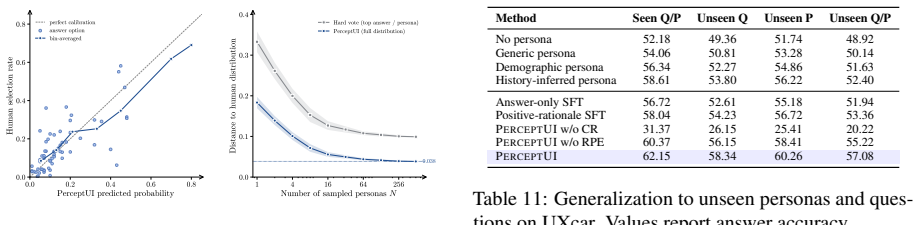
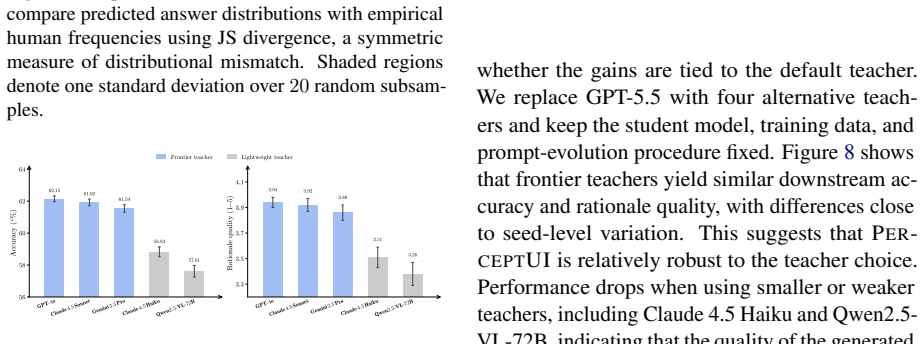

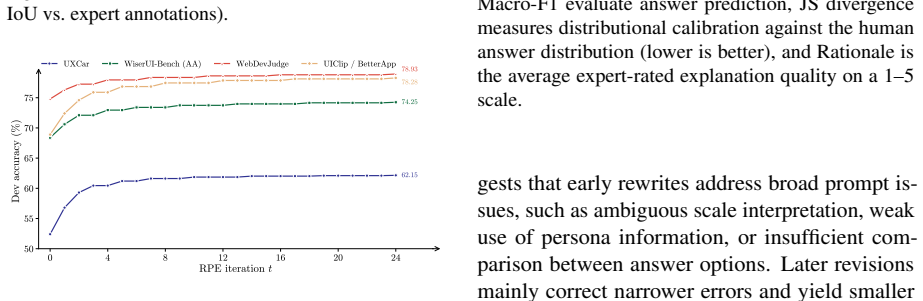
read the original abstract
User interface (UI) and user experience (UX) evaluation is central to product development, yet reliable feedback still relies on recruiting human participants or running online A/B tests, making early-stage iteration slow and costly. In light of this, recent work has explored Multimodal Large Language Models as proxy evaluators. However, existing approaches either produce surface-level critiques or a judgment that reflects the model's own biases rather than the genuine response of a particular user. We introduce PerceptUI, a framework for persona-conditioned UI/UX evaluation that predicts how a specific user would answer interface-related questions and produces natural-language rationales. PerceptUI is trained in two stages: (i) contrastive reflection fine-tuning distills teacher-generated rationales by extracting lessons from human decisions, and (ii) a reflective prompt-evolution step from the model's own failure traces. Across multiple domains and datasets, PerceptUI achieves human-level realism, generalizes to unseen questions and personas, and yields population-level response distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PerceptUI, a two-stage framework for training multimodal LLMs as persona-conditioned synthetic users for UI/UX evaluation. Stage (i) performs contrastive reflection fine-tuning to distill teacher-generated rationales extracted from human decisions; stage (ii) applies reflective prompt-evolution on the model's own failure traces. The central claim is that the resulting agents achieve human-level realism, generalize to unseen questions and personas, and reproduce population-level response distributions across multiple domains and datasets.
Significance. If the empirical claims are substantiated with rigorous controls, the work could reduce the cost and latency of early-stage UI/UX iteration by supplying scalable, persona-specific feedback that current surface-level LLM critiques do not provide. The two-stage training approach is a concrete attempt to move beyond model biases, but its value hinges on external validation against held-out human response variance.
major comments (3)
- [Abstract] Abstract: the claims of 'human-level realism,' generalization to 'unseen questions and personas,' and accurate 'population-level response distributions' are stated without any reported metrics, baselines, dataset sizes, statistical tests, or bias controls. These omissions make the central empirical contribution impossible to assess from the provided description.
- [Training stages] Training description (both stages): contrastive reflection fine-tuning and reflective prompt-evolution operate entirely on LLM-generated rationales and self-traces after the initial teacher set. No ablation comparing human vs. synthetic labels, no divergence metrics against held-out human distributions, and no external mechanism to inject genuine response variance are described, leaving open the possibility that outputs converge on base-model priors rather than human decision processes.
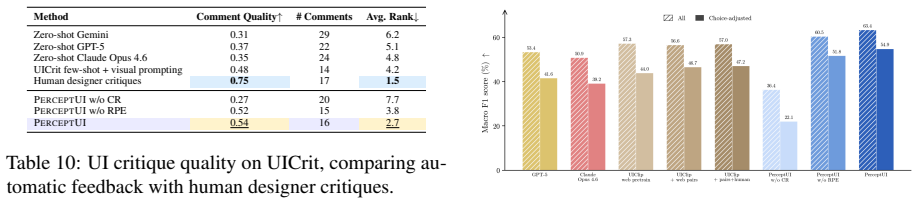
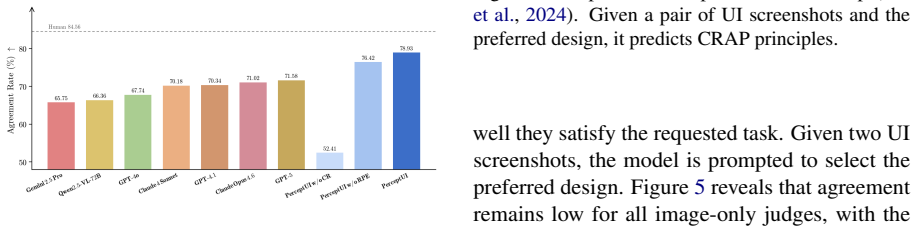
- [Evaluation] Evaluation claims: the assertion that PerceptUI 'yields population-level response distributions' requires quantitative comparison (e.g., KL divergence, calibration plots, or statistical equivalence tests) to real user data; none are referenced, undermining the generalization and realism assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the comments identify opportunities to strengthen clarity or add supporting analyses, we agree to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of 'human-level realism,' generalization to 'unseen questions and personas,' and accurate 'population-level response distributions' are stated without any reported metrics, baselines, dataset sizes, statistical tests, or bias controls. These omissions make the central empirical contribution impossible to assess from the provided description.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. The full manuscript reports these details in Sections 4.1–4.3 (dataset sizes, baselines such as standard prompting and SFT, alignment accuracies, KL divergences, and statistical tests). We will revise the abstract to include key reported figures and controls so that the central claims can be assessed directly from the abstract. revision: yes
-
Referee: [Training stages] Training description (both stages): contrastive reflection fine-tuning and reflective prompt-evolution operate entirely on LLM-generated rationales and self-traces after the initial teacher set. No ablation comparing human vs. synthetic labels, no divergence metrics against held-out human distributions, and no external mechanism to inject genuine response variance are described, leaving open the possibility that outputs converge on base-model priors rather than human decision processes.
Authors: The initial teacher rationales are extracted from human decisions (Section 2.1). The contrastive objective is explicitly constructed to pull the model toward human-derived lessons rather than base-model priors. We acknowledge, however, that the manuscript does not present an explicit human-vs-synthetic ablation or additional held-out divergence metrics. We will add these analyses in the revision to directly address the concern about convergence on model priors. revision: partial
-
Referee: [Evaluation] Evaluation claims: the assertion that PerceptUI 'yields population-level response distributions' requires quantitative comparison (e.g., KL divergence, calibration plots, or statistical equivalence tests) to real user data; none are referenced, undermining the generalization and realism assertions.
Authors: Section 4.2 and the associated figures already contain the requested quantitative comparisons (KL divergence to held-out human distributions, calibration plots, and statistical tests). These results are referenced in the evaluation narrative but were not highlighted in the abstract. We will add explicit cross-references to these quantitative results in the abstract and strengthen the discussion of generalization controls. revision: yes
Circularity Check
No circularity: training incorporates external human decisions and claims external evaluation
full rationale
The abstract describes a two-stage process: contrastive reflection fine-tuning that distills teacher-generated rationales from human decisions, followed by reflective prompt-evolution from the model's failure traces. No equations, parameter-fitting steps, or self-citations appear in the provided text that would reduce the claimed outputs (human-level realism, generalization to unseen questions/personas, population distributions) to the inputs by construction. The paper invokes external datasets for evaluation and does not rename known results or import uniqueness via author citations. The derivation chain therefore remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nicolas Bougie, Gian Maria Marconi, Xiaotong Ye, and Narimasa Watanabe
Gepa: Reflec- tive prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457. Nicolas Bougie, Gian Maria Marconi, Xiaotong Ye, and Narimasa Watanabe. 2026a. Beyond offline a/b testing: Context-aware agent simulation for recommender system evaluation.arXiv preprint arXiv:2604.09549. Nicolas Bougie, Gian Maria Marconi, Tony Yip,...
-
[2]
In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 215–229
Citysim: Modeling urban behaviors and city dynam- ics with large-scale llm-driven agent simulation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 215–229. Xiaojiao Chen, Jiahuan Zhou, Yunfeng Shu, Ruihan Wang, and Qinghua Liu
2025
-
[3]
InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–
Critiquecrew: Or- chestrating multi-perspective conversational design critique. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–
2026
-
[4]
InProceedings of the 31st International Conference on Intelligent User Interfaces, pages 646–662
Mapping the design space of user experience for computer use agents. InProceedings of the 31st International Conference on Intelligent User Interfaces, pages 646–662. Peitong Duan, Chin-Yi Cheng, Bjoern Hartmann, and Yang Li. 2024a. Visual prompting with iterative refinement for design critique generation.arXiv preprint arXiv:2412.16829. Peitong Duan, Chi...
arXiv 2024
-
[5]
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li
Persuasive technology: using com- puters to change what we think and do.Ubiquity, 2002(December):2. Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li
2002
-
[6]
arXiv preprint arXiv:2307.14984
S3: Social-network simulation sys- tem with large language model-empowered agents. arXiv preprint arXiv:2307.14984. Guilherme Guerino, Luiz Rodrigues, Bruna Capeleti, Rafael Ferreira Mello, André Freire, and Luciana Zaina
-
[7]
Uxcascade: Scalable usability testing with simulated user agents.arXiv preprint arXiv:2601.15777. Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister
-
[8]
InFindings of the Association for Computa- tional Linguistics: ACL 2023, pages 8003–8017
Dis- tilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computa- tional Linguistics: ACL 2023, pages 8003–8017. Jaehyun Jeon, Min Soo Kim, Jang Han Yoon, Sumin Shim, Yejin Choi, Hanbin Kim, Dae Hyun Kim, and Youngjae Yu
2023
-
[9]
Do mllms capture how inter- faces guide user behavior? a benchmark for multi- modal ui/ux design understanding.arXiv preprint arXiv:2505.05026. Chunyang Li, Yilun Zheng, Xinting Huang, Tianqing Fang, Jiahao Xu, Lihui Chen, Yangqiu Song, and Han Hu
-
[10]
Webdevjudge: Evaluating (m) llms as critiques for web development quality.arXiv preprint arXiv:2510.18560. Yuxuan Lu, Ting-Yao Hsu, Hansu Gu, Limeng Cui, Yaochen Xie, William Headden, Bingsheng Yao, Akash Veeragouni, Jiapeng Liu, Sreyashi Nag, and 1 others. 2025a. Agenta/b: Automated and scalable web a/btesting with interactive llm agents.arXiv preprint a...
-
[11]
Towards recommend- ing usability improvements with multimodal large language models.arXiv preprint arXiv:2508.16165. Reuben A. Luera, Ryan Rossi, Franck Dernon- court, Samyadeep Basu, Sungchul Kim, Subhojyoti Mukherjee, Puneet Mathur, Ruiyi Zhang, Jihyung Kil, Nedim Lipka, Seunghyun Yoon, Jiuxiang Gu, Zichao Wang, Cindy Xiong Bearfield, and Branislav Kveton
-
[12]
Mllm as a ui judge: Benchmarking 8 multimodal llms for predicting human perception of user interfaces.Preprint, arXiv:2510.08783. Tim Miller
-
[13]
InProceedings of the SIGCHI conference on human factors in com- puting systems, pages 2049–2058
Predicting users’ first impressions of website aesthetics with a quantification of perceived visual complexity and colorfulness. InProceedings of the SIGCHI conference on human factors in com- puting systems, pages 2049–2058. Tim Rieder, Marian Schneider, Mario Truss, Vitaly Tsaplin, Alina Rublea, Sinem Dere, Francisco Chicharro Sanz, Tobias Reiss, and Mu...
2049
-
[14]
Maryam Taeb, Amanda Swearngin, Eldon Schoop, Rui- jia Cheng, Yue Jiang, and Jeffrey Nichols
Simab: Simulating a/b tests with persona-conditioned ai agents for rapid design evaluation.arXiv preprint arXiv:2603.01024. Maryam Taeb, Amanda Swearngin, Eldon Schoop, Rui- jia Cheng, Yue Jiang, and Jeffrey Nichols
-
[15]
InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–
Ax- nav: Replaying accessibility tests from natural lan- guage. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–
2024
-
[16]
Opera: A dataset of observation, persona, rationale, and action for evaluating llms on human online shopping behav- ior simulation.arXiv preprint arXiv:2506.05606. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others
-
[17]
InProceedings of the 2026 CHI Conference on Human Factors in Computing Sys- tems, pages 1–17
Improving user interface generation models from de- signer feedback. InProceedings of the 2026 CHI Conference on Human Factors in Computing Sys- tems, pages 1–17. Wei Xiang, Hanfei Zhu, Suqi Lou, Xinli Chen, Zhenghua Pan, Yuping Jin, Shi Chen, and Lingyun Sun
2026
-
[18]
InProceedings of the 2024 CHI Con- ference on Human Factors in Computing Systems, pages 1–17
Simuser: Generating usability feedback by simulating various users interacting with mobile applications. InProceedings of the 2024 CHI Con- ference on Human Factors in Computing Systems, pages 1–17. Naimeng Ye, Xiao Yu, Ruize Xu, Tianyi Peng, and Zhou Yu
2024
-
[19]
An Zhang, Leheng Sheng, Yuxin Chen, Hao Li, Yang Deng, Xiang Wang, and Tat-Seng Chua
Ai agents for web testing: A case study in the wild.arXiv preprint arXiv:2509.05197. An Zhang, Leheng Sheng, Yuxin Chen, Hao Li, Yang Deng, Xiang Wang, and Tat-Seng Chua
-
[20]
Qingxiao Zheng, Minrui Chen, Pranav Sharma, Yiliu Tang, Mehul Oswal, Yiren Liu, and Yun Huang
On generative agents in recommendation.arXiv preprint arXiv:2310.10108. Qingxiao Zheng, Minrui Chen, Pranav Sharma, Yiliu Tang, Mehul Oswal, Yiren Liu, and Yun Huang
-
[21]
InProceedings of the 2025 CHI Conference on Human Factors in Comput- ing Systems, pages 1–25
Evalignux: Advancing ux evaluation through llm- supported metrics exploration. InProceedings of the 2025 CHI Conference on Human Factors in Comput- ing Systems, pages 1–25. Ruican Zhong, David W McDonald, and Gary Hsieh. 2025a. Synthetic cognitive walkthrough: Aligning large language model performance with human cogni- tive walkthrough.arXiv preprint arXi...
arXiv 2025
-
[22]
Likert-Scale Answer Simulation Prompt Simulate how the described participant would answer a Likert-scale UI/UX question
Likert-scale questions. Likert-Scale Answer Simulation Prompt Simulate how the described participant would answer a Likert-scale UI/UX question. Use the provided scale anchors exactly, and select the rating that best reflects the participant’s likely response to the UI. UI image:ui_image Reference image (optional):refer- ence_image 13 Persona:persona_desc...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.