Smoothed-KL Reweighting: A Principled Account and Matching Rule for SNR-Based Diffusion Training
Pith reviewed 2026-06-27 05:52 UTC · model grok-4.3
The pith
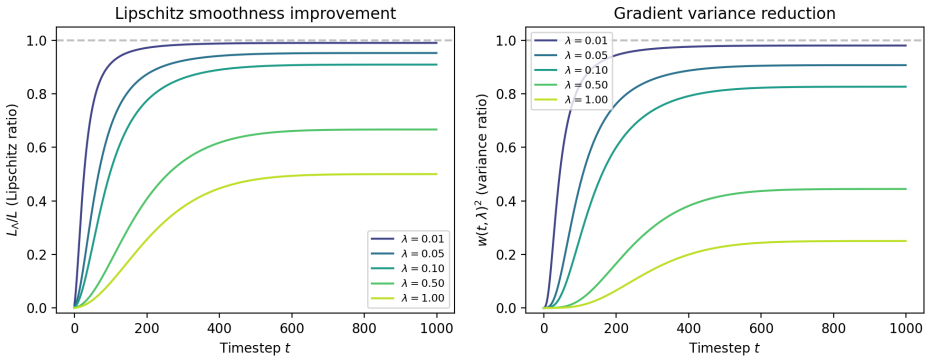
Spread divergence on per-sample Gaussian surrogates yields closed-form Soft-Min-SNR weight w(t,lambda) = sigma^2 / (sigma^2 + lambda).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The spread divergence of Zhang et al. (2018) convolves both compared distributions with a Gaussian kernel before taking the KL divergence; applied to the per-sample local matched-Gaussian surrogate at each timestep, it yields the closed-form weight w(t,lambda) = sigma^2 / (sigma^2 + lambda). For variance-preserving schedules, w(t,lambda) equals a constant multiple of Soft-Min-SNR with gamma' = (1+lambda)/lambda. The same weight matches Min-SNR-gamma at leading order under gamma approximately 1/lambda. A local-geometry analysis scales an SGD-difficulty proxy by w^3 at high-SNR timesteps.
What carries the argument
Spread divergence applied to per-sample local matched-Gaussian surrogates, which smooths both model output and target before KL computation and produces the closed-form weight.
If this is right
- For variance-preserving schedules the weight recovers Soft-Min-SNR as a constant multiple with gamma' = (1+lambda)/lambda.
- The weight matches Min-SNR-gamma at leading order when gamma is set near 1/lambda, supplying a cross-walk between soft and hard families.
- Local geometry predicts that the weight scales an SGD-difficulty proxy by w cubed at high-SNR timesteps.
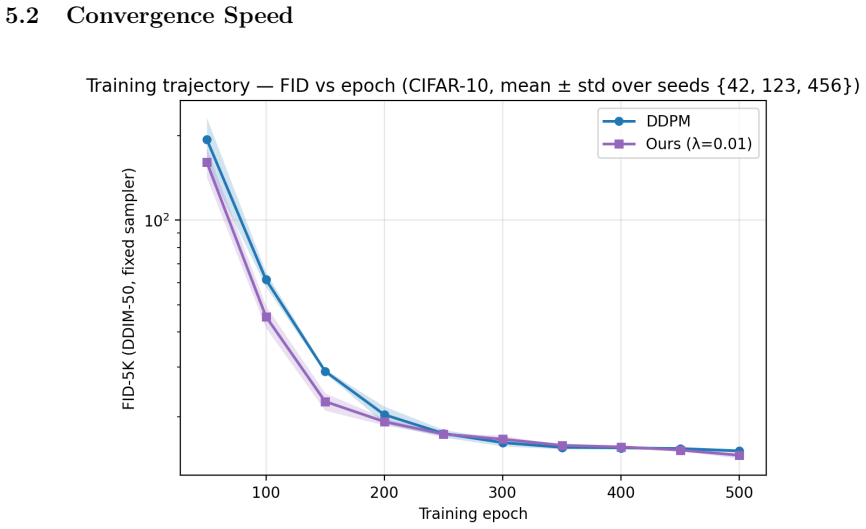
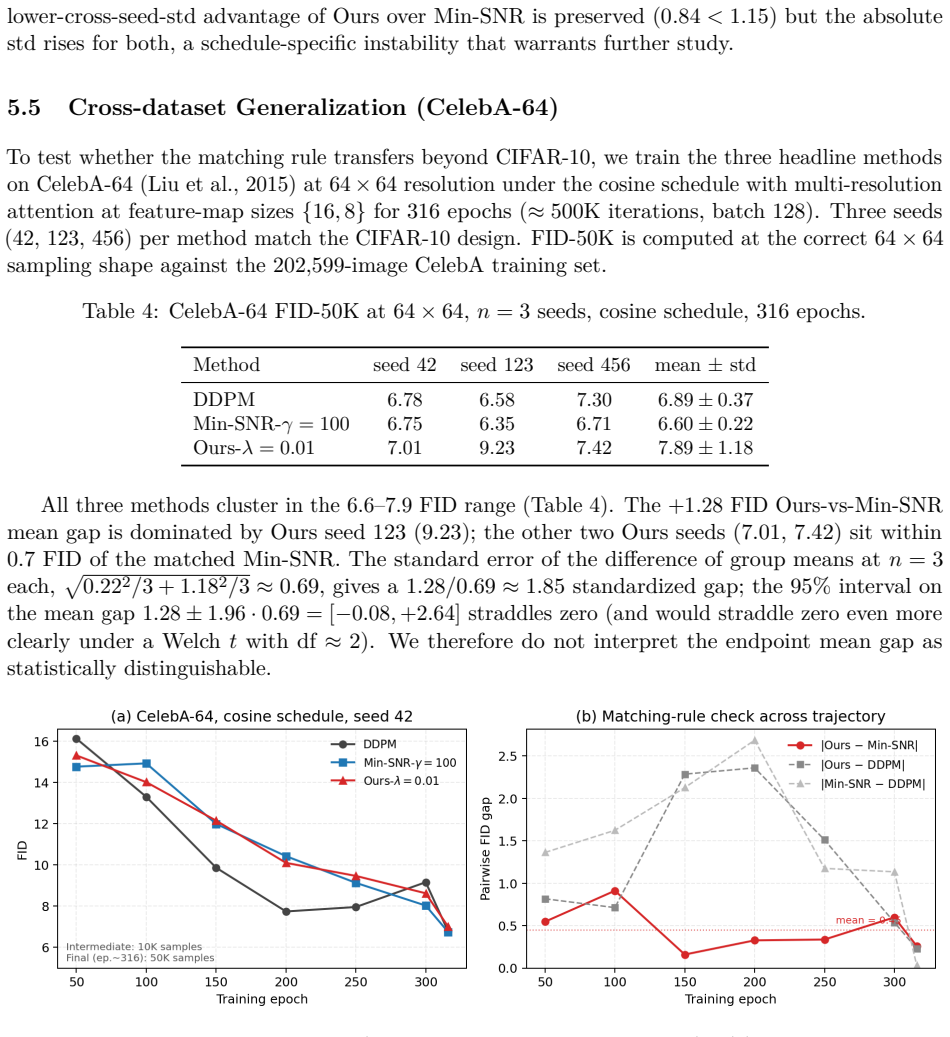
- Empirically the matching rule holds on CIFAR-10 linear and cosine schedules and CelebA-64 cosine, with average FID gap of 0.45 to Min-SNR.
Where Pith is reading between the lines
- The account smooths both sides of the divergence rather than only the data side, distinguishing it from noise-augmentation ELBO derivations.
- Iteration-efficiency gains appear schedule- and dataset-dependent, largest when high-SNR damping has the most headroom.
- The explicit matching rule between families could support hybrid reweighting that switches based on training phase without retraining.
Load-bearing premise
The per-sample local matched-Gaussian surrogate is a sufficiently accurate stand-in for the true model-target comparison when spread divergence is applied at each timestep.
What would settle it
If the average absolute FID difference between the derived weights and Min-SNR across seven intermediate checkpoints on a new dataset trajectory exceeds 1.0, the claimed matching rule would be falsified.
Figures


read the original abstract
We give a principled derivation of the Soft-Min-SNR weight of Crowson et al. (2024). The spread divergence of Zhang et al. (2018) convolves both compared distributions with a Gaussian kernel before taking the Kullback-Leibler (KL) divergence; applied to the per-sample local matched-Gaussian surrogate at each timestep, it yields the closed-form weight w(t,lambda) = sigma^2 / (sigma^2 + lambda). Three consequences follow. First, for variance-preserving schedules, w(t,lambda) equals a constant multiple of Soft-Min-SNR with gamma' = (1+lambda)/lambda, deriving a validated heuristic rather than introducing a new weight. Second, the same weight matches Min-SNR-gamma at leading order under gamma approximately 1/lambda, giving a cross-walk between the soft and hard reweighting families. Third, a local-geometry analysis scales an SGD-difficulty proxy by w^3 at high-SNR timesteps. Complementary to the objective-level account of Kingma & Gao (2023), who unified monotonic-in-log-SNR weightings as ELBOs of noise-augmented data, ours smooths both compared distributions rather than only the data side. Empirically, the matching rule holds on CIFAR-10 (linear and cosine) and CelebA-64 (cosine), with trajectory-wide confirmation on the cross-dataset cut: |Ours - Min-SNR| averages 0.45 FID across seven intermediate checkpoints on the seed-42 CelebA-64 trajectory, roughly 3x tighter than either reweighter's gap to DDPM. The local-geometry prediction is partially borne out: Ours converges about 21% earlier than DDPM at mid-training FID thresholds on CIFAR-10's linear schedule, where high-SNR damping headroom is largest, but this iteration-efficiency advantage does not transfer to cosine or CelebA-64, where all three methods reach similar final FIDs. Overall: final-FID parity with dataset-dependent iteration efficiency, plus a principled matching rule across the Min-SNR family.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a principled derivation of the Soft-Min-SNR weighting via the spread divergence (convolution with Gaussian kernel of variance λ followed by KL) applied to the per-sample local matched-Gaussian surrogate at each timestep, producing the closed-form w(t,λ) = σ²/(σ² + λ). From this it derives matching rules equating the weight (up to constant) to Soft-Min-SNR with γ' = (1+λ)/λ for variance-preserving schedules and to Min-SNR-γ at leading order for γ ≈ 1/λ; it also presents a local-geometry SGD-difficulty scaling by w³ at high-SNR timesteps. Complementary to Kingma & Gao (2023), the account smooths both distributions. Empirical results on CIFAR-10 (linear/cosine) and CelebA-64 (cosine) show final-FID parity, a trajectory-wide |Ours - Min-SNR| gap averaging 0.45 FID (3× tighter than gaps to DDPM), and partial iteration-efficiency gains (21% earlier convergence on CIFAR-10 linear at mid-training thresholds) that do not transfer to other schedules/datasets.
Significance. If the surrogate step is justified, the work supplies an explicit cross-walk between soft and hard SNR reweighting families, deriving validated heuristics from a single smoothing principle rather than ad-hoc fitting. The explicit parameter mapping and multi-dataset trajectory checks add concrete value; the local-geometry prediction, while only partially confirmed, offers a falsifiable link between weighting and optimization difficulty.
major comments (2)
- [Abstract (derivation paragraph) and the section presenting the closed-form weight] The central derivation applies spread divergence exclusively to the per-sample local matched-Gaussian surrogate rather than the true model-output and target distributions, yielding w(t,λ) = σ²/(σ² + λ) with no accompanying error bound, concentration inequality, or high-dimensional approximation guarantee. This surrogate step is load-bearing for the closed-form claim and the subsequent matching rules.
- [Empirical results paragraph] The empirical validation reports a trajectory-wide average FID gap of 0.45 between Ours and Min-SNR (roughly 3× tighter than either to DDPM) across seven checkpoints on seed-42 CelebA-64, but provides no per-run variance, number of seeds, or statistical test; without this the claim that the matching rule is confirmed at the trajectory level cannot be assessed for robustness.
minor comments (2)
- [Local-geometry analysis] The local-geometry analysis that scales an SGD-difficulty proxy by w³ at high-SNR timesteps is stated without the explicit proxy definition or derivation steps; adding these would clarify the prediction.
- [Matching-rules paragraphs] Notation for the spread-divergence parameter (λ) and the resulting γ, γ' should be cross-referenced explicitly to the Soft-Min-SNR and Min-SNR-γ definitions to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, proposing clarifications and additions where the concerns are valid.
read point-by-point responses
-
Referee: The central derivation applies spread divergence exclusively to the per-sample local matched-Gaussian surrogate rather than the true model-output and target distributions, yielding w(t,λ) = σ²/(σ² + λ) with no accompanying error bound, concentration inequality, or high-dimensional approximation guarantee. This surrogate step is load-bearing for the closed-form claim and the subsequent matching rules.
Authors: The manuscript explicitly frames the derivation as operating on the per-sample local matched-Gaussian surrogate, which is a deliberate modeling choice that yields the exact closed-form weight under the spread divergence. This surrogate is standard in diffusion analyses for capturing local per-timestep behavior (e.g., in score-matching and SNR studies) and enables tractability; direct application to the true high-dimensional distributions does not produce a closed form. We do not claim exact equivalence to the true distributions. We agree that the absence of error bounds or approximation guarantees is a limitation and will add a dedicated paragraph discussing the surrogate rationale, its relation to prior local approximations, and the lack of concentration results as an open direction. revision: partial
-
Referee: The empirical validation reports a trajectory-wide average FID gap of 0.45 between Ours and Min-SNR (roughly 3× tighter than either to DDPM) across seven checkpoints on seed-42 CelebA-64, but provides no per-run variance, number of seeds, or statistical test; without this the claim that the matching rule is confirmed at the trajectory level cannot be assessed for robustness.
Authors: The reported 0.45 FID gap and 3× tightness are computed on a single seed-42 trajectory for CelebA-64 (as is common for compute-intensive diffusion runs). The language of “confirmation” and “trajectory-wide” is descriptive of the observed values on this run rather than a statistical claim. We will revise the empirical section to explicitly state that the numbers come from a single trajectory, qualify the gap as an observed difference, and note the absence of multi-seed variance or formal tests as a limitation. Additional seeds are not currently available but the text will be updated accordingly. revision: partial
Circularity Check
Derivation applies external spread divergence to surrogate without reduction to inputs by construction
full rationale
The paper's central step applies the spread divergence (Zhang et al. 2018) to an explicitly chosen per-sample local matched-Gaussian surrogate, yielding the closed-form w(t,lambda) = sigma^2 / (sigma^2 + lambda) as a direct algebraic consequence. Subsequent matching rules to Soft-Min-SNR and Min-SNR-gamma are obtained by algebraic comparison under variance-preserving schedules rather than by fitting parameters or self-definition. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present; the account remains an external reinterpretation of existing weights and is self-contained against the cited external divergence measure.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (1)
- domain assumption Spread divergence is obtained by convolving both distributions with a Gaussian kernel before computing KL divergence (Zhang et al. 2018)
Reference graph
Works this paper leans on
-
[1]
(2016).Information Geometry and Its Applications
Amari, S.-I. (2016).Information Geometry and Its Applications. Springer
2016
-
[2]
Chazal, C., Korba, A., & Bach, F. (2024). Statistical and geometrical properties of regularized Kernel Kullback-Leibler divergence. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[3]
Choi, J., Lee, J., Shin, C., Kim, S., Kim, H., & Yoon, S. (2022). Perception prioritized training of diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2022
-
[4]
A., Birch, A., Abraham, T
Crowson, K., Baumann, S. A., Birch, A., Abraham, T. M., Kaplan, D. Z., & Shippole, E. (2024). Scalable high-resolution pixel-space image synthesis with Hourglass Diffusion Transformers. In International Conference on Machine Learning (ICML), PMLR 235:9550–9575
2024
-
[5]
Efron, B. (2011). Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496), 1602–1614
2011
-
[6]
Gabriel, F., Ged, F., Han Veiga, M., & Schertzer, E. (2025). Kernel-smoothed scores for denoising diffusion: A bias-variance study.arXiv preprint arXiv:2505.22841
arXiv 2025
-
[7]
Hang, T., Gu, S., Li, C., Bao, J., Chen, D., Hu, H., Geng, X., & Guo, B. (2023). Efficient diffusion training via Min-SNR weighting strategy. InIEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[8]
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS)
2020
-
[9]
Karras, T., Aittala, M., Aila, T., & Laine, S. (2022). Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[10]
P., Salimans, T., Poole, B., & Ho, J
Kingma, D. P., Salimans, T., Poole, B., & Ho, J. (2021). Variational diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS)
2021
-
[11]
P., & Gao, R
Kingma, D. P., & Gao, R. (2023). Understanding diffusion objectives as the ELBO with simple data augmentation. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[12]
Krizhevsky, A. (2009). Learning multiple layers of features from tiny images. Technical report, University of Toronto
2009
-
[13]
Leinster, T., & Cobbold, C. A. (2012). Measuring diversity: The importance of species similarity. Ecology, 93(3), 477–489
2012
-
[14]
Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023). Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR)
2023
-
[15]
Liu, Z., Luo, P., Wang, X., & Tang, X. (2015). Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 18
2015
-
[16]
Q., & Dhariwal, P
Nichol, A. Q., & Dhariwal, P. (2021). Improved denoising diffusion probabilistic models. In International Conference on Machine Learning (ICML)
2021
-
[17]
Rao, C. R. (1982). Diversity and dissimilarity coefficients: A unified approach.Theoretical Population Biology, 21(1), 24–43
1982
-
[18]
Robbins, H. (1956). An empirical Bayes approach to statistics. InProceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1, 157–163. University of California Press
1956
-
[19]
Sahasrabuddhe, R., & Lambiotte, R. (2026). Structure-aware divergences for comparing probability distributions.arXiv preprint arXiv:2603.22237
arXiv 2026
-
[20]
Shi, J., & Titsias, M. K. (2025). Demystifying diffusion objectives: Reweighted losses are better variational bounds.arXiv preprint arXiv:2511.19664
arXiv 2025
-
[21]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning (ICML)
2015
-
[22]
P., Kumar, A., Ermon, S., & Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR)
2021
-
[23]
Song, J., Meng, C., & Ermon, S. (2021). Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR)
2021
-
[24]
Turan, E., Dufour, N., & Ovsjanikov, M. (2026). Generative drifting is secretly score matching: A spectral and variational perspective.arXiv preprint arXiv:2603.09936
Pith/arXiv arXiv 2026
-
[25]
Vincent, P. (2011). A connection between score matching and denoising autoencoders.Neural Computation, 23(7), 1661–1674
2011
-
[26]
Zhang, M., Grosse-Wentrup, M., & Barber, D. (2018). Spread divergence.arXiv preprint arXiv:1811.08968. 19 A Proofs and Derivations A.1 Propositions 3.1 and 3.2: KL Contraction and Recovery For Proposition 3.1,KΛ is a Markov kernel, so the data-processing inequality for KL gives KL(KΛq∥KΛp)≤KL(q∥p). Equality atΛ = 0follows becauseK 0 is the identity kernel...
arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.