SelPE: Progressive Selection for Private Structured Text Synthesis
Pith reviewed 2026-06-26 08:20 UTC · model grok-4.3
The pith
SelPE concentrates the privacy budget on progressive top-1 selections to synthesize valid structured text under differential privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
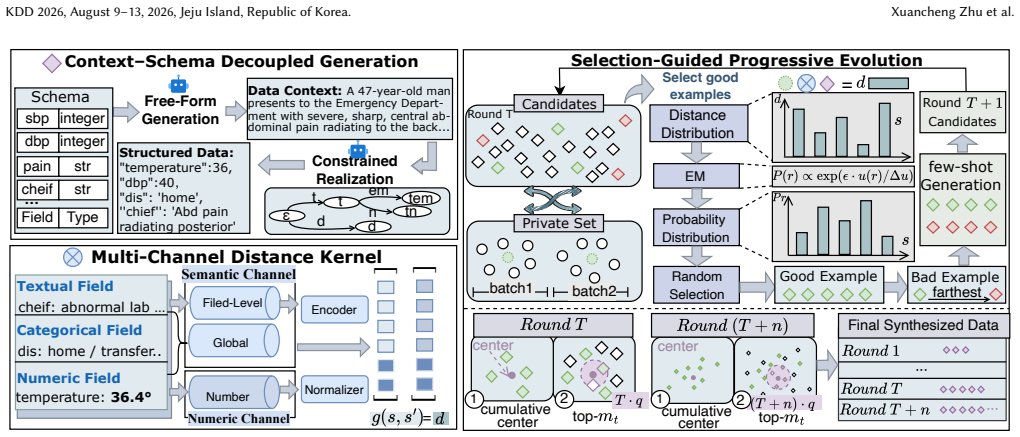
SelPE is a selection-guided progressive evolution framework for small-sample private structured text synthesis that concentrates privacy budget on multi-batch top-1 selections, decouples semantic abstraction from schema realization via two-stage generation, and evaluates candidates with a multi-channel distance kernel, thereby improving structural validity, fidelity, and downstream utility under strict differential privacy budgets.
What carries the argument
The progressive selection mechanism that allocates the privacy budget across a sequence of multi-batch top-1 selections to provide guidance for the synthesis process.
Load-bearing premise
Concentrating the privacy budget on a sequence of multi-batch top-1 selections provides efficient and faithful guidance for synthesis without violating differential privacy guarantees or degrading candidate quality.
What would settle it
An experiment on the same benchmarks where SelPE produces no statistically significant improvement in structural validity or downstream task performance over prior differential privacy synthesis methods at identical privacy budgets would falsify the central claim.
Figures


read the original abstract
Many data-driven applications rely on structured textual records, such as clinical triage notes and financial transaction logs, for downstream learning and decision-making. In privacy-sensitive domains, access to such records is strictly regulated, often resulting in only a small number of available private examples for model development and analysis. Yet existing differential privacy data synthesis methods fall short: tabular techniques cannot faithfully model free-form text, while text-based approaches often break structural constraints. We propose SelPE, a selection-guided progressive evolution framework for small-sample private structured text synthesis. Rather than relying on noisy aggregation or private model training, SelPE concentrates privacy budget on a sequence of multi-batch top-1 selections, enabling efficient guidance under tight privacy constraints. To support faithful and valid synthesis, SelPE decouples semantic abstraction from schema realization via a two-stage generation pipeline, and evaluates candidates using a multi-channel distance kernel that jointly models textual, categorical, and numeric fields in their native representations. A non-private contrastive expansion mechanism further promotes diversity without incurring additional privacy cost. Extensive Experiments demonstrate that SelPE consistently improves structural validity, fidelity, and downstream utility under strict differential privacy budgets, particularly in low-data regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SelPE, a selection-guided progressive evolution framework for synthesizing structured textual records (e.g., clinical notes, transaction logs) under differential privacy when only small private samples are available. It concentrates the privacy budget on a sequence of multi-batch top-1 selections rather than noisy aggregation or private model training, decouples semantic abstraction from schema realization via a two-stage generation pipeline, evaluates candidates with a multi-channel distance kernel operating on native textual/categorical/numeric representations, and applies non-private contrastive expansion to promote diversity. The central claim is that SelPE improves structural validity, fidelity, and downstream utility relative to prior DP synthesis methods, especially under tight privacy budgets and in low-data regimes.
Significance. If the privacy accounting, candidate evaluation kernel, and experimental results hold under scrutiny, the work addresses a practical gap between tabular DP synthesizers (which ignore free-form text) and text DP methods (which often violate structural constraints). The design choice to spend privacy budget only on selections while keeping contrastive expansion non-private is a potentially efficient allocation that could be useful in regulated domains with scarce data.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): the claim of consistent improvements in structural validity, fidelity, and downstream utility is stated without any reported metrics, baselines, dataset sizes, privacy budgets (ε, δ), or error bars. This makes it impossible to assess whether the gains are statistically meaningful or merely artifacts of the chosen evaluation protocol.
- [§3] §3 (Method): the privacy analysis of the multi-batch top-1 selection sequence is described at a high level but lacks explicit composition theorems, sensitivity bounds for the distance kernel, or the exact privacy accounting used to allocate the concentrated budget. Without these, it is not possible to verify that the mechanism satisfies the stated DP guarantees while still producing high-quality candidates.
minor comments (2)
- [§3] Notation for the multi-channel distance kernel and the two-stage pipeline should be formalized with equations rather than prose descriptions to allow reproducibility.
- [§4] The manuscript should include a table comparing SelPE against at least three representative baselines (tabular DP, text DP, and non-private) on the same datasets and privacy budgets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the claim of consistent improvements in structural validity, fidelity, and downstream utility is stated without any reported metrics, baselines, dataset sizes, privacy budgets (ε, δ), or error bars. This makes it impossible to assess whether the gains are statistically meaningful or merely artifacts of the chosen evaluation protocol.
Authors: We agree that the abstract presents a high-level summary of the results. The experiments in §4 contain the requested details on metrics, baselines, dataset sizes, privacy budgets, and error bars across runs. To address the concern directly, we will revise the abstract to include key quantitative results and ensure §4 makes these elements more prominent for statistical evaluation. revision: yes
-
Referee: [§3] §3 (Method): the privacy analysis of the multi-batch top-1 selection sequence is described at a high level but lacks explicit composition theorems, sensitivity bounds for the distance kernel, or the exact privacy accounting used to allocate the concentrated budget. Without these, it is not possible to verify that the mechanism satisfies the stated DP guarantees while still producing high-quality candidates.
Authors: We agree that explicit details are needed for verification. Section §3 provides a high-level description of the selection process and budget concentration. In revision we will expand this section to include the specific composition theorems, sensitivity bounds for the multi-channel kernel, and the precise accounting for budget allocation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and high-level description present SelPE as an empirical framework relying on multi-batch selection, two-stage generation, and experimental validation under differential privacy. No equations, fitted parameters presented as predictions, self-citations as load-bearing premises, or ansatzes are supplied in the text. The central claims rest on downstream utility measurements rather than any derivation that reduces to its own inputs by construction. This is the expected self-contained case for a methods paper whose contributions are algorithmic and empirical.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. 308–318
2016
-
[2]
Gergely Acs, Luca Melis, Claude Castelluccia, and Emiliano De Cristofaro. 2018. Differentially private mixture of generative neural networks.IEEE Transactions on Knowledge and Data Engineering31, 6 (2018), 1109–1121
2018
-
[3]
Alan Arazi, Eilam Shapira, and Roi Reichart. 2025. TabSTAR: A Tabular Foun- dation Model for Tabular Data with Text Fields. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[4]
Hassan Jameel Asghar, Ming Ding, Thierry Rakotoarivelo, Sirine Mrabet, and Dali Kaafar. 2020. Differentially private release of datasets using Gaussian copula. Journal of Privacy and Confidentiality10, 2 (2020)
2020
-
[5]
Debangshu Banerjee, Tarun Suresh, Shubham Ugare, Sasa Misailovic, and Gagan- deep Singh. 2025. CRANE: Reasoning with constrained LLM generation. In Forty-second International Conference on Machine Learning
2025
-
[6]
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawel- czyk, and Gjergji Kasneci. 2022. Deep neural networks and tabular data: A survey. IEEE transactions on neural networks and learning systems35, 6 (2022), 7499–7519
2022
-
[7]
Qingrong Chen, Chong Xiang, Minhui Xue, Bo Li, Nikita Borisov, Dali Kaarfar, and Haojin Zhu. 2018. Differentially private data generative models.arXiv preprint arXiv:1812.02274(2018)
Pith/arXiv arXiv 2018
-
[8]
Graham Cormode, Samuel Maddock, Enayat Ullah, and Shripad Gade. 2025. Synthetic Tabular Data: Methods, Attacks and Defenses. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 5989–5998. doi:10.1145/3711896.3736562
-
[9]
Jinshuo Dong, David Durfee, and Ryan Rogers. 2020. Optimal differential privacy composition for exponential mechanisms. InInternational Conference on Machine Learning. PMLR, 2597–2606
2020
-
[10]
Enjun Du, Xunkai Li, Tian Jin, Zhihan Zhang, Rong-Hua Li, and Guoren Wang
-
[11]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
GraphMaster: Automated Graph Synthesis via LLM Agents in Data-Limited Environments. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=h3dbocj7po
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[13]
David Durfee and Ryan Rogers. 2021. One-shot DP Top-k mechanisms. Differen- tialPrivacy.org. https://differentialprivacy.org/one-shot-top-k/
2021
-
[14]
Cynthia Dwork, Krishnaram Kenthapadi, Frank McSherry, Ilya Mironov, and Moni Naor. 2006. Our data, ourselves: Privacy via distributed noise generation. InAnnual international conference on the theory and applications of cryptographic techniques. Springer, 486–503
2006
-
[15]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Cali- brating noise to sensitivity in private data analysis. InTheory of cryptography conference. Springer, 265–284
2006
-
[16]
Cynthia Dwork and Aaron Roth. 2014. The algorithmic foundations of differential privacy.Foundations and trends®in theoretical computer science9, 3-4 (2014), 211–487
2014
-
[17]
Muhammad Hasan Ferdous, Emam Hossain, and Md Osman Gani. 2025. Time- Graph: Synthetic Benchmark Datasets for Robust Time-Series Causal Discovery. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 5425–5435. doi:10.1145/3711896.3737439
-
[18]
Lorenzo Frigerio, Anderson Santana de Oliveira, Laurent Gomez, and Patrick Duverger. 2019. Differentially private generative adversarial networks for time series, continuous, and discrete open data. InIFIP International Conference on ICT Systems Security and Privacy Protection. Springer, 151–164
2019
-
[19]
Yuqian Fu, Yuanheng Zhu, Jian Zhao, Jiajun Chai, and Dongbin Zhao. 2025. INS: Interaction-aware Synthesis to Enhance Offline Multi-agent Reinforcement Learning. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=kxD2LlPr40
2025
-
[20]
Zeyu Gan and Yong Liu. 2025. Towards a Theoretical Understanding of Synthetic Data in LLM Post-Training: A Reverse-Bottleneck Perspective. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=UxkznlcnHf
2025
-
[21]
Fengyu Gao, Ruida Zhou, Tianhao Wang, Cong Shen, and Jing Yang. 2025. Data- adaptive Differentially Private Prompt Synthesis for In-Context Learning. In The Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=sVNfWhtaJC
2025
-
[22]
Quan Geng and Pramod Viswanath. 2015. The optimal noise-adding mechanism in differential privacy.IEEE Transactions on Information Theory62, 2 (2015), 925–951
2015
-
[23]
Saibo Geng, Hudson Cooper, Michal Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, and Harsha Nori. 2025. JSON- SchemaBench: Evaluating Constrained Decoding with LLMs on Efficiency, Cov- erage and Quality. InES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models. https://openreview.net/forum?id=FKOaJqKoio
2025
-
[24]
Emmanuel Anaya Gonzalez, Sairam Vaidya, Kanghee Park, Ruyi Ji, Taylor Berg- Kirkpatrick, and Loris D’Antoni. 2025. Constrained Sampling for Language Models Should Be Easy: An MCMC Perspective.arXiv preprint arXiv:2506.05754 (2025)
arXiv 2025
-
[25]
Tomás González, Giulia Fanti, and Aaditya Ramdas. 2025. Private Evolution Converges.arXiv preprint arXiv:2506.08312(2025)
arXiv 2025
-
[26]
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. 2021. Revisiting deep learning models for tabular data.Advances in neural information processing systems34 (2021), 18932–18943
2021
-
[27]
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos. 2020. TaPas: Weakly Supervised Table Parsing via Pre-training. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Lin...
-
[28]
Yuzheng Hu, Fan Wu, Qinbin Li, Yunhui Long, Gonzalo Munilla Garrido, Chang Ge, Bolin Ding, David Forsyth, Bo Li, and Dawn Song. 2024. Sok: Privacy- preserving data synthesis. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 4696–4713
2024
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
Pith/arXiv arXiv 2023
-
[30]
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Leo Anthony Celi, Roger Mark, and Steven Horng. 2023. MIMIC-IV-ED.PhysioNet(Jan. 2023). doi:10.13026/5ntk- km72 Version 2.2
-
[31]
Peter Kairouz, Sewoong Oh, and Pramod Viswanath. 2015. The Composi- tion Theorem for Differential Privacy. InProceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 37), Francis Bach and David Blei (Eds.). PMLR, Lille, France, 1376–1385. https://proceedings.mlr.press/v37/kairouz15.html
2015
-
[32]
Haoran Li, Li Xiong, and Xiaoqian Jiang. 2014. Differentially private synthesiza- tion of multi-dimensional data using copula functions. InAdvances in database technology: proceedings. International conference on extending database technology, Vol. 2014. 475
2014
-
[33]
Qintong Li, Jiahui Gao, Sheng Wang, Renjie Pi, Xueliang Zhao, Chuan Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. Forewarned is Forearmed: Harness- ing LLMs for Data Synthesis via Failure-induced Exploration. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=yitH9xAHQs
2025
-
[34]
Xuechen Li, Florian Tramer, Percy Liang, and Tatsunori Hashimoto. 2022. Large Language Models Can Be Strong Differentially Private Learners. InInternational Conference on Learning Representations
2022
-
[35]
Junyong Lin, Lu Dai, Ruiqian Han, Yijie Sui, Ruilin Wang, Xingliang Sun, Qinglin Wu, Min Feng, Hao Liu, and Hui Xiong. 2025. ScIRGen: Synthesize Realistic and Large-Scale RAG Dataset for Scientific Research. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Ma...
-
[36]
Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, Harsha Nori, and Sergey Yekhanin. 2024. Differentially Private Synthetic Data via Foundation Model APIs 1: Images. InThe Twelfth International Conference on Learning Representa- tions
2024
-
[37]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
Pith/arXiv arXiv 2019
-
[38]
Yaxi Lu, Haolun Li, Xin Cong, Zhong Zhang, Yesai Wu, Yankai Lin, Zhiyuan Liu, Fangming Liu, and Maosong Sun. 2025. Learning to Generate Structured Output with Schema Reinforcement Learning.arXiv preprint arXiv:2502.18878(2025)
arXiv 2025
-
[39]
Xuebin Ma, Xuejian Qi, Yulei Meng, and Tao Yang. 2023. Improved Bayesian network differential privacy data-releasing method based on junction tree. In2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 759–764
2023
-
[40]
Frank McSherry and Kunal Talwar. 2007. Mechanism design via differential privacy. In48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07). IEEE, 94–103
2007
-
[41]
Michał Moskal, Harsha Nori, Hudson Cooper, and Loc Huynh. 2025. LLGuidance: Making Structured Outputs Go Brrrr. https://guidance-ai.github.io/llguidance/llg- go-brrr. blog, Guidance-AI. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Xuancheng Zhu et al
2025
-
[42]
OpenAI. 2024. GPT-4o Mini: Efficient Multimodal Language Model. https: //platform.openai.com/docs/models. Model used: gpt-4o-mini
2024
-
[43]
Clément Pierquin, Aurélien Bellet, Marc Tommasi, and Matthieu Boussard. 2025. Privacy Amplification Through Synthetic Data: Insights from Linear Regression. InForty-second International Conference on Machine Learning. https://openreview. net/forum?id=TOn1rhgdeD
2025
-
[44]
Ulyana Piterbarg, Lerrel Pinto, and Rob Fergus. 2025. Training Language Models on Synthetic Edit Sequences Improves Code Synthesis. InThe Thirteenth Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= AqfUa08PCH
2025
-
[45]
Gang Qiao, Weijie Su, and Li Zhang. 2021. Oneshot differentially private top-k selection. InInternational Conference on Machine Learning. PMLR, 8672–8681
2021
-
[46]
Chuan Qin, Xin Chen, Chengrui Wang, Pengmin Wu, Xi Chen, Yihang Cheng, Jingyi Zhao, Meng Xiao, Xiangchao Dong, Qingqing Long, Boya Pan, Han Wu, Chengzan Li, Yuanchun Zhou, Hui Xiong, and Hengshu Zhu. 2025. SciHorizon: Benchmarking AI-for-Science Readiness from Scientific Data to Large Language Models. InProceedings of the 31st ACM SIGKDD Conference on Kno...
-
[47]
Federico Raspanti, Tanir Ozcelebi, and Mike Holenderski. 2025. Grammar- constrained decoding makes large language models better logical parsers. In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 6: Industry Track). 485–499
2025
-
[48]
saurabh13nov. 2017. Lending Club Loan Data. https://www.kaggle.com/datasets/ saurabh13nov/lending-club-loan-data. Accessed: 2026-02
2017
-
[49]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Mem- bership inference attacks against machine learning models. In2017 IEEE sympo- sium on security and privacy (SP). IEEE, 3–18
2017
-
[50]
MAYNARA DONATO DE SOUZA and Cleber Zanchettin. 2025. Breaking the Barrier of Hard Samples: A Data-Centric Approach to Synthetic Data for Medical Tasks. InForty-second International Conference on Machine Learning. https: //openreview.net/forum?id=SJkpCMeIxu
2025
-
[51]
Shun Takagi, Tsubasa Takahashi, Yang Cao, and Masatoshi Yoshikawa. 2021. P3gm: Private high-dimensional data release via privacy preserving phased generative model. In2021 IEEE 37th international conference on data engineering (ICDE). IEEE, 169–180
2021
-
[52]
Xing, Zhiting Hu, and Shanshan Wu
Bowen Tan, Zheng Xu, Eric P. Xing, Zhiting Hu, and Shanshan Wu. 2025. Syn- thesizing Privacy-Preserving Text Data via Finetuning *without* Finetuning Billion-Scale LLMs. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=FCm4laCLiH
2025
-
[53]
Bowen Tan, Zheng Xu, Eric P Xing, Zhiting Hu, and Shanshan Wu. 2025. Syn- thesizing Privacy-Preserving Text Data via Finetuning* without* Finetuning Billion-Scale LLMs. InForty-second International Conference on Machine Learn- ing
2025
-
[54]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. 2024. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118(2024)
Pith/arXiv arXiv 2024
-
[55]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[56]
M. S. S. Tharun. 2023. Water Bottle Dataset from Flipkart. https://www.kaggle. com/datasets/tharunmss/water-bottle-dataset-flipkart. Accessed: 2025-02
2023
-
[57]
Shuaiqi Wang, Vikas Raunak, Arturs Backurs, Victor Reis, Pei Zhou, Sihao Chen, Longqi Yang, Zinan Lin, Sergey Yekhanin, and Giulia Fanti. 2025. Struct-Bench: A Benchmark for Differentially Private Structured Text Generation. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2025
-
[58]
Shuaiqi Wang, Vikas Raunak, Arturs Backurs, Victor Reis, Pei Zhou, Sihao Chen, Longqi Yang, Zinan Lin, Sergey Yekhanin, and Giulia Fanti. 2025. Struct-Bench: A Benchmark for Differentially Private Structured Text Generation. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net...
2025
-
[59]
Yuxin Wang, Duanyu Feng, Yongfu Dai, Zhengyu Chen, Jimin Huang, Sophia Ananiadou, Qianqian Xie, and Hao Wang. 2024. HARMONIC: Harnessing LLMs for tabular data synthesis and privacy protection.Advances in Neural Information Processing Systems37 (2024), 100196–100212
2024
-
[60]
Justin Whitehouse, Aaditya Ramdas, Ryan Rogers, and Steven Wu. 2023. Fully- adaptive composition in differential privacy. InInternational conference on ma- chine learning. PMLR, 36990–37007
2023
-
[61]
Chulin Xie, Zinan Lin, Arturs Backurs, Sivakanth Gopi, Da Yu, Huseyin A Inan, Harsha Nori, Haotian Jiang, Huishuai Zhang, Yin Tat Lee, et al. 2024. Differen- tially Private Synthetic Data via Foundation Model APIs 2: Text. InForty-first International Conference on Machine Learning
2024
-
[62]
Liyang Xie, Kaixiang Lin, Shu Wang, Fei Wang, and Jiayu Zhou. 2018. Differ- entially private generative adversarial network.arXiv preprint arXiv:1802.06739 (2018)
Pith/arXiv arXiv 2018
-
[63]
Pham, Mingyu Ding, Masayoshi Tomizuka, and Wei Zhan
Yichen Xie, Chenfeng Xu, Chensheng Peng, Shuqi Zhao, Nhat Ho, Alexan- der T. Pham, Mingyu Ding, Masayoshi Tomizuka, and Wei Zhan. 2025. X- Drive: Cross-modality Consistent Multi-Sensor Data Synthesis for Driving Sce- narios. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=IEMmEd5Jgm
2025
-
[64]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni
-
[65]
Modeling tabular data using conditional gan.Advances in neural information processing systems32 (2019)
2019
-
[66]
Jialin Yang, Dongfu Jiang, Lipeng He, Sherman Siu, Yuxuan Zhang, Disen Liao, Zhuofeng Li, Huaye Zeng, Yiming Jia, Haozhe Wang, et al . 2025. StructEval: Benchmarking LLMs’ Capabilities to Generate Structural Outputs.arXiv preprint arXiv:2505.20139(2025)
Pith/arXiv arXiv 2025
-
[67]
Mengmeng Yang, Chi-Hung Chi, Kwok-Yan Lam, Jie Feng, Taolin Guo, and Wei Ni. 2024. Tabular Data Synthesis with Differential Privacy: A Survey. arXiv:2411.03351 [cs.CR] https://arxiv.org/abs/2411.03351
arXiv 2024
-
[68]
Yu Yao, Yang Zhou, Bo Han, Mingming Gong, Kun Zhang, and Tongliang Liu. 2025. A Robust Method to Discover Causal or Anticausal Relation. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/ forum?id=Q0s6kgrUMr
2025
-
[69]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF). IEEE, 268–282
2018
-
[70]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. InPro- ceedings of the 58th Annual Meeting of the Association for Computational Linguis- tics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Associa- tion for Computational Linguistics, On...
-
[71]
Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, et al
-
[72]
InInternational Conference on Learning Representations
Differentially Private Fine-tuning of Language Models. InInternational Conference on Learning Representations
-
[73]
Xiang Yue, Huseyin Inan, Xuechen Li, Girish Kumar, Julia McAnallen, Hoda Shajari, Huan Sun, David Levitan, and Robert Sim. 2023. Synthetic text generation with differential privacy: A simple and practical recipe. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1321–1342
2023
-
[74]
Jun Zhang, Graham Cormode, Cecilia M Procopiuc, Divesh Srivastava, and Xi- aokui Xiao. 2017. Privbayes: Private data release via bayesian networks.ACM Transactions on Database Systems (TODS)42, 4 (2017), 1–41
2017
-
[75]
Jianqing Zhang, Yang Liu, JIE FU, Yang Hua, Tianyuan Zou, Jian Cao, and Qiang Yang. 2025. PCEvolve: Private Contrastive Evolution for Synthetic Dataset Gener- ation via Few-Shot Private Data and Generative APIs. InForty-second International Conference on Machine Learning
2025
-
[76]
Zhikun Zhang, Tianhao Wang, Ninghui Li, Jean Honorio, Michael Backes, Shibo He, Jiming Chen, and Yang Zhang. 2021. {PrivSyn}: Differentially private data synthesis. In30th USENIX Security Symposium (USENIX Security 21). 929–946
2021
-
[77]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[78]
Yiyang Zhou, Zhaoyang Wang, Tianle Wang, Shangyu Xing, Peng Xia, Bo Li, Kaiyuan Zheng, Zijian Zhang, Zhaorun Chen, Wenhao Zheng, Xuchao Zhang, Chetan Bansal, Weitong Zhang, Ying Wei, Mohit Bansal, and Huaxiu Yao
-
[79]
In The Thirteenth International Conference on Learning Representations
Anyprefer: An Agentic Framework for Preference Data Synthesis. In The Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=WpZyPk79Fu
-
[80]
Chengzhang Zhu, Longbing Cao, Qiang Liu, Jianping Yin, and Vipin Kumar. 2018. Heterogeneous metric learning of categorical data with hierarchical couplings. IEEE Transactions on Knowledge and Data Engineering30, 7 (2018), 1254–1267
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.