LaMo: Self-Supervised Latent Motion Priors for Physical Realism in Video Generation
Pith reviewed 2026-05-25 04:41 UTC · model grok-4.3
The pith
LaMo extracts self-supervised latent motion priors from unlabeled training videos to improve physical consistency in video diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
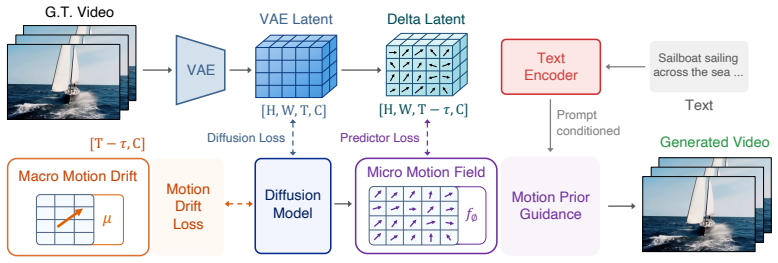
The paper claims that a latent motion prior defined over frame-to-frame changes in the diffusion latent space, conditioned on the current latent and prompt, supplies effective self-supervised signals for physical realism. This prior is realized through two lightweight readouts: a macro motion drift applied as a training loss and a learned micro motion field applied as sampling guidance. When added to existing video diffusion backbones such as CogVideoX, the components raise performance on VideoPhy and VideoPhy2 above recent physics-aware methods that require external simulators or curated data, while leaving VBench scores intact.
What carries the argument
The latent motion prior over frame-to-frame latent changes, conditioned on current latent and prompt, which is exposed as both a training loss and a sampling guidance term.
If this is right
- Existing video diffusion models can gain physical fidelity using only the data they were already trained on.
- The two readouts integrate into current backbones without any change to model architecture or input-output format.
- Performance on physics benchmarks can exceed methods that rely on external simulators or additional labeled data.
- Motion-related dimensions on general quality benchmarks improve while overall scores remain comparable.
Where Pith is reading between the lines
- The same self-supervised extraction approach could be tested on other generative domains where dynamics are implicit in large unlabeled corpora.
- Longer video sequences might reveal whether the prior scales to extended temporal consistency beyond the short clips used in current benchmarks.
- Combining the motion prior with other self-supervised signals present in the same data could produce stronger world-modeling capabilities.
Load-bearing premise
Motion patterns already present in the unlabeled videos used to train video diffusion models contain useful and unbiased information about physical fidelity.
What would settle it
An experiment in which adding the motion drift loss and motion prior guidance produces no reduction in physical violation rates on VideoPhy while keeping VBench scores unchanged.
Figures





read the original abstract
Modern video generators produce visually compelling clips but still struggle with physical and motion consistency, limiting their use as reliable world simulators. Existing remedies often rely on external simulators, teacher models, or curated physics-focused data. We explore a complementary self-supervised direction: extracting motion cues from the unlabeled videos already used to train video diffusion models. We propose LaMo, which formulates a latent motion prior over frame-to-frame latent changes conditioned on the current latent and prompt. This prior is exposed through two lightweight readouts: a macro motion drift used during training as a Motion Drift Loss, and a learned micro motion field used during sampling as Motion Prior Guidance. Both components are plug-and-play with existing video diffusion backbones, requiring no architectural or I/O changes. On VideoPhy and VideoPhy2, LaMo improves CogVideoX backbones and outperforms recent physics-aware baselines that use external supervision. On VBench, it preserves overall generation quality while improving motion-related dimensions. These results suggest that unlabeled video contains useful motion supervision for improving physical fidelity in modern video diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LaMo, a self-supervised method to improve physical realism and motion consistency in video diffusion models. It extracts motion cues from the unlabeled videos already used for pretraining to formulate a latent motion prior over frame-to-frame latent changes, conditioned on the current latent and prompt. The prior is exposed via a Motion Drift Loss (macro motion drift) during training and Motion Prior Guidance (learned micro motion field) during sampling; both are plug-and-play with no architectural or I/O changes to backbones such as CogVideoX. Experiments report improvements on VideoPhy and VideoPhy2 over recent physics-aware baselines that use external supervision, while preserving overall generation quality on VBench and improving motion-related dimensions.
Significance. If the empirical results hold under full verification of the training and sampling procedures, the work is significant for demonstrating that useful motion supervision for physical fidelity can be derived directly from the same unlabeled pretraining corpus without external simulators, teacher models, or curated physics data. The plug-and-play design increases the likelihood of adoption in existing video generators.
minor comments (3)
- [Abstract, §3] Abstract and §3: the terms 'macro motion drift' and 'micro motion field' are introduced without a concise one-sentence definition or reference to the exact equations that implement them; adding this would improve immediate readability.
- [§4.2, Table 2] §4.2 and Table 2: the VideoPhy/VideoPhy2 gains are reported as aggregate scores; per-category breakdowns (e.g., collision, gravity) would strengthen the claim that the prior specifically improves physical dimensions rather than generic motion.
- [§3.3] §3.3: the Motion Prior Guidance procedure at sampling is described at a high level; a short pseudocode block or explicit conditioning diagram would clarify how the learned micro motion field is injected without altering the diffusion backbone.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments appear in the report, so we provide no point-by-point responses below. We note the referee's emphasis on full verification of training and sampling procedures and will ensure all code, hyperparameters, and procedures are clearly documented and reproducible in the camera-ready version.
Circularity Check
No significant circularity identified
full rationale
The paper's core contribution is a self-supervised latent motion prior extracted from the same unlabeled pretraining videos, exposed via a Motion Drift Loss and Motion Prior Guidance that are applied to existing diffusion backbones. All reported gains are measured against external benchmarks (VideoPhy, VideoPhy2, VBench) and compared to independent baselines that use external supervision; no equation or claim reduces by construction to a fitted parameter defined from the target metric, no self-citation chain is load-bearing, and the formulation does not rename or smuggle in prior results as new derivations. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chat- topadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Videophy-2: A challenging action-centric physical commonsense evaluation in video generation
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation. arXiv preprint arXiv:2503.06800,
-
[5]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Yuanhao Cai, Kunpeng Li, Menglin Jia, Jialiang Wang, Junzhe Sun, Feng Liang, Weifeng Chen, Felix Juefei-Xu, Chu Wang, Ali Thabet, et al. Phygdpo: Physics-aware groupwise direct preference optimization for physically consistent text-to-video generation.arXiv preprint arXiv:2512.24551,
-
[7]
arXiv preprint arXiv:2502.02492 , year=
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492,
-
[8]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Quentin Garrido, Nicolas Ballas, Mahmoud Assran, Adrien Bardes, Laurent Najman, Michael Rabbat, Emmanuel Dupoux, and Yann LeCun. Intuitive physics understanding emerges from self-supervised pretraining on natural videos.arXiv preprint arXiv:2502.11831,
-
[10]
Nate Gillman, Yinghua Zhou, Zitian Tang, Evan Luo, Arjan Chakravarthy, Daksh Aggarwal, Michael Freeman, Charles Herrmann, and Chen Sun. Goal force: Teaching video models to accomplish physics-conditioned goals.arXiv preprint arXiv:2601.05848,
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training newton’s laws with verifiable rewards.arXiv preprint arXiv:2512.00425,
-
[14]
Realwonder: Real-time physical action-conditioned video generation.arXiv preprint arXiv:2603.05449,
Wei Liu, Ziyu Chen, Zizhang Li, Yue Wang, Hong-Xing Yu, and Jiajun Wu. Realwonder: Real-time physical action-conditioned video generation.arXiv preprint arXiv:2603.05449,
-
[15]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworld- model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Zhongwei Ren, Yunchao Wei, Xiao Yu, Guixun Luo, Yao Zhao, Bingyi Kang, Jiashi Feng, and Xiaojie Jin. Videoworld 2: Learning transferable knowledge from real-world videos.arXiv preprint arXiv:2602.10102,
-
[18]
Siddarth Nilol Kundur Satish, Devesh Jaiswal, Hongyu Chen, and Abhishek Bakshi. Physvideogen- erator: Towards physically aware video generation via latent physics guidance.arXiv preprint arXiv:2601.03665,
-
[19]
Dreamworld: Unified world modeling in video generation.arXiv preprint arXiv:2603.00466,
Boming Tan, Xiangdong Zhang, Ning Liao, Yuqing Zhang, Shaofeng Zhang, Xue Yang, Qi Fan, and Yanyong Zhang. Dreamworld: Unified world modeling in video generation.arXiv preprint arXiv:2603.00466,
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Wisa: World simulator assistant for physics-aware text-to-video generation
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video generation. InNeurIPS, 2025a. Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, et al. Wisa: World simulator assistant for physics-a...
-
[22]
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
11 Weijie Wang, Xiaoxuan He, Youping Gu, Yifan Yang, Zeyu Zhang, Yefei He, Yanbo Ding, Xirui Hu, Donny Y . Chen, Zhiyuan He, Yuqing Yang, and Bohan Zhuang. World-r1: Reinforcing 3d constraints for text-to-video generation.arXiv preprint arXiv:2604.24764, 2026a. Zijun Wang, Panwen Hu, Jing Wang, Terry Jingchen Zhang, Yuhao Cheng, Long Chen, Yiqiang Yan, Zu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Motion attribution for video generation
Xindi Wu, Despoina Paschalidou, Jun Gao, Antonio Torralba, Laura Leal-Taixé, Olga Russakovsky, Sanja Fidler, and Jonathan Lorraine. Motion attribution for video generation.arXiv preprint arXiv:2601.08828,
-
[24]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Haoze Zhang, Tianyu Huang, Zichen Wan, Xiaowei Jin, Hongzhi Zhang, Hui Li, and Wangmeng Zuo. Physchoreo: Physics-controllable video generation with part-aware semantic grounding.arXiv preprint arXiv:2511.20562, 2025a. Qiyuan Zhang, Biao Gong, Shuai Tan, Zheng Zhang, Yujun Shen, Xing Zhu, Yuyuan Li, Kelu Yao, Chunhua Shen, and Changqing Zou. Physrvg: Physi...
-
[26]
Videorepa: Learning physics for video generation through relational alignment with foundation models
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. Videorepa: Learning physics for video generation through relational alignment with foundation models. InNeurIPS, 2025b. 12 A Heatmap Computation for Figure 4 We compute the two heatmaps in Figure 4 on the same generated latent trajectory so that the macro a...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.